基于朴素 ML 思想的协同过滤算法(十七)

写在前面:
大家好,我是强哥,一个热爱分享的技术狂。目前已有 12 年大数据与 AI 相关项目经验, 10 年推荐系统研究及实践经验。平时喜欢读书、暴走和写作。
业余时间专注于输出大数据、AI 等相关文章,目前已经输出了 40 万字的推荐系统系列精品文章,今年 6 月底会出版「构建企业级推荐系统:算法、工程实现与案例分析」一书。如果这些文章能够帮助你快速入门,实现职场升职加薪,我将不胜欢喜。
想要获得更多免费学习资料或内推信息,一定要看到文章最后喔。
内推信息
如果你正在看相关的招聘信息,请加我微信:liuq4360,我这里有很多内推资源等着你,欢迎投递简历。
免费学习资料
如果你想获得更多免费的学习资料,请关注同名公众号【数据与智能】,输入“资料”即可!
学习交流群
如果你想找到组织,和大家一起学习成长,交流经验,也可以加入我们的学习成长群。群里有老司机带你飞,另有小哥哥、小姐姐等你来勾搭!加小姐姐微信:epsila,她会带你入群。
我们在第十六章协同过滤推荐算法中介绍了经典的 item-based 协同过滤推荐算法。在本章中我们会继续介绍三种思路非常简单朴素的协同过滤算法,这几个算法的原理简单,容易理解,也易于工程实现,非常适合我们快速搭建推荐算法原型,并快速上线到真实业务场景中,作为其他更复杂算法的 baseline,提供效果对比参考。
具体来说,我们在本章中会介绍利用关联规则、朴素贝叶斯(naive bayes)、聚类三类机器学习算法来做协同过滤推荐的方法。并且还会介绍 3 个核心思想基于这三类机器学习算法的工业级推荐系统,这 3 个推荐系统被 YouTube 和 Google 分别用于视频和新闻推荐中(其中会介绍 Google News 的两个推荐算法),这些算法在 YouTube 和 Google News 早期产品中得到采用,并且在当时情况下效果是非常不错的,值得我们深入了解和学习。
7.1 基于关联规则的推荐算法
关联规则是数据挖掘领域非常经典的算法,该算法来源于一个真实的案例:“啤酒与尿布”的故事。该故事发生在 20 世纪 90 年代的美国沃尔玛超市中,沃尔玛的超市管理人员分析销售数据时发现了一个令人难以置信的现象:在某些特定的情况下,“啤酒”与“尿布”两件看上去毫无关系的商品会经常出现在同一个购物篮(用户一次购物所买的所有商品形象地称为一个购物篮)中,这种独特的销售现象引起了管理人员的注意,经过后续调查发现,这种现象出现在年轻的父亲身上。
在美国有婴儿的家庭中,一般是母亲在家中照看婴儿,年轻的父亲前去超市购买尿布。父亲在购买尿布的同时,往往会顺便为自己购买啤酒,这样就会出现啤酒与尿布这两件看上去毫不相干的商品经常会出现在同一个购物篮的现象。沃尔玛发现了这一独特的现象,开始在卖场尝试将啤酒与尿布摆放在相同的区域,让年轻的父亲可以方便地同时找到这两件商品,并很快地完成购物。这样做沃尔玛超市就让这些客户一次购买了两件商品、而不是一件,从而获得了很好的商品销售收入,这就是“啤酒与尿布”故事的由来。
下面我们给出关联规则的定义,假设
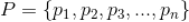
是所有标的物的集合(对于沃尔玛超市来说,就是所有的商品集合)。关联规则一般表示为
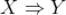
的形式,其中
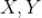
是
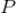
的子集,并且
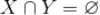
。关联规则
表示如果
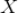
在用户的购物篮中,那么用户有很大概率同时购买了
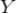
。通过定义关联规则的度量指标,一些常用的关联规则算法(如 Apriori)能够自动地发现所有关联规则。关联规则的度量指标主要有支持度(support)和置信度(confidence)两个,支持度是指所有的购物篮中包含
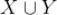
的购物篮的比例(即
同时出现在一次交易中的概率),而置信度是指包含
的购物篮中同时也包含
的比例(即在
给定的情况下,
出现的条件概率)。它们的定义如下:
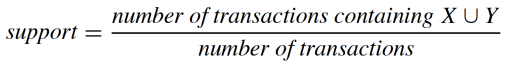
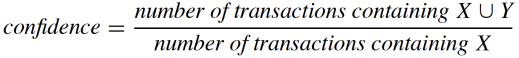
支持度越大,包含
的交易样本越多,说明关联规则
有更多的样本来支撑,“证据”更加充分。置信度越大,我们更有把握从包含
的交易中推断出该交易也包含
。关联规则挖掘中,我们需要挖掘出支持度和置信度大于某个阈值的关联规则,这样的关联规则才更可信,更有说服力,泛化能力也更强。
有了关联规则的定义,下面我们来讲解怎么将关联规则用于个性化推荐中。对于推荐系统来说,一个购物篮即是用户操作过的所有标的物的集合。关联规则
表示的意思是:如果用户操作过
中的所有标的物,那么用户很可能喜欢
中的标的物。有了这些说明,那么利用关联规则为用户

