
一种基于 HiveMetaStore 的跨源查询方案实践
本文作者为中国移动云能力中心大数据团队软件开发工程师张步涛,文章对比 了多种跨源查询联邦方案,并介绍了基于 HiveMetaStore 的方案在 Hive、Trino、Ranger 的一些优化实践,实现多引擎对接 HiveMetaStore 读写 MySQL 数据源的整体方案。
前言
大数据业务开发中,用户的数据会存放在不同的存储中,比如 HDFS 上的 Hive 数据,MySQL 中的数据或者 HBase 中的数据,用户希望用多种计算引擎进行跨源联邦计算,但多种分散的数据源可能会面临不同的权限管理方案,同时每一种元数据对外提供的接口也是不同,无法满足企业级生产需求。在数据湖建设中,我们希望多种计算引擎在跨源计算时能够对接统一的元数据接口以及统一的权限管理,这种需求需要一个统一的元数据管理服务,我们考虑基于 Hive Metastore(HMS)设计多种异构数据源管理方案。
HMS 发展之初是为 Hadoop HDFS 上的文本数据如 textfile、列存数据如 Parquet、ORC 等提供表的访问形式,用户可以向计算引擎提交简单的 SQL 完成数据查询,经过多年的发展,HMS 成为大数据生态元数据服务的事实标准。我们选择 HMS 作为统一元数据管理的基础框架,HMS 中纳管不同的数据源,并提供统一权限管理以及标准的元数据接口,满足多种计算引擎跨源查询的需求。
以 JDBC 数据源为例,在调研中,我们尝试了多种跨源查询联邦方案,比如下面的方案一和方案二,最后确定了本文采用的方案三即基于 HMS 的跨源查询方案:
方案一
为用户提供 Trino 计算引擎,Trino 天生适合同时查询多个数据源数据,一条 SQL 中既可以包含 HMS 数据也可以包含 MySQL 数据。能够基于 Trino 的 pipeline 流水线内存执行框架进行相对高效的查询。同时 Ranger Trino 插件也可以做一些权限管理。
方案二
使用 Spark3 计算引擎,利用 Spark3 datasource V2 自定义相关 JDBC catalog,既可以 SQL 方式进行 HMS 数据与 JDBC 联查也可以 dataframe 编码方式进行跨源数据探索。
实际上方案一与方案二用户可以交替使用。但是在真实生产中,当前两个方案都会有一些问题:
方案一需要 Trino 集成 Ranger 插件,而我们 HMS 已经具备 Ranger 鉴权能力,我们更希望所有的元数据均在 metastore 端进行鉴权;而且 Trino 定位主要 OLAP 查询,有时并不能 cover 住我们内部业务场景。
方案二 Spark3 如果纯 SQL 操作多数据源的话还是需要一些 catalog 的完善设计,而且目前没有太好的 Spark Ranger 鉴权方案,而且即便集成 Ranger 插件,由于我们内部有很多 Spark 即席查询,如果每次运行任务都会拉取一下 Ranger 策略,也会引起性能问题。
