Uber 多区域 Kafka 的灾难恢复
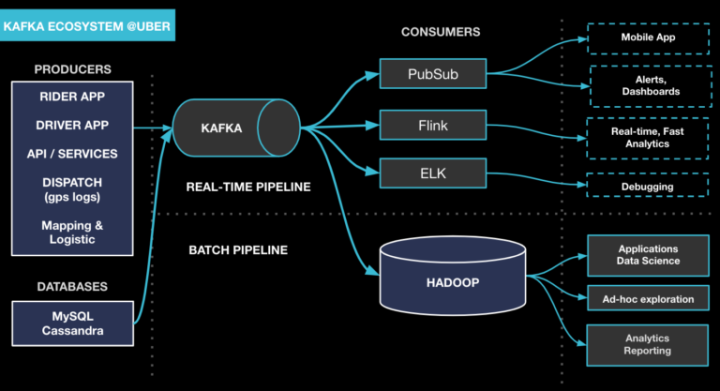
优步的 Apache Kafka
优步拥有世界上最大的 Apache Kafka 部署之一,每天处理数万亿条消息和数 PB 的数据。如上图所示,今天我们将 Apache Kafka 定位为 Uber 技术堆栈的基石,并在其之上构建一个复杂的生态系统,以赋能大量不同的工作流。其中包括发布/订阅消息总线,用于传递来自乘客和司机应用程序的事件数据,启用流式分析平台(例如 Apache Samza、Apache Flink)、将数据库更改日志流式传输到下游订阅者,以及将各种数据摄取到 Uber 的 Apache Hadoop 数据湖。
为了在 Apache Kafka 之上提供可扩展、可靠、高性能且易于使用的消息传递平台,我们克服了许多挑战。在本文中,我们重点介绍了从集群停机等灾难中恢复的一项挑战,并描述了我们如何在 Uber 构建多区域 Apache Kafka 基础设施。
1000+份计算机paper,卡耐基梅隆大学,哈佛,斯坦福,芝加哥大学,MIT,facebook,google,微软,Amazon,twitter等大牛一作
Uber 的多区域 Kafka
提供业务弹性和连续性是优步的首要任务。灾难恢复计划经过精心制定,以最大限度地减少自然和人为灾难(例如停电、灾难性软件故障和网络中断)对业务的影响。我们采用多区域策略,即在地理分布的数据中心部署服务并进行备份。当一个地区的物理基础设施不可用时,该服务仍然可以在其他地区保持正常运行。
我们构建了一个多区域 Kafka 设置,为区域故障转移支持提供数据冗余。如今,Uber 技术堆栈中的许多服务都依赖 Kafka 来支持区域级故障转移。这些服务位于 Kafka 流的下游,并假设数据在 Kafka 中可用且可靠。
图 2 描绘了多区域 Kafka 的架构。集群有两种类型:生产者在本地将消息发布到 Region Clusters ,然后将来自 Region Clusters 的消息复制到 Aggregate Clusters 以提供全局视图。为简单起见,图 2 仅显示了两个区域中的集群。
