在阿里做了 3 年码农,竟然不知道 JDK 和 JRE 背后的秘密,我慌了

今日分享开始啦,请大家多多指教~
这篇文章给大家介绍一下 JDK 和 JRE 、final 与 static 、堆和栈;为了保持 JDK 的独立性和完整性,在 JDK 的安装过程中,JRE 也是安装的一部分。所以,在 JDK 的安装目录下有一个名为 jre 的目录,用于存放 JRE 文件。
一、JDK 和 JRE 的区别?
JDK:java development kit (java 开发工具)
JRE:java runtime environment (java 运行时环境)
JVM:java virtuak machine (java 虚拟机)

1、jdk--开发环境(核心)
Java development kit 的缩写,意思是 Java 开发工具,我们写文档做 PPT 需要 office 办公软件,开发当然需要开发工具了,说到开发工具大家肯定会想到 Eclipse,但是如果直接安装 Eclipse 你会发现它是运行不起来 是会报错的,只有安装了 JDK,配置好了环境变量和 path 才可以运行成功。这点相信很多人都深有体会。
jdk 主要包含三个部分:
第一部分是 Java 运行时环境,JVM
第二部分是 Java 的基础类库,这个类库的数量还是相当可观的
第三部分是 Java 的开发工具,它们都是辅助你更好地使用 Java 的利器
2、jre--运行环境
① jdk 中的 jre
如下图:jdk 中包含的 jre,在 jre 的 bin 目录里有个 jvm.dll,既然 JRE 是运行时环境,那么运行在哪?肯定是 JVM 虚拟机上了。另,jre 的 lib 目录中放的是一些 JAVA 类库的 class 文件,已经打包成 jar 文件。
② 第二个 JRE(独立出来的运行时环境)
如下图,不管是 JDK 中的 JRE 还是 JRE 既然是运行时环境必须有 JVM。所以 JVM 也是有两个的。
3、JVM——转换环境
java virtuak machine (java 虚拟机)的缩写。
大家一提到 JAVA 的优点就会想到:一次编译,随处运行,说白了就是跨平台性好,这点 JVM 功不可没。
Java 的程序也就是我们编译的代码都会编译为 class 文件,class 文件就是在 jvm 上运行的文件,只有 JVM 还不能完全支持 class 的执行,因为在解释 class 的时候 JVM 需要调用解释所需要的类库 lib,而 jre 包含 lib 类库。
JVM 屏蔽了与具体操作系统平台相关的信息,使得 Java 程序只需生成在 Java 虚拟机上运行的目标代码(字节码),就可以在多种平台上不加修改的运行。
JVM 也是一门很深的学问,感兴趣的同学可以深入研究,只有好处,没有坏处。
其实有时候面试官问 JDK 和 JRE 的区别的目的不是想让你解释什么名词的,而是想看看你的基础和研究 Java 的深浅,还有另一方面就是你是不是经常喜欢问为什么。
二、final 与 static 的区别?
都可以修饰类、方法、成员变量
static 可以修饰类的代码块,final 不可以
static 不可以修饰方法内局部变量,final 可以
static 修饰表示静态或全局
static 修饰的代码块表示静态代码块,当 JVM 加载类时,只会被创建一次
static 修饰的变量可以重新赋值
static 方法中不能用 this 和 super 关键字
因为 this 代表的是调用这个函数的对象的引用,而静态方法是属于类的,不属于对象,静态方法成功加载后, 对象还不一定存在。 this 代表对本类对象的引用,指向本类已创建的对象。 super 代表对父类对象的引用,指向父类对象。 静态优先于对象存在,方法被 static 修饰之后,方法先存在,所需的父类引用对象晚于该方法的出 现,也就是 super 所指向的对象还没出现,当然就会报错。
static 方法必须被实现,而不能是抽象的 abstract
static 方法只能被 static 方法覆盖
final 修饰表示常量、一旦创建不可被修改
