浅谈实时语音质量监控系统
今天小王学长跟大家谈谈实时语音质量监控系统的前世今生, 实时语音想必大家都不陌生,微信语音聊天、视频直播,生活中的例子比比皆是。
在过去的语音通信系统中,影响语音质量的因素有很多,包括但不仅限于延时(delay)、丢包(packet loss)、包延迟变化(packet delay variation)、回声(echo)、以及由于编码造成的失真。
语音质量评估方法总的来说可以分为三种:有参考客观评价方法、主观评价方法和无参考客观评价方法。
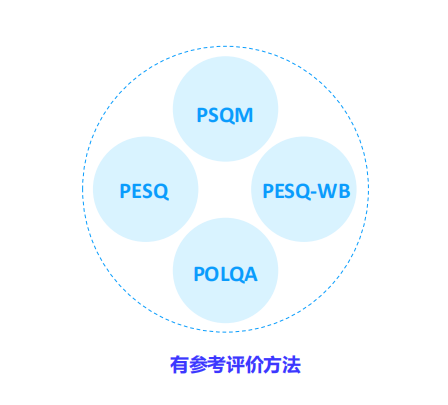
有参考客观评价方法:
是指把原始参考音视频与失真音视频在每一个对应帧中的每一个对应像素之间进行比较。准确的讲,这种方法得到的并不是真正的视频质量,而是失真音视频相对于原始音视频的相似程度或保真程度。最简单的方法如均方误差 MSE 和峰值信噪比 PSNR,其应用比较广泛。
PESQ 语音质量作为衡量语音传输性能的一个重要指标,如何得到准确、可靠的 QoE(体验质量)评价系统已成为当前研究的重点,PESQ(perceptual evaluation of speech quality,语音质量评价算法)是由 ITU 提出的基于 QoE 的语音质量评价算法,并随之成了 ITU-T P.862 标准。 PESQ 算法是当前比较流行的语音质量评价算法,说到 P.862 标准,P.861 PSQM 是最早的标准,ITU-T P.861 也叫做 PSQM,是根据 PAQM 推倒出来的一种语音质量评估体系。目前,P.862 PESQ、PESQ-WB 是应用最广泛的有参考评价方法,最新的有参考评价方法有 P.863 POLQA,这些都是依赖无损参考信号的。
无参考客观评价方法:
语音质量客观评价研究自七十年代以来得到了迅速发展,国内外学者提出了数以千计的客观评价方法。客观评价主要依据的就是原始语音信号和失真语音信号的时频域或变换域的特征参数对比。其主要是针对主观评价方法的不足,人们早就希望有客观评价方法来评价语音设备的音质,这之后许多人陆续提出了基于客观测度的客观音质评价方法。希望采用这些方法方便、快捷地给出被测语音系统的语音质量评价值,只不过评价的主体是由机器硬件或软件来完成。目前国内外采用较多的客观评价方法有 PSQM、PAMS 和 PSQM+等方法。其中 P.563 是最著名的窄带无参考评价方法。像 ANIQUE+这样的据作者称准确度超过有参考的 PESQ,其它的还有像 E-Model/P.1201 参数域评价方法以及 xxNet 深度学习域评价方法。
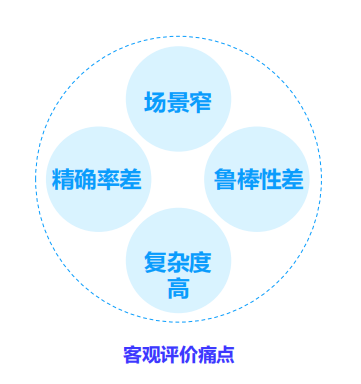
客观评价方法也有许多弊端:
有参考方法: 只能用在上线前
无参考方法-传统信号域: 应用场景窄、鲁棒性差
无参考方法-传统参数域: 仅在有限弱网条件下可以保持精度
无参考方法-深度学习: 应用场景和语料有限,复杂度略高
通常,我们可以从不同方向提出各种客观语音质量评估方法,但是客观语音质量评估必须最终通过其与主观语音质量评估的相关性来确定其性能和可靠性,我们通常通过主观和客观语音质量评估的拟合过程做出上述判断。拟合的过程是通过主观和客观语音质量评估输入不同条件下的语音主观和客观值,然后对主观和客观值进行最小二乘拟合,其中水平轴上的目标值为目标值在垂直轴上。画出语音的主客观质量评价曲线,得出主客观语音质量评价的比较关系。人们通常使用预测的均方误差值来反映主观和客观语音质量评估的相关程度。预测的均方误差值越接近,主观和客观语音质量评估之间的相关性越好,即,客观语音质量评估的性能越好。相反,它表明主观和客观言语质量评估之间的相关性越差,即客观言语质量评估的性能越差。
发展到现在以线下测试的线上化为主,具有高精度、广覆盖、低复杂度、强鲁棒等特点。
质量评估足够准确
覆盖绝大多数业务场景
不引入过多算法复杂度
和语音内容弱相关
上行链路质量评价方法: 采集-AEC-NS-AGC-诊断,具有独立检测+统一检测
特点:设备采集稳定性、回声消除能力、噪声抑制能力、音量调整能力
下行链路质量评价方法: 采用编码-传输-解码-播放
举一个某实验室的例子,其验证数据绘制全球音频质量地图的核心指标有:编解码器性能、网络质量、弱网对抗算法质量、设备播放能力。
其在多弱网、多设备、多模式的测试 case 下,该方法的打分与 POLQA 的参考打分 MAE 小于 0.1 分,MSE 小于 0.01 分,误差最大值小于 0.15 分
下图是某设备某模式的多弱网测试结果