生成推荐的算法流程如下(假设
所有操作过的标的物集合为
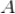
):
1. 挖掘出所有满足一定支持度和置信度(支持度和置信度大于某个常数)的关联规则
;
2. 从 1 中所有的关联规则中筛选出所有满足
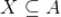
的关联规则
;
3. 为用户
生成推荐候选集,具体计算如下:
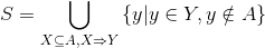
即将所有满足 2 的关联规则
中的
合并,并剔除掉用户已经操作过的标的物,这些标的物就是待推荐给用户
的。对于 3 中的候选推荐集
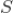
,可以按照该标的物所在关联规则的置信度的大小降序排列,对于多个关联规则生成同样的候选推荐标的物的,可以用置信度最大的那个关联规则的置信度。除了可以采用置信度外,也可以用支持度和置信度的乘积作为排序依据。对于 4 中排序好的标的物,可以取 topN 作为推荐给用户的推荐结果。
基于关联规则的推荐算法思路非常简单朴素,算法也易于实现,Spark Mllib 中有关联规则的两种分布式实现FP-Growth和PrefixSpan,大家可以直接拿来使用(关于这两个关联规则挖掘算法的实现细节,读者可以阅读参考文献 10、11、12)。
关于关联规则算法的介绍及怎么利用关联规则进行个性化推荐,读者还可以阅读参考文献 4、5、6、7、8、9。利用关联规则做推荐,是从用户的过往行为中挖掘用户的行为模式,并用于推荐,只用到了用户的行为数据,因此利用关联规则做推荐也是一种协同过滤算法。
7.2 基于 naive bayes 的推荐算法
利用概率方法来构建算法模型为用户做推荐,可以将预测评分问题看成一个分类问题,将可能的评分离散化为有限个离散值(比如 1、2、3、4、5 一共 5 个可行的分值),那么预测用户对某个标的物的评分,就转化为用户在该标的物上的分类了(比如分为 1、2、3、4、5 个类别,这里不考虑不同类之间的有序关系)。在本节我们就利用最简单的贝叶斯分类器来进行个性化推荐。
假设一共有 k 个不同的预测评分,我们记为
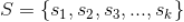
,所有用户对标的物的评分构成用户行为矩阵
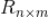
,该矩阵的
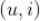
-元素记为
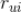
,即是用户
对标的物

的评分,取值为评分集合
中的某个元素。下面我们来讲解怎么利用贝叶斯公式来为用户
做推荐。
假设用户
有过评分的所有标的物记为
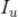
,
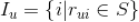
。现在我们需要预测用户
对未评分的标的物
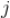
的评分
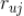
(
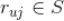
)。我们可以将这个过程理解为在用户已经有评分记录
的条件下,用户对新标的物
的评分
取集合
中某个值的条件概率:
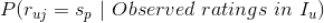
条件概率
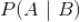
,表示的是在事件
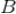
发生的情况下事件
发生的概率,由著名的贝叶斯定理,条件概率可以通过如下公式来计算:
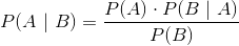
因此,回到我们的推荐问题,
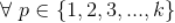
,我们有
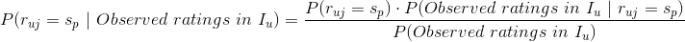
我们需要确定具体的
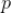
值,让上式左边的
的值最大,这个最大的值
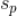
就可以作为用户
对未评分的标的物
的评分(
=
)。我们注意到上式中右边的分母的值与具体的
无关,因此右边分子的值的大小才最终决定公式左边的值的相对大小,基于该观察,我们可以将上式记为:
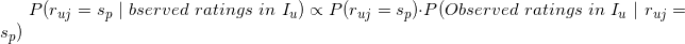
现在的问题就是怎么估计上式右边项的值,实际上基于用户评分矩阵,这些项的值是比较容易估计出来的,下面我们就来估计这些值。
1. 估计
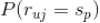
其实是
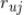
的先验概率,我们可以用对标的物
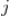
评分为
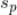
的用户的比例来估计该值,即
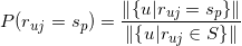
这里分母是所有对标的物
有过评分的用户,而分子是对标的物
评分为
的用户。
估计
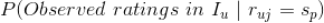
要估计
,我们需要做一个朴素的假设,即条件无关性假设:用户
所有的评分
是独立无关的,也就是不同的评分之间是没有关联的,互不影响(该假设就是该算法叫做 naive bayes 的由来)。实际上,同一用户对不同标的物评分可能是有一定关联的,在这里做这个假设是为了计算方便,在实际使用 naive bayes 做推荐时效果还是很不错的,泛化能力也可以。
有了条件无关性假设,
就可以用如下公式来估计了:
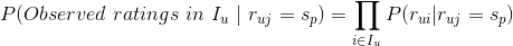
而
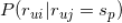
可用所有对标的物
评分为
的用户中对标的物

