百度大规模 Service Mesh 落地实践

导读:百度过去基于 rpc 框架的服务治理存在各种框架能力层次不齐、业务自身服务治理效率低、全局可观测性不足等诸多问题。本文介绍了百度内部落地 service mesh 的实践过程,以基础稳定性能力治理和流量调度治理能力为业务落地点,详细阐述了内部落地的 service mesh 整体技术方案以及一系列关键技术,如性能的极致优化、扩展的高级策略、周边服务治理系统等。
全文 6835 字,预计阅读时间 13 分钟。
一、背景
百度大部分产品线已完成微服务的改造, 数万个微服务对架构服务治理能力提出了更高的要求。传统的服务治理一般通过 rpc 框架去解决,多年以来百度内部也衍生出多种语言的 rpc 框架,比如 c++、go、php 等等框架,基础服务治理能力和 rpc 框架耦合,rpc 框架能力参差不齐,给公司整体服务治理能力和效率提升带来较多的痛点及挑战:
1.高级架构能力无法多语言、多框架复用
如某产品线近 2 年发生数次雪崩 case,底层依赖的 php、golang 等框架需要重复建设来定制动态熔断、动态超时等高级能力,而这些能力在其他 rpc 框架已支持;
如常用架构降级、止损能力各个产品线重复建设,接口方案差异大,从运维层面,运维同学期望基础的架构止损能力在不同产品线之间能够通用化,接口标准化,降低运维成本;
2.架构容错能力治理周期长,基础能力覆盖度低
随着混沌工程全面落地,对架构能力有了更高要求。多数模块对单点异常,慢节点等异常缺乏基础容忍能力,推动每个模块独立修复,成本高,上线周期长。
如某产品线治理改造花了 2 个季度完成;推荐某类召回服务经常出现超时、重试配置等不合理的问题,集中管理调整成本比较高。
3.可观测性不足,是否有通用机制提升产品线可观测性?
比如某推荐业务缺少整体模块调用关系链和流量视图,线上故障靠人肉经验定位、新机房搭建周期长,效率低。
二、service mesh 解决什么问题?
为彻底解决当前业务服务治理的痛点和问题,我们引入了 service mesh,基本思路解耦治理能力和框架,治理能力下沉到 sidecar。内部联合多个部门通过合作共建方式建设通用的 service mesh 架构, 提供通用的基础稳定性能力和统一的流量控制接口。
我们期望 service mesh 在厂内业务落地解决什么问题?总结为两点:
