Redis - 哈希表

redis 是一个键值对数据库,底层存储数据的结构是怎么样的呢?
众所周知,根据 key 查询 value 这种存在映射关系的查询,哈希表数据结构能够极大的提升查询效率,理想状态下为复杂度为 O(1)。
哈希表
哈希表是一种数据结构,以一般的实现来说,可以看做一个数组 + 链表,如下图所示
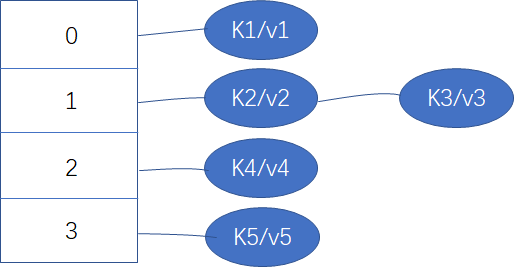
数组的每个元素可以看成是桶,每个桶中放置若干键值对。哈希表比较重要的概念:
长度:即桶数量,也为数组长度。上述 size = 4
元素个数:实际键值对个数。上述 num = 5
负载因子:元素个数/长度,表示哈希表的满、空程度,越大代表装得越满。负载因子超过或低于某一常量时,会自动进行伸缩,即增加或者缩减桶数量,一般称为 rehash
散列函数:根据 f(K)决定将键值对存放到具体的桶,一般使用 hash 后求余
哈希表的目标
理想情况下,哈希表中每个桶就装一个键值对,通过散列函数能直接定位到数组下标,查询复杂度为 O(1),但实际却因为哈希碰撞的存在不尽人意。哈希碰撞简单的说,即:
k1 ≠ k2,但 f(k1) = f(k2)
这样会导致一个桶有多个键值对,那这样有什么问题呢?极端情况下所有的键值对都跑到一个桶里面,形成一个链表,而链表的查询复杂度是 O(n),这样明显就降低了查询效率。
所以哈希表应该尽量避免一个桶装多个键值对。要达到这个目标,两点是关键:
1、长度
长度越长,桶越多,键值对分散的概率越高
2、散列函数
选择一个合适的散列函数让键值对分散到不同的桶中。散列函数不合适,即便长度再长也无济于事,很有可能所有键值对都跑同一个桶中了。
Rehash
选定散列函数情况下,哈希表长度固定,那么随着存储键值对的个数越来越多,那么每个桶存储的键值对个数相应的也会大概率变多,最终导致整个哈希表的查询效率变慢。所以,当键值对数量达到一定程度时,需要将增加桶数量,以增加数据分散度,那么有两个问题:
1、达到什么阈值才触发桶数量增加?
2、以什么样的方式增加桶数量呢?翻倍?还是一次加 100 个?
对于第一个问题,通常以负载因子加以评估。引用 java 中 hashmap 的实现方式(底层也是一个哈希表),默认当负载因子到达 0.75 时进行桶扩展。
为什么是 0.75 呢?按照概率论中的泊松分布,当负载因子等于 0.75 时,每个桶中存储元素个数的概率为:
如上表可知,0.75 时可以较大概率保证桶中只有一个键值对。
对于第二个问题,桶是不是越多越好呢?答案是否定的,桶太多,肯定有较多的桶是空的,一方面浪费内存,一方面对于遍历操作来说也多费些时间。
所以,扩容方式各有不同,但总体思路都是适可而止。
另外,正是因为桶太多带来的负面效果,当哈希表中的数据个数变少,则需要收缩,思路和扩容相同。
rehash 过程必然会导致性能损耗,怎么减量减少负面影响也是比较重要的需要考虑的点。
Redis 中的哈希表
DB 结构体,即 Redis 中 DB0、DB1...,每个 DB 的结构如下:
上述的每个 dict 底层即为哈希表,存储了键值对、键过期时间等。
dict 的结构如下:
真正的哈希表为 dictht,结构如下:
上述 used/size 即可得到负载因子。
那么 Redis 怎么实现的哈希表的几个概念呢?
1、散列函数
Redis 自定义了散列函数,然后和桶数量掩码位与操作得到桶索引。
2、伸缩阈值
扩容时机
服务器目前没有在执行 BGSAVE 命令或者 BGREWRITEAOF 命令, 并且哈希表的负载因子大于等于 1
服务器目前正在执行 BGSAVE 命令或者 BGREWRITEAOF 命令, 并且哈希表的负载因子大于等于 5
收缩时机
当哈希表的负载因子小于 0.1 时, 程序自动开始对哈希表执行收缩操作
3、伸缩方式
扩容时,桶数量增大到大于当前键值对个数的第一个 2 的 n 次幂
比如,个数为 10,则第一个大于 10 的 2 的 n 次幂为 2^4=16
缩容也一样。
4、渐进式 rehash
为尽量将 rehash 带来的性能损耗影响减少到最小,redis 采用了渐进式 rehash,即逐步将原哈希表中的键值对 迁移至伸缩后的新的哈希表中。
迁移时是按桶的粒度进行迁移的,即一次迁移会将一个桶中的全部数据都迁移至新的哈希表。
执行迁移有两个时机:
1)客户端执行键命令时(增删改查)都会顺带帮助执行一次迁移
2)周期性的定时任务

还未添加个人签名 2020.04.30 加入
还未添加个人简介









评论