渣硕试水字节跳动,本以为简历都过不了,123+HR 面直接拿到意向书
前言
双非渣硕,本以为简历都过不了...,还好字节能给一次机会。前阵子字节跳动的提前批开始了,看宣传是说有海量 HC,机会多多,本着涨涨面经的心理,然后就投递了一下杭州那边的 Data 部门,首先在这里还要非常感谢内推我的小哥哥,非常热心的帮我跟踪进度,因为中间还出了一些小插曲(我投错部门了。。。),还是热心的小哥哥帮我联系 HR,最后把我转到想要投递的部门了,我投的是 java 后端开发~面试项目大部分问题是围绕我的开源项目 蘑菇博客 展开的,还有就是我之前准备面试的一些 笔记(大佬请轻喷..)

注意:我投的是 java 后端开发~面试项目大部分问题是围绕我的开源项目 蘑菇博客 展开的,还有就是我之前准备面试的一些刷题笔记(大佬请轻喷..)有需要的可以【见下图添加上小助手】即可给你分享哦~

面试时间
HR 面完后,等了一个礼拜多,以为凉凉了,没想到收到惊喜,许愿成功~
第一天:第一面 + 第二面
等了两天:第三面 + HR 面
过了一周后:等来了意向书
第一面
第一面我觉得应该是基础面,重点考察的是自己技术的广度 和一些技术的掌握情况,一面小哥哥也没有深究于某个特定的点,面试时间大约 1 个小时。
自我介绍
怎么打算投递后台岗位的,没有考虑契合自己研究方向的工作
有了解过 OAuth2.0 么,说说你对 OAuth2.0 的理解
蘑菇博客开发过程中,有了解或学习其它的开源框架么
蘑菇博客文章发布的流程是怎么样的,是多人博客系统么
对其它的一些博客框架有了解么,比如 hexo
hexo 和蘑菇博客相比有什么区别呢?蘑菇博客多了哪些功能和优势
看你蘑菇博客用到了 RabbitMQ,那谈谈为什么引入 RabbitMQ?
RabbitMQ 和其它消息队列,比如 ActiveMQ,RocketMQ,Kafka 有什么区别
Redis 在你博客项目中的使用,为什么引入 Redis?
Redis 中存储的是热门文章,是通过什么来得到的?这样做会有什么问题么?
有听过长尾效应么?你通过推荐字段设置的推荐等级,这样会让这些文章一直保持在较高的点击量,而且热度和点击量也不会随着时间而降低,有什么解决方案么?
我看到你有用到 JustAuth 这个登录授权?说说它会存在账号泄漏的问题么?
下面谈谈 Redis,它会存在线程切换的问题么?
