
华为云数据库 DDS 产品深度赋能

声明:本文参考自《华为云开发者学堂》,华为云数据库 DDS 产品深度赋能,主要面向 DA、交付、一线、二线数据库从业者,针对 DDS 常见问题及产品特性进行介绍,涉及:产品特性介绍、产品使用场景介绍、产品常见问题介绍、DDS 实例使用规范及最佳实践介绍、DDS 副本集内部机制和分片集群内部原理介绍等。
本文适合数据库解决方案工程师(DA)、数据库交付工程师、数据库一线 &二线从业者、以及对 DDS 感兴趣的用户,希望读者可以通过本文通过华为云数据库 DDS 产品深度赋能课程的学习,加强 DA、交付、一线、二线对数据库产品的理解和技能提升。
本文分为 5 个章节展开讲解:
第 1 章 华为云数据库 DDS 产品介绍
第 2 章 DDS 业务开发使用基础
第 3 章 了解 DDS 内核原理
第 4 章 快速使用分片集群
一、 华为云数据库 DDS 产品介绍
1. DDS 概述
首先我们要了解一下 DDS 的一些基础信息:
文档数据库 DDS(Document Database Service)完全兼容 MongoDB 协议,也就是正常 MongoDB 如何使用,DDS 就如何使用,在华为云高性能、高可用、高安全、可弹性伸缩的基础上,提供了一键部署,弹性扩容,容灾,备份,恢复,监控等服务能力。目前支持分片集群(Sharding)、副本集(ReplicaSet)、单节点(Single)三种部署架构。
MongoDB 的数据结构


编辑
MongoDB 存储结构
• 文档(Document):MongoDB 中最基本的单元,由 BSON 键值对(key-value)组成。
相当于关系型数据库中的行(Row)。
• 集合(Collection):一个集合可以包含多个 文档,相当于关系型数据库中的表(Table)
• 数据库(Database):等同于关系型数据库中的数据库概念,一个数据库中可以包含多个集合。您可以在 MongoDB 中创建多个数据库。
2. DDS 部署形态及关键特性
2.1DDS 服务部署形态-单节点(Single)
架构特点
1.超低成本,仅需支付一个节点的费用
2.支持 10GB-1000GB 的数据存储;
3.较副本集/集群可用性不高:当节点故障,业务不可用;
适用场景
非核心数据存储
学习实践;
测试环境的业务;
2.2 DDS 服务部署形态--副本集(Replica Set)