评分为
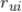
的比例来估计。即
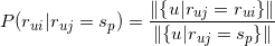
有了上面的两个估计,那么我们利用 naive bayes 计算用户对标的物的评分概率问题最终可以表示为
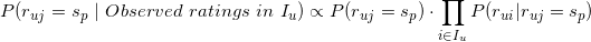
公式 1:用户对标的物评分的概率估计
有了上式,一般来说,我们可以采用两种方法来估计
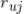
的值。
1. 类似极大似然的思路估计
该方法就是用
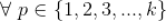
,使得
取值最大的 p 对应的
作为
的估计值,即
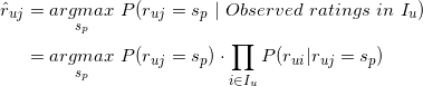
该方法仅仅将用户对标的物的评分看为类别变量而忽略具体评分的数值,而下面的方法则利用了评分的具体数值。
采用加权平均来估计
用户
对标的物
的估计
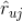
可以取
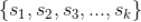
中的任一值,基于上面的公式 1,取每一个值都有一个概率估计
,那么最自然的方式是可以用这个概率作为权重,利用加权平均来估计
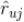
,具体的估计公式如下:
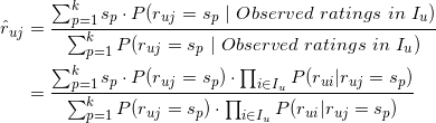
有了用户对标的物评分的估计,那么推荐就是顺其自然的事情了。具体来说,我们可以计算出用户对所有未评分标的物的估计值,再按照估计值的大小降序取 topK 作为给用户的推荐。这里说明一下,对于采用极大似然思路的估计(即上面的第一种估计方法),因为该方法是将评分看成类别变量,那么肯定有很多标的物的估计值是一样的,这时如果我们需要再区别这些评分一样的标的物的话,可以采用估计该值时的概率大小再进行二次排序。
采用贝叶斯方法来做推荐会存在一些问题,具体来说,我们在估计
和估计
时,由于样本数据稀疏,导致无法进行估计或者估计值不够鲁棒性的问题。比如在估计
时,我们用公式
来估计,从该式可以看到,如果无用户或者很少用户对标的物
有评分(这种情况是存在的,如
是新加入的标的物或者是冷门标的物),这时可能会出现用

来估计的情况,即使不是
,当分子分母都很小时,估计值波动会很大,不够鲁棒,对估计结果影响很大。一般我们可以采用拉普拉斯平滑(Laplacian smoothing)的方法来处理,得到更加稳定的估计值。
针对上面这个例子,我们来说下怎么利用拉普拉斯平滑来处理:假设
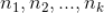
是对标的物
评分分别为
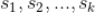
的用户数,那么上面的估计就是
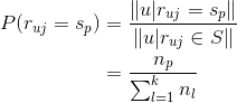
增加拉普拉斯平滑后的估计公式就是
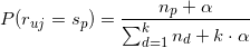
从这个公式可以看出,当没有用户对标的物
评过分时,就用

来估计,这是在没有已知信息的情况下比较合理的估计。上式中

是光滑化因子,
值越大,估计越光滑(鲁棒性越好),这时公式对数据就不够敏感。对于
的估计,也可以采用一样的方法,这里不再赘述。
到此为止,我们讲完了怎么利用 naive bayes 来为用户做推荐的方法,该方法也是只利用了用户的操作行为矩阵,所以也是一种协同过滤算法。
naive bayes 方法是一个非常简单直观的方法,工程实现也非常容易,也易于并行化。它对噪音有一定的“免疫力”,不太会受到个别评分不准的影响,并且也不易于过拟合(个人觉得前面介绍的条件无关性假设是泛化能力强的主要原因),一般情况下预测效果还不错,并且当用户行为不多时,也可以使用(需要利用拉普拉斯平滑来处理),而不像矩阵分解等算法,需要大量的用户行为才能进行推荐。
读者可以从从参考文献 13、14、15、16 中了解更多关于怎么利用贝叶斯及其他概率方法来做推荐的方案。
7.3 基于聚类的推荐算法
基于聚类来做推荐有两种可行的方案,一种是将用户聚类,另外一种是将标的物聚类。下面来简单描述一下怎么基于这两种聚类来做推荐。
7.3.1 基于用户聚类的推荐
如果我们将所有用户聚类了,就可以将该用户所在类别的其他用户操作过的标的物(但是该用户没有操作行为)推荐给该用户。具体计算公式如下,其中
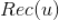
是给用户 u 的推荐,
是用户所在的聚类,
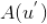
、
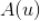
分别是用户
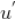
、
的操作历史集合。
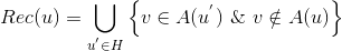
那么怎么对用户聚类呢?可行的方案主要有如下几类:
(1) 基于用户的人口统计学特征对用户聚类
用户的年龄、性别、地域、家庭组成、学历、收入等信息都可以作为一个特征,类别特征可以采用 one-hot 编码,所有特征最终都可以转化为数值的,最终获得用户特征的向量表示,通过 Kmeans 聚类算法来对用户聚类。
(2) 基于用户行为对用户聚类
比如采用矩阵分解就可以获得用户的嵌入表示,用户操作行为矩阵的行向量也是用户的一种向量表示,再利用 Kmeans 对用户进行聚类。
(3) 基于社交关系对用户聚类
如果是社交产品,用户之间的社交链条可以构成一个用户关系图,该社交图中所有的联通区域就形成了用户的一种聚类。这种推荐其实就是将你的好友喜欢的标的物推荐给你。
7.3.2 基于标的物聚类的推荐
如果有了标的物的聚类,推荐就好办了。从用户历史行为中的标的物所在的类别挑选用户没有操作行为的标的物推荐给该用户,这种推荐方式是非常直观自然的。具体计算公式如下,其中
是给用户

的推荐,
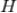
是用户的历史操作行为集合,
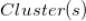
是标的物

