强强联手!腾讯 T6 大佬带你玩转 SpringData,GitHub 上线分享秒过万

今日分享开始啦,请大家多多指教~
1. 什么是 SpringData
Spring Data :Spring 的一子项目。用于简化数据库访问,支持 NoSQL 和关系数据存储。其主要目标是使数据库的访问变得方便快捷。
SpringData 项目所支持 NoSQL 存储:
MongoDB (文档数据库)
Neo4j(图形数据库)
Redis(键/值存储)
Hbase(列族数据库)
SpringData 项目所支持的关系数据存储技术:
JDBC
JPA
Spring Data JPA : 致力于减少数据访问层 (DAO) 的开发量. 开发者唯一要做的,就只是声明持久层的接口(有点类似于 mybatis 采用接口代理方式),其他都交给 Spring Data JPA 来帮你完成!
框架怎么可能代替开发者实现业务逻辑呢?比如:当有一个 UserDao.findUserById() 这样一个方法声明,大致应该能判断出这是根据给定条件的 ID 查询出满足条件的 User 对象。Spring Data JPA 做的便是规范方法的名字,根据符合规范的名字来确定方法需要实现什么样的逻辑。
2、SpringData JPA 入门
2.1、SpringData 开发步骤
使用 Spring Data JPA 进行持久层开发需要的四个步骤:
配置 Spring 整合 JPA
在 Spring 配置文件中配置 Spring Data:
让 Spring 为声明的接口创建代理对象。配置了 jpa:repositories 后,Spring 初始化容器时将会扫描 base-package 指定的包目录及其子目录,为继承 Repository 或其子接口的接口创建代理对象,并将代理对象注册为 Spring Bean,业务层便可以通过 Spring 自动封装的特性来直接使用该对象。
声明持久层的接口,该接口继承 Repository:
Repository 是一个标记型接口,它不包含任何方法,如必要,Spring Data 可实现 Repository 其他子接口,其中定义了一些常用的增删改查,以及分页相关的方法。
在接口中声明需要的方法:
Spring Data 将根据给定的策略(具体策略稍后讲解)来为其生成实现代码。
2.2、SpringData 环境搭建
创建 maven 项目:
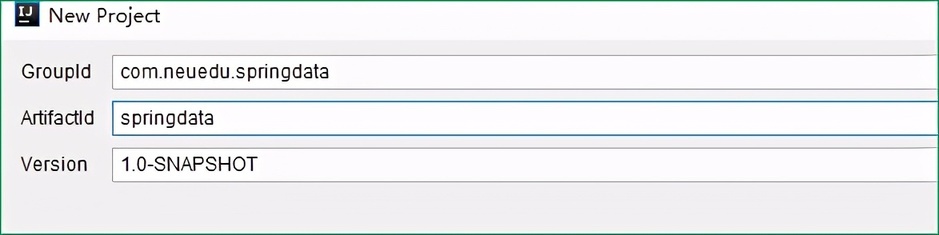
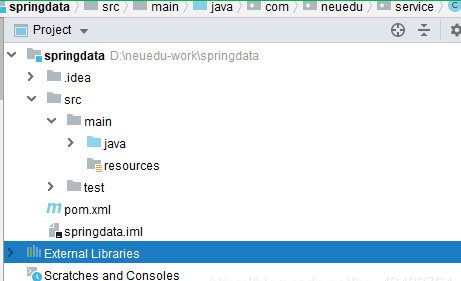
2.3、入门案例
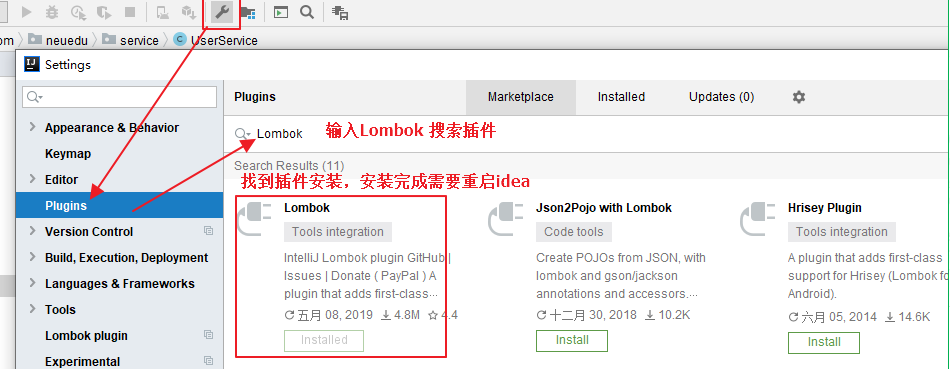
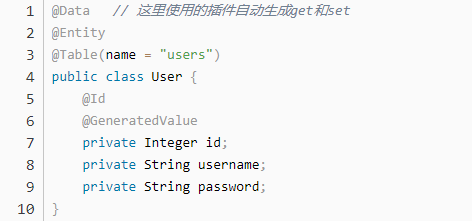
2.3.1、Lombok 插件
开发中我们要写大量的 java 实体类,虽然 idea 能够直接生成 get 和 set 方法,有的时候碰到那种属性很多的实体类,看代码都看的头痛。Lombok 插件,它能够让代码更简洁好看,不需要生成 get 和 set 方法,编译也能通过。更加直白地说,就是帮助我们快速生成 get 和 set 方法。
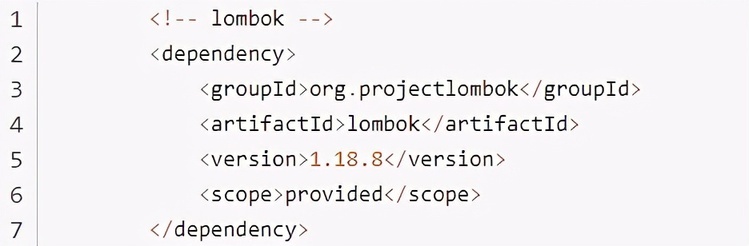
同时还需要在 pom 中引入
上面这些步骤做完之后,只要在书写的 pojo 上添加对应的注解即可:@Data 注解