1、基础稳定性能力的关键组件 – 为微服务提供通用的基础故障容错能力、基础故障检测能力、统一的干预和控制接口;
2、流量治理的核心系统 – 实现各产品线整体的连接托管、全局流量的可观测、精细调度能力;
附 service mesh 定义:Linkerd CEO William Morgan 于 2016 年 9 月 29 日公开提出,service mesh 是用于处理服务间通信的基础设施层,用于在云原生应用复杂的服务拓扑中实现可靠的请求传递。在实践中,service mesh 通常是一组与应用一起部署,但对应用透明的轻量级网络代理。
三、技术挑战
我们在落地 service mesh 实际过程中,面临以下几大挑战:
· 低侵入:百度大大小小有上百个产品线,模块数量级达到万级别,实例数达到百万级别,如何让业务在不改代码前提下无缝迁移,低侵入接入是我们在设计方案考虑第一要素;
· 高性能:百度核心产品线在线服务对延迟要求极高,比如推荐、搜索等核心产品线,延迟上涨几毫秒会直接影响用户的体验和公司收入,从业务角度不能接受接入 mesh 后带来的性能退化。因此我们在落地过程中,投入很大精力来优化 mesh 的延迟,降低接入 mesh 后的性能损耗;
· 异构系统融合:首先我们需要解决厂内多语言框架互通问题,其次需要统一接口和协议,打通厂内多个服务治理系统,如服务发现、流量调度、故障止损等系统;
· mesh 可靠性:在线业务对可靠性要求极高,要求我们在落地过程中,充分考虑自身稳定性,避免出重大 case。
总结:我们的需求是实现一套低侵入、高性能、完备的治理能力,能够解决业务实际问题 service mesh 架构。
四、整体架构
· 技术选型:我们底层以开源 istio+envoy 组件为基础,基于厂内实际业务场景,适配厂内组件。选择基于开源定制的主要原因是兼容社区,跟开源保持标准协议,吸收社区的高级 feature 同时能够反哺到社区。
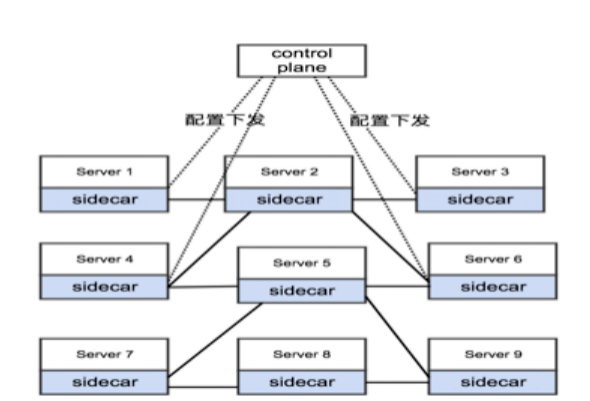
我们内部落地的 mesh 整体架构如下 ,包括以下核心组件:
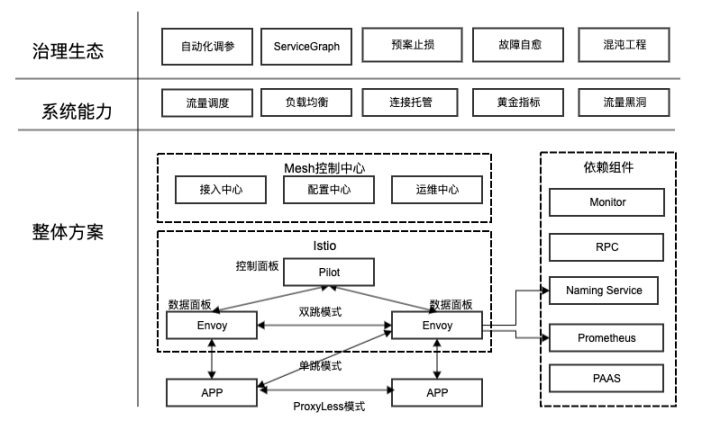
· Mesh 控制中心:
· 接入中心:sidecar 的注入,管理 sidecar 版本,统一上线入口;