所在的聚类。
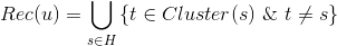
同时,有了标的物聚类,我们还可以做标的物关联标的物的关联推荐,具体做法是将标的物 A 所在类别中的其他标的物作为关联推荐结果。
那么怎么对标的物聚类呢?可行的方法有利用标的物的 metadata 信息,采用 TF-IDF、LDA、Word2vec 等方式获得标的物的向量表示,再利用 Kmeans 聚类。具体的实现细节这里不介绍,感兴趣的读者可以自行搜索相关材料做深入学习,作者在第五章《基于内容的推荐算法》中也做了比较详细的介绍。另外,也可以基于用户的历史操作行为,获得标的物的嵌入表示(矩阵分解、item2vec 等算法),用户行为矩阵的列向量也是标的物的一种向量表示。
参考文献 17、18、19、20 有更多关于怎么用聚类来做推荐的算法,感兴趣的读者可以参考学习。
到此为止,我们讲完了基于关联规则、naive bayes、聚类做个性化推荐的方法。下面我们就基于这几个方法的思想来介绍三个工业级的推荐引擎,供大家学习参考,同时也希望借助这几个工业级推荐系统的介绍让大家加深对这三个方法的思路的理解。
7.4 YouTube 基于关联规则思路的视频推荐算法
YouTube 基于关联规则思路的视频推荐算法(见参考文献 1)建立在一个基本假设基础之上:如果用户喜欢种子视频
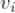
,那么用户喜欢与种子视频
相似的候选视频
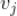
的概率一定很大,候选视频
与
越相似,那么用户喜欢候选视频
的概率也越大。那么剩下就是怎么解决这两个问题了:一是怎么计算两个视频的相似度,二是怎么选择种子视频,下面我们来分别介绍。同时,我们也会介绍最终怎么给用户生成个性化推荐。
7.4.1 计算两个视频的相似度(关联度)
该算法是利用关联规则的思路,在一定时间内(比如 24 小时内)统计两两被用户同时播放过的视频对
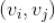
,将播放次数计为
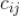
,那么候选视频
与
的相似度可以表示如下:
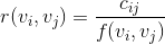
其中
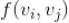
是一个归一化常数,会综合考虑种子视频
与候选视频
的“全局流行度”,如果我们分别记
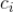
、
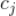
为视频
、
在上面的一段时间内总的播放次数。那么我们可以定义
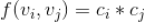
该归一化函数是非常直观简单的,用其他归一化函数也是可以的。如果用该归一化函数的话,对所有候选视频
来说,
是一样的,所以可以忽略,其实我们是用候选视频的“全局流行度”
来归一化。
在分母中,这说明
越大的视频,与种子视频
的相似度会更小,该归一化方法更加偏向于偏冷门的候选视频。
上面只是一个非常简单的描述和计算公式,我们也可以将视频的 metadata、观看时间等信息整合进来计算相似度。另外,还需要处理脏的播放行为数据。
7.4.2 基于单个种子视频生成候选视频集
基于相似度计算公式
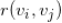
,我们可以选择出种子视频
的最相似的 topN 候选集
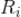
,一般我们会确定一个最小的阈值,需要相似度大于该阈值才会选出来,这也是为了避免选择很多只有很少播放量的视频(这时种子视频和候选视频被同时播放的次数也很小)导致推荐结果太差。
基于上述从种子视频选择候选视频的规则,我们可以构建一个有向图。将所有视频集合构成一个有向图,对于任何一个视频对
,如果
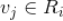
(候选视频
在种子视频
的相似视频列表集中),那么存在一条从
到
的边,边的权重为这两个视频的相似度
。
利用该方式为种子视频生成的视频候选集,可以作为视频的关联推荐,为种子视频推荐相关的视频。
7.4.3 基于用户行为为用户生成推荐候选集
上面讲到了单个视频怎么生成候选集,那么对于单个用户也是很容易采用上面的方式生成推荐候选集的。我们可以将用户播放过的视频或者明确表示过喜欢的视频作为初始种子视频集。
对于初始种子集
,我们可以采用如下方式来生成候选集:
基于上面视频的有向图解释,我们可以沿着集合
的有向边向外拓展,对于任意的种子视频
(
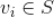
),我们考虑它的相关视频集
。我们将所有通过这种方式拓展出的视频集记为
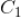
,那么我们有
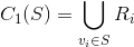
一般情况下,我们计算出
就足够获得比较多的、效果还可以的、有一定多样性的推荐候选集了。但实际上,通过这种方式生成的推荐候选集种类比较狭窄,跟用户的兴趣太相似。这种方式虽然生成了用户可能感兴趣的视频,但是可能用户没有太多惊喜,会让用户沉浸在比较小的视频范围内,就像进入了一个漩涡中,无法发现更大更精彩的世界。
为了拓展用户的候选推荐集的空间,解决上述越推越窄的问题,我们可以沿着种子视频集
所在的视频有向图进行 n 次向外拓展(用图论的术语,就是 n 次传递闭包),我们记
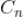
为通过种子集
中的某个种子视频通过不超过 n 次路由可达的所有视频组成的集合,那么我们有
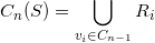
注意,
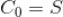
,上面的公式也跟前面提到的
的公式是兼容的。那么我们最终生成的推荐候选集就是
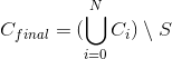
一般 N 很小(拓展很少的几步)时就可以获得非常多具备多样性的推荐结果,即使对种子集很小的用户也是如此。通过上述路径拓展,我们可以为每个候选的推荐视频关联一个种子视频(通过上述拓展,从某个种子视频到候选视频的路径就将候选视频关联到了种子视频),该种子视频既可用于后面的推荐结果排序,还可以作为推荐解释(例如如果候选视频
是通过种子视频
获得的,我们可以用“因为你喜欢/看过
”来作为推荐解释语,
与
是通过多步相似链接在一起的,它们多少是有一些相似性的,用户从这两个视频中是可以直接感知到这种相似的,所以该推荐理由是有一定说服力的)。
7.4.4 推荐结果排序
通过上面 7.4.3 中的介绍,我们可以为用户生成推荐候选集了,那么这些候选集中的视频怎么推荐给用户呢?也即我们怎么对这些候选视频排序呢?我们需要将用户更愿意点击的排在前面。
我们可以从视频质量、用户对视频的偏好度、多样性等几个维度来考虑。
视频质量是指视频本身的吸引力,比如视频的海报清晰度、视频播放次数、视频被点赞的次数、视频被转载的次数、视频被收藏的次数等。这些不同维度的视频质量,我们可以通过打分获得一个固定的质量得分,具体打分方式可以多种多样,这里不再细说。我们这里记视频
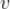
的质量为
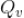
。
通过前面的介绍我们知道每个候选视频是通过某个种子沿着有向图通过若干步的拓展获得的。如下图,假设候选视频
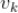
是通过种子视频
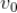
经过 k 步获得,下图中箭头上方的
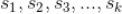
是相邻两个视频的相似度。
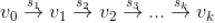
那么用户对视频
的偏好度可以用如下公式来计算
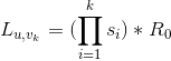
其中,
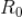
是用户对视频
的偏好度及它自身的受欢迎程度,我们可以通过用户播放
的时长或者
总播放量等数值来度量。
如果从
到
有多条路径,可以选择最短的路径,这是因为我们是一步一步拓展获取候选集的,当某个视频被某一步拓展到了,后面再拓展到它时,前面已经计算了,所以在这一步就忽略掉。
有了上面介绍的候选视频得分及用户对视频的偏好度,我们可以用下面公式来计算用户
对视频
最终的评分:
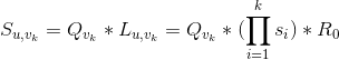
通过将所有候选视频按照上述公式降序排列就可以得到候选视频的排序了。利用上面公式,距离用户种子视频集
越远,通过公式
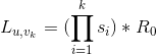
的相似性连乘得到的值也越小,那么就有可能排在后面了。那么我们怎样解决这个问题获得多样性呢?一般我们可以通过限制由同一种子视频生成的候选视频的数量来获得多样性(因为同一种子视频生成的视频多少是有一些相似度的),或者限制由同一渠道产生视频数量(比如由同一个用户上传的视频)。通过在上述排好序的推荐列表中,剔除掉部分由同一种子视频生成的视频或者同一渠道产生的视频,就可以获得最终的推荐结果。
上面介绍的就是 YouTube 基于视频被用户共同观看的次数获得视频之间的相似度,进而通过视频相似度传递获得最终推荐的方法。该方法本质上就是关联规则的思路,只用到了用户的播放行为信息,因此也是一种协同过滤算法。
7.5 Google News 基于贝叶斯框架的推荐算法
前面 7.2 节简单讲了怎么利用 naive bayes 算法来为用户生成个性化推荐的一般思路,在这一节我们讲解 Google News 利用贝叶斯框架来做推荐的具体方法。Google 的这篇文章(参考文献 2)采用另外的思路,基于用户过去看新闻的历史行为利用贝叶斯框架来预测用户当前对新闻的兴趣,再结合协同过滤来做推荐。下面我们来讲解该篇文章的核心思想。
7.5.1 基于用户过去的行为来分析用户的兴趣点
首先将所有新闻按照事先确定好的类别分成若干类(主题):
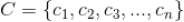
,如“世界”、“体育”、“娱乐”等类别。
首先计算某个用户
在某段时间周期

