
焱融看|非结构化数据场景下,数据湖到底有多香?

当前,云计算、人工智能、物联网等技术在各行各业更加广泛地普及与应用,前沿技术在给社会创造价值以外,也在产生着大量的数据,导致数据的管理和价值挖掘变得愈加复杂和困难。这主要是因为,一方面,数据在不断增长,根据 IDC 的预测,全球数据总量预计到 2025 年将达到 175ZB。据调查,很多企业每年的数据增长量超过了 60%,部分互联网企业的数据量呈现指数式增长;另一方面,数据类型多样,出现了大量文本、图片、音频和视频等非结构化数据。
然而,由于过去缺乏有效的数据处理机制,这些大量的数据,分散于各处,难以管理。因此,如何最大化释放大数据带来的价值,不仅成为各个企业关注的重点,也成为如今让数据湖被高度重视的关键原因。那到底什么是数据湖呢?今天我们就来一探究竟。
什么是数据湖
数据湖是一个被定义为集中且可扩展的存储库,它主要是以本机格式保存来自多个源和系统的大量原始大数据。
举个例子,我们可以把数据湖看作是一个真实的湖,其中汇聚成湖里的水则是原始数据,它们分别从多个数据源流入,然后再流出,用于满足支持内部和面向客户的需求和目的。数据湖比数据仓库更广泛,数据仓库更像是一个家用水箱,它主要是存储“净化水”,也就是结构化数据,且只能用于一个特定的房子,而不是在任何场景下都可以使用的。
数据湖可以使用内部构建的工具,或第三方供应商的软件和服务来执行。根据外研机构 Markets and Markets 的数据,全球数据湖软件和服务市场预计将从 2019 年的 79 亿美元增长到 2024 年的 201 亿美元。预计大量供应商将推动这一增长,包括 Databricks、AWS、Dremio、Qubole 和 MongoDB。当前,已经有许多组织开始提供所谓的 Lakehouse 产品,通过单一产品将数据湖和数据仓库的优势结合起来。
数据湖的概念是先加载后使用,这意味着存储在存储库中的数据,不一定要立即用于特定目的。它可以按原样转储,并在未来某个阶段随着业务需求的出现而全部一起使用(或部分使用)。这种灵活性和存储海量数据的结合,使得数据湖成为企业内数据实验、机器学习和高级分析应用程序的理想选择。
数据湖有什么好处
数据仓库仅为某些预定义的商业智能、报告应用程序存储经过处理的结构化数据(按行和列组织),但是数据湖具有无限存储一切的潜力,数据可以是是结构化数据、半结构化数据,甚至是非结构化数据,比如图像(.jpg)和视频(.mp4)。
数据湖对企业的好处包括:
存储扩展数据类型多样化:由于数据湖提供了存储所有数据类型的能力,包括对执行高级分析形式至关重要的数据类型。企业可以利用它们来识别机会和可操作的建议,从而有助于企业提高运营效率、增加收入、节省资金和降低风险。
扩展数据分析带来的收入增长:根据阿伯丁的一项调查(Angling for Insight in Today's Data Lake),实施数据湖的机构在收入有机增长方面,比同类公司高出 9%。这些公司能够对存储在数据湖中的先前未使用的数据,比如日志文件、点击流数据、社交媒体数据和联网设备数据中,进行新型分析。
来自孤岛的统一数据:数据湖还可以集中来自不同部门孤岛、大型机和遗留系统的信息,从而减轻其个人容量的负担,防止数据重复等问题,并为用户提供 360 度的视图。同时,他们可以将储存数据成本保持在较低的水平,以备未来使用。