某设备某模式的多弱⽹测试结果
在这里简单说下 NOMA 吧,NOMA(Non Othogonal Multiple Access),NOMA 的理论基础叫做多用户信息论。NOMA 即非正交多址接入技术,是非常有希望的 5G 技术。其优点是可以提高频谱效率(rate/bandwigth)和接入量,这恰好符合了即将到来的 5G 时代的爆炸性的数据增长和接入需求。在上下路链路质量评价方法中可以利用 NOMA 技术进行一个简单的比较。
上下行链路质量评价方法比较
1. 用户发送功率的分配不同。
在下行 NOMA 技术中,每个用户的发送功率是受基站的总发送功率以及其他各个用户的发送功率影响的,且对于信道质量不同的用户分配的发送功率不同(信道质量差即信道增益低的用户分配得高发送功率,反之则分配得低发送功率。
上行链路是每个用户的发送功率只是受到其设备的最大的发送功率影响。且对于信道质量有差异的用户都让其使用本身最大的发送功率(即每个用户都以自己最大的发射功率来发),信道质量差异很小的情况下则会采用在保证信道质量差的性能的同时提高信道质量好的分配方法,但是往往在这种情况下会对信道质量差的用户造成不好的影响。
2. SIC 解码顺序不同。
在下行链路中,每个接收端都收到了来自基站的叠加信号,且每个接收端都有自己的 SIC 接收机,对于接收到的信号,通过连续的解码,得到各自需要的信号。对于某一个接收端来说,叠加信号传过来的时候经历的信道是一样的,所以在算速率的时候大家乘的信道增益是一样的,这个时候则先解调接收功率最大的。
而在上行链路中的解码顺序则恰恰相反,因为发射用户可以理解成硬件的发射机性能没有差别,它们信道增益有高低之分,但是他们都会以自己的发射机的最大功率发射,这样距离基站近的用户的信号到了基站那边其接收功率更大(接收功率=发射功率 x 信道增益),这个时候则先解调接收功率最大的(也即信道增益最大的,因为此时发射功率一样)。
解码顺序:会对信道质量好的(即在接收端接收功率大的)进行优先解码;所以,在 NOMA 系统中,不管上行还是下行,在接收端优先解调的都是在接收端的接收功率最大的。
3、用户所受干扰不同。
在下行链路中,由于信道质量差的用户分配有高的发送功率,所以信道质量差的用户更容易在簇内对其他用户产生干扰,即为信道质量好的用户更容易受到干扰;
在上行链路中,由于是用户各自给基站发送信号从而产生叠加信号由基站接收,所以信道质量较差的用户比信道质量较好的更容易受到干扰。
4、实现难易度不同。
上行链路相较于下行链路更容易实现。在 NOMA 技术中,要最终实现多用户检测和连续干扰消除,其中连续干扰消除需要通过 SIC 接收机区分不同用户信号接受功率来实现。对于下行链路来说,是由基站发送叠加信号到用户,所以需要用户终端来实现多用户检测和连续干扰消除技术;在上行链路则是由各用户将各自信号发至基站,只需在基站处实现多用户检测和连续干扰消除技术。用户终端相较于基站而言处理能力过于有限,所以很难在用户终端实现多用户检测及连续干扰消除。
如果对 NOMA 技术感兴趣的小伙伴可以去搜下相关论文和资料学习下,定位就是有前景的 5G 技术。
下面简单说下实时语音过程中漏回声、噪音、杂音以及音量小的原因~
漏回声的原因:
在延时抖动过程中:可能会存在线程繁忙、设备非线性严重、双设备、非因果等
大混响环境:混响长度超出滤波器长度
采集信号溢出:导致滤波器不收敛
双讲:强依赖 NLP,容易顾此失彼
噪音、杂音原因
设备噪声:比如单频音、工频噪声、笔记本风扇声、无序杂音
环境噪声:Babble、鸣笛等
信号溢出:爆破音
算法引入:残留回声等
音量小的原因
设备采集能力弱、说话声音小 (这个占大多数)
设备播放能力弱
模拟增益、模拟 boost 增益小
数字增益小
最后在独立监测模块可以分为:啸叫检测、杂音监测、噪音检测、硬件检测四大部分。
小展望
在未来我认为感知、反馈和监控一定会呈现一体化,也会变得更细、更广、更快、更全;内部状态也会变得更细、体验覆盖更广、反馈速度会更快、覆盖通话也更全。也相信我国 5G 技术和实时音视频传输技术和质量评价体系会越来愈好。

还未添加个人签名 2021.02.05 加入
声网 Agora 是实时互动 API 平台行业开创者,实时互动技术服务覆盖全球 200 多个国家和地区。开发者只需简单调用 API,即可在应用内构建多种实时音视频互动场景。









评论