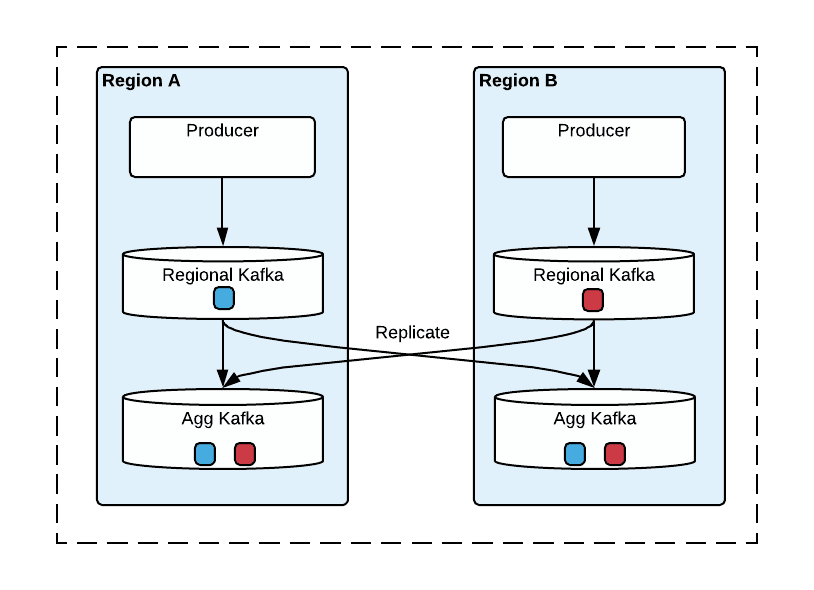
图 2:两个区域的 Kafka 复制拓扑
在每个区域中,生产者总是在本地生产以获得更好的性能,并且在 Kafka 集群不可用时,生产者会故障转移到另一个区域并在该区域的区域集群中生产。
此架构中的一个关键部分是消息复制。消息从区域集群异步复制到跨区域的聚合集群。我们构建了 uReplicator,这是 Uber 的开源解决方案,用于以稳健可靠的方式复制 Apache Kafka 数据。该系统扩展了 Kafka MirrorMaker 的原始设计,专注于极高的可靠性、零数据丢失保证和易于操作。
从多区域 Kafka 集群消费
从多区域消费比生产更复杂。Multi-region Kafka 支持两种类型的 all-active。
主动/主动消费
一种常见的消费类型是主动/主动,其中消费者独立地在每个区域的聚合集群中消费相同的主题。如今,Uber 的许多应用程序都使用主动-主动模式从多区域 Kafka 中消费,并且不直接与其他区域的同行通信。当一个区域出现故障时,如果 Kafka 流在两个区域中都可用并且包含相同的数据,则它们会切换到另一个区域中的对应区域。
例如,图 3 展示了 Uber 的动态定价服务(即激增定价)如何使用双活 Kafka 来构建灾难恢复计划。价格是根据附近地区近期历史上的旅行事件计算得出的。所有的旅行事件都被发送到 Kafka 区域集群,然后聚合到聚合集群中。然后在每个区域中,一个具有大内存占用的复杂 Flink 作业计算不同区域的定价。接下来,一个全活动服务协调区域中的更新服务并分配一个主要区域进行更新。来自主要区域的更新服务将定价结果存储在主动/主动数据库中以供快速查找。
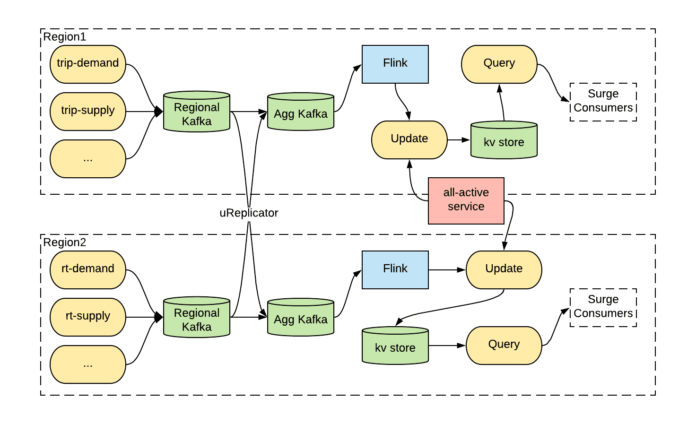
图 3:主动/主动激增定价架构
当灾难袭击主区域时,双活服务会分配另一个区域作为主区域,并将激增定价计算故障转移到另一个区域。需要注意的是,Flink 作业的计算状态太大,无法在区域之间同步复制,因此其状态必须独立于来自聚合集群的输入消息进行计算。