谈谈 Redis 单线程模型和 IO 多路复用
Redis 的大 Key 的问题,如果有个 Value 的大小是 2M,会有什么问题么?最大支持的 Value 大小是多少?
谈谈 Redis 集群 Redis Cluster,以及主从复制原理?
说说 Redis 中的哨兵,即 Redis Sentinel
下面来聊聊 Linux,你知道 Linux 怎么查看当前的负载情况么?
你还知道其它的一些 Linux 命令么?
cat、tail、vi、vim 命令的区别,分别说一说?
如果 Linux 下需要打开或者查看大文件,你会怎么做?
下面聊聊 Http Code,你知道 3XX 状态码 对应的是什么?
再谈谈你知道的其它一些状态码,4XX 和 5XX?
下面我们来做个题目吧?语言任意,选择喜欢的(ps:其实是 leetCode 原题,没有做过类似的,想了几分钟没有思路,哭。。,想问问思路,然后说换一题吧,那就,事后想想还挺简单的,根据第一位排序一下就好了)
那就换个题目吧,看看下面这个题目,找数组出现次数最多的 TOP N,回头听室友说,好像又是 leetcode 原题,泪目,算法能力太弱,没怎么刷题。
然后我最开始的思路就是,通过 hash 存储出现的次数,然后 key 就是数组中出现的值。最后再对 hash 中的次数进行排序,最后得到 top N,因为时间复杂度是 O(N^2),问有没有优化思路,能否优化到 O(N),想了半天没有想出来,没有充分运用以及构建好的 hash 表
后面面试官给讲了一下思路。从数组长度向下遍历进行查找
反问环节,问了问面试的表现,被告知算法能力比较薄弱,以为就此凉凉。。。然后一面说这边可以让你进入下一环节,这边大概需要等 5 到 10 分钟左右
第二面
二面考察的是技术深度面试,面试时间大约 50 分钟左右
自我介绍
博客已经开源了么,用的什么开源协议,博客的用户多么?
看你博客中用到了 Solr 和 ElasticSearch,谈谈它们的原理,以及倒排索引?
对于 Solr 或者 ES 里面用到的一些中文分词器有了解过么?
谈谈那些技术栈,你比较熟悉的是那些,mysql 和 redis?
聊聊 MySQL 的底层索引结构,InnoDB 里面的 B+Tree?
B Tree 和 B+ Tree 的区别