(比如按照一个月一个周期等)内的点击行为在上述类别上的分布,记为
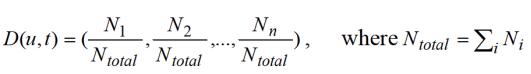
公式 1:用户 u 在时间周期 t 内的行为在新闻主题上的分布
这里,
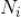
代表用户
在时间周期
内点击主题类别
的次数。
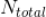
是该用户在这段时间周期内点击新闻的总数量。
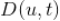
表示用户
在时间周期
内在各个新闻主题类别上的时间花费分布,反映了用户的兴趣分布。
新闻是有地域差异性的,同样地,类似单个用户的兴趣偏好分布,我们可以统计某个国家或者某个地区的所有用户点击行为的整体在时间周期
内在上述新闻主题上的分布。我们将该分布记为
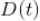
。计算方法和上面单个用户一样,将该国家或地区所有用户当成一个整体来计算。
该文章通过大量的数据分析,最终得到如下 4 个结论,后面的贝叶斯框架也是基于这几个结论来展开的。细节的分析读者可以阅读参考文献 2。
(1) 用户的兴趣确实随着时间变化;
(2) 公众对新闻的点击分布反映了兴趣的发展趋势,并受到重大事件(如世界杯等)的影响;
(3) 不同国家/地区对新闻的偏好是不一样的,存在不同的发展趋势;
(4) 从某种程度上说,单个用户的兴趣变化趋势是受到该用户所在国家/地区的新闻趋势变化影响的;
有了上面的基本概念和初步数据分析得到的结论作为基础,下面我们来说明怎么用贝叶斯框架来为用户的兴趣建模。
7.5.2 利用贝叶斯框架来建模用户的兴趣
我们可以将用户的兴趣分为两种:一种是用户的真实兴趣,一种是会受到国家/地区大的兴趣趋势影响的临时兴趣。用户的真实兴趣是由用户的性别、年龄、受教育程度、专业等决定的,它是相对稳定的,不太会随着时间而急剧变化。另一方面,当用户觉得要读什么新闻时,是会受到用户所在区域新闻趋势的影响的,这种影响是短期的,是随着时间变化的。
基于用户点击行为模式和用户所在地群体的行为模式,可以通过贝叶斯框架很好地预测用户当前对新闻的兴趣,具体可以通过如下三个步骤来获得用户的当前兴趣。
(1) 预测用户在某个时间周期内的真正兴趣
对于特定时间周期
内的某个用户
,
是用户在所有新闻主题上的点击分布,
是用户所在地域整体用户的兴趣分布,代表的是兴趣趋势。我们期望学习用户的从
呈现出的而不会受到
干扰的真实兴趣。
我们用
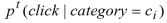
来表示用户在新闻主题
上的真实兴趣,它是一个条件概率,表示在新闻主题为
的条件下,用户进行点击的概率。利用贝叶斯公式,我们可以采用下式来计算
。
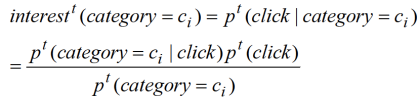
公式 2:用户点击属于主题
的文章的概率
上式中
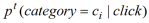
是用户点击的所有新闻中该新闻属于主题
的概率,它可以从用户的点击分布
中估算出(参见上面的公式 1,可以用
的第 i 个分量来估算)。
而
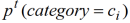
是新闻属于主题
的先验概率,也就是在时间周期
内所有发布的新闻属于类别
的比例,它与用户所在地域的新闻变化趋势相关,如有有更多的有关主题
的新闻事件发生,那么关于主题
的新闻就会越多。我们可以用整体分布
中的第 i 个分量来近似估计
。
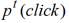
是用户点击任何一个类别的文章的先验概率,与具体的文章主题无关。
从上面公式 2 知道,
表示用户对主题
的感兴趣程度,不同于该地区其他用户的兴趣。如果用户读了很多体育类的新闻,而很多其他用户也读了体育类新闻,这可能是有一些体育相关热点事件引起的。相反,如果该用户阅读了大量体育新闻而该地区其他用户很少读体育新闻,这就代表的是用户真的对体育感兴趣。
(2) 结合用户在不同时间周期的兴趣,获得用户精确的与时间无关的真实兴趣
上面(1)中计算了用户在一个时间周期
内的兴趣偏好,我们可以将用户在过去统计周期内所有时间周期的兴趣归并起来获得用户综合的对新闻类别的真实兴趣偏好,具体参见下面公式的计算逻辑。