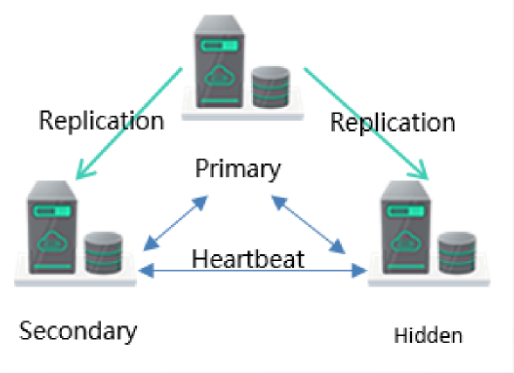
编辑
上图为一个经典的三副本形态
架构特点
1. 三节点高可用架构:当主节点故障时,系统自动选出
新的主节点
2.支持 10GB-3000GB 数据存储;
3. 具备扩展到 5 节点,7 节点副本集的能力。
适用场景
有高可用需求,数据存储<3T
2.3 DDS 服务部署形态--集群(sharding)
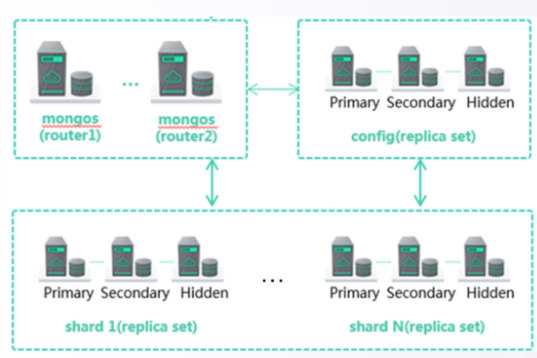
编辑
架构特点
1. 组件构成:由 mongos(路由)、config(配置)、shard(分片)三种类型的节点构成
2. Shard 分片:每个 shard 都是一个副本集架构,负责存储业务数据。可创建 2-16 个分片,每个分片 10GB-2000GB。因此,集群空间范围( 2-16)*(10GB-2000GB)
3. 扩展能力:在线规格变更、在线横向扩展
适用场景
要求高可用,数据量大且未来横向扩展要求
2.4 DDS 关键特性
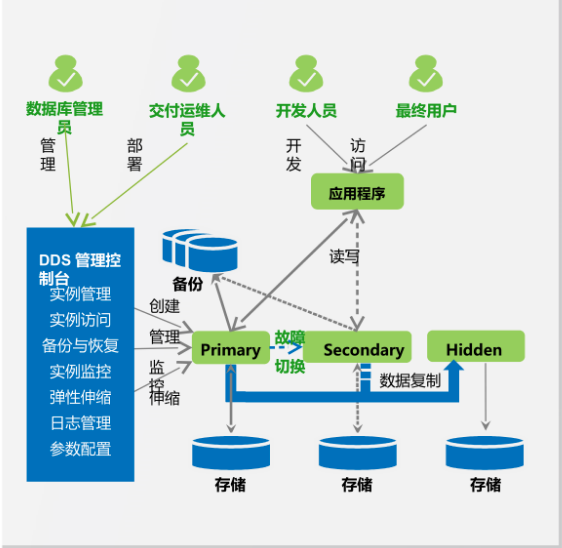
编辑
文档数据库 DDS 主要特性集
• 数据库类型及版本:兼容 MongoDB 3.4/4.0 版本
• 数据安全:多种安全策略保护数据库和用户隐私,例如:VPC、子网、安全组、SSL 等
• 数据高可靠:数据库存储支持三副本冗余,数据库数据可靠性高;备份数据可靠性高
• 服务高可用(同城容灾):集群/副本集实例支持跨 AZ 部署,服务可用性高
• 实例访问:多种访问方式,包括:内网 IP 访问、公网 IP 访问
• 实例管理:支持实例的创建、删除、规格变更、节点扩容、磁盘扩容、重启等生命周期管理
• 实例监控:支持监控数据库实例 OS 及 DB 引擎的关键性能指标,包括 CPU/内存/存储容量使用率、1/O 活动、数据库连接数等
• 弹性伸缩:水平伸缩:增删 shard 分片(最多 16 个);垂直伸缩:实例规格变更,存储空间扩容(最大 n*2TB)
• 备份与恢复:备份:自动备份、手动备份,全量备份、增量备份,备份文件的增、删、查、复制等生命周期管理。恢复:副本集支持恢复到备份保留期内任意时间点(Point-In-Time Recovery, PITR)/某个全量备份时间点,恢复到新实例/原实例。备份保存周期高达 732 天
• 日志管理:支持慢 SQL 日志、错误日志的查看、以及审计日志下载