聊聊 MySQL 索引的发展过程?是一来就是 B+Tree 的么?从 没有索引、hash、二叉排序树、AVL 树、B 树、B+树 聊。
谈谈 MySQL 里面的事务,说说什么是事务?
MySQL 里面有那些事务级别,并且不同的事务级别会出现什么问题?
谈谈可重复读和幻读的区别?
MySQL 中如果使用 like 进行模糊匹配的时候,是否会使用索引?一定不会用么?(索引这块了解的太少了,二面结束后,回去恶补了一下)
谈谈 Redis 吧,在你项目中的具体使用?
谈谈 Redis 如何实现分布式锁?
蘑菇博客是否存在缓存不一致的情况,你是如何解决的?
谈谈 Redis 中缓存穿透的问题,以及解决的方法?
还有其它解决缓存穿透的方法么?布隆过滤器有了解过么?
Redis 中大面积的缓存失效,然后请求全部打到数据库,有什么解决方法?
如果出现一些热点数据,比如明星之间的新闻,造成大量的吃瓜用户涌入后台,但是服务器还没有缓存对应的数据,这样可能造成数据库宕机,如何避免这样的情况?
聊聊 JVM 的组成结构?
谈谈垃圾收集原理?以及垃圾收集算法
复制算法 和 标记整理算法?
为什么不在新生代使用标记整理算法?或者在老年代使用复制算法?
有了解过 Volatile 么?谈谈你对 Volatile 的理解
Volatile 如何保证可见性的?以及如何实现可见性的机制。
如果大量的使用 Volatile 存在什么问题?
谈谈操作系统的线程,以及它的状态
线程和进程的区别?
为什么要提出多线程应用,而不是多进程应用呢?
Linux 你平时都有用到什么命令呢?
如果我需要查看端口号或者进程号,你会使用什么命令?
谈谈你做的另外一个项目吧?稍微介绍一下
来吧,写个题目试试
毕业时间是什么时候?现在面试的是实习岗位么?
反问环节:追问面试表现?告知 Redis 这块掌握的还可以,但是 MySQL 这块显得不足。问后续的安排。
第三面
应该是 Leader 面,面试时间大概 50 分钟
自我介绍
好奇一下,用码云的人应该不多吧,为什么没有用 Github?
你英文水平怎么样?
聊聊开源项目吧?我看这项目已经有 800 多赞了,你在这开源项目主要做了什么工作?
我们找些点来聊聊吧?先从 ES 和 Solr 开始,你们这两个都有在用么?
SQL 的方式实现搜索,你是怎么做的呢?
使用 like 匹配的时候,会不会查询非常慢呢?
ES 和 Solr 的底层都用了 lunce,谈谈你对 lunce 的理解?