除此之外,无论是 Spark3 还是 Trino,如果访问多个数据源的话,都需要三级元数据目录定位表位置,如 mysqlcatalog.testdb.testtb,对于已经习惯开发 Hive 业务的同事需要修改很多业务代码,所以我们考虑还是二级元数据目录定位表位置,即常规的 testdb.testtbl 形式。
还有综合未来我们对 HMS 的统一元数据管理服务的愿景,我们提出了第三种方案:
方案三
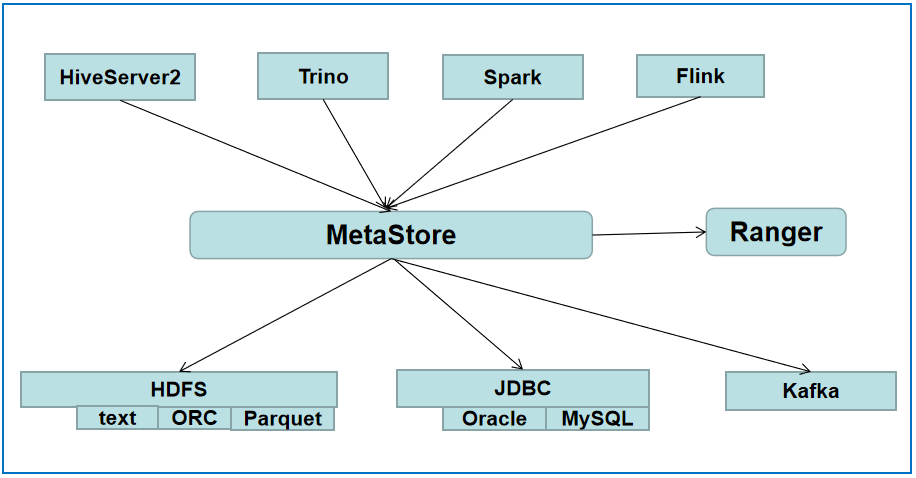
基于 HMS 管理 JDBC 数据源
如图,我们的设想是基于 metastore 对 JDBC 数据源、Kafka 数据源等非 HDFS 数据进行管理,并让上层计算引擎无缝对接,简要概述如下:
1)JDBC 元数据统一由 HMS 提供接口访问;上层计算引擎可以利用已有的 HMS 接口获取 JDBC 表;
2)JDBC 元数据由 HMS 提供统一的 Ranger 鉴权,能够通过 HMS 对 JDBC 库表进行基本的权限管理;
3)上层计算引擎读取 JDBC 的表数据。即上层计算引擎通过 HMS 获取 JDBC 表结构信息后,使用合适的 Serialize/Deserialize(SerDe)序列化反序列化接口读取 JDBC 数据,且能够与 HMS 数据关联计算。这一点非常重要,下面会重点阐述。
为了满足以上三点,我们充分调研了 Hive、Trino、Spark 组件具备的能力,最后确定能够较完美的完成整个方案设计。以下我们会针对方案三的这三点分别展开论述。
一、HMS 标准接口统一访问 JDBC 元数据
1、Hive JDBCStorageHandler 问题
如何通过 HMS 的 getAllTables 接口获取 JDBC 表呢?其实 Hive 2.3 版本 (https://issues.apache.org/jira/browse/HIVE-1555) 已经实现了 Hive 中查询 MySQl 表的功能就是 JDBCStorageHandler,但是整个功能有很大限制:
1)需要用户在 HMS 中创建表映射 MySQL 表,每次只能映射一个表,效率很低;
2)HMS 中需要冗余存储一份 MySQl 映射表,而且远端 MySQL 表有字段变动时,HMS 中的映射表还需要人工去同步修改;
3)由于 Hive 和 MySQL 中的数据类型不统一,创建 HMS 映射表时,需要用户对 MySQL 中的字段类型手动转换成 Hive 数据类型,如果一个 MySQL 表有上百个字段,那么对用户来说转换数据类型就是一个很大的工作量。
虽然 JDBCStorageHandler 功能可以通过 HMS 获取 JDBC 元数据,但是很不方便,如果基于这个功能去实现整体方案,用户使用起来会痛苦不堪。那么怎么优化这个功能?