· 配置中心:稳定性治理和流量治理入口,托管连接、路由配置、通信等策略;
· 运维中心:mesh 的日常运维,如干预去劫持操作;
· 控制面板:istio-pilot 组件,负责路由管理、通信策略等功能;
· 数据面板:envoy 组件,负责流量转发、负载均衡等功能;
· 依赖组件:融合厂内服务发现组件 naming service、内部各种 rpc 框架适配、监控系统、底层 paas 支持;
· 周边治理生态:基于 mesh 统一治理接口衍生出的服务治理生态,如智能调参系统、 故障自动定位 &止损系统、故障治愈、混沌工程(基于 mesh 的精细化故障注入)。
接下来我们从接入方式、性能优化、稳定性治理、流量治理、周边系统协同、稳定性保障等关键技术来解析:
4.1 接入方式
社区采用的 iptables 流量劫持方案, iptables 规则过多会导致性能问题,尤其在厂内数万个实例转发下受限 iptables 线性匹配规则,转发延迟非常大,不能满足在线低延迟的场景。
我们的解决思路:基于本地 lookbackip 地址方案,envoy 打通内部服务发现组件,劫持服务发现请求,通过回传 lookback 地址透明劫持业务流量。同时本地 naming agent 定期探活 envoy,一旦 envoy 出现异常,自动回退到直连模式,避免 envoy 故障导致流量丢失。
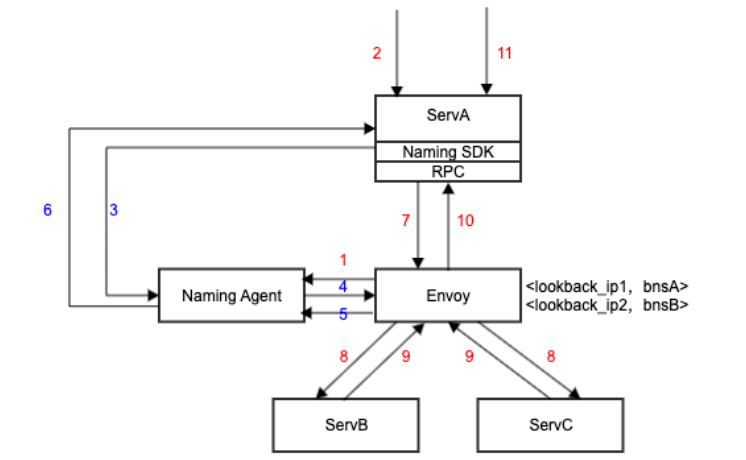
同时针对一些不走流量劫持的业务,我们设计了 proxyless 方案,即通过 rpc 框架适配 istio 标准的 xds,接入 pilot 服务治理的通路,托管服务治理策略和参数分发生效。无论业务流量是否被劫持,都通过 mesh 标准化的干预入口实现服务治理的统一管控和治理。目前 proxyless 方案已在内部 c++等 rpc 框架完成适配,在搜索、推荐等业务线落地。
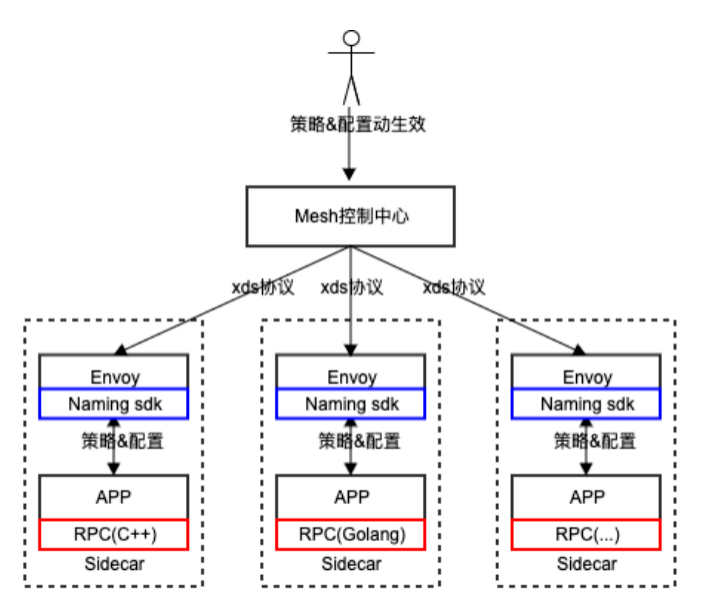
总结:我们通过基于服务发现流量劫持和 proxyless 两种透明迁移的的接入方案,实现业务模块无需修改代码即可接入 mesh 的低侵入方式,降低业务接入 mesh 的成本。
4.2 性能极致优化