lunce 里面也有用到分词器,比如一些新的词 “新冠肺炎” ,它能不能做到很好的划分呢?
除了人为的维护词库,来解决最新词语的分割,你还有知道其它什么更好的方法么?
你有了解过其它什么开源的分词库么?
谈谈字典树?
Solr 和 ES 底层都用了 Lunce,那他们两者有什么区别呢?
Solr 所谓的集群环境 和 ES 所谓的分布式环境,它们之间有什么区别呢?
上面你有提到微服务,你有了解过微服务是个什么样的理念么?
你现在的微服务,也是打包成多个 jar 包,部署在一个服务器上,如果服务器出现问题了,也会造成服务不可用,有没有好的解决方法呢?
聊聊服务的注册与发现?
服务的注册和发现,其实依赖于一个注册中心的概念,会不会出现注册中心挂掉,而导致整个服务不可用,有没有什么好的解决方法呢?
有了解过 Zookeeper 整个的选举过程么?
谈谈 Zookeeper 的分布式一致性协议?
聊聊索引,我给你写个表,看看下面的查询语句,走了那些索引?
上述 SQL 用到了几个索引?分别是那几个?
有了解过 InnoDB 底层的索引结构么?
通过两个索引查询出来的结果,会进行什么样的操作?交集,并集?
如果你在 MySQL 中遇到一些慢查询,有什么解决方法么?
谈谈 explain?执行的 explain 后,出现的那些字段,能够帮助我们呢?
我看你的博客里面,关于 Redis 还有好几篇文章,我们可以聊一聊你对 Redis 的理解?
为什么 Redis 能够保持这么高的并发响应?
有了解过 IO 多路复用技术是个什么样的原理
通过一个线程,同时连接多个线程不会存在多个线程切换么?(感觉进坑了。。)
当你通过 jedis 进行连接 redis 的时候,已经和一个进程连接了 ,redis 还能够和其它的进程进行通信么?
Redis 每秒能够处理处理十万请求,如果按照你上面说的,那说明它每次交互只在 1/十万 秒内完成?
有了解过 Redis 的源码么?
MySQL 用了 B+Tree,Redis 中的 SortSet 内部用了跳跃表,他们之间有什么差别?为什么 MySQL 不用跳跃表,或者是 Redis 不用 B+Tree 呢?
感觉自己编码功底怎么样?那我们先聊聊操作系统的知识再给你一道题吧。在操作系统中,有高速缓存,主存,虚拟内存,外存,有知道它们之间有什么样的关系,以及它们的作用是啥?