• 参数配置:可以根据监控和日志等信息,通过管理控制台对数据库实例的参数进行自定义设置,从而优化数据库。另外管理控制台对参数组提供了增、删、改、查、重置、比较、复制等一系列的参数管理的能力。
3. DDS 产品优势及应用场景
3.1 DDS 的产品优势
MongoDB
• 100%兼容 MongoDB
• 具备无需业务改造,直接迁移上云的能力
• 支持社区 3.4/4.0 版本
3 种架构
• 集群、副本集、单节点
• 集群:nTB 存储、在线扩容
• 副本集:2TB 存储
• 单节点:高性价比
高可用
• 架构高可用、跨 AZ 部署
• 支持副本集,Shard 高可用架构(集群)
• 副本集多节点(三、五、七)
• 集群、副本集支持跨 AZ 部署
高可靠
• 自动/手动备份,数据恢复
• 每天自动备份,保留 732 天
• 手动备份,永久保存
• 备份恢复
高安全
• 具备多层安全防护
• 网络:VPC 网络隔离
• 传输:SSL 安全连接
• 访问:安全组出、入限制
管理、监控
• 可视化监控:CPU、内存、10、网络等
• 实例一键扩容、规格变更
• 错误日志、慢日志管理
• 参数组配置
3.2 DDS 应用场景
灵活多变的业务场景
DDS 采用 No-Schema 的方式,避免变更表结构的痛苦,非常适用于初创型的业务需求。
游戏应用
作为游戏服务器的数据库存储用户信息,用户的游戏装备、积分等直接以内嵌文档的形式存储,方便进行查询与更新。
视频直播
存储用户信息,礼物信息等
3.3 DDS 使用场景举例:业务弹性扩展,数据结构灵活
游戏行业业务和数据特点
1.用户信息和交易数据存储在 MySQL 中。
2.角色装备数据及游戏的过程日志存储在 DDS 中
3.游戏业务变化频繁,对于数据表需要做结果变更 DDS 修改表结构对业务无影响。
客户痛点(私有云部署)
1.资源不具备弹性伸缩,需要停服然后手工操作,风险极高。
2.没有数据库的故障自动切换机制或能力不足,主实例故障,修改应用配置,停服时间长。
3.很少设置专职 DBA 岗位,遇见数据回档场景,很难满足运营的诉求。
4.游戏玩法变化快,数据模型灵活变化
华为云数据库的解决方案
1.高性能
RDS MySQL 和 DDS 性能超越阿里云。
2.弹性伸缩
RDS 和 DDS 支持磁盘的弹性扩容,对业务无影响。
3.一键回档(游戏业务数据诉求)
RDS 和 DDS 支持表级和实例别任意时间点的回档。
4. 快读开服
RDS 和 DDS,可使用备份创建新实例,实现快速开服。
