如何使用阿里云容器服务保障容器的内存资源质量
作者:韩柔刚(申信)
背景
云原生场景中,应用程序通常以容器的形式部署和分配物理资源。以 Kubernetes 集群为例,应用工作负载以 Pod 声明了资源的 Request/Limit,Kubernetes 则依据声明进行应用的资源调度和服务质量保障。
当容器或宿主机的内存资源紧张时,应用性能会受到影响,比如出现服务延时过高或者 OOM 现象。一般而言,容器内应用的内存性能受两方面的影响:
自身内存限制:当容器自身的内存(含 page cache)接近容器上限时,会触发内核的内存子系统运转,此时容器内应用的内存申请和释放的性能受到影响。
宿主机内存限制:当容器内存超卖(Memory Limit > Request)导致整机内存出现紧张时,会触发内核的全局内存回收,这个过程的性能影响更甚,极端情况能导致整机夯死。
前文《阿里云容器服务差异化 SLO 混部技术实践》和《如何合理使用 CPU 管理策略,提升容器性能》分别阐述了阿里云在云原生混部、容器 CPU 资源管理方面的实践经验和优化方法,本文同大家探讨容器使用内存资源时的困扰问题和保障策略。
容器内存资源的困扰
Kubernetes 的内存资源管理
部署在 Kubernetes 集群中的应用,在资源使用层面遵循标准的 Kubernetes Request/Limit 模型。在内存维度,调度器参考 Pod 声明的 Memory Request 进行决策,节点侧由 Kubelet 和容器运行时将声明的 Memory Limit 设置到 Linux 内核的 cgroups 接口,如下图所示:
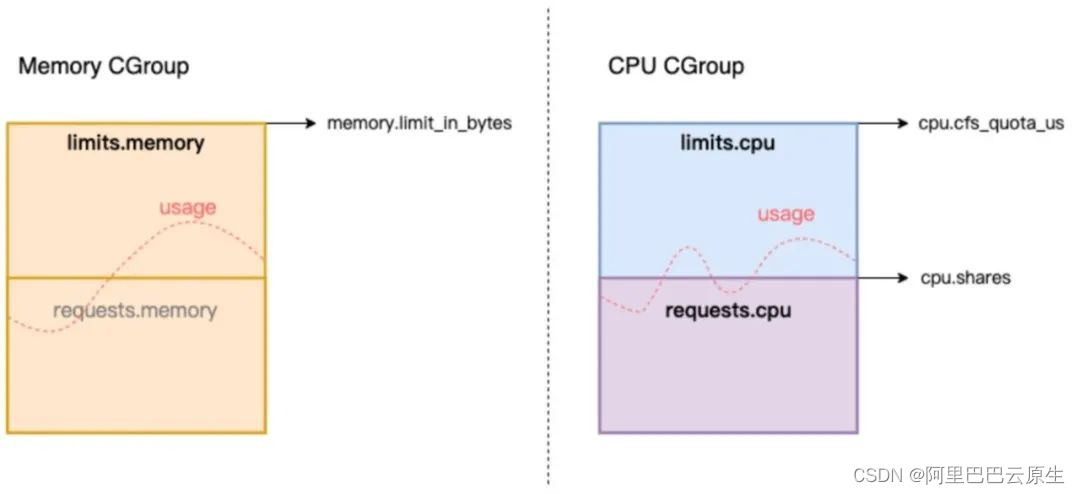
CGroups(Control Groups,简称 cgroups)是 Linux 上管理容器资源使用的机制,系统可以通过 cgroups 对容器内进程的 CPU 和内存资源用量作出精细化限制。而 Kubelet 正是通过将容器的 Request/Limit 设置到 cgroup 接口,实现对 Pod 和 Container 在节点侧的可用资源约束,大致如下:

Kubelet 依据 Pod/Container 的 Memory Limit 设置 cgroups 接口 memory.limit_in_bytes,约束了容器的内存用量上限,CPU 资源维度也有类似限制,比如 CPU 时间片或绑定核数的约束。对于 Request 层面,Kubelet 依据 CPU Request 设置 cgroups 接口 cpu.shares,作为容器间竞争 CPU 资源的相对权重,当节点的 CPU 资源紧张时,容器间共享 CPU 时间的比例将参考 Request 比值进行划分,满足公平性;而 Memory Request 则默认未设置 cgroups 接口,主要用于调度和驱逐参考。
Kubernetes 1.22 以上版本基于 cgroups v2 支持了 Memory Request 的资源映射(内核版本不低于 4.15,不兼容 cgroups v1,且开启会影响到节点上所有容器)。
例如,节点上 Pod A 的 CPU Request 是 2 核,Pod B 的 CPU Request 是 4 核,那么当节点的 CPU 资源紧张时,Pod A 和 Pod B 使用 CPU 资源的相对比例是 1:2。而在节点的内存资源紧张时,由于 Memory Request 未映射到 cgroups 接口,容器间的可用内存并不会像 CPU 一样按 Request 比例划分,因此缺少资源的公平性保障。