对它们来说,肯定会存在一个问题,就是当我们的主存满了,或者虚存满了,那么需要存在一个换页操作,你知道有那些换页算法么?
我们来聊聊 LRU?叫你手写一个 LRU 算法谈谈你的思路?
用链表的方式实现,时间复杂度是 O(N),有没有什么方式能够让它是 O(1)的时间复杂度呢?
OK,思路还可以,那你手写一个 LRU 算法吧?(双向链表 + Hash?)
反问环节:问了下组织架构,以及 python 和 go 在项目中的使用。然后问了下面试的表现,答:代码写的不算好吧,LRU 写成这样我觉得是不太合适的。(心碎的声音,感觉到凉凉的气息...),结束后以为面试已经结束,后面在准备关页面的时候,面试官说等一下,还有同学和我聊?
HR 面
花 10 来分钟做个简单的沟通
自我介绍
考研的时候为什么选择的是这个学校呢?
回顾一下,上大学到现在这段时间内,让自己最有挫败感的事情是什么呢?
有哪些方面需要在改进的么?
对于以后参加的工作,你主要会看重哪些方面呢?
同学这块,大家都有在投递字节这边的岗位么?
反问环节:关于面试结果,告知,这边只是做简单的了解,面试结果大约会在一周左右出来,到时候会有邮件或者电话通知。关于面试的结果,需要综合前面的几个面试官进行综合评测,才能决定是否录取。
总结+面试前的准备(供大家参考学习)
由于篇幅原因,有需要的朋友请务必麻烦大家帮小编点赞一下,因为这样可以帮助更多有需要的人看见,然后"【见下图添加上小助手即可】"获取这些笔记文档哦
给大家个建议,面试官如果愿意和你聊组里业务,一定要把握机会好好聊,最好能提出让面试官眼前一亮的问题,直指业务核心。代码谁都会写,基础知识网上都能查到,但是对产品的理解和新的想法不是谁都有的
(1)第一步,面试前整理一个完整知识架构大纲
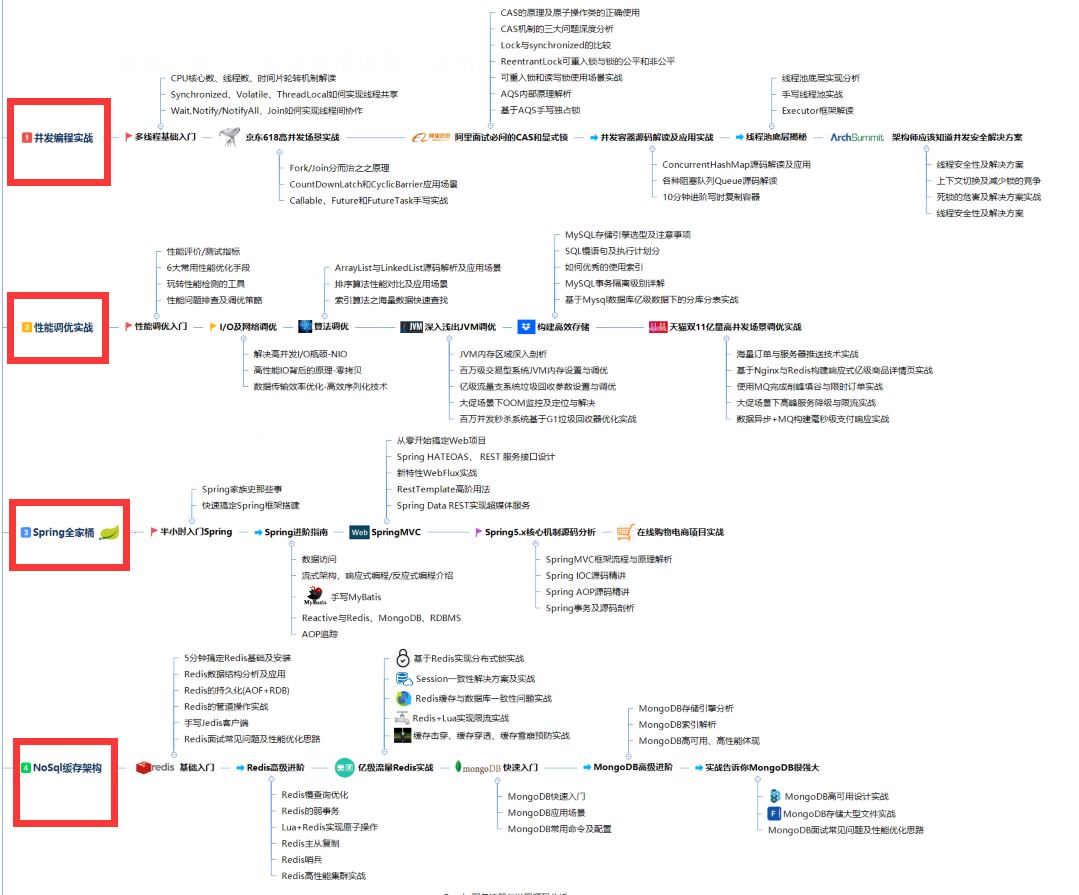
我将架构体系分为五大模块:并发编程、JVM 性能调优、Spring 开源框架源码解读、缓存数据库、分布式架构,微服务架构
(2)第二步,通过大纲对面试中的高频技术逐个攻克
1,并发编程(手写笔记:并发编程+并发编程_原理+并发编程_应用+并发编程_模式)
并发编程共享模型篇
并发编程_模式篇
并发编程_应用篇
并发编程_原理篇
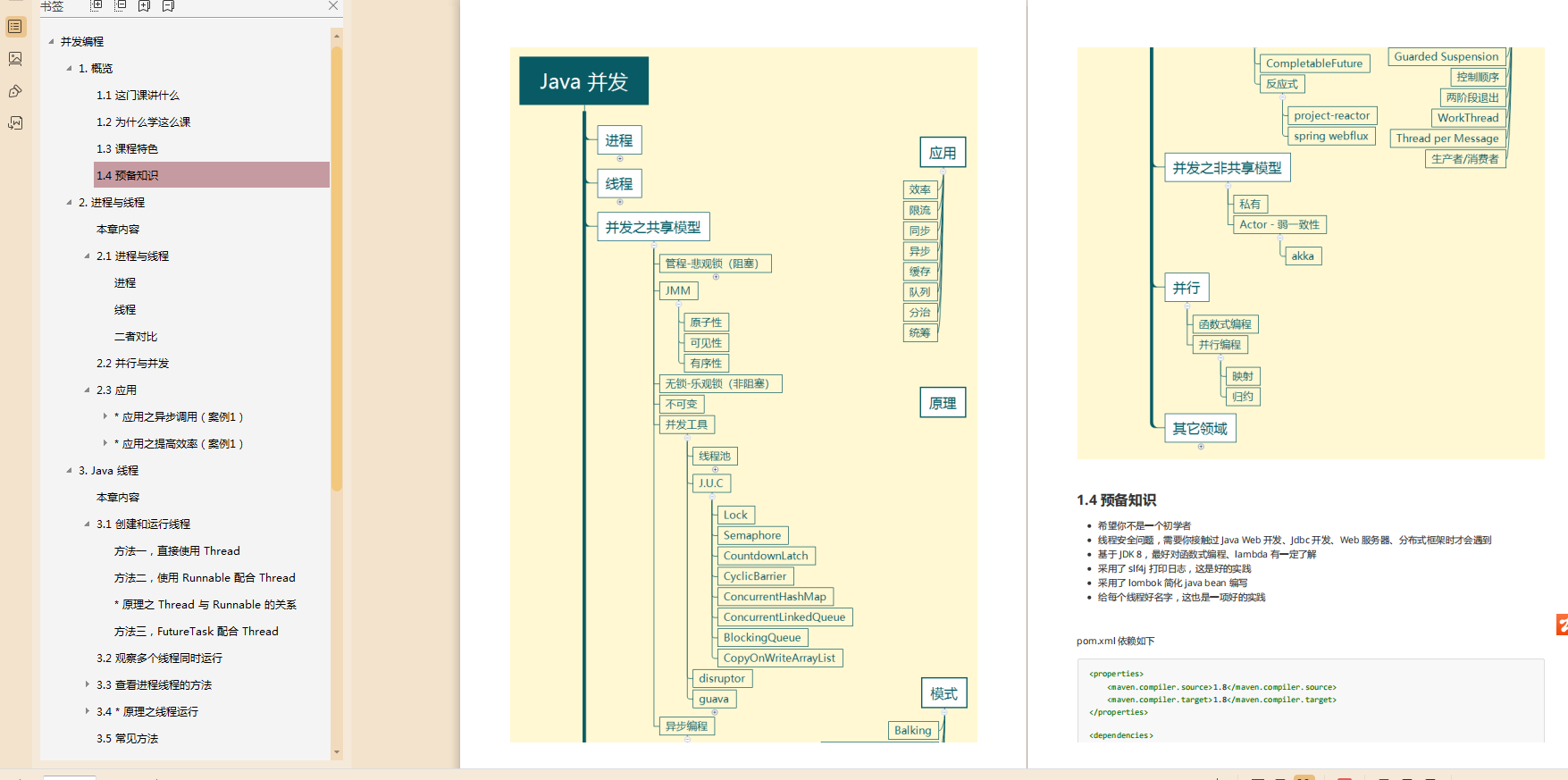
并发编程共享模型篇