5.故障切换
RDS 和 DDS 主备故障秒级别切换,对业务透明,应用配置无需改动。
4. DDS 管理控制台及运维指南
DDS 服务首页
编辑
DDS 实例创建-1
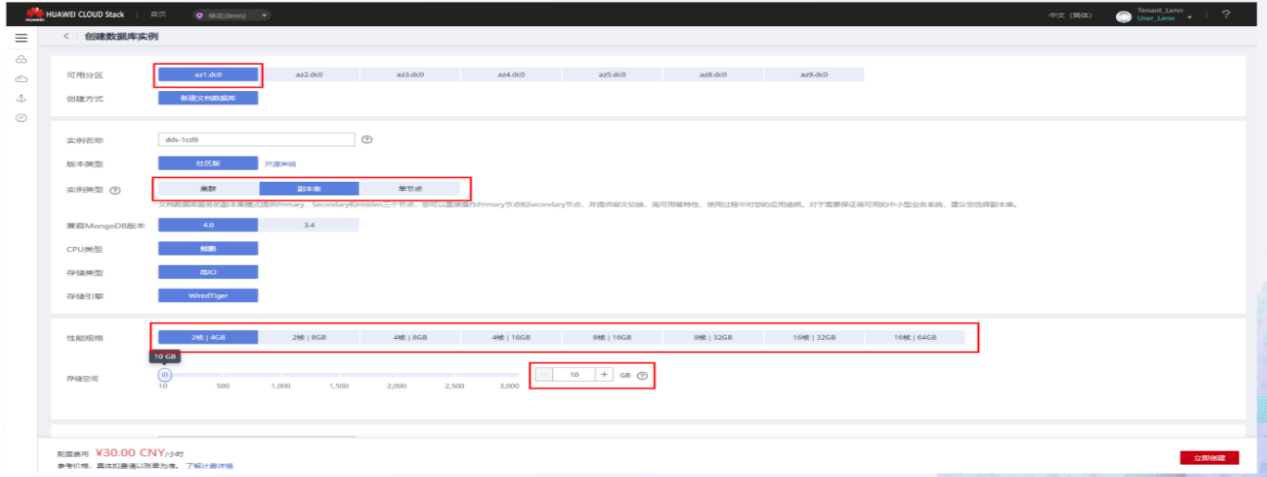
编辑
DDS 实例创建-2
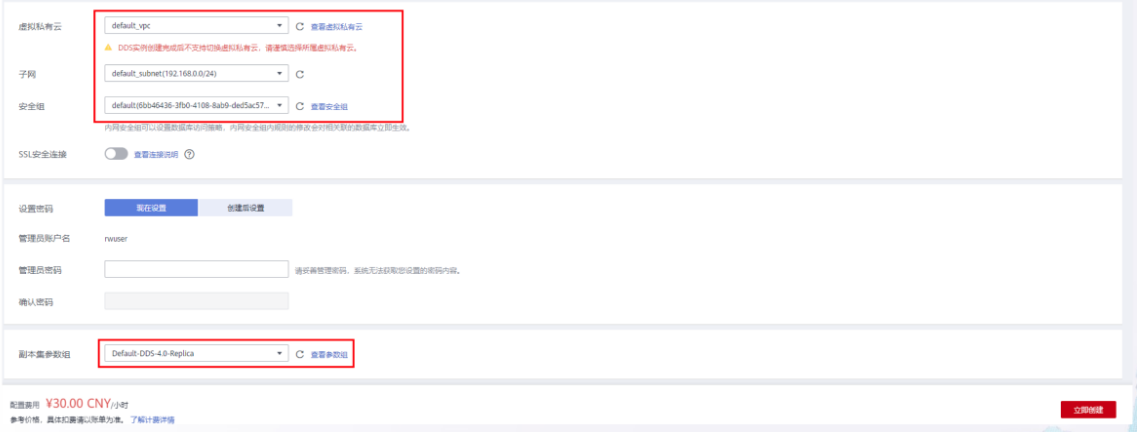
编辑
DDS 实例详情
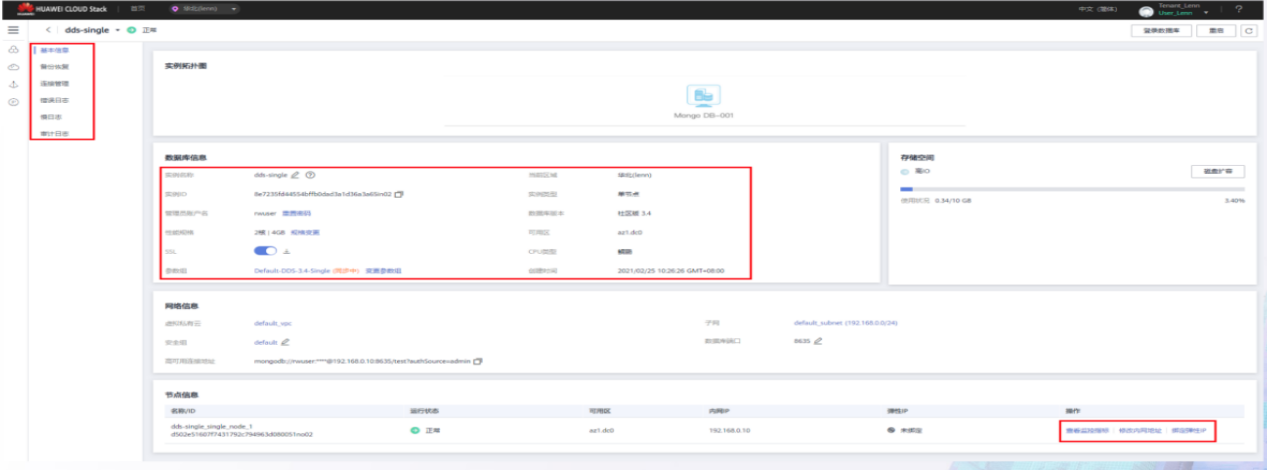
编辑
二、 DDS 业务开发使用基础
1. DDS 高可用连接方式
分片集群高可用址:
mongodb://wuser;****@192.168.0.204:8635.192.168.0.94:8635/test?authSource=admin
多个 mongosIP 配置在客户端 Driver 进行负载均衡
单个 mongos 故障,其他 mongos 正常运行
副本集和分片集群实例连接失败场景:
• 网络端口不通,安全组,跨 vpc
• 是否开启 SSL 安全连接
• 连接参数错误,用户名、密码错误
• DDS 实例连接占满,无法创建新连接
• DDS 实例内存、CPU 过高
• 更多详情参考官方指南:https://support.huaweicloud.com/dds fa/dds_faq_0218.html
2. DDS 用户认证及创建
2.1 用户认证用户,角色,权限,对象 模型 ---- 基于 admin 库创建并管理用户角色用户:userA,userB,userC,角色:role1,role2,role3 权限:userAdmin,readWrite.…
对象:db,collection(action)
查看当前用户及角色: use admin
db.runCommand({rolesinfo: 1});db.runCommand({ userslnfo: 1} );举例几个常用用户角色:管理用户及角色账号:userAdminAnyDatabasedb.createUser({user:"user_admin,pwd:"YourPwd_234",roles:[{role:"userAdminAnyDatabase",db:"admin")管理数据库账号:dbAdminAnyDatabasedb.createUser(fuser:"dbadmin"pwd:"YourPwd 