云原生场景的内存资源使用
在云原生场景中,容器的内存 Limit 设置影响着容器自身和整个宿主机的内存资源质量。由于 Linux 内核的原则是尽可能使用内存而非不间断回收,因此当容器内进程申请内存时,内存用量往往会持续上升。当容器的内存用量接近 Limit 时,将触发容器级别的同步内存回收,产生额外延时;如果内存的申请速率较高,还可能导致容器 OOM (Out of Memory) Killed,引发容器内应用的运行中断和重启。
容器间的内存使用同时也受宿主机内存 Limit 的影响,如果整机的内存用量较高,将触发全局的内存回收,严重时会拖慢所有容器的内存分配,造成整个节点的内存资源质量下降。
在 Kubernetes 集群中,Pod 之间可能有保障优先级的需求。比如高优先级的 Pod 需要更好的资源稳定性,当整机资源紧张时,需要尽可能地避免对高优先级 Pod 的影响。然而在一些真实场景中,低优先级的 Pod 往往运行着资源消耗型任务,意味着它们更容易导致大范围的内存资源紧张,干扰到高优先级 Pod 的资源质量,是真正的“麻烦制造者”。对此 Kubernetes 目前主要通过 Kubelet 驱逐使用低优先级的 Pod,但响应时机可能发生在全局内存回收之后。
使用容器内存服务质量保障容器内存资源
容器内存服务质量
Kubelet 在 Kubernetes 1.22 以上版本提供了 MemoryQoS 特性,通过 Linux cgroups v2 提供的 memcg QoS 能力来进一步保障容器的内存资源质量,其中包括:
• 将容器的 Memory Request 设置到 cgroups v2 接口 memory.min,锁定请求的内存不被全局内存回收。• 基于容器的 Memory Limit 设置 cgroups v2 接口 memory.high,当 Pod 发生内存超用时(Memory Usage > Request)优先触发限流,避免无限制超用内存导致的 OOM。
上游方案能够有效解决 Pod 间内存资源的公平性问题,但从用户使用资源的视角来看,依然存在一些不足:
• 当 Pod 的内存声明 Request = Limit 时,容器内依然可能出现资源紧张,触发的 memcg 级别的直接内存回收可能影响到应用服务的 RT(响应时间)。• 方案目前未考虑对 cgroups v1 的兼容,在 cgroups v1 上的内存资源公平性问题仍未得到解决。
阿里云容器服务 ACK 基于 Alibaba Cloud Linux 2 的内存子系统增强,用户可以在 cgroups v1 上提前使用到更完整的容器 Memory QoS 功能,如下所示:
保障 Pod 间内存回收的公平性,当整机内存资源紧张时,优先从内存超用(Usage > Request)的 Pod 中回收内存,约束破坏者以避免整机资源质量的下降。
当 Pod 的内存用量接近 Limit 时,优先在后台异步回收一部分内存,缓解直接内存回收带来的性能影响。
节点内存资源紧张时,优先保障 Guaranteed/Burstable Pod 的内存运行质量。

典型场景
内存超卖