这样在编写 pojo 的时候,只需要添加属性即可, 其他的 get 和 set 自动生成(在源码中是没有 get 和 set 的,只是在生成的 class 源码中存在)。
需要在数据库中创建 User 表

2.3.2、编写 pom 文件

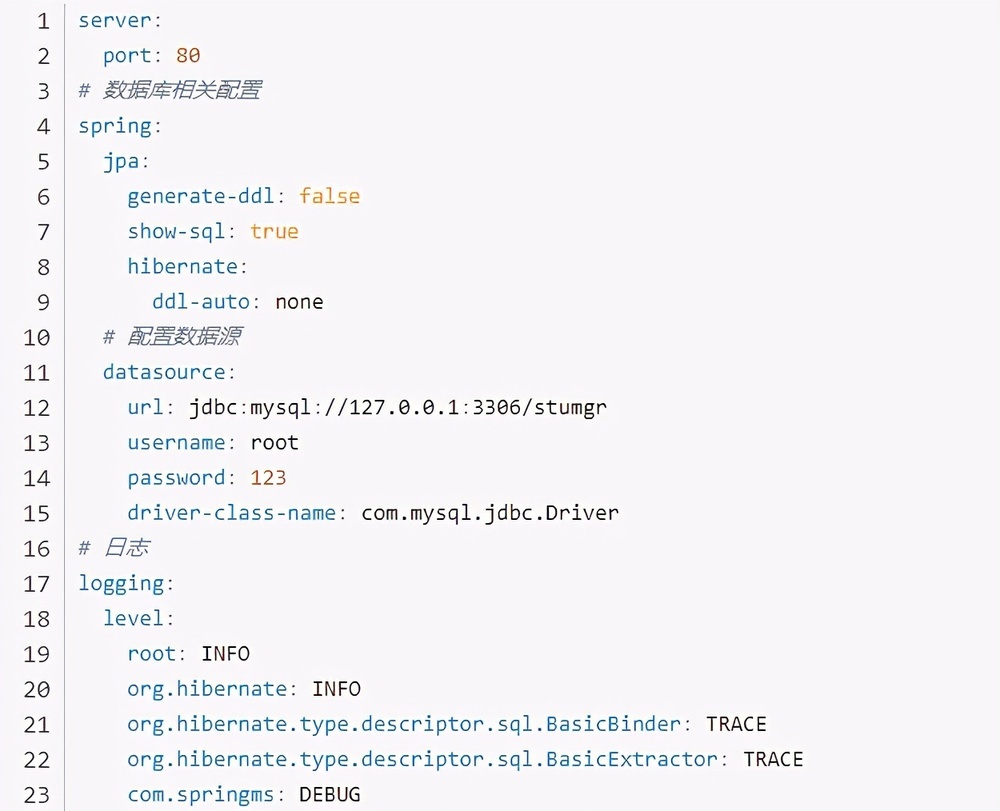
2.3.3、编写 springboot 的配置文件
2.3.4、编写启动类

2.3.5、编写 Controller 类

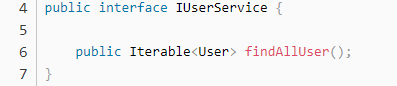
2.3.6、编写 Service
接口的编写:
编写实现类:

2.3.7、编写 repository
public interface UserRepository extends JpaRepository<User,Integer> { }