增强的数据捕获,包括物联网:组织可以实现数据湖,从多个来源(包括工厂和仓库中的物联网设备传感器)吸收数据。这些资源可以是内部,或面向客户数据的统一数据湖。面向客户的数据可以帮助营销、销售和客户管理团队,为每一位客户提供最新和统一的信息来策划全渠道的活动,而内部数据则用于整体员工和财务管理战略。
借助数据湖,大量企业内部技术高效地支撑了不同数据分析场景,满足业务数据分析对于弹性扩展吞吐的需求。同时,数据湖多样的存储类型,也让存储成本有了更多的优化空间。
非结构化数据存储,是否有更优解?
数据湖最大的优势之一就是,可以轻松实现非结构化数据的采集、存储和分析,帮助企业解决了一定的问题,但目前数据湖仍然面临数据治理的问题。在数据湖中的数据往往大多采用不同的基于文件的格式,但数据仓库主要是数据库格式,这增加了数据治理和两种存储类型之间沿袭管理的复杂性。
为此,焱融科技希望能帮助企业用户打造更高效、精准的数据平台,实现存储资源可以有效且高效的全生命周期管理。同时,提供高性能、低延迟的数据服务能力,保证各业务系统平稳运行的基础。
YRCloudFile 是一款在经过企业和用户访谈、技术交流、全面测试以及版本迭代推出的非结构化数据统一存储平台,它可以在公有云、私有云环境下为客户提供高性能、高扩展以及云原生的非结构化数据存储系统。其核心产品特色是具备高性能特性,借助这一特性,YRCloudFile 可在人工智能、自动驾驶领域中的训练环节,以及高计算环境中的数据加载运算阶段提供高速、稳定的数据访问能力。
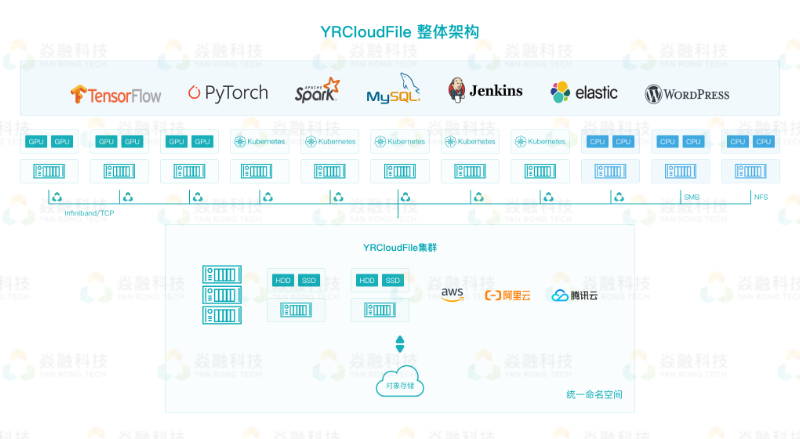
YRCloudFile 产品构架图
YRCloudFile 产品架构经典特点:
海量小文件下的高性能,采用元数据节点集群化、多级智能缓存、智能预读等多种技术,深度优化海量文件读写性能、目录访问热点等问题;
云原生容器存储,提供了标准 CSI 接口,支持 PV 配额、Resize、QoS,分别从容量、IO 性能上对存储资源做了隔离与规划,通过 PV Insight 帮助管理员查看存储卷内部数据分布和冷热情况;
支持公有云、混合云,实现在阿里云、腾讯云、AWS 等公有云上实现一键部署,在公有云上提供高性能的文件存储服务,并通过冷热数据分层功能使数据在不同层级之间流动,从而降低存储的总体拥有成本。
YRCloudFile 所采用的 Scale-Out 架构,可以给提供高效的目录配额限制,精准的流量控制;数千客户端的并发访问能力满足统一云原生平台的访问需求;可以有效监控客户端访问及操作性能。
另外,YRCloudFile 通过多级智能缓存、预读等机制,提供高性能、低延迟的数据访问服务,助力企业用户实现非结构化数据资源的共享,实现最高效的整合。
结语
目前,数据仍然是技术创新的核心之一,任何数据都需要保护、存储和管理以便更好地应用。毋庸置疑,数据湖的应用可以有效帮助企业用户解决一定的数据问题,但是若想真正成为未来主流的数据存储管理方案,还需继续努力。作为高性能文件存储和容器存储的领导者,焱融科技长期关注企业用户需求,解决数据面临的存储架构、数据安全、数据维护等方面的问题,打造海量数据存储解决方案最优解。
版权声明: 本文为 InfoQ 作者【焱融科技】的原创文章。
原文链接:【http://xie.infoq.cn/article/27f607a8f021548f0ec4a25df】。文章转载请联系作者。

Drive Future Storage 2020.05.29 加入
面向未来的下一代云存储









评论