我们在落地过程发现社区版本 envoy 延迟、资源消耗较大,在一些大扇出复杂场景下,流量劫持带来的延迟上涨接近 5ms,cpu 消耗占比 20%以上,无法满足厂内在线业务高吞吐、低延迟场景。我们分析 evnoy 底层模型,本质原因是 envoy 是一个单进程多线程的 libevent 线程模型,一个 event-loop 只能使用一个核,一个回调卡住就会卡住整个线程,容易产生高延时,导致吞吐长尾控制能力比较差。
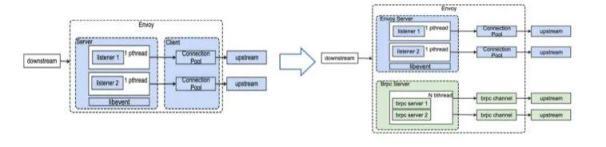
我们基于 envoy 扩展接口扩展 envoy 的网络模型 &线程模型,引入 brpc 底层高性能的 bthread 协程模型 。在我们内部简称高性能 brpc-envoy 版本。同时我们打通 pilot,实现原始 libevent 和 brpc-thread 在线切换,用户可以非常方便自助选择开启高性能模型。备注:brpc 百度内部 c++ 高性能 rpc 开源框架,内部数几十个产品线再使用,实例数有数百万规模,已开源。
测试下来结果,相比开源社区版本和 MOSN(蚂蚁自研已开源)等业界框架, CPU 降低 60%+,平均延迟降低 70%+,长尾延迟平均降低 75%+,性能大幅领先业界,彻底解决社区版 envoy 无法满足大规模工业高性能场景的问题,为大规模落地 mesh 扫清障碍。
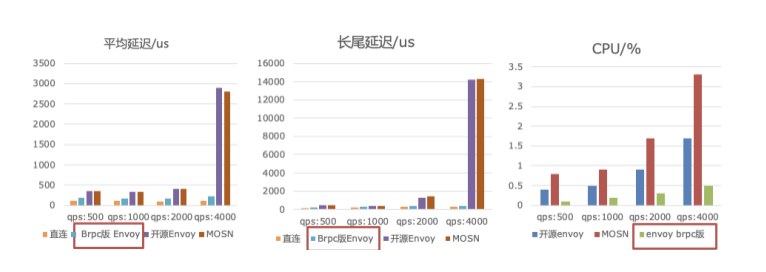
同时我们正在调研 ebpf、dpdk 等新技术,进一步降低延迟和资源消耗。目前测试下来 ebpf 相比本地 lookbackip 转发性能有 20%的提升,dpdk 相比内核协议栈有 30%的性能优化空间(在绑核条件下)。
4.3 稳定性治理
内部在线 &离线服务大规模混部,线上混部环境复杂,对模块的架构稳定性能力要求比较高。我们基于 mesh 提供通用的故障容错能力、故障检测能力、统一的干预和降级能力来整体提升产品线稳定性能力的 baseline:
4.3.1 局部故障容错能力:
为了提升架构对日常机器故障的容错能力,我们基于 envoy 扩展了高级稳定性容错策略,比如增加动态重试熔断策略,通过滑动窗口计算分位值耗时,动态控制重试比例,通过重试捞回请求同时也避免大量重试引发雪崩的风险。另外我们引入反馈式的高级负载均衡策略,根据下游返回定制的错误码,降权 &屏蔽故障实例,通过熔断保护机制控制权值,避免正常实例被打挂。在我们内部核心产品线上线后,大幅提升模块在局部故障下的容错能力,架构韧性能力大大提升。