关于 Spring Data JPA 的 Repository 接口后续会详细说明
2.3.8、完整的 pojo
2.3.9、测试结果

3、Repository 接口
Repository 接口是 Spring Data 的一个核心接口,它不提供任何方法,开发者需要在自己定义的接口中声明需要的方法
@Indexed
public interface Repository<T, ID> { }
Spring Data 可以让我们自定义接口,只要遵循 Spring Data 的规范,就无需写实现类。
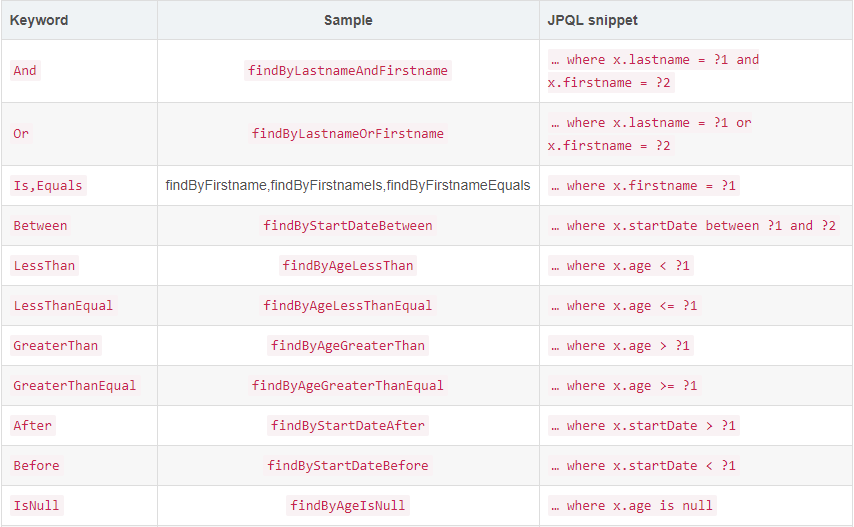
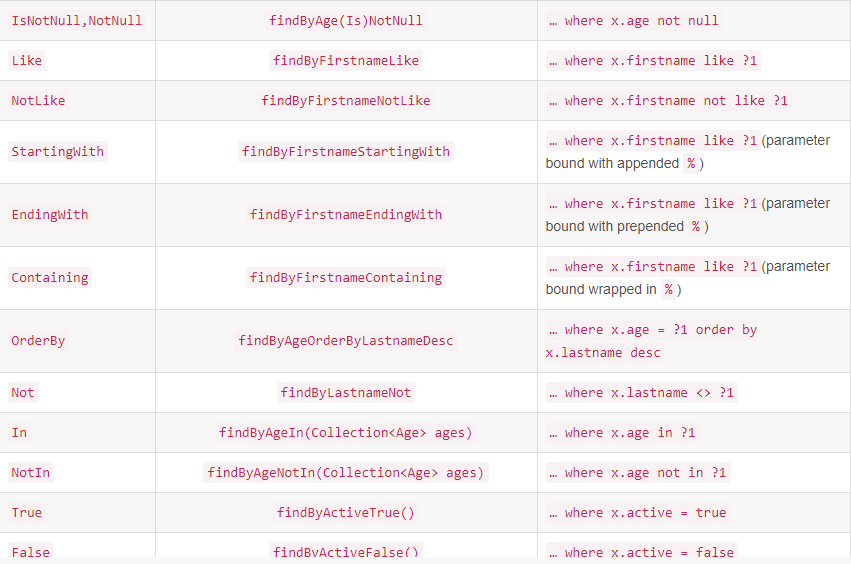
spring data 支持的关键字

