老骥伏枥 -network policy 之 iptables 实现
今天这篇是 Network Policy 系列第二篇,前一篇链接在这里“镜子-或许我们也和Pod一样生活在虚拟世界”。嗯,二哥是一个贴心的人。
上一篇结尾处我用一个外包公司将研发和测试按项目组打散混坐的例子来比喻 K8s 将各个 Pod 分散到不同的 Node 上这样一个编排策略。如果你是这家公司的老板,该如何解决不同 team 之间信息乱窜的问题呢?我们先来看看 K8s 是如何解决这个问题的,看看能不能给从中找到一些思路。
Network policy
Network policy 初探
K8s Network Policy 一种资源,资源名称是 NetworkPolicy。你或许要问什么是资源,什么是自定义资源(CRD),它和自定义 api server(custome api server)又有什么关系?这些不急,以后再细聊。
Network Policy 顾名思义,首先它是一种 Policy, 其次它与 Network 相关。Network Policy 主要的功能有:
Policy 以 namespace 为范围边界(比如你在 namespace default 的上下文创建 policy)
Policy 通过 label selectors 来应用到具体的 Pods
Policy 里面可以指定哪些特定的流量可以进/出其它的 pods, namespaces, or CIDRs
Policy 里面可以指定哪些特定的协议(TCP, UDP, SCTP),named ports 或者 port numbers
下面是一个 Network Policy 的简单示例:
这个示例中,在名为 default 的 namespace 里面,所有带有 label app=falco的 Pod 都会被完全隔离,变成一个个信息孤岛。
为什么 Network policy 非常重要
我们之前在聊 K8s 网络模型以及 K8s 网络与宿主机网络对比的时候,有一个词反复提到过:扁平。
扁平的目的是为了让容器之间可以非常简单、直接、高效地通信。但现实是残酷的,简单固然非常的重要,但隐私也同样需要重视。
一个典型的对外提供服务的 SaaS 在 K8s 内部是通过 Ingress+service+Pods 组合搭建的。其中 Ingress 和 Client 之间是 HTTPS,但 Ingress 和内部的 Pod 之间很多情况下是直接通过 HTTP,而非走加密通道。Ingress 通过服务发现的方式感知 service 的存在,service 通过 endpoint 列表得知可以为之提供服务的 Pod 有哪些。
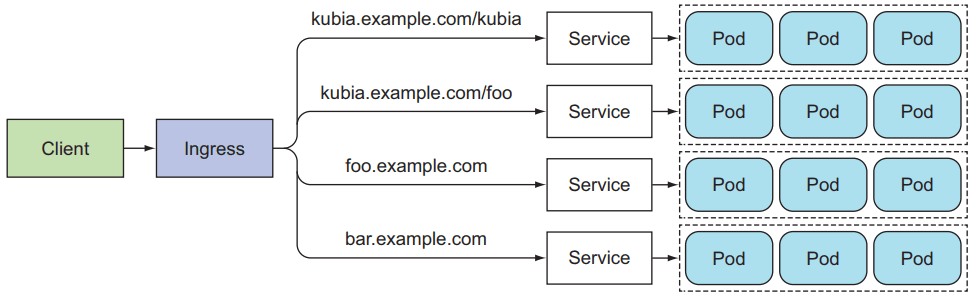
图 1:K8s 方式,一个典型的通过 Ingress+service+Pods 组合搭建的 SaaS 服务
设想一下,假如完全不管隐私的话,万一在生产环境混进了一个有问题的 Pod,它里面跑着一个恶意的容器,这个容器就可以用各种网络嗅探工具记录这个 K8s 集群所有的流量。
Network Policy 就是为了解决这个问题而出生的。但我们不禁要问题一个问题:以前的直接控制 firewall, iptables 的方式不香吗?为什么非要用 Network Policy 不可呢?