final 标记的成员变量必须在声明的同时赋值,或在该类的构造方法中赋值,不可重新赋值
final 方法不能被子类重写
final 类不能被继承,没有子类,final 类中的方法默认是 final 的
final 不能用于修饰构造方法
private 类型的方法默认是 final 类型的
三、final 与 static 的区别
get 和 post 是表单提交的两种方式,get 请求数据通过域名后缀 URL 传送,用户可见,不安全,post 请求数据通过在请求报文正文里传输,相对比较安全。get 是通过 URL 传递表单值,post 通过 URL 看不到表单域的值。
get 传递的数据量是有限的,如果要传递大数据量不能用 get,不如 type=“file”上传文章、type=“password”传递密码,get 和 post 是表单提交数据的两种方式,get 请求数据通过地域名后缀 URL 传送,用户可见,不安全,post 请求数据通过将在请求报文正文里传输,相对比较安全。
get 是通过 url 传递表单值,post 通过 url 看不到表单域的值;
get 传递的数据量是有限的,如果要传递大数据量不能用 get,比如 type=“file”上传文章、type=“password”传递密码或者< text area >发表大段文章,post 则没有这个限制;
post 会有浏览器提示重新提交表单的问题,get 则没有(加分的回答)
对于 Post 的表单重新敲地址栏再刷新就不会提示重新提交了,因为重新敲地址就没有偷偷提交的数据了。Post 方式的正确的地址很难直接发给别人。
四、get 和 post 的区别
1.get 提交的数据放在 URL 之后,以?分割 URL 和传输数据,参数之间以 &相连,如 EditPosts.aspx?name=test1&id=123456. post 方法是把提交的数据放在 HTTP 包的 body 中。
2.get 提交的数据大小有限制(因为浏览器对 URL 的长度有限制),而 post 方法提交的数据没有限制。
3.get 方式需要使用 request.querystring 来取得变量的值,而 post 方式通过 request.form 来获取变量的值。
4.get 方式提交数据会带来安全问题,比如一个登陆页面,通过 get 提交数据时,用户名和密码将出现在 URL 中,如果页面可以被缓存或者其他人可以访问这台机器 ,就可以从历史记录获得该用户的账户和密码。
get 是从服务器获取数据,post 向服务器传送数据。
get 是把参数数据队列加到提交表单的 action 属性所指的 URL 中,值和表单内各个字段一一对应,在 URL 中可以看到。post 是通过 HTTP post 机制,将表单内各个字段与其内容放置在 HTML.header 内一起传送到 action 属性所指的 URL 地址。用户看不到这个过程。
对于 get 方式,服务器端用 request.querystring 获取变量的值,对于 post 方式,服务器端用 request.form 获取提交的数据
get 传送的数据量较小,不能大于 2KB.POST 传送的数据量较大,一般被默认为不受限制。但理论上,限制取决于服务器的处理能力。
get 安全性较低。post 安全性较高。
五、堆和栈的概念和区别
在说堆和栈之前,先说一下 JVM(虚拟机)内存的划分:
Java 程序在运行时都要开辟空间,任何软件在运行时都要在内存中开辟空间,Java 虚拟机运行时也是要开辟空间的。JVM 运行时在内存中开辟一片内存区域,启动时在自己的内存区域中进行更细致的划分,因为虚拟机中每一片内存处理的方法都不同,所以要单独进行管理。
JVM 内存的划分有五片:
1.寄存器
2.本地方法区
3.方法区
4.栈内存
5.堆内存
我们来重点说一下堆和栈:
栈内存:栈内存首先是一片内存区域,存储的都是局部变量,凡是定义在方法中的都是局部变量,for 循环内部定义的也是局部变量,是先加载函数才能进行局部变量的定义,所以方法先进栈,然后再定义变量,变量有自己的作用于,一旦离开作用域,变量就会被释放。栈内存的更新速度很快,因为局部变量的声明周期都很短。