2、Hive data connector 功能
在调研 Hive 社区最新动态时,我们发现 Hive 社区正在开发 data connector 功能 (https://issues.apache.org/jira/browse/HIVE-24396),data connector 基于 JDBCStorageHandler 功能做了改进,能够一定程度上满足我们的需求 。data connector 解决了使用 JDBCStorageHandler 的三个痛点:
1)取代单表逐一映射繁琐操作,用户在 HMS 中创建映射库(REMOTE DATABASE),映射远端 MySQL 的库;
2)HMS 中不会冗余存储 MySQL 映射表,SQL 任务在 runtime 运行期会动态拉取需要的远端 MySQL 表;
3)HMS 中会自动进行 MySQl 数据类型转换 Hive 数据类型,不需要用户人工转换。
由于 data connector 整个功能目前还处于开发中,使用中我们发现了很多问题,部分 bug fix 已经贡献给了 Hive 社区,如:
•https://issues.apache.org/jira/browse/HIVE-26180
•https://issues.apache.org/jira/browse/HIVE-26171
•https://issues.apache.org/jira/browse/HIVE-26040
•https://issues.apache.org/jira/browse/HIVE-26192
•https://issues.apache.org/jira/browse/HIVE-26131
总而言之,社区已经搭好了 data connector 的架子,我们可以根据自己定制化需求做更多改造,比如开发 Kafka、HBase 等类型的 connector,满足我们通过 HMS 标准接口获取外部元数据基本需求。
二、HMS 提供统一的 JDBC 元数据鉴权
1、HMS 支持 Ranger 鉴权 data connector
通过 data connector 创建的映射库 remote database 以及映射表和一般的库表鉴权一样,在 Ranger 侧没有区别,鉴权方式一样,不需要任何改造。这里我们主要指的是 data connector 的权限控制。由于 data connector 中存储了远端 MySQL 的用户名和密码,如果没有权限控制,用户 A 创建的 data connector 可以被任何人看到并且使用,在 HMS 多租户使用情况下会有安全隐患。实际上 Hive 社区已经对 data connector 的权限管理做了一部分工作(https://issues.apache.org/jira/browse/HIVE-25214),但是社区完成的部分工作是 HiveServer2 端对 data connector 的鉴权,而我们需要的是 HMS 端的 data connector 统一鉴权,所以我们基于社区现有的开发工作,补齐了 HMS 端的 data connector 鉴权能力,部分开发贡献给了 Hive 社区,如:
•https://issues.apache.org/jira/browse/HIVE-26246
•https://issues.apache.org/jira/browse/HIVE-26248
•https://issues.apache.org/jira/browse/HIVE-26247
2、Trino、Presto 对接 HMS 授权
同时,在 Trino/Presto 对接 HMS 权限控制时(详情可以参考历史文章 Trino 多租户最佳实践),我们也发现了一些问题,比如 Trino 中部分接口没有使用真实的客户端用户导致 HMS 无法鉴权,并把部分 fix 贡献给了 Trino、Presto 社区,如:
•https://github.com/trinodb/trino/pull/12002
•https://github.com/prestodb/presto/pull/17574
3、Ranger 中新增支持 dataconnector 资源类型校验
由于我们内部 HMS 使用 Ranger 插件进行鉴权,但是开源 Ranger 中是没有 data connector 这种校验资源类型的,我们对 Ranger Hive Plugin 以及 Ranger Admin 代码进行了改造,在 Ranger 中增加了 Hive 的 dataconnector 资源校验类型,满足了我们 HMS 中使用 Ranger 鉴权 data connector 的需求。后续我们也会把相关 Ranger 改造贡献给 Ranger 社区,尽量保持与上游 Ranger 代码的一致。
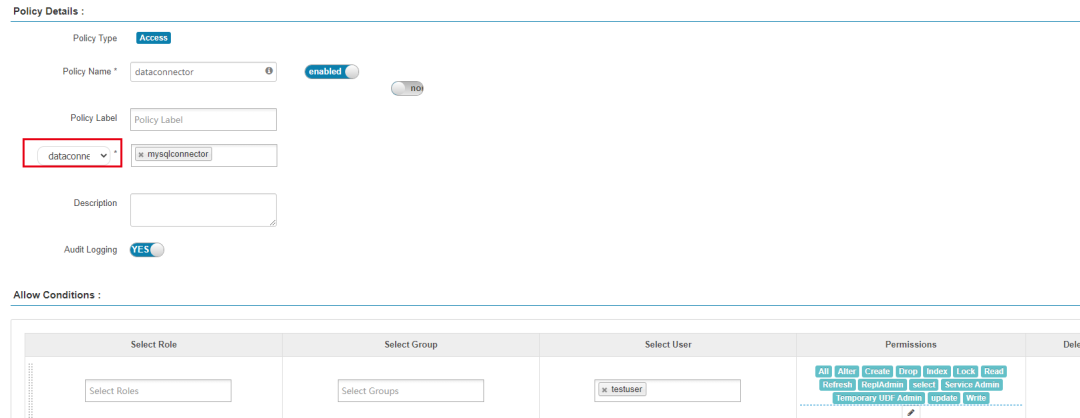
Ranger 中新增 Hive dataconnector 资源鉴权类型
三、上层计算引擎通过 HMS 读写 JDBC 数据源
通过 HMS data connector 功能,上层计算引擎能够使用标准的 HMS 接口获取远端 MySQL 表结构。但是仅获取 MySQL 表信息是不够的,还要能够读取 MySQL 数据并且和 HMS 中其他 HDFS 数据关联计算,而读取 MySQL 数据需要每个计算引擎有合适的 SerDe 接口。我们当前使用的主要计算引擎有 HiveServer2、Flink、Spark、Trino,由于 data connector 以及 JDBCStorageHandler 是 Hive 的功能,HiveServer2 当然可以原生支持通过 HMS 读写 MySQL 数据。这里我们考虑的是 Flink、Spark 以及 Trino 怎么通过 HMS 读写 MySQL 数据?
经过调研测试,我们选型了两种读取 MySQL 数据的方式,一种是兼容 Hive SerDe 接口的读写另一种是计算引擎自带的 SerDe 接口读写数据。
1、兼容 Hive SerDe 的计算引擎读写 MySQL 数据
Flink、Spark 计算引擎能够很好地兼容 Hive 语法以及 Hive SerDe,并且能够对 Hadoop 生态 InputFormat/OutputForm 接口有很好地兼容,JDBCStorageHandler 实现了 Hive 的 AbstractSerDe 接口,所以只要把 JDBCStorageHandler 相关 lib 放到 Flink、Spark 的 classpath 就可以实现 MySQL 的基本读写功能。我们通过测试,发现方案基本是可行的,但 JDBCStorageHandler 中针对的是 Hive 数据类型与 MySQL 数据类型转换,Spark 和 Flink 使用的时候会有些类型转换问题,我们后续会针对计算引擎单独优化 JDBCStorageHandler 的相关依赖。
2、计算引擎自带 SerDe 接口读写 MySQL 数据
Trino 计算引擎的数据读写接口比较有意思,Trino 代码中没有引用任何开源相关的 Hadoop、Hive 依赖,但是 Trino 自己维护一套 Hadoop 和 Hive 相关的 shade 包,比如 Trino 用 Hive thrift 文件自己搞了一个兼容 HMS 的客户端。同时 Trino 中没有使用 Hive SerDe 接口,Trino 不会使用 Hive 中任何已有的 InputFormat/OutputForm 接口去读写数据,而是用数据源的 native 接口去进行读写操作,比如 ORC 数据,Trino 不会去调用 Hive 封装的 OrcInputFormat/OrcOutputFormat 接口,而是直接调用 ORC 最底层的 native 接口去实现自己的一套读写接口。Trino 这样做有自己的考虑,因为 Trino 定位自己是跨多数据源查询的 OLAP,直接调用数据源 native 读写接口能够带来更高效的查询,而且如果代码中引入了过多开源组件的依赖,会导致整体代码结构混乱,更重要的是 Trino 不想因为其他开源框架封装的读写接口出现 bug 而导致自己开发阻塞。