K8s 方式与传统的微服务部署方式安全控制机制对比
在云原生这个概念落地之前,微服务之间的安全控制机制是依赖 iptables 创建若干条规则来控制流量的过滤、转发等操作。比如像下面这样的一条 rule,将所有的访问者都拒之门外。在云平台上,这些规则的集合常称为安全组。
实际上上面这条简单的规则是设置在 Firewall 上面的。当然 Operator 不可能一条一条手工去这样编写 rule,他们是在云平台安全组控制平面去做配置,但是最终这些配置变成了 iptables 的表+链+规则。如下图所示:
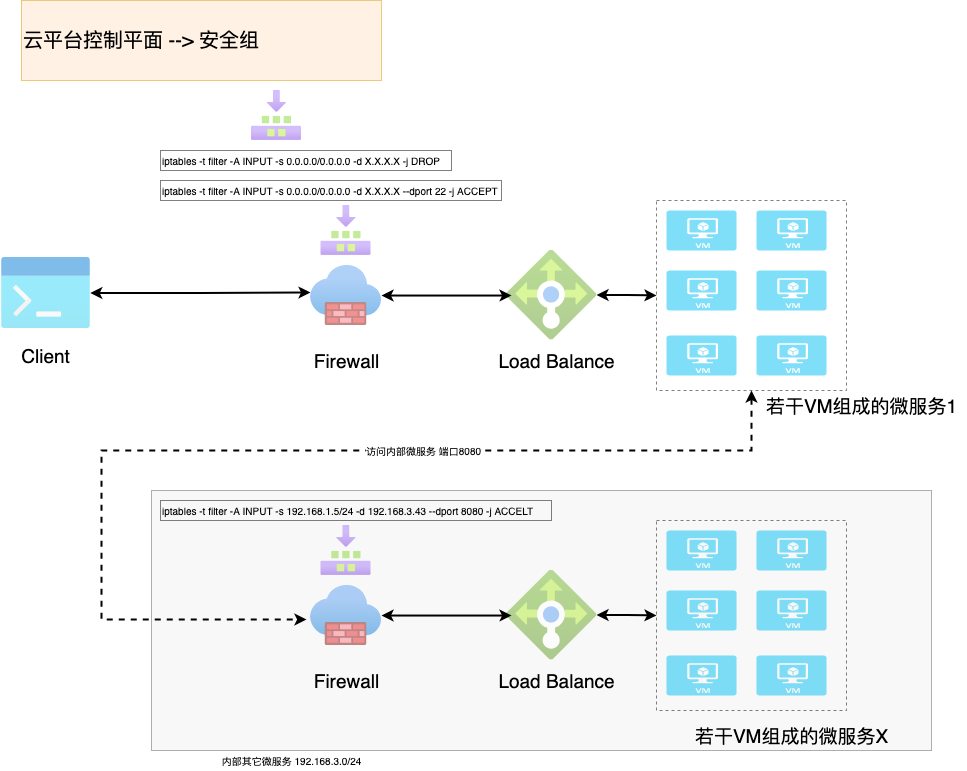
图 2:传统的架构,Firewall+Load Balance+VM 集群
这样做当然没有问题,但它基于一个前提:如无特殊情况,Load Balance 的 IP 地址是固定不变的,即使躲在 LB 后面的 VM 会被不断地创建和销毁。
我们来对比图 1 和图 2,会发现以下几个有趣的现象:
传统的架构,在一个 VM 上跑一个(或几个)微服务,微服务的 IP 地址为该 VM 的地址。而对于 K8s 的方式,每个 Pod 都会有自己的 IP,且和运行它的 VM IP 地址不同,正常情况下它们俩不在一个网段。
传统架构的调度是以 VM 为粒度,也即以 VM 为单位来 scale out 和 scale in。而 K8s 却是以 Pod 为单位调度,以 Pod 为最小粒度来 scale out 和 scale in。
传统的架构是以 Firewall 为安全边界,安全组设置作用于 Firewall。而 K8s 方式里,Firewall 消失了,看起来 service 起到了负载均衡的作用,但它也只是一个普通的 K8s resource,无法承担安全的重任,且它的地址是不固定的,生命周期更不固定。
传统的架构,VM 的创建和销毁的速度、频率、效率虽然相比 Bare Metal 有巨大的改进,但与 K8s 方式所用的 Pod 相比,还是显得笨重了许多。而在 K8s 方式里,Pod 会出现剧烈的、快速的、高频次的大规模扩大和收缩的情况。
传统的架构是在云平台控制平面通过配置安全组并下发到 Firewall 来实现安全控制,而 K8s 却选择通过 Network Policy 这种声明式 API。