4、Repository 子接口
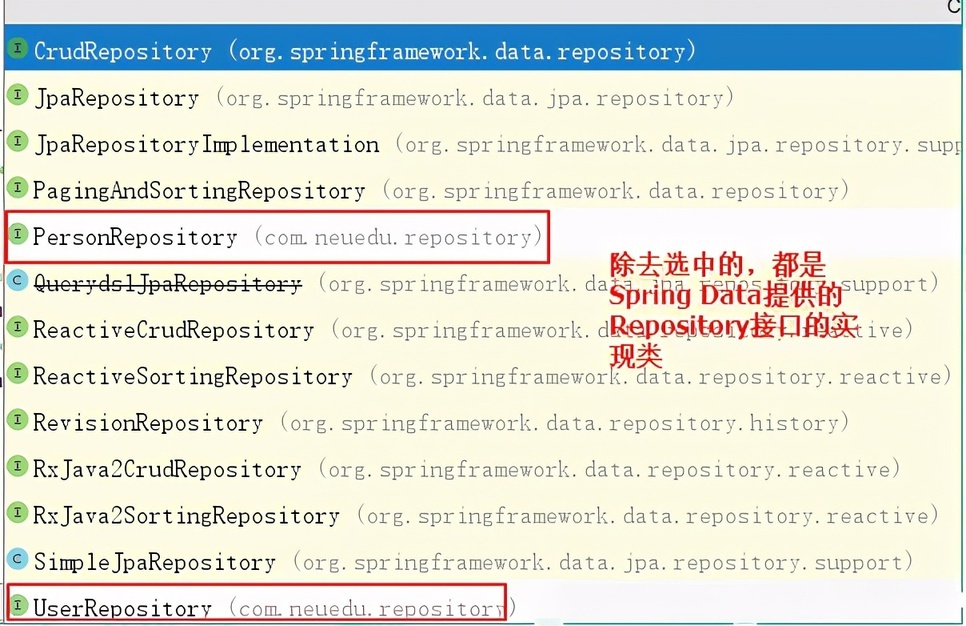
基础的 Repository 提供了最基本的数据访问功能,其几个子接口则扩展了一些功能。它们的继承关系如下:
Repository: 仅仅是一个标识,表明任何继承它的均为仓库接口类
CrudRepository: 继承 Repository,实现了一组 CRUD 相关的方法
PagingAndSortingRepository: 继承 CrudRepository,实现了一组分页排序相关的方法
JpaRepository: 继承 PagingAndSortingRepository,实现一组 JPA 规范相关的方法
自定义的 XxxxRepository 需要继承 JpaRepository,这样的 XxxxRepository 接口就具备了通用的数据访问控制层的能力。
JpaSpecificationExecutor: 不属于 Repository 体系,实现一组 JPA Criteria 查询相关的方法
5、使用 @Query 注解
5.1 使用数字占位符
可以在 Repository 方法中,将查询直接在相应的接口方法上(类似于 mybatis 的注解开发),结构更为清晰。
@Query("select u from User u where u.id = ?1")
public User findUserById(Integer id);
说明:
索引参数:索引值从 1 开始,查询中 ”?X” 个数需要与方法定义的参数个数相一致,并且顺序也要一致。
表名需要使用 POJO 代替,并且用别名。
select 后面不能使用*,可以使用别名代替
5.2 使用参数占位符和注解
上面使用的数字占位符非常不友好,可以使用参数占位符代替,但是需要在方法上使用 @Param 注解声明参数占位符的名称,
@Query("select u from User u where u.username = :name")
public User findUserByName(@Param("name") String name);
@Param 注解中标注的参数名。
如果是 @Query 中有 LIKE 关键字,后面的参数需要前面或者后面加 %,这样在传递参数值的时候就可以不加 %:
@Query(“select o from UserModel o where o.name like ?1%”)
public List<UserModel> findByUuidOrAge(String name);
@Query(“select o from UserModel o where o.name like %?1”)
public List<UserModel> findByUuidOrAge(String name);
@Query(“select o from UserModel o where o.name like %?1%”)
public List<UserModel> findByUuidOrAge(String name);
还可以使用 @Query 来指定本地查询,只要设置 nativeQuery 为 true,比如:
@Query(value="select * from tb_user where name like %?1" ,nativeQuery=true)
public List<UserModel> findByUuidOrAge(String name);
6、@Modifying 注解和事务
@Query 与 @Modifying 执行(CUD)操作这两个 annotation 一起声明,可定义个性化更新操作,例如只涉及某些字段更新时最为常用,示例如下:

注意:在调用的地方必须加事务,没有事务不能正常执行
对于自定义的方法,如需改变 SpringData 提供的事务默认方式,可以在方法上注解 @Transactional 声明。
7、CrudRepository 接口
CrudRepository 接口提供了最基本的对实体类的添删改查操作

8、PagingAndSortingRepository 接口
该接口提供了分页与排序功能

9、JpaRepository 接口
该接口提供了 JPA 的相关功能

10、JpaSpecificationExecutor 接口
不属于 Repository 体系,实现一组 JPA Criteria 查询相关的方法

Specification:封装 JPA Criteria 查询条件。通常使用匿名内部类的方式来创建该接口的对象
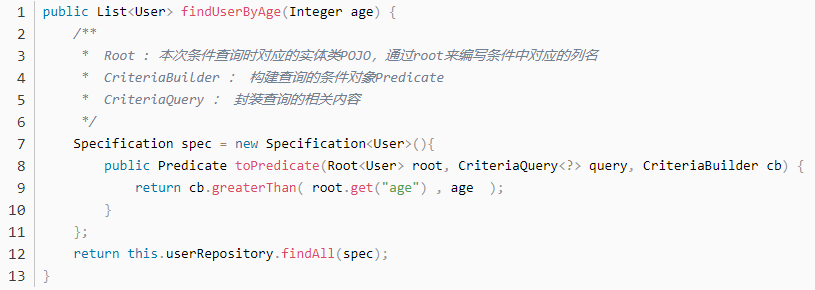
11、多表操作
11.1、一对一查询
一对一的业务场景:用户和地址,一个用户拥有唯一的户籍归属地
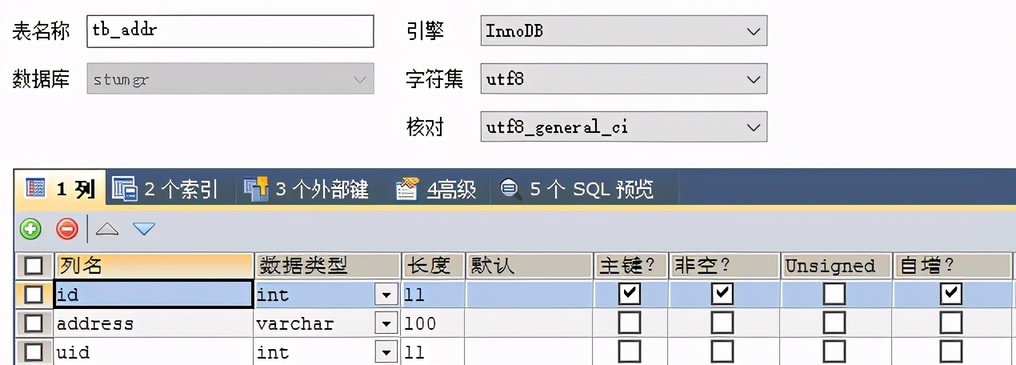
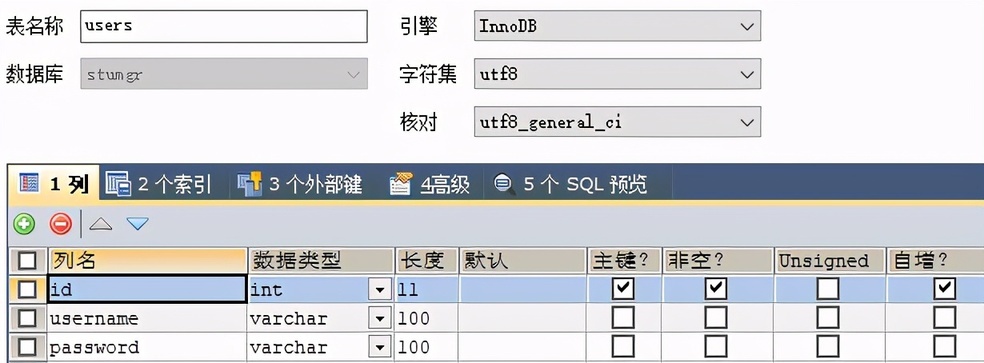
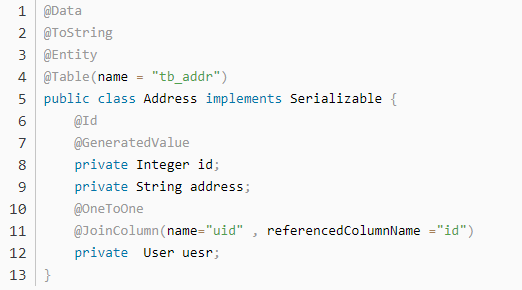
针对一对一的查询操作,需要在对应的一的 pojo 中添加另外一方的对象,并且使用
@OneToOne
@JoinColumn(name=“uid” , referencedColumnName =“id”)注解配置映射关系。name=“uid” 当前的外键列名,referencedColumnName =“id”,关联的对象的中的主键名称
在 pojo 中如果存在外键,需要删除或者忽略。而配置的 OneToOne 的注解就相当于外键列。