上式中
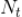
是用户在时间周期
内总的新闻播放量。我们可以假设用户在所有时间周期内点击一篇新闻的先验概率是固定不变的,也即假设上式中的
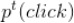
与时间周期
无关,我们记为
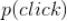
。那么上式可以改写为下面的
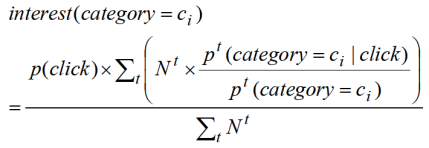
公式 3:用户在过去统计周期内所有时间段的综合兴趣
上面的公式 3 就是用户的真实兴趣,该兴趣其实是用户在多个时间周期内的兴趣的某种加权平均。
(3) 结合用户真实兴趣和当前的新闻趋势,预测用户当前的兴趣
如前面所说,用户的兴趣可以分解为两部分,一部分是用户长期的的真实兴趣,另外一部分是受到当前趋势影响的短期兴趣。(1)、(2)基于用户过去的点击播放行为计算出了用户的长期的真实兴趣。为了度量用户当前对新闻的短期兴趣,我们用用户所在地域的所有用户在一个较短时间段(比如过去一个小时)的整体点击分布来刻画(用
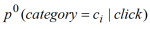
来表示),由于所在地域有大量用户,在这段较短时间内也有足够多的数据来准确计算出哪些新闻主题是热门的。
我们的最终目标是预测用户在将来一段时间的点击分布,同样地,我们可以用贝叶斯公式得到下面的计算公式:

我们用用户的真实兴趣
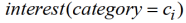
(公式 3)来估计
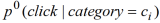
,并且假设用户点击任何一篇新闻的概率为常数,不受时间影响(即假设
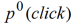
=
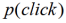
),那么上式就可以表示为(将公式 3 代入进来)

