万字长文轻松彻底入门 spring,GitHub 已标星 16k
Redis 主从复制
概念
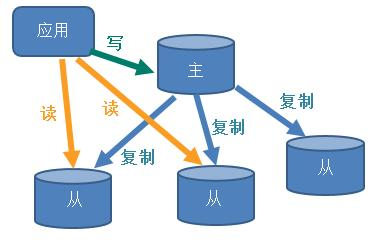
Redis 的主从复制概念和 MySQL 的主从复制大概类似。一台主机master,一台从机slaver。master 主机数据更新后根据配置和策略,自动同步到 slaver 从机,Master 以写为主,Slave 以读为主。
主要用途
读写分离:适用于读多写少的应用,增加多个从机,提高读的速度,提高程序并发数据容灾恢复:从机复制主机的数据,相当于数据备份,如果主机数据丢失,那么可以通过从机存储的数据进行恢复。高并发、高可用集群实现的基础:在高并发的场景下,就算主机挂了,从机可以进行主从切换,从机自动成为主机对外提供服务。
一主多从配置
环境准备
老哥太穷了,就用一台机器模拟三个机器。
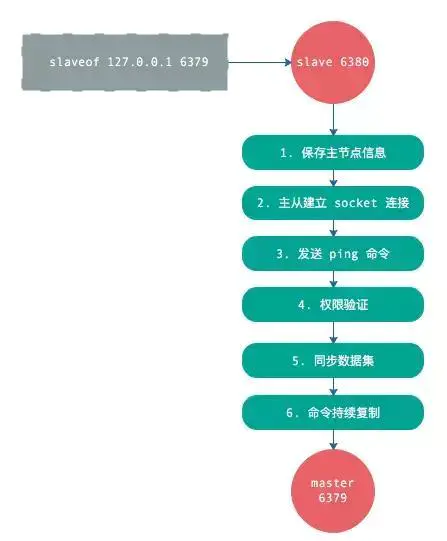
第一步:将 redis.conf 复制 3 份,分别是 redis6379.conf、redis6380.conf、redis6381.conf第二步:修改三个 redis.conf 文件里的 port 端口、pid 文件名、日志文件名、rdb 文件名第三步:分别打开三个窗口模拟三台服务器,并开启 redis 服务。
查看当前 3 台机器主从角色
先用命令info replication看看 3 台机器目前的角色是什么。
设置主从关系
这里注意,我们只设置从机就可以了,不用设置主机。我们选择6380和6381作为从机。6379作为主机。
再次查看 3 台机器目前角色
再次执行命令:info replication
搭建成功,试验一把
全量复制:从机会把主机之前的数据全部都同步过来,大家可以在从机上 get 某 key 试试。增量复制:当主机新增数据时,从机会将该新增数据同步过来,大家可以在主机上执行命令 set key value,然后在从机上 get 该 key,看是否能获取到。
读写分离
Redis 的从机默认不允许进行写操作,大家可以在从机上执行命令set key value,会报错。
「呼,好累」,主从复制写的差不多了!!
主从复制原理
全量复制