11.2、一对多查询
一对多业务场景假设:作者和作品,一个作者对应多个作品,每个作品对应唯一的一个作者。
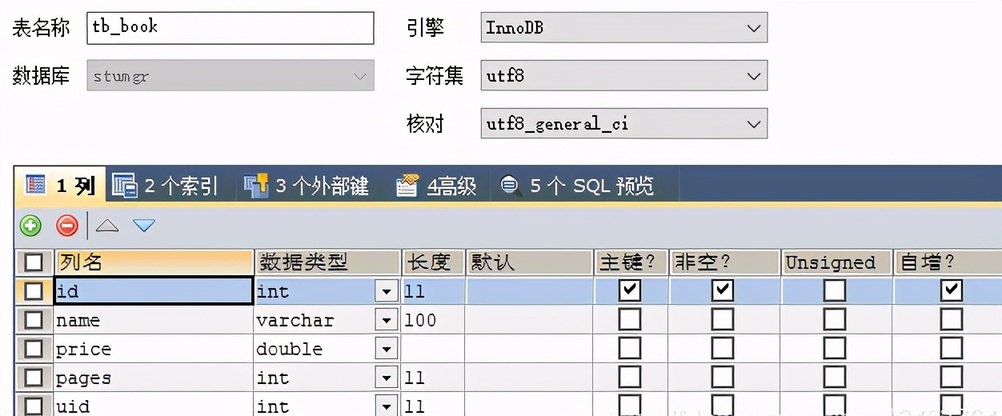
11.2.1 Book 和 User 实体


针对一对多的操作:
在一的一方的 Pojo 中添加多的一方的引用:List 集合,同时需要在属性添加对应的注解
@OneToMany : 声明当前的属性是一个一对多的设置,SpringData JPA 会进行关联查询
@JoinColumn(name = “uid” ,referencedColumnName = “id”) 设置关联的外键和主键的关系
11.2.2 BookRepository