对比之后,可以看见与传统方式相比,K8s 对安全控制的理念、方式都发生了比较大的改变。这种改变既是源于基础架构的变化,编排方式的改变,也是微服务技术演变过程中,业界(学术界和工程领域)对服务治理新认识、新理解的体现。
iptables and eBPF
又一次需要提到 CNI 了。我们来从 10000 米高空来俯视一下 K8s 和 CNI 的关系。CNI, CRI, CSI 组成了 K8s 规范的三大金刚,其中 CNI 完成与容器网络相关的大部分工作。只要满足 CNI 规定的最低要求,即可成为一个 CNI 插件。
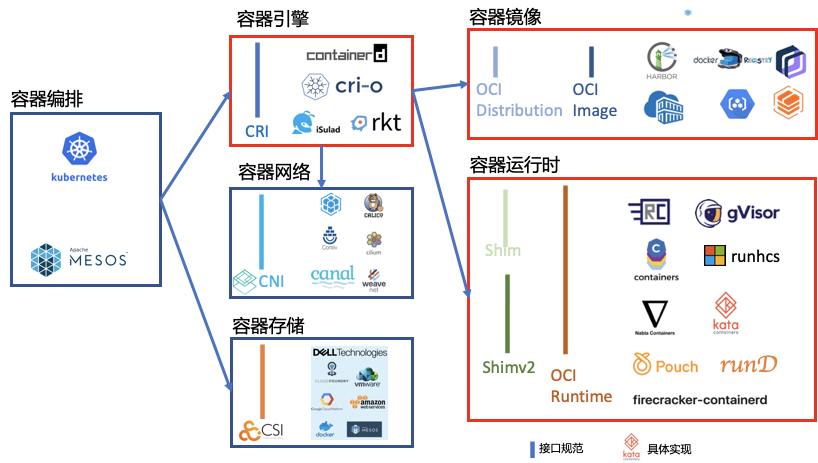
图 3:CNI 在 K8s 规范中的位置
Network Policy 这活也是网络插件在干,在这方面 K8s 就是个甩手掌柜,把所有的事都外包出去了。K8s 只需要关注 Network Policy 请求这件事,至于如何实现则由具体的插件来完成。这里(强行)插播一条广告:CNI 插件是如何知道它要处理 Network Policy 请求的呢?这个地方涉及到 informer 和 controller 机制,二哥后面安排上。
Network Policy 有两种典型的实施方案:iptables 和 eBPF。前者是老骥伏枥,K8s 网络插件对 Pod 进行隔离,靠在宿主机上生成 NetworkPolicy 对应的 iptable 规则来实现的。而后者为最近几年大火的新秀,它以可编程、稳定、高效、安全出名,被作为下一代网络、安全和监控的首选技术。 Cilium 即以 eBPF 为核心玩出了各种各样令人眼花缭乱的,小鹿乱撞的功能。
今天这篇我们先聊下 iptables 这种实现方式,eBPF 因为涉及到更多的背景知识,我把它放到下一篇再细聊。
Network Policy 实现之 iptables
上文提到的使用 iptables 来实现 Network Policy,其实是通过在 Pod 所属的 Node 上生成相应的 iptables 规则来实现的。拿文章开头提到的 Network Policy 的简单示例来说,在对应的 Node 上会看到如下所示的 iptables rule。
这个示例所涉及到的 pod 为 falco ,它的部署方式是daemontset。这就意味每个 Node 上都会运行这样一个 pod。所以自然地每个 Node 上面的 iptables 里面都会添加这样的 chain 和 rule。