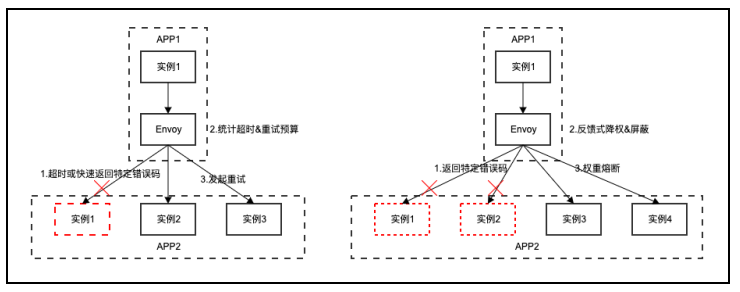
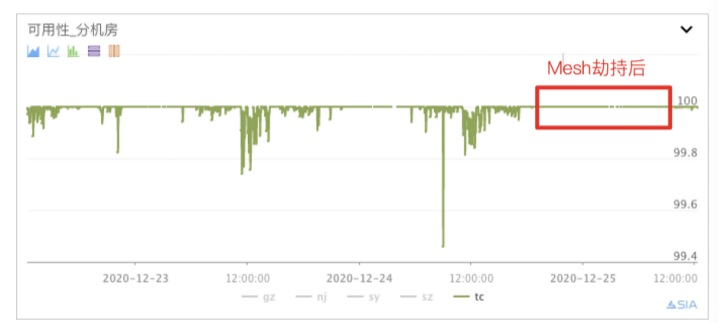
(参考下图,某在线核心模块接入 mesh 后,可用性从之前 2 个 9 提升到 4 个 9)
针对雪崩治理场景(我们统计厂内核心产品线雪崩历史 case,90%以上 case 都是雪崩治理能力缺失,比如重试风暴、超时倒挂、降级能力缺失导致),我们基于 mesh 定制熔断能力的高级重试能力来抑制重试风暴,提供动态超时机制来预防超时倒挂。在核心产品线的大范围铺开后,覆盖近 2 年内雪崩 90%+故障场景, 2020 年雪崩 case 对比 2019 年雪崩类 case 损失环比下降了 44%
4.3.2 局部故障检测能力:
过去故障检测依赖机器粒度的基础指标,粒度比较粗,针对容器故障实例缺乏精细指标检测,无法及时探测到故障实例,通常需要数小时才会检测到故障实例。我们打通了上层故障自愈系统,基于 envoy 扩展故障检测策略,提供通用、快速直接的故障发现检测能力,外部故障自愈系统通过 prometheus 接口采集故障实例,经过汇聚分析,触发 paas 迁移故障实例。对于已接入 mesh 的业务线,几乎零成本代价下即可具备局部异常的快速发现 &定位能力,故障实例的检测时效性从原来数小时优化到分钟级。
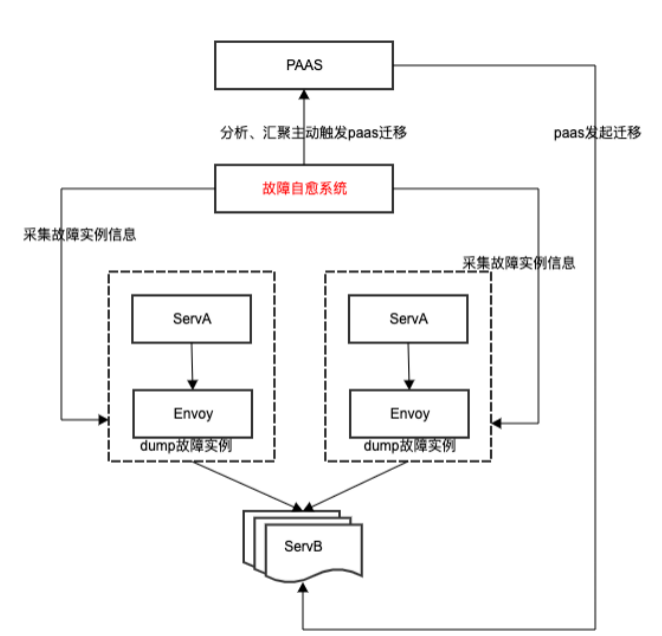
4.3.3 统一的干预和降级能力:
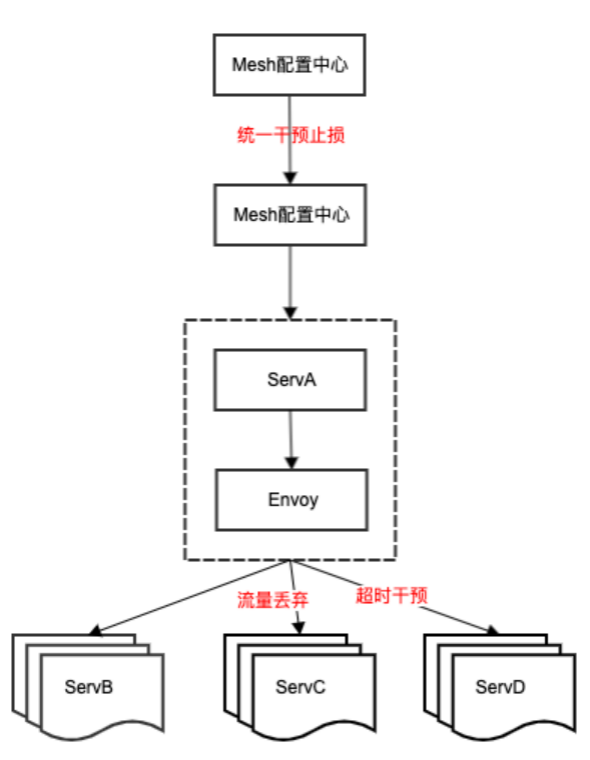
对于一些大规模故障,单靠架构自身容错解决不了,需要依赖稳定性预案去止损,比如典型的下游弱依赖摘除预案。过去依赖不同产品线和模块自身去建设降级能力,不同模块接口方案差异大,随着系统不断迭代,降级能力可能出现退化,运维成本和挑战比较大。我们结合 mesh 实现通用降级和干预能力,如支持多协议场景下流量丢弃能力,实现统一的流量降级策略;通过统一的超时和重试干预能力,实现秒级的干预时效性。
通过落地 mesh 为多产品线提供统一的干预和控制接口,为稳定性预案提供一致的操作接口,大大提升了服务治理效率,产品线服务治理迭代周期从过去季度级缩短到月级。
如 20 年某业务线接入 mesh 两周完成 4 个方向 20+模块架构治理改造,而原来往往需要一个季度周期才能完成改造。