11.3、 多对多查询
11.3.1 表结构
多对多场景假设:订单和商品之间的关系,一个订单中存在多类商品,一类商品可以出现在多个订单中。
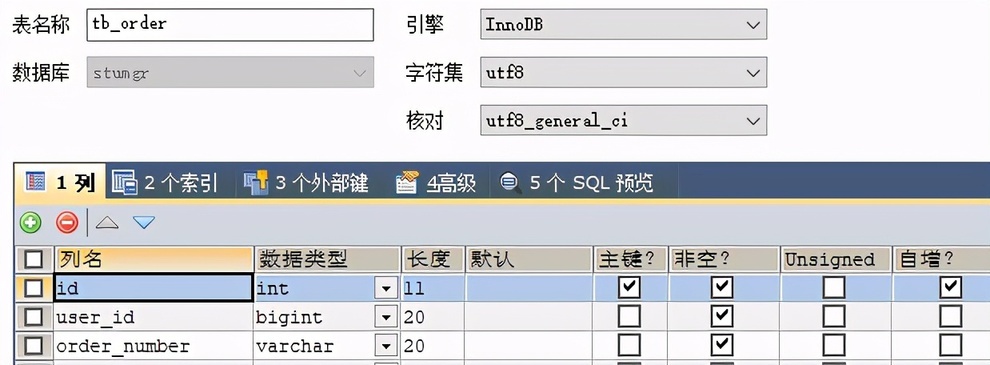
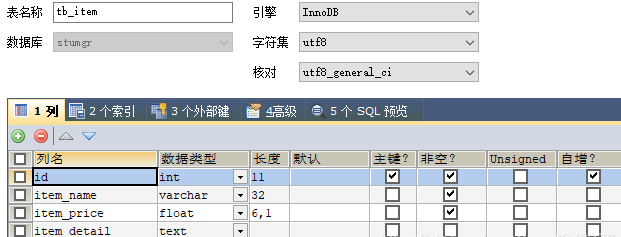
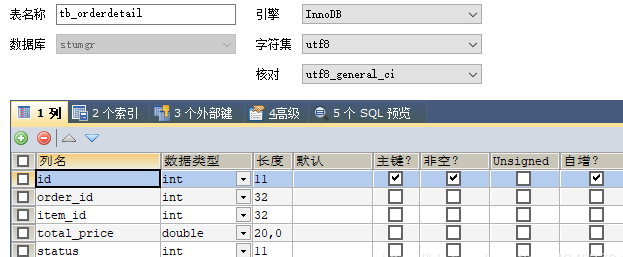
11.3.2 POJO 的编写

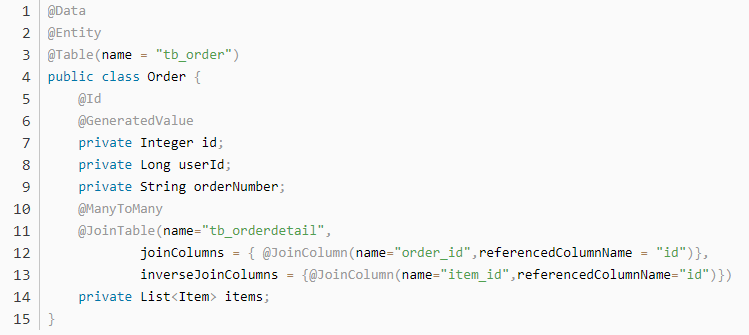
在多对多查询的时候,分为主表和副表(主查询对象和次查询对象)
针对上面的案例:
Order 是主查询对象,Item 是次查询对象,但在两个 POJO 中都需要使用集合表示多的这种关系。同时在上面添加 @ManyToMany 注解,表示多对多
在主查询 Order 中:
需要使用 @JoinTable 声明多对多的中间和字段映射关系
@JoinTable(name=“tb_orderdetail”,
joinColumns = { @JoinColumn(name=“order_id”,referencedColumnName = “id”)},
inverseJoinColumns = {@JoinColumn(name=“item_id”,referencedColumnName=“id”)})
@JoinTable 注解中的 name 书写中间表名
joinColumns 书写主查询的主键在中间表中的外键列名
referencedColumnName 书写主查询的主键列名(可以省略)
inverseJoinColumns 书写关联的次查询在中间表中的外检列名
次查询 Item 中:
需要在集合属性上的 @ManyToMany 注解中使用
targetEntity 属性编写主查询的类
mappedBy 属性编写主查询管理的次查询的属性名
千万别踩的坑:
在给主查询和次查询的 pojo 中添加 get 和 set 方法的时候,注意不要形成嵌套。
在次查询中的集合不要再生成 get 和 set 方法了,否则就会嵌套,无法正常进行数据的 json 操作。
今日份分享已结束,请大家多多包涵和指点!

还未添加个人签名 2021.04.20 加入
Java工具与相关资料获取等WX: pfx950924(备注来源)









评论