既然 Trino 不兼容 Hive SerDe 读写接口,那么即便我们把 JDBCStorageHandler 相关 lib 放到 Trino classpath 也是无济于事。那应该怎样使 Trino 通过 HMS 读写 MySQL 数据呢?我们考虑了两个方案:
1)在 Trino 的 Hive Catalog Plugin 模块实现 JDBC 数据读写,即在 Trino Hive Plugin 中把 Hive 中的 JDBCStorageHandler 相关读写重新实现,把 JDBC 数据源和 ORC 一样作为一种 Hive 数据类型。这种方案理论上可行,但是 JDBC 数据比较特殊,不能很好的复用现有的 Trino Hive 接口,改造起来问题还是比较多。
2)复用 Trino 中现有的 MySQL Plugin SerDe。因为 Trino 本身有一套 MySQL Plugin 读写 MySQL 数据,而且这套接口应用了很长时间,非常稳定,我们考虑怎么在 Trino Hive Plugin 中复用现有的 MySQL SerDe,完成 MySQL 数据高效稳定的读写。
我们优先考虑第二种方案,因为即便实现了第一种方案把 MySQL 数据读写搞定,后续我们还会在 HMS 中接入其他比如 Kafka 数据源,如果每次在 HMS 中接入新的数据源都要对 Trino Hive Plugin 改造,那么代码维护成本就很高,而且没有经过大规模验证读写效率也不敢保证。
那么 Trino 如何通过 HMS 读写 MySQL 表时复用现有的 MySQL Plugin SerDe 呢?我们在调研 Trino 社区最新的开发动向时,发现 Trino 一个有趣的功能 https://github.com/trinodb/trino/pull/10173 。Trino 社区主力当前正在开发 Trino Iceberg Plugin,Iceberg 的表默认还是使用 HMS 存储,但 Trino Hive Plugin 和 Trino Iceberg Plugin 读写数据接口是不同的,用户登录 Trino 操作 Hive Plugin 时,既可以看到 HMS 中普通表也可以看到 Iceberg 表,但是 Hive Plugin 中是无法读写 Iceberg 表数据的。所以 Trino 社区开发了表重定向功能,即在 Hive Plugin 中读写 Iceberg 表时会自动重定向到 Iceberg Plugin 中,这样就复用了现有的 Trino Iceberg SerDe 接口,不需要在 Hive Plugin 去改造实现 Iceberg 类型数据读写接口。比如 Trino Hive Plugin 中查 Iceberg 表,SQL 会在 Trino 内部转换:
Trino 的这个表重定向功能能够很完美的满足我们第二种方案需求,即在 Trino Hive Plugin 通过重定向复用已有的 MySQL 读写接口。由于这个功能是由参数控制跳转到固定的 Trino Iceberg Plugin,我们需要改造的是如何动态的跳转不同的 Trino MySQL Plugin。我们做了两方面小改造:
1)在 HMS 中 MySQL 表属性中增加记录需要跳转的 Trino MySQL Plugin 名称(对应 data connector 名称)以及远端 MySQL 的 database 名称;