4.4 流量治理能力
· 流量可观测性:
过去构建产品线模块上下游调用链和基础黄金指标一直缺乏通用的解决方案,大多数都是基于 rpc 框架或者业务框架定制,模块调用链和黄金指标覆盖率低。比如某重要产品线端到端涉及到 2000 多个模块,调用链关系十分复杂,具体流量的来源不够透明,严重影响运维效率。如机房搭建不知道上下游的连接关系,靠人肉梳理误差大,某产品线一次搭建周期将近 2 个月时间。另外故障定位、容量管理等由于全局的可观测性不足,往往只能依赖经验定位,效率十分低下。
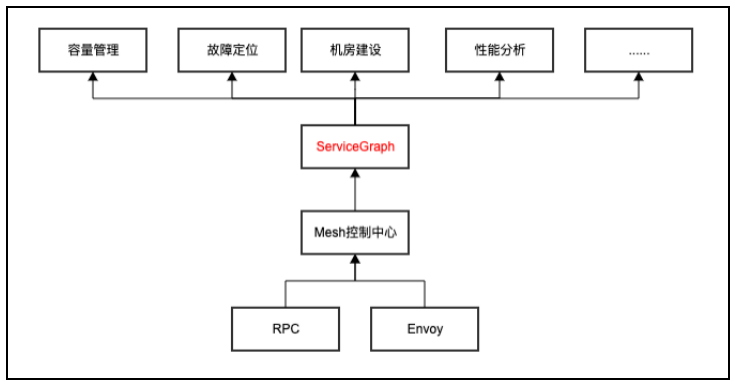
我们整体思路以 mesh 为中心,结合周边 rpc 框架,构建全局 servicegraph 调用链。
· 一方面通过 istio 内部 crd 抽象表达出模块链路关系和链路属性,在 istio 上层自建 mesh 配置中心,屏蔽底层 crd 细节。以配置中心作为连接托管的唯一入口,托管模块全链路的调用关系,新机房建设基于 servicegraph 快速构建出新机房的拓扑,很大程度提升机房搭建效率,缩短周期。
· 另一方面同时结合 brpc 和 mesh,制定标准的黄金指标格式,建设统一的黄金指标数据仓库,支持上游的服务治理建设,比如容量管理分析、故障定位、性能分析、故障注入等。比如我们正在落地的故障自感知、止损系统基于 servicegraph 可自动化、快速、准确实现线上故障的感知、止损。
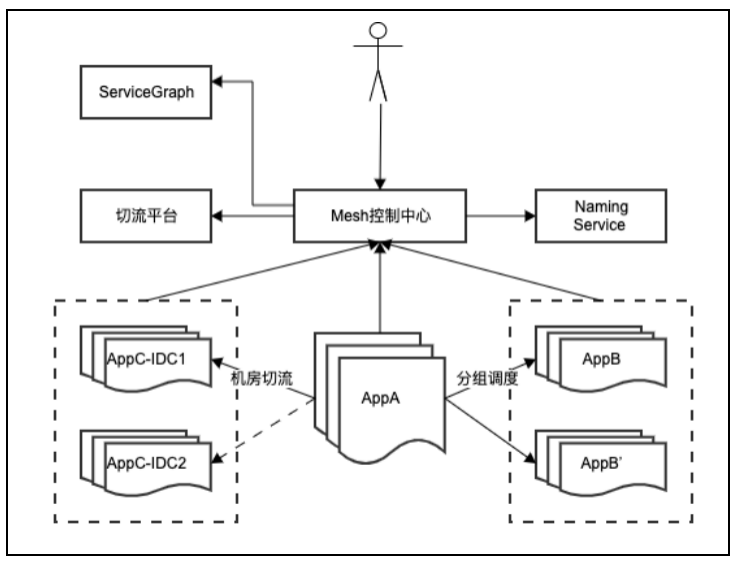
· 流量精细调度:
厂内大部分产品线基于入口整体切流,一直缺乏对模块链路内部流量精细调度控制能力。我们结合 mesh 的流量调度能力,打通厂内服务发现组件,整合一系列切流平台,统一流量调度入口到 mesh 控制中心。结合前面 servicegraph 提供的全局调用链,实现模块精细连接关系的流量调度能力;另外我们基于 mesh 实现模块实例粒度精细流量调度和流量复制能力,典型应用于模块的精细流量评估、线下压测、导流场景下。
4.5 周边生态协同
基于 mesh 提供统一的控制接口,衍生出周边服务治理系统,典型场景如治理参数自动调参、故障自动止损、故障自愈等系统。
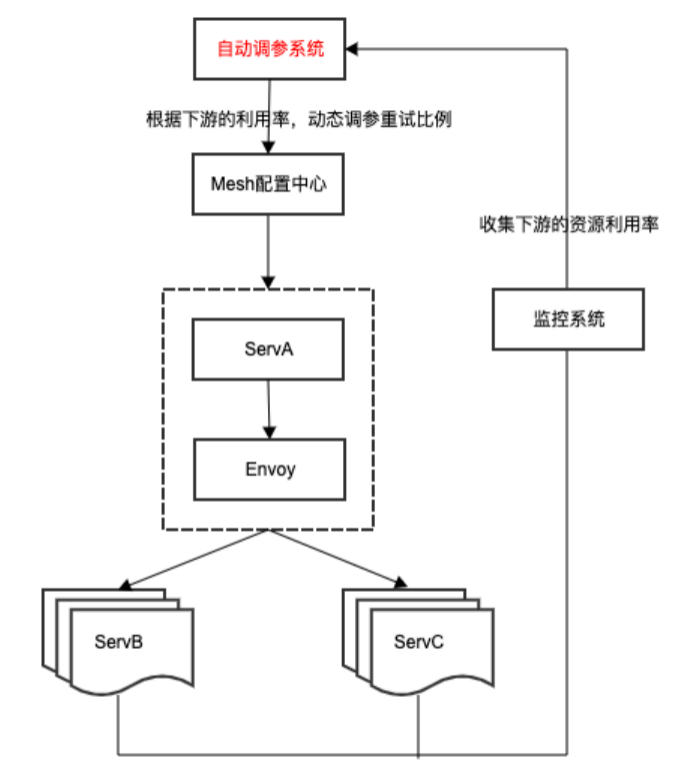