**「①」**slave 发送 psync,由于是第一次复制,不知道 master 的 runid,自然也不知道 offset,所以发送 psync ? -1
**「②」**master 收到请求,发送 master 的 runid 和 offset 给从节点。
**「③」**从节点 slave 保存 master 的信息
**「④」**主节点 bgsave 保存 rdb 文件
**「⑤」**主机点发送 rdb 文件
并且在**「④」和「⑤」**的这个过程中产生的数据,会写到复制缓冲区 repl_back_buffer 之中去。
**「⑥」**主节点发送上面两个步骤产生的 buffer 到从节点 slave
**「⑦」**从节点清空原来的数据,如果它之前有数据,那么久会清空数据
**「⑧」**从节点 slave 把 rdb 文件的数据装载进自身。
全量复制的开销
**「①」**bgsave 时间
**「②」**rdb 文件网络传输时间
**「③」**从节点清空数据的
**「④」**从节点加载 rdb 的时间
**「⑤」**可能的 aof 重写时间,这是针对从节点,例如开启了 aof 之后,从节点添加 buffer 数据时候,可能需要 aof 重写
基于上面的原因,有的情况下不适合使用全量复制,例如网络抖动之后,从节点只需要传送一部分数据,不需要传送全部数据,redis2.8之后实现了部分复制功能
部分复制
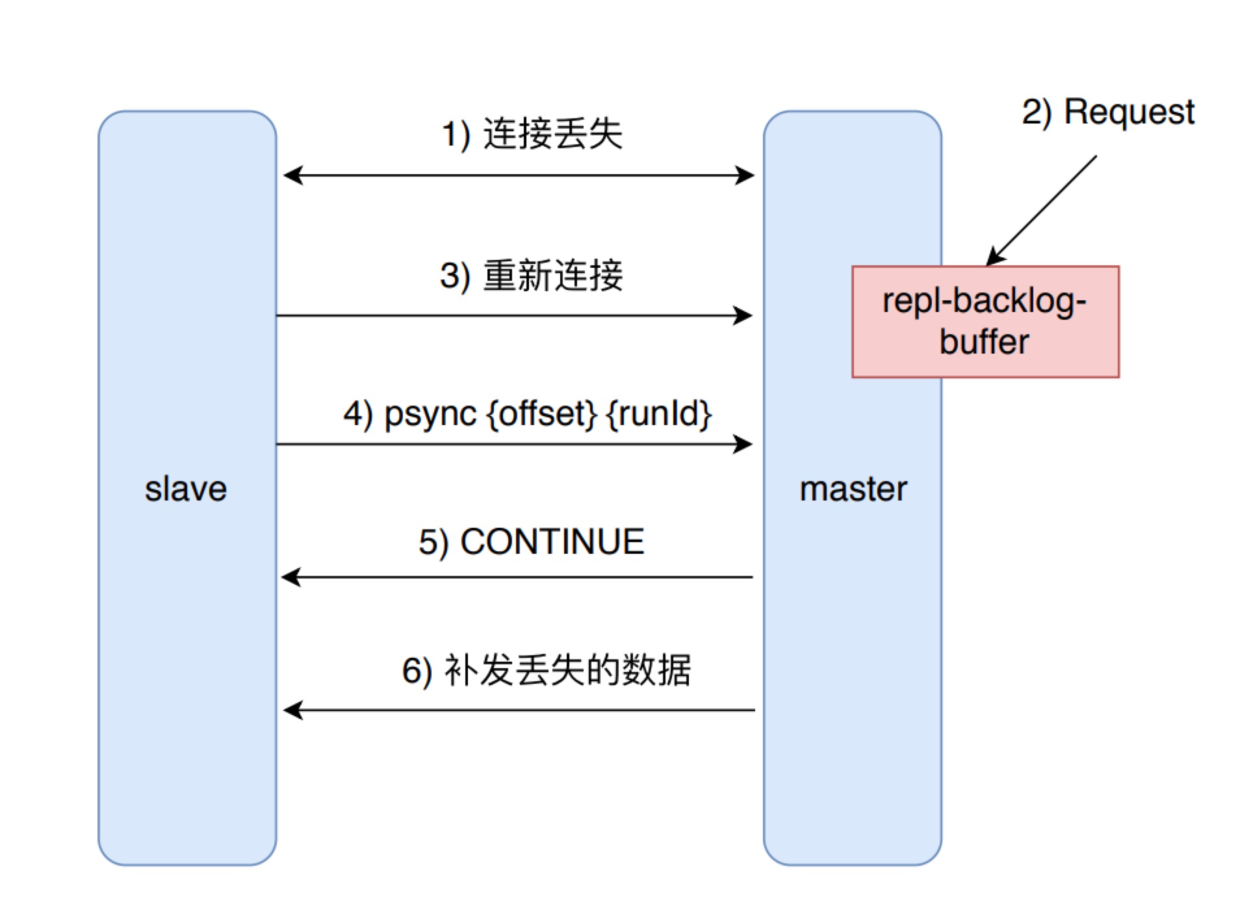
**「①」**假设发送网络抖动或者别的情况,暂时失去了连接
**「②」**这个时候,master 还在继续往 buffer 里面写数据
**「③」**slave 重新连接上了 master
**「④」**slave 向 master 发送自己的 offset 和 runid
**「⑤」**master 判断 slave 的 offset 是否在 buffer 的队列里面,如果是,那就返回 continue 给 slave,否则需要进行全量复制(因为这说明已经错过了很多数据了)
**「⑥」**master 发送从 slave 的 offset 开始到缓冲区队列结尾的数据给 slave

最后
这份文档从构建一个键值数据库的关键架构入手,不仅带你建立起全局观,还帮你迅速抓住核心主线。除此之外,还会具体讲解数据结构、线程模型、网络框架、持久化、主从同步和切片集群等,帮你搞懂底层原理。相信这对于所有层次的 Redis 使用者都是一份非常完美的教程了。

快速入手通道:(戳这里,免费下载)诚意满满!!!
整理不易,觉得有帮助的朋友可以帮忙点赞分享支持一下小编~
你的支持,我的动力;祝各位前程似锦,offer 不断!!!

VX:Lzzzzzz63 领取资料 2021.07.07 加入
还未添加个人简介









评论