实践中的一个关键洞察是,提供可靠的、多区域可用的基础设施服务,如 Kafka,可以大大简化应用程序业务连续性计划的制定。应用程序可以将其状态存储在基础设施层,从而变为无状态,将状态管理的复杂性(如跨区域同步和复制)留给基础设施服务。
主动/被动消费者
另一种多区域消费模式是主动/被动:一次只允许一个消费者(由唯一名称标识)从其中一个区域(即主要区域)的聚合集群中进行消费。多区域 Kafka 跟踪其在主要区域的消费进度,由偏移量表示,并将偏移量复制到其他区域。因此,在主要区域发生故障时,主动/被动模式允许消费者故障转移到另一个区域并恢复其消费。主动/被动模式通常用于支持更强一致性的服务,例如支付处理和审计。
主动/被动模式对区域间消费者的偏移同步提出了关键挑战。当消费者故障转移到另一个区域时,它需要采取一个偏移量来恢复进度。因为优步的很多服务不能接受任何数据丢失,消费者无法从高水位恢复(最新的消息),并且为了避免过多的积压,消费者也不能从低水位线(最早的消息)恢复。此外,来自聚合集群的消息在从区域集群聚合后可能会变得乱序。由于跨区域复制延迟,消息从区域集群复制到本地聚合集群的速度比远程聚合集群快。因此,聚合集群中的消息顺序可能不同。例如,在图 4a 中,消息 A1、A2 和 B1、B2 几乎同时发布到区域 A 和区域 B 的区域集群,但聚合后它们在两个聚合集群中的顺序不同。
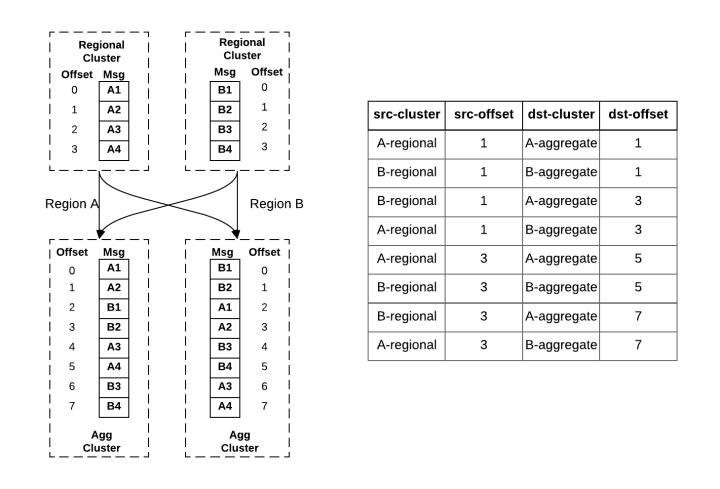
图 4:跨区域消息复制示例 b.消息复制的检查点
为了管理跨区域的此类偏移映射,我们在 Uber 开发了复杂的偏移管理服务。架构如图 5 所示。当 uReplicator 将消息从源集群复制到目标集群时,它会定期检查从源到目标的偏移映射。例如,图 4b 的右侧显示了图 4a 左侧的消息复制的存储偏移映射。表的第一行记录了 Region A 的区域集群中偏移量 1(0 索引)处的消息 A2 映射到区域 A 的聚合集群中偏移量 1 处的消息 A2。同理,表记录的其余行 4 个复制路由中的其他检查点。
偏移管理将这些检查点存储在一个主动-主动数据库中,它可以使用它们来计算给定主动-被动消费者的偏移映射。同时,偏移同步作业会定期为主动-被动消费者同步两个区域之间的偏移。当主动/被动消费者从一个区域故障转移到另一个区域时,消费者可以采用最新的同步偏移量并恢复消费。