堆内存:存储的是数组和对象(其实数组就是对象),凡是 new 建立的都是在堆中,堆中存放的都是实体(对象),实体用于封存数据,而且是封存多个(实体的多个属性),如果一个数据消失,这个实体也没有消失,还可以用,所以堆是不会随时释放的,但是栈不一样,栈里存放的都是单个变量,变量被释放了,也就没有了。堆里的实体虽然不会被释放,但是会被当做垃圾,Java 有垃圾回收机制不定时的收取。
下面我们通过一个图例详细讲一下堆和栈:
比如主函数里的语句
int[] arr = new int[3];
在内存中是怎么被定义的:
主函数先进栈,在栈中定义一个变量 arr,接下来为 arr 赋值,但是右边不是一个具体值,是一个实体。实体创建在堆里,在堆里首先通过 new 关键字开辟一个空间,内存在存储数据的时候都是通过地址来实现的,地址是一块连续的二进制,然后给这个实体分配一个内存地址。数组都有一个索引,数组这个实体在堆内存中产生之后每一个空间都会默认的初始化(这是堆内存的特点,未初始化的数据是不能用的,但是在堆里是可以用的,因为初始化过了,但是栈里没有),不同的类型初始化的值不一样,所以堆和栈里就创建了变量和实体:
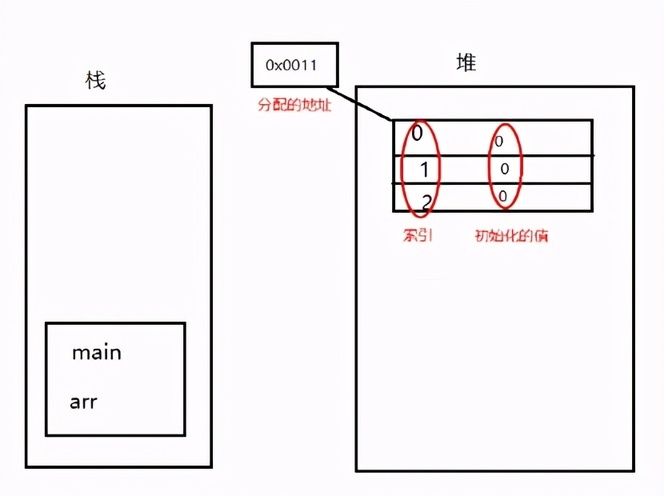
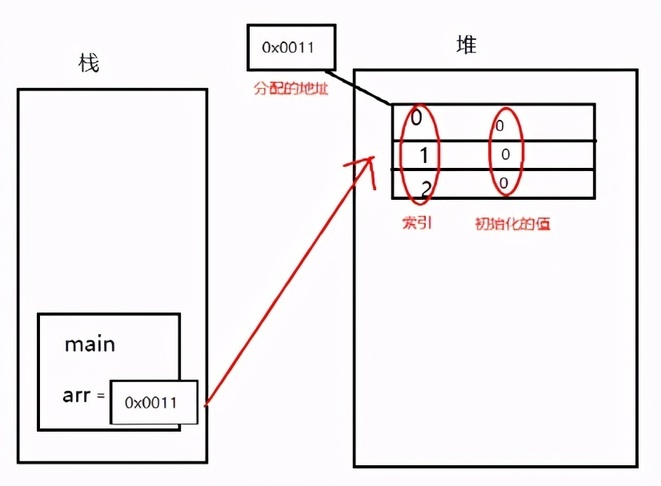
那么堆和栈怎么联系起来的呢?
我们刚刚说过给堆分配一个地址,把堆的地址赋给 arr,arr 就通过地址只想了数组。所以 arr 想操作数组时,就通过地址,而不是直接把四蹄都赋给它。这种我们不再叫它基本数据类型,而叫引用数据类型。称为 arr 引用了堆内存当中的实体
如果当 int[] arr = null;
arr 不做任何指向,null 的作用就是取消引用数据类型的指向。
当一个实体,没有引用数据类型指向的时候,它在堆内存中不会被释放,而被当作一个垃圾,在不定时的时间内自动回收,因为 Java 有一个自动回收机制。自动回收机制自动监测堆里是否有垃圾,如果有,就会自动地做垃圾回收的动作,但是什么时候回收不一定。
所以堆和栈的区别很明显:
1.栈内存存储的是局部变量而堆内存存储的是实体;
2.栈内存的更新速度要快于堆内存,因为局部变量的声明周期很短;
3.栈内存存放的变量声明周期一旦结束就会被释放,而堆内存存放的实体会被垃圾啊回收机制不定时的回收。
六、浅谈 Java 反射机制
1、反射的定义是什么?
Java 反射机制是在运行状态中,对于任意一个类,都能够知道这个类的所有属性和方法;对于任意一个对象,都能够调用它的任意一个方法,这种动态获取、调用对象方法的功能成为 Java 语言的反射机制。
2、反射存在的必要性?
反射机制是很多 Java 框架的基石。
① 在 xml 文件或 properties 里面写好了配置,然后再 Java 类里面解析 xml 或 properties 里面的内容,得到一个字符串,然后用反射机制,根据这个字符串获得某个类的 Class 实例,这样就可以动态配置一些东西,不用每一次都要在代码里去 new 或者做其它事情,以后要改的话直接改配置文件,代码维护起来就很方便了。
② 有时候要适应某些需求,Java 类里面不一定能直接调用另外的方法,这时候也可以通过反射机制来实现。
3、反射的缺点?
反射的代码比正常调用的代码更多,性能更慢,应避免使用反射。
String 中 intern()方法的使用:
jdk6 中:
将这个字符串常量池尝试放入字符串常量池。
如果常量池中有,则不会方法。返回已有的常量池中对象的地址;
如果没有,会把此对象复制一份,放入串池,并返回串池中的对象地址;
jdk7 中:
将这个字符串常量池尝试放入字符串常量池。
如果常量池中有,并不会放入。返回已有的常量池中的对象的地址;
如果没有,会把对象的引用地址复制一份,放入常量池,并返回常量池中的引用地址;
今日份分享已结束,请大家多多包涵和指点!

还未添加个人签名 2021.04.20 加入
Java工具与相关资料获取等WX: pfx950924(备注来源)









评论