234"roles:[{role:"dbAdminAnyDatabase",db:"admin"}l})·指定库的管理账号:dbAdmindb.createUser({user:"db_admin_db1",pwd:"YourPwd_234",roles:[{role:"dbAdmin",db:"db1"}I})全库的只读账号:readAnyDatabasedb.createUser({user:"db_read",pwd:"YourPwd_234",roles:{role: "readAnyDatabase",db:"admin"}})·指定库的读写账号:readWritedb.createUser({user:"db_rw_db2",pwd:"YourPwd_234",roles:[{role:"readWrite",db:"db2"}l})
2.2 创建权限用户
管理用户登录后可管理库表不可读写数据
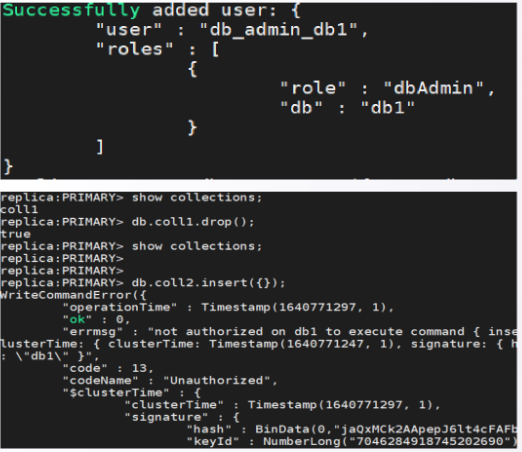
编辑
只读用户登录后可读不可写
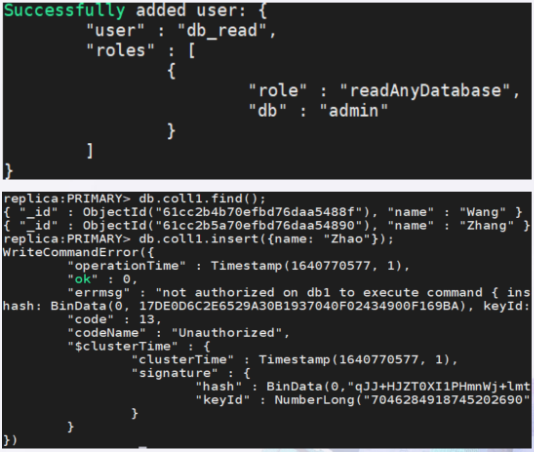
编辑
3. DDS 用连接参数读写分离
3.1 读写分离场景的选择
• 生产环境的高可靠运转,核心组件高可用,提高系统整体可用性及服务质量
• 结合节点部署形态理解 :
•https://supporthuaweicloud.com/bestpractice-dds/dds_0003.html
• 读写分离的使用场景
• 怎么选择读参数 Read Preferenceprimary(只主)只从 primary 节点读数据,这个是默认设置 primaryPreferred(先主后从)优先从 primary 读取,primary 不可服务,从 secondary 读 secondary(只从)只从 scondary 节点读数据 secondaryPreferred (先从后主)优先从 secondary 读取,没有 secondary 成员时,从 primary 读取 nearest(就近)根据网络距离就近读取,根据客户端与服务端的 PingTime 实现
3.2 读写分离配置使用举例
读写分离配置使用举例:
可以通过 uri 连接参数配置,也可以再单次查询操作的时候配置读取偏好 mongodb://db_rw_db2:YourPwd_234@IP1:port1,IP2:port2/db2?