并发编程_模式篇

并发编程_应用篇

并发编程_原理篇
2,性能调优(Java 性能调优实战:Java 编程性能调优+JVM 性能优化+Mysql 调优笔记)
JVM 性能优化

JVM 性能优化
JVM 性能监测及调优

JVM 性能监测及调优
Mysql 调优笔记

3,Spring 开源框架源码解读
4,缓存数据库
Redis 核心笔记
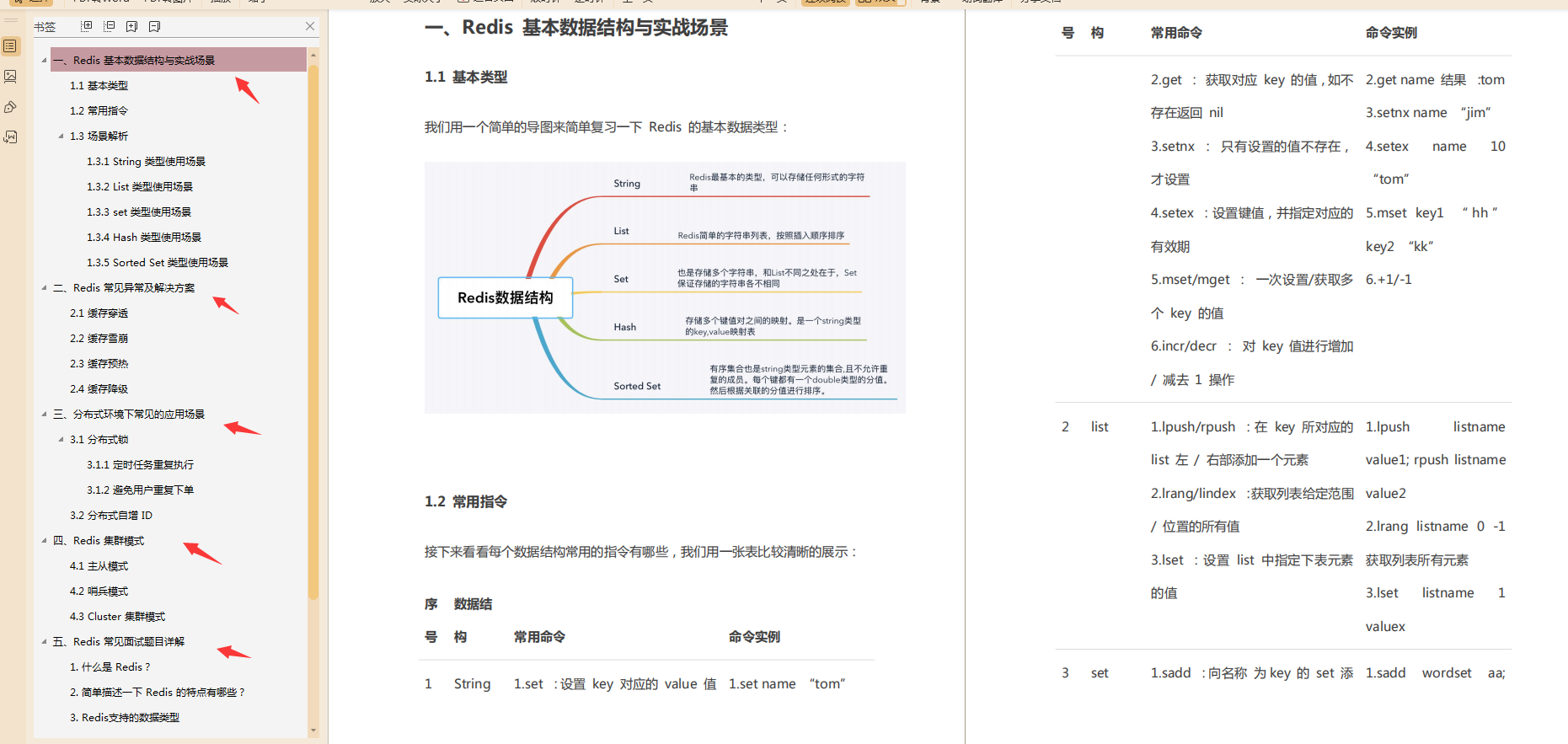
Redis 核心笔记
MongDB 基础到进阶