在云原生场景下,应用管理员可能会为容器设置一个大于 Request 的 Memory Limit,以增加调度灵活性,降低 OOM 风险,优化内存资源的可用性;对于内存利用率较低的集群,资源管理员也可能使用这种方式来提高利用率,作为降本增效的手段。但是,这种方式可能造成节点上所有容器的 Memory Limit 之和超出物理容量,使整机处于内存超卖(memory overcommit)状态。当节点发生内存超卖时,即使所有容器的内存用量明显低于 Limit 值,整机内存也可能触及全局内存回收水位线。因此,相比未超卖状态,内存超卖时更容易出现资源紧张现象,一旦某个容器大量申请内存,可能引发节点上其他容器进入直接内存回收的慢速路径,甚至触发整机 OOM,大范围影响应用服务质量。
Memory QoS 功能通过启用容器级别的内存后台异步回收,在发生直接回收前先异步回收一部分内存,能改善触发直接回收带来的延时影响;对于声明 Memory Request < Limit 的 Pod,Memory QoS 支持为其设置主动内存回收的水位线,将内存使用限制在水位线附近,避免严重干扰到节点上其他 Pod。
混合部署
Kubernetes 集群可能在同一节点部署了有着不同资源使用特征的 Pods。比如,Pod A 运行着在线服务的工作负载,内存利用率相对稳定,属于延时敏感型业务(Latency Sensitive,简称 LS);Pod B 运行着大数据应用的批处理作业,启动后往往瞬间申请大量内存,属于资源消耗型业务(Best Effort,简称 BE)。当整机内存资源紧张时,Pod A 和 Pod B 都会受到全局内存回收机制的干扰。实际上,即使当前 Pod A 的内存使用量并未超出其 Request 值,其服务质量也会受到较大影响;而 Pod B 可能本身设置了较大的 Limit,甚至是未配置 Limit 值,使用了远超出 Request 的内存资源,是真正的“麻烦制造者”,但未受到完整的约束,从而破坏了整机的内存资源质量。
Memory QoS 功能通过启用全局最低水位线分级和内核 memcg QoS,当整机内存资源紧张时,优先从 BE 容器中回收内存,降低全局内存回收对 LS 容器的影响;也支持优先回收超用的的内存资源,保障内存资源的公平性。
技术内幕
Linux 的内存回收机制
如果容器声明的内存 Limit 偏低,容器内进程申请内存较多时,可能产生额外延时甚至 OOM;如果容器的内存 Limit 设置得过大,导致进程大量消耗整机内存资源,干扰到节点上其他应用,引起大范围的业务时延抖动。这些由内存申请行为触发的延时和 OOM 都跟 Linux 内核的内存回收机制密切相关。
容器内进程使用的内存页面(page)主要包括:• 匿名页:来自堆、栈、数据段,需要通过换出到交换区(swap-out)来回收(reclaim)。• 文件页:来自代码段、文件映射,需要通过页面换出(page-out)来回收,其中脏页要先写回磁盘。• 共享内存:来自匿名 mmap 映射、shmem 共享内存,需要通过交换区来回收。
Kubernetes 默认不支持 swapping,因此容器中可直接回收的页面主要来自文件页,这部分也被称为 page cache(对应内核接口统计的 Cached 部分,该部分还会包括少量共享内存)。由于访问内存的速度要比访问磁盘快很多,Linux 内核的原则是尽可能使用内存,内存回收(如 page cache)主要在内存水位比较高时才触发。
具体而言,当容器自身的内存用量(包含 page cache)接近 Limit 时,会触发 cgroup(此处指 memory cgroup,简称 memcg)级别的直接内存回收(direct reclaim),回收干净的文件页,这个过程发生在进程申请内存的上下文,因此会造成容器内应用的卡顿。如果此时的内存申请速率超出回收速率,内核的 OOM Killer 将结合容器内进程运行和使用内存的情况,终止一些进程以进一步释放内存。