你肯定会由此想到一个问题:那岂不是每个 Node 上面的 iptables 都会变得很庞大?是的,你的顾虑正是事实。不只是变大,过于庞大的 iptables 还会导致 package 经过协议栈的时候速度变慢。这是由于 iptables 的工作模式决定的。老骥伏枥,虽志在千里,可无耐已烈士暮年,而我们下一篇将要聊到的 eBPF 则是后起之秀代代强。
图 4 展示了使用 Cilium 这个 CNI 生成的庞大的 iptables 规则图。规则分为两大部分:K8s 自己设置的规则以及 Cilium 添加的规则。
虽然前文提到 Cilium 更钟情于 eBPF,但在不得已的情况下(例如 Linux kernel 版本太低)它也可以基于 iptables 工作。但无论图 4 有多复杂,总逃不脱 iptables 的表+链+规则的基本工作框架。理解了 iptables,相信你可以非常快速地读懂这些规则。
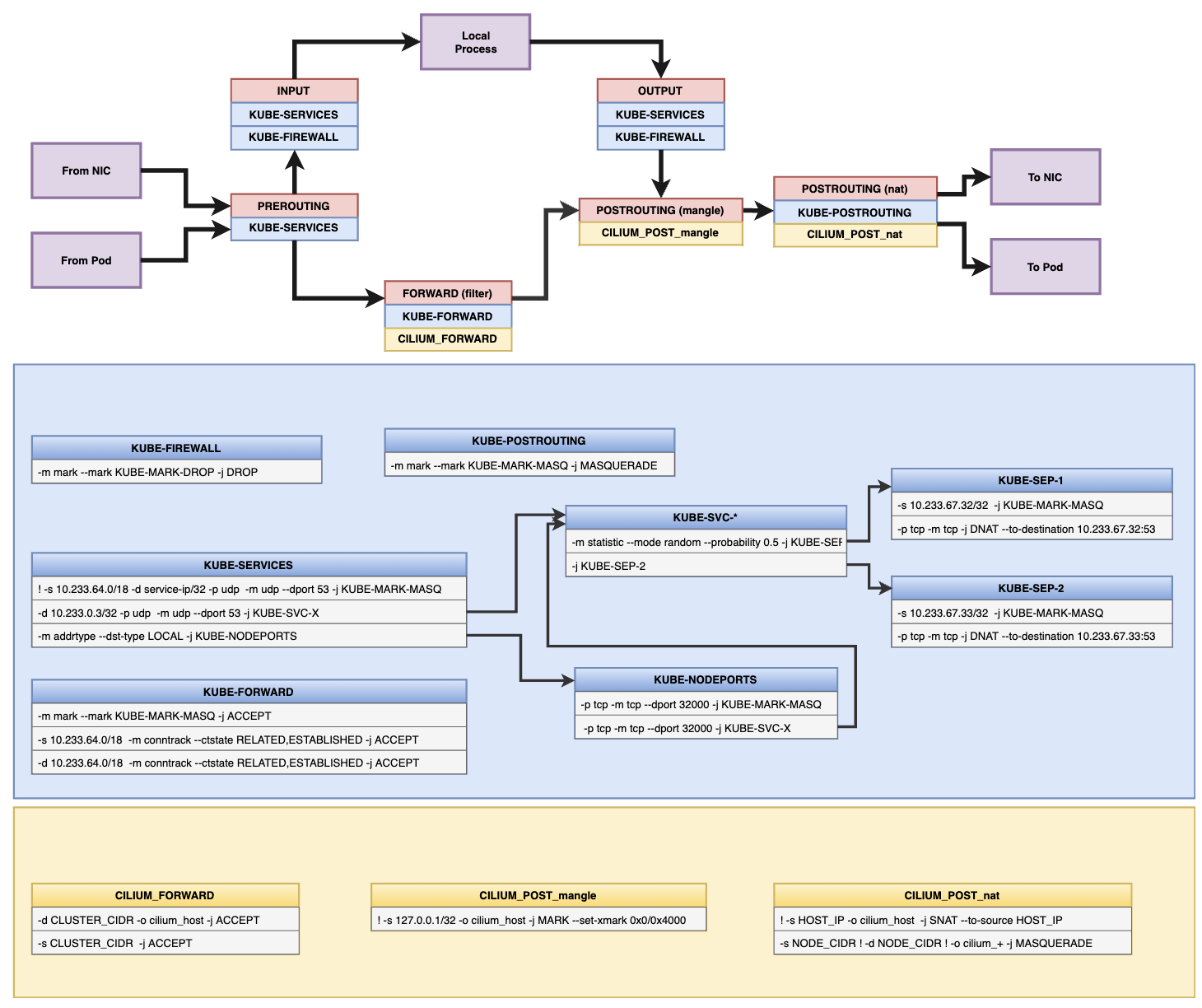
图 4:Cilium 实现的 iptables 规则图(图片选自https://docs.cilium.io/en/v1.10/concepts/ebpf/iptables/)
当我们尝试去解构各种云服务网络组成时,会发现无论是简单的 Docker,还是 Kubernetes,或者 SDN(Software-defined networking ),都大量地用到了虚拟交互机也即 bridge,又称网桥。它的出现和大量使用在客观上要求 iptables 能够过滤 bridge 中的数据包,比如二层的网桥在转发包时也需要被 iptables 的 FORWARD 规则所过滤。本文把这部分略过,感兴趣的你可以搜索bridge-netfilter和ebtables找到更多参考资料。
Network Policy 实现之 eBPF
欲知此事,且听下回分解。
以上就是本文的全部内容。码字不易,更多内容请关注二哥的微信公众号。您的举手之劳是对二哥莫大的鼓励。感谢有你!

版权声明: 本文为 InfoQ 作者【Lance】的原创文章。
原文链接:【http://xie.infoq.cn/article/27874e2ee6e8f24d0a0688752】。文章转载请联系作者。

码海茫茫 2018.03.18 加入
软件行业从业多年,焊过电路、干过驱动、写过内核的代码、砌过业务的砖,人生转角处偶遇云原生。









评论