· 自动调参系统
服务治理参数依赖用户手工配置参数(超时比例、权重比例等),完全依赖人肉经验,频繁出现配置不合理影响治理能力效果,同时线上环境差异比较大,静态配置无法适应线上复杂环境变化。我们设计出一套动态调参系统,核心思路基于 mesh 的治理统一接口和结合线上指标实时反馈,实时调整治理参数。比如根据下游 CPU 利用率,动态调参访问下游重试分位值比例;根据下游机器负载差异化,动态调参访问下游权重。
在厂内核心产品线落地后,通过自动调参完全代替人肉调参,实现服务治理参数自适应调整。
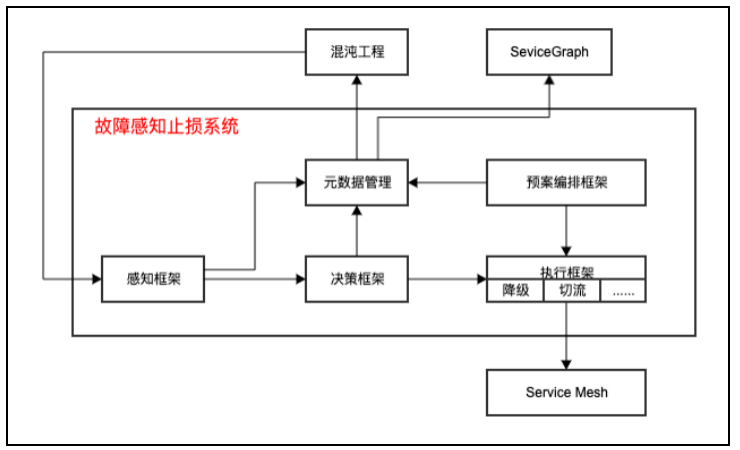
· 故障自动感知止损系统
传统线上故障凭人工经验定位,产品线深度定制预案能力,强依赖有经验的工程师,新人上手成本高;并且预案止损操作散落在文档中,可维护性差,随着业务迭代可能失效或者逐步退化,不可持续。
我们基于 mesh 通用的干预能力和统一控制接口,研发一套故障预案自动止损系统,结合前面提到的 service graph 提供全局调用链和黄金指标,实现常见故障的自动感知、预案自动止损,降低故障止损的 mttr 时间。同时打通混沌工程,定期端到端注入故障触发预案演练,避免预案能力退化。这套系统目前典型应用在强弱依赖降级、精细化流量调度等预案场景,预计到年底,接入 mesh 的产品线大部分线上故障都能自动化处理。
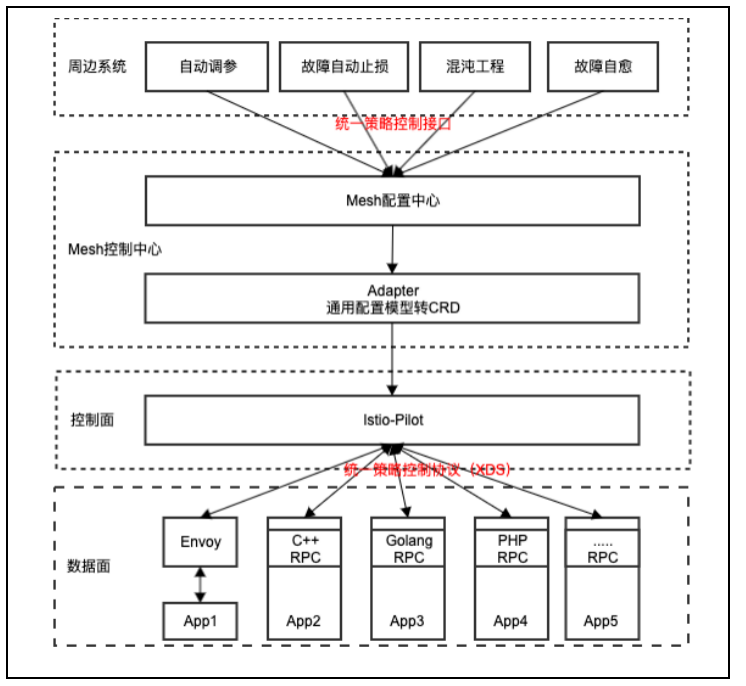
· 统一协议,协同周边系统
基于 mesh 配置中心提供标准的流量控制和服务治理接口(如流量降级接口),协同周边系统生态,如自动调参、故障感知止损、故障自愈、流量调度。
基于开源 xds 协议,统一数据面协议,对接周边 rpc 框架,实现不同 rpc 框架能够统一控制。
4.6 自身稳定性保障
厂内业务比如搜索、推荐等关键业务对稳定性要求极高,在线迁移 mesh 好比”高速公路上换车轮“,必须保证对业务无损。因此稳定性建设是我们在落地 mesh 过程重点关注点之一。