authSource=admin&replicaSet=replica&readPreference=secondaryPreferred
replica:PRIMARY> db.coll1.find().readPref("secondary");
2021-12-29T11:56:09.435+0000 I NETWORK [js] Successfully connected to 192.168.2
"id":0bjectId("61cc2b7270efbd76daa54891"),"age": 13 }
id" ObjectId("61cc2b7970efbd76daa54892"),"age": 14 }
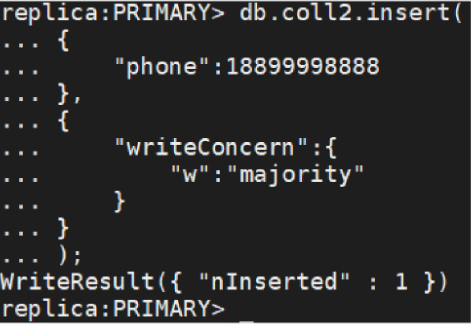
4. DDS 写策略配置
一致性和可用性的一场较量----- 可调一致性参数
• 写入策略 writeConcern 参数使用及默认值
·db.collection.insert({x:1},{writeConcern:{w:1}})
·mongodb://db_rw_db2:YourPwd 234@IP1:port1P2:port2/db2?
authSource=admin&replicaSet=replica&w=majority&wtimeoutMS=5000
• 分区容错不可避免
• 业务数据一致性:实时一致性,最终一致性{w:n} {w:“majority"}w 默认是 1
• 系统服务可用性:读写操作的延迟容忍度多节点数据同步依赖 oplog 复制到备节点
• 业务特征来平衡选择以上参数取值
写操作策略再连接参数中指定
编辑
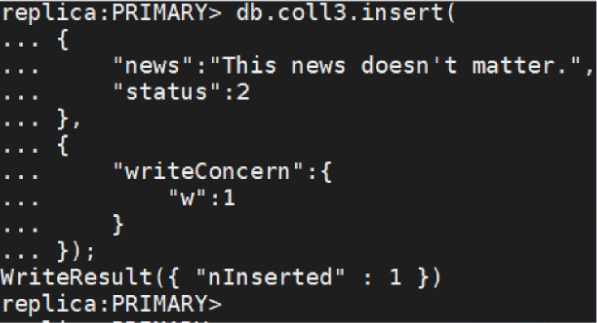
写操作策略再单次操作参数中指定
编辑
三、 了解 DDS 内核原理
1. DDS 服务部署模型概述
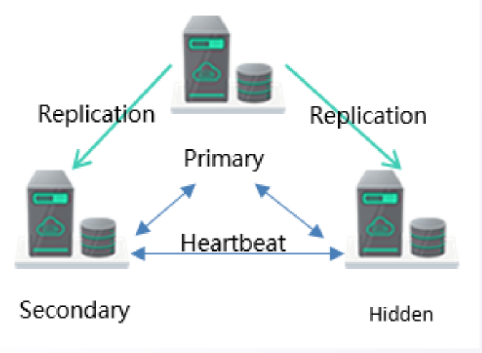