我们可以在上式中加上一个虚拟点击项,它跟当前新闻趋势的概率分布
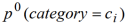
同分布,那么用户在未来短时间内对新闻的兴趣偏好概率最终变为
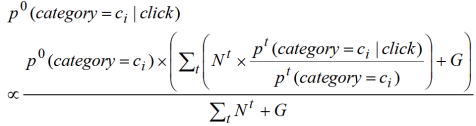
公式 4:用户当前对新闻主题的兴趣偏好概率
上式中的
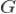
就是虚拟点击数(在参考文献 2 中取值为 10),它可以看成是一个光滑化的因子,当某个用户只有非常少的点击历史时,这时是用户当前的新闻趋势(
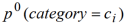
)来预估该用户的点击概率,这在没有太多该用户历史数据的情况下是一个合理的估计。当
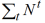
远远大于
时,上式就可以忽略
,还原为用户真实的点击分布预估。
上述预估用户将来短时间内的兴趣分布的方法的一个重要优点是,我们可以增量地计算用户的点击分布。我们可以将过去每个时间周期
对应的
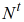
和
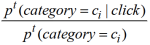
的值事先存起来,当更新用户的兴趣偏好概率时,只需要将最近一个时间周期的值计算出,利用上面的公司 4 及预先存下来的过去时间段的值就可以得到用户最新的兴趣偏好分布。
7.5.3 为用户做个性化推荐
为了对推荐候选集进行排序获得最终的推荐结果,该推荐算法计算出两个统计量:一个是

,称之为信息过滤得分,另外一个是
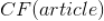
,即协同过滤得分(利用协同过滤算法预测的用户对新闻的得分,可以利用参考文献 3 中的方法得到)。其中
的计算过程是这样的,先获得该文章的类别
,再基于上面的公式 4 得到用户对类别
的的偏好概率,该值作为
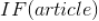
的值。我们将这两个得分相乘,最终利用如下的公式来计算用户对某个新闻的兴趣得分。
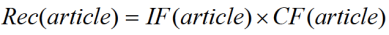
最终基于上述公式计算出该用户对所有新闻的得分,取得分最高的 topN 作为最终的推荐结果。该方法通过在 Google news 上验证,比单独采用协同过滤有更好的预测效果。
该方法利用用户过去及用户所在地区的点击行为来预测用户当前对新闻的偏好概率,再与协同过滤结合进行最终的推荐。预测用户兴趣偏好概率的过程只用到了用户及用户所在地域全体用户对新闻的点击数据,因此也是一种协同过滤方法。细节的实现方案,读者可以阅读参考文献 2 进行进一步了解。
7.6 Google News 基于用户聚类的推荐算法
参考文献 3 中利用了 3 种模型来预估一个用户对一个新闻的评分,最终通过加权平均获得用户对新闻的最终评分,其中第三种方法 covisitation 的思想我们在第 6 章《协同过滤推荐算法》第 6 节“近实时协同过滤算法的工程实现“有详细讲解,本质上是一种关联规则的思路,我们这里不再介绍。另外两种算法分别是基于 MinHash 和 PLSI 聚类的方法,在这里我们只介绍 MinHash 算法,PLSI 算法读者可以自行阅读参考文献 3 来了解。
7.6.1 基于 MinHash 聚类
对于用户
,他的点击历史记为
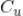
。那么两个用户
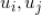
的相似度可以用 Jaccard 系数来表示:
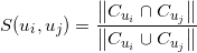
有了两个用户之间的相似度,我们可以非常形式化地将相似用户点击过的新闻通过上面的相似度加权推荐给用户
。但是用户数和新闻数都是天文数字,无法在极短时间内为大量用户完成计算。这时,我们可以采用 LSH(Locality Sensitive Hashing)的思路来计算,大大减少计算复杂度。LSH 的核心思想是,对于一组数据(对于我们这个场景来说,这一组数据就是用户的历史点击记录
),我们可以用一组哈希函数来获得哈希值,如果两组数据非常相似,那么哈希值冲突的概率也越大,而冲突率是等于这两组数据的相似度的。当我们用 Jaccard 系数来计算用户点击历史的相似度时,这时的 LSH 就叫做 MinHash。
我们先来说明怎么为一个用户
计算 hash 值,所有新闻集为
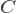
,我们对集合
进行一次随机置换,置换后的有序集合记为
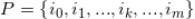
(
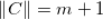
,即一共有 m+1 条新闻),我们计算用户
的哈希值为
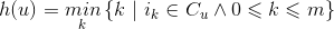
上式表示的意思是,按顺序从左到右数,
中第一个包含在
中的元素的下标就是
的哈希值。
可以证明(有兴趣的读者可以自行证明,或者参考相关参考文献),两个用户
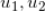
的哈希值冲突(值一样)的概率就是
用 Jaccard 系数计算的相似度。所以我们可以将 MinHash 认为是一种概率聚类方法,对应的哈希值就是一个类:
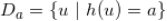
,所有哈希值为