2)Trino 表重定向功能处根据表属性动态确定当前表需要跳转的 MySQL Plugin 以及 database。
这两个改动,代码量很少,但是完美解决了我们复用现有 Trino MySQL SerDe 的需求,极大地减少了我们自定义改造的工作量。如下图,hive 中已经创建了 data connector 命名 mysqlconnector,并用 db_mysql 映射远端的 MySQL 中的 testdb 数据库,然后在 Trino Hive Plugin 中执行 SQL 查询 db_mysql.mysqltbl 表,在 Trino 内部就会跳转为 mysqlconnector.testdb.mysqltbl 表:
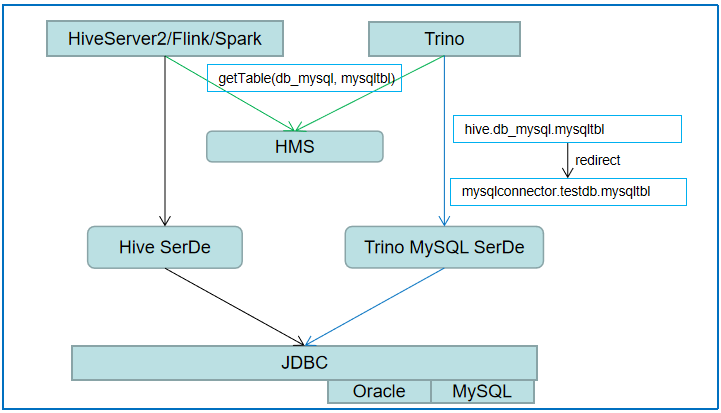
HiveServer2/Flink/Spark 使用 Hive SerDe 读写 JDBC 数据,Trino 使用重定向功能复用 Trino MySQl Serde 读写 JDBC 数据
在解决了复用 Trino MySQL SerDe 的问题后,我们又面临了一个新的问题:用户在 Hive 中创建的 data connector 需要与 Trino MySQL Plugin 名称对应,而且用户可能会动态创建多个 data connector,而 Trino 当前不支持动态添加 Plugin,每次创建或者删除一个 data connector,都需要人工在 Trino 侧添加或者删除配置并重启 Trino 服务,使用起来不是很方便。为此,我们开发了 Trino 动态数据源增删接口,同时在 HMS Listener(MetaStorePreEventListener.java)侧监听每次的 data connector 增删事件,data connector 创建成功就会向 Trino 集群发送 MySQL 数据源创建请求,保持 data connector 的增删与 Trino 中 MySQL 数据源增删实时同步。为了进一步确保一致,我们后台还有一个定时同步任务,定时全量同步 data connector 至 Trino。后续我们会考虑 Trino 侧主动同步数据源信息,比如我们可以把 data connector 信息存到 redis,Trino 定期读取 redis 更新数据源信息,这种主动更新方式比外部服务向 Trino 同步要更稳妥一些。
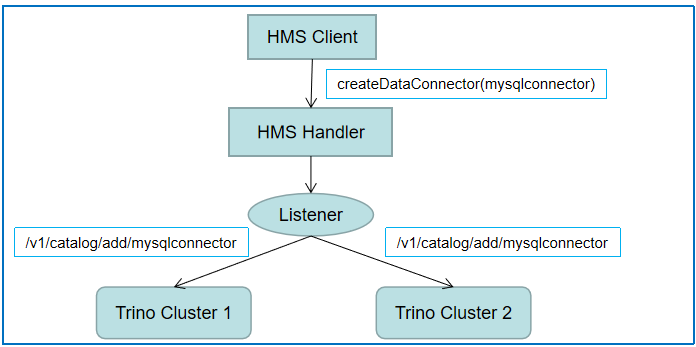
HMS 与 Trino 同步 data connector 信息
当前,针对 Spark、Flink,我们使用现有的 Hive SerDe 完成了基本的读写 HMS 中 MySQL 数据源,针对 Trino,我们使用表重定向以及 data connector 同步功能,复用 Trino 现有能力读写 MySQL 数据。整个读写方案能够很好的支持后续接入新的数据源,不需要过多侵入性代码改造。
总结
通过对 Hive、Trino、Ranger 的一些优化,我们实现了多引擎对接 HMS 读写 MySQL 数据源的整体方案。未来我们会基于该方案继续添加新的数据源,比如 Kafka、HBase 等,使 HMS 支持多种异构数据源,并做到企业级多租户权限管理效果。同时我们还会积极与开源社区互动,向开源社区进一步贡献相关 bug fix 以及新功能等。

移动云,5G时代你身边的智慧云 2019.02.13 加入
移动云大数据产品团队,在移动云上提供云原生大数据分析LakeHouse,消息队列Kafka/Pulsar,云数据库HBase,弹性MapReduce,数据集成与治理等PaaS服务。 微信公众号:人人都学大数据









评论