当整机内存资源紧张时,内核将根据空闲内存(内核接口统计的 Free 部分)的水位触发回收:当水位达到 Low 水位线时,触发后台内存回收,回收过程由内核线程 kswapd 完成,不会阻塞应用进程运行,且支持对脏页的回收;而当空闲水位达到 Min 水位线时(Min < Low),会触发全局的直接内存回收,该过程发生在进程分配内存的上下文,且期间需要扫描更多页面,因此十分影响性能,节点上所有容器都可能被干扰。当整机的内存分配速率超出且回收速率时,则会触发更大范围的 OOM,导致资源可用性下降。
Cgroups-v1 Memcg QoS
Kubernetes 集群中 Pod Memory Request 部分未得到充分保障,因而当节点内存资源紧张时,触发的全局内存回收能破坏 Pod 间内存资源的公平性,资源超用(Usage > Request)的容器可能和未超用的容器竞争内存资源。
对于容器内存子系统的服务质量(memcg QoS),Linux 社区在 cgroups v1 上提供了限制内存使用上限的能力,其也被 Kubelet 设置为容器的 Limit 值,但缺少对内存回收时的内存使用量的保证(锁定)能力,仅在 cgroups v2 接口上支持该功能。
Alibaba Cloud Linux 2 内核在 cgroups v1 接口中默认开启 memcg QoS 功能,阿里云容器服务 ACK 通过 Memory QoS 功能为 Pod 自动设置合适的 memcg QoS 配置,节点无需升级 cgroups v2 即可支持容器 Memory Request 的资源锁定和 Limit 限流能力,如上图所示:
• memory.min:设置为容器的 Memory Request。基于该接口的内存锁定的能力,Pod 可以锁定 Request 部分的内存不被全局回收,当节点内存资源紧张时,仅从发生内存超用的容器中回收内存。• memory.high:当容器 Memory Request < Limit 或未设置 Limit 时,设置为 Limit 的一个比例。基于该接口的内存限流能力,Pod 超用内存资源后将进入限流过程,BestEffort Pod 不能严重超用整机内存资源,从而降低了内存超卖时触发全局内存回收或整机 OOM 的风险。
更多关于 Alibaba Cloud Linux 2 memcg QoS 能力的描述,可参见官网文档:https://help.aliyun.com/document_detail/169536.html
内存后台异步回收
前面提到,系统的内存回收过程除了发生在整机维度,也会在容器内部(即 memcg 级别)触发。当容器内的内存使用接近 Limit 时,将在进程上下文触发直接内存回收逻辑,从而阻塞容器内应用的性能。
针对该问题,Alibaba Cloud Linux 2 增加了容器的后台异步回收功能。不同于全局内存回收中 kswapd 内核线程的异步回收,本功能没有创建 memcg 粒度的 kswapd 线程,而是采用了 workqueue 机制来实现,同时支持 cgroups v1 和 cgroups v2 接口。
如上图所示,阿里云容器服务 ACK 通过 Memory QoS 功能为 Pod 自动设置合适的后台回收水位线 memory.wmark_high。当容器的内存水位达到该阈值时,内核将自动启用后台回收机制,提前于直接内存回收,规避直接内存回收带来的时延影响,改善容器内应用的运行质量。