的用户聚为一类
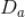
。
我们可以取
个置换(即
个哈希函数),将这
个哈希函数得到的哈希值拼接起来,那么两个用户
这
个拼接的哈希值一样的概率就等于
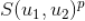
。很显然,通过将
个哈希值拼接起来得到的聚类更精细(
个哈希值都相等的用户肯定更少,所以类
更小,更精细),并且相似度也会更高。从找用户最近的领域(最相似的用户)的角度来看,将
个哈希值拼接起来的方法的精准度更高,但是召回率更低(聚类更小了,因此召回的新闻更少了,所以一般召回率就降低了),为了提升召回率,获得更多的相似用户,我们可以将这个过程并行进行
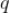
次,最终每个用户获得
个聚类,相当于进行了
次召回,在论文中作者建议
取 2 到 4,
取 10 到 20。
在实际的工程实践上,由于新闻数量太大,进行置换操作耗时很大,可以采用简化的思路(精度会打折扣),对于上面提到的
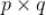
个哈希函数(置换),我们事先取
个独立的随机种子值与之一一对应,每个随机种子就是哈希函数的替代。对于每个新闻及每个种子值,我们利用该种子值和该新闻的 Id(是整数值),利用一个特定的哈希函数
计算出一个哈希值,该哈希值作为利用前面讲的通过置换后该新闻的下标,那么采用这种方法后用户
的哈希计算公式如下:
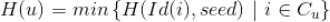
该方法不需要对新闻集进行置换,会大大减少计算量,并且只要这个特定哈希函数
的取值范围在 0 到
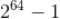
之间,那么冲突概率就会比较小,通过这种近似的 MinHash 值与真正的 MinHash 值性质近似。
上面讲解了 MinHash 聚类的算法实现细节,具体工程实现时是可以用 Hadoop 或者 Spark 等分布式计算平台来并行计算的,这里不细说。我们可以将每个用户的聚类及每个聚类包含的用户用倒排索引表的格式存储起来,方便后面做推荐时查阅。
7.6.2 基于聚类为用户做推荐
有了用户的聚类,我们可以采用如下步骤来为单个用户生成个性化推荐,每个用户的推荐策略是一样的,所以可以采用分布式计算平台 Spark 等工具来并行化处理。
(1) 计算出用户
对新闻
的评分
(2) 计算出用户
对所有新闻的评分
(3) 将所有新闻评分降序排列,取 topK 作为该用户的推荐
上面的(2)、(3)是非常简单的处理,我们重点来说一下(1),怎么计算用户
对新闻
的评分。首先我们可以得到用户
所属的所有类别
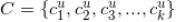
,对于每个类别
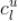
,取出该类别中所有的用户对新闻
的点击次数之和(我们可以事先将每个类别中用户点击过的新闻及次数存储起来,方便查找),再除以该类别所有点击之和,得到该类别对新闻
的评分,那么用户
所属的类别对新闻
的总评分为:
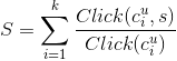
这里的
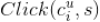
即是刚刚提到的类
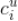
中所有用户对新闻
点击次数之和,
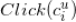
是类
所有用户的所有点击次数之和。我们用上式计算出的
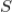
来表示用户
对新闻
的评分。
至此,基于作者自己的理解,简单介绍完了 Google News 基于用户聚类的推荐算法。该方法也只用到了用户及其他用户的新闻点击行为,因此也是一种协同过滤算法,该算法的细节读者可以阅读参考文献 3。参考文献 17、18、19、20 有更多关于怎么用聚类来做推荐的算法,感兴趣的读者可以参考学习。
总结
本章讲解了关联规则、朴素贝叶斯、聚类等三类基础机器学习算法怎么用于个性化推荐的理论知识,同时从算法原理和工程实现的角度简单总结了 YouTube 和 Google News 的三篇分别采用关联规则、朴素贝叶斯、聚类思路来做推荐的论文。这几篇论文有很强的工程指导意义,值得读者学习。
虽然这些算法原理简单、容易理解,看起来不那么高大上,但是这些算法却在工业界有过非常好的应用,在当时算是非常优秀的算法。这些算法现在可能看起来太简单了,也可能不会用在现在的推荐系统上,但它们朴素的思想下面蕴含的是深刻的道理,值得我们推荐从业者学习、思考、借鉴,希望读者可以很好地理解它们,并吸收这些朴素思想背后的精华。
参考文献
1. The YouTube Video Recommendation System
2. Personalized News Recommendation Based on Click Behavior
3. Google news personalization: Scalable online collaborative flitering
4. Robustness of collaborative recommendation based on association rule mining
5. Analysis of recommendation algorithms for e-commerce
6. Fast algorithms for mining association rules
7. Efficient adaptive-support association rule mining for recommender systems
8. Mining navigation history for recommendation
9. Collaborative filtering by mining association rules from user acess sequences
10. Mining frequent patterns without candidate generation
11. Pfp: parallel fp-growth for query recommendation
12. Mining sequential patterns by pattern-growth: the PrefixSpan approach
13. Empirical analysis of predictive algorithms for collaborative filtering
14. A Bayesian model for collaborative filtering
15. Collaborative filtering with the simple Bayesian classifier
16. Probabilistic memory-based collaborative filtering
17. Clustering methods for collaborative filtering
18. Rectree: A efficient collaborative filtering method
19. Scalable collaborative filtering using cluster-based smoothing
20. Latent class models for collaborative filtering
版权声明: 本文为 InfoQ 作者【数据与智能】的原创文章。
原文链接:【http://xie.infoq.cn/article/0dff50a168199ed6c6456abca】。文章转载请联系作者。

还未添加个人签名 2018.05.14 加入
公众号【数据与智能】主理人,个人微信:liuq4360 12 年大数据与 AI相关项目经验, 10 年推荐系统研究及实践经验,目前已经输出了40万字的推荐系统系列精品文章,并有新书即将出版。









评论