首先我们通过多级兜底机制保障流量转发的可靠性。针对局部故障,如个别 envoy 实例配置、进程等异常,envoy 自身具备 fallback 机制,异常可以自动回退直连模式,无需人工介入。但一些大规模故障,比如 envoy 出现大范围故障,靠 envoy 自身机制已经无法保证(可能出现劫持、非劫持模式来回波动),我们通过外部干预平台一键下发转发黑名单,强制干预 envoy 切到直连模式,全产品线止损时效性控制在 5 分钟以内;极端情况下,如 envoy 大范围 hang 死,可能导致对外干预接口失效,我们准备了兜底预案,联动 paas 批量强制杀掉 envoy 进程,回退到直连模式。
其次在服务治理配置发布方面,我们核心思路控制故障隔离域,比如打通 mesh 配置中心,灰度控制配置发布的百分比;同时构建 mesh 接入一站式平台,梯度逐步发布,控制 envoy 升级对业务的影响面。我们引入 monitor 模块定期做端到端巡检,如配置一致性、envoy 节点服务异常、版本一致性等校验。
最后我们定期通过混沌工程主动注入故障,比如模拟 envoy 异常、pilot 异常、配置中心异常等,进行极限异常 case 演练,避免自身稳定性架构能力退化。
五、总结
从 19 年年底开始立项,不到 2 年的时候,在内部数十个产品线已完成落地,其中一些核心产品线主干模块已覆盖到 80%以上,天级托管流量超过千亿。新接入模块几乎零成本接入,即可具备基础稳定性治理和流量调度能力。我们结合周边生态系统,构建一站式 mesh 接入平台,为各业务线提供低侵入、低成本、标准化的服务治理解决方案,系统性解决各个产品线的基础可用性问题,大幅降低治理迭代成本 &周期,促进体系整体稳定性能力的提升。
招聘信息
如果你对微服务感兴趣,请你联系我,我们当面聊聊未来的 N 种可能性。无论你是后端,前端 ,大数据还是算法,这里有若干职位在等你,欢迎投递简历,关注同名公众号百度 Geek 说,输入内推即可,我们期待你的加入!
推荐阅读
---------- END ----------
百度 Geek 说
百度官方技术公众号上线啦!
技术干货 · 行业资讯 · 线上沙龙 · 行业大会
招聘信息 · 内推信息 · 技术书籍 · 百度周边
欢迎各位同学关注
版权声明: 本文为 InfoQ 作者【百度Geek说】的原创文章。
原文链接:【http://xie.infoq.cn/article/361258f7cb065882c6655bade】。
本文遵守【CC-BY 4.0】协议,转载请保留原文出处及本版权声明。

百度官方技术账号 2021.01.22 加入
关注我们,带你了解更多百度技术干货。









评论