更多关于 Alibaba Cloud Linux 2 内存后台异步回收能力的描述,可参见官网文档:https://help.aliyun.com/document_detail/169535.html
全局最低水位线分级
全局的直接内存回收对系统性能有很大影响,特别是混合部署了时延敏感型业务(LS)和资源消耗型任务(BE)的内存超卖场景中,资源消耗型任务会时常瞬间申请大量的内存,使得系统的空闲内存触及全局最低水位线(global wmark_min),引发系统所有任务进入直接内存回收的慢速路径,进而导致延敏感型业务的性能抖动。在此场景下,无论是全局 kswapd 后台回收还是 memcg 后台回收,都将无法有效避免该问题。
针对上述场景,Alibaba Cloud Linux 2 增加了 memcg 全局最低水位线分级功能,允许在全局最低水位线(global wmark_min)的基础上,通过 memory.wmark_min_adj 调整 memcg 级别生效的水位线。阿里云容器服务 ACK 通过 Memory QoS 功能为容器设置分级水位线,在整机 global wmark_min 的基础上,上移 BE 容器的 global wmark_min,使其提前进入直接内存回收;下移 LS 容器的 global wmark_min,使其尽量避免直接内存回收,如下图所示:
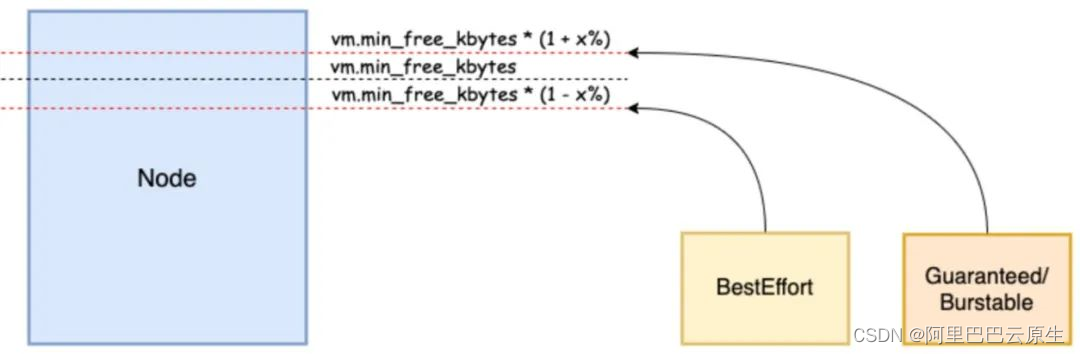
这样,当 BE 任务瞬间大量申请内存的时候,系统能通过上移的 global wmark_min 将其短时间抑制,避免促使 LS 发生直接内存回收。等待全局 kswapd 回收一定量的内存后,再解决对 BE 任务的短时间抑制。
更多关于 Alibaba Cloud Linux 2 memcg 全局最低水位线分级能力的描述,可参见官网文档:https://help.aliyun.com/document_detail/169537.html
小结
综上,容器内存服务质量(Memory QoS)基于 Alibaba Cloud Linux 2 内核保障容器的内存资源质量,各能力的推荐使用场景如下:

我们使用 Redis Server 作为时延敏感型在线应用,通过模拟内存超卖和压测请求,验证开启 Memory QoS 对应用延时和吞吐的改善效果:
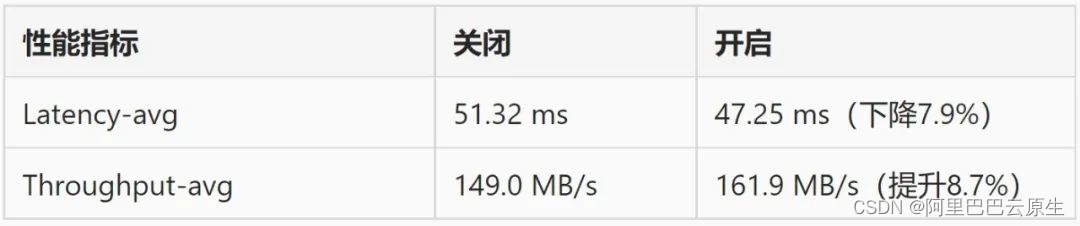
对比以上数据可得知,开启容器内存服务质量后,Redis 应用的平均时延和平均吞吐都得到了一定改善。
总结
针对云原生场景下容器使用内存的困扰,阿里云容器服务 ACK 基于 Alibaba Cloud Linux 2 内核提供了容器内存服务质量(Memory QoS)功能,通过调配容器的内存回收和限流机制,保障内存资源公平性,改善应用的运行时内存性能。Memory QoS 属于相对静态的资源质量方案,适合作为保障 Kubernetes 集群内存使用的兜底机制,而对于复杂的资源超卖和混合部署场景,更加动态和精细化的内存保障策略显得不可或缺。例如,对于内存水位的频繁波动,基于实时资源压力指标的驱逐策略,能够敏捷地在用户态进行减载(load schedding);另一方面,可以通过更细粒度地发掘内存资源,比如基于冷热页面标记的内存回收,或 Runtime (e.g. JVM) GC,来达到高效的内存超卖。敬请期待阿里云容器服务 ACK 支持差异化 SLO 功能的后续发布。

阿里巴巴云原生 2019.05.21 加入
还未添加个人简介









评论