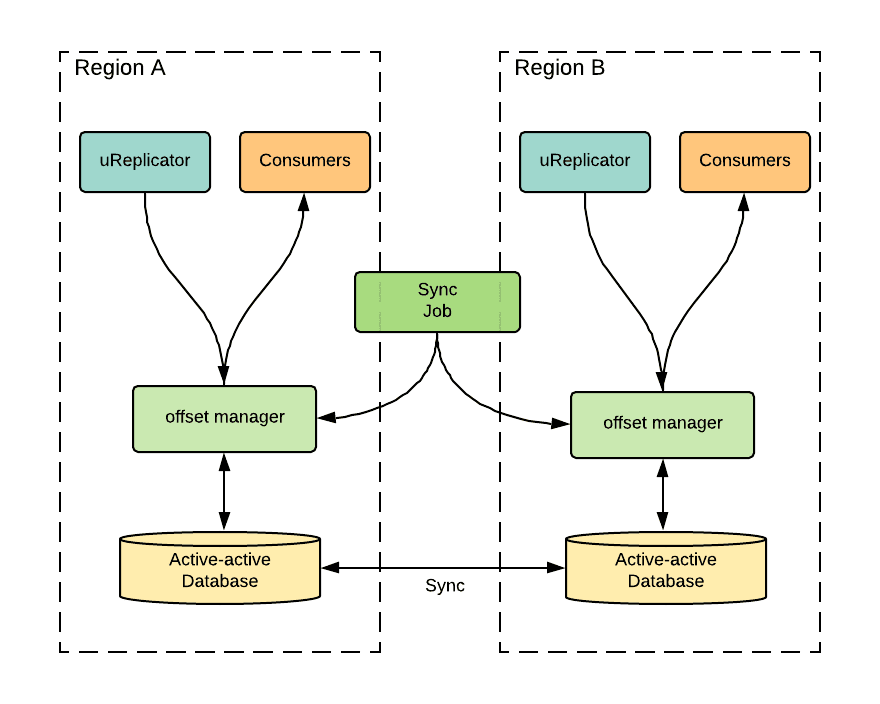
图 5:主动/主动偏移管理服务的架构
偏移映射算法的工作原理如下:在活跃消费者的聚合集群上,从每个区域的区域集群中找到所有最新的检查点。然后,对于每个检查点中的源偏移量,找到另一个区域中聚合集群的检查点。最后,它采用被动区域的聚合集群中检查点偏移量的最小偏移量。
在图 6 的例子中,假设活跃消费者的当前进度在 Region B 的聚合集群中消息 A3 的偏移 6 处。 根据右侧的检查点表,聚合集群上最近的两个检查点是 A2 的偏移 3(蓝色)和 B4 在偏移量 5(红色)处,偏移量 1(蓝色)的源分别位于区域 A 的区域集群中,偏移量 3(红色)的源分别位于区域 B 的区域集群中。这些源偏移量映射到区域 A 中偏移量 1(蓝色)和偏移量 7(红色)处的另一个聚合集群。通过算法,被动消费者(黑色)应取两者中较小的偏移量,即偏移量 1。
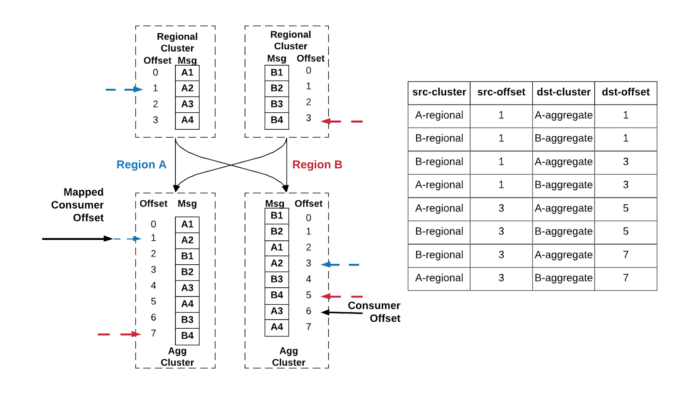
图 6:主动/被动使用者从一个区域故障转移到另一个区域的示例。消息复制的检查点
自成立以来,偏移管理服务对于管理偏移映射很有价值,不仅对于消费者从一个区域到另一个区域的故障转移,而且对于我们将在以后的文章中讨论的其他几个关键用例。
结论
在优步,业务连续性取决于跨服务的高效、不间断的数据流,而 Apache Kafka 在公司的灾难恢复计划中发挥着关键作用。在本文中,我们简要介绍了 Uber 多区域 Apache Kafka 设置的整体架构,以及灾难发生时跨区域的不同故障转移策略。但是,目前摆在我们面前的是更具挑战性的工作,即解决更细粒度的恢复策略,该策略可以容忍单个集群灾难而无需区域故障转移。
本文来自:Uber.

直奔腾讯去,一起学习:Q群654378476 2021.05.20 加入
我要学完第十代《Linux C/C++服务架构开发》知识体系里的内容,直奔腾讯去,一起学习:Q群654378476 系统学习免费课程:https://ke.qq.com/course/417774?flowToken=1033508









评论