MongoDB 快速上手
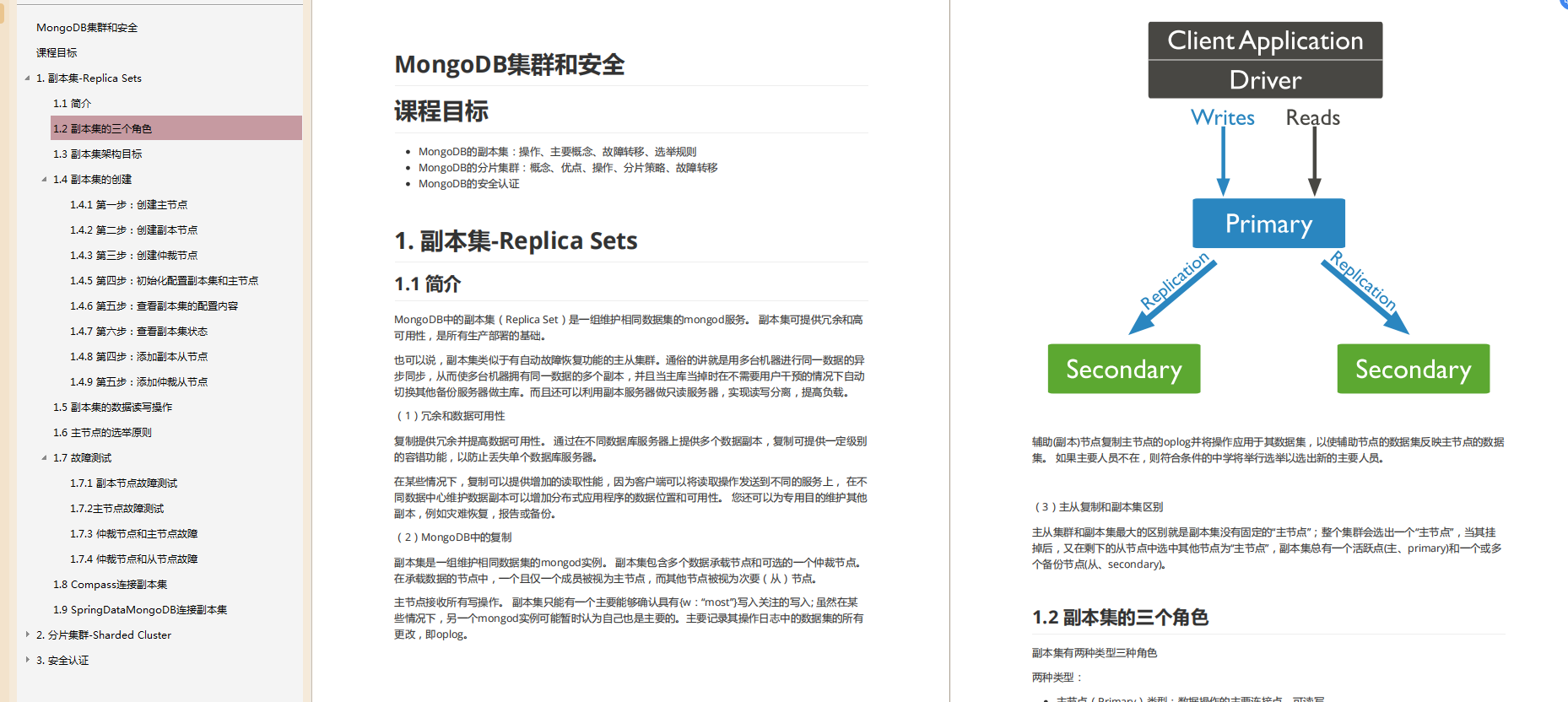
MongoDB 集群和安全
5,分布式架构
Kafka 源码解析与实战

6,微服务架构
Spring Cloud Alibaba 技术栈全解
Spring Cloud 微服务笔记
k8s+Jenkins 笔记

(3)第三步,刷面试题,面试字节跳动算法是必问的
团灭 LeetCode 的算法刷题宝典
算法刷题小册

25 大 Java 面试专题
字节跳动总体来说,面试体验还很不错的,尤其是在手撕代码题的时候,面试老哥会先叫你提供思路,如果你说的思路有问题的话,会帮你拨正,然后在进入 coding 阶段,但是怎奈何平时没怎么练习算法,leetcode 做的少,面试两行泪。。这也算是提前批打响第一枪,期待后面精彩表现~
以上就是我在面试前整理搜集的面试资源和一个学习路线规划,希望能对大家有所帮助,有需要的朋友请务必麻烦大家帮忙点赞一下,因为这样可以帮助更多有需要的人看见,然后【见下图添加上小助手】即可获取这些笔记文档哦

还未添加个人签名 2021.03.15 加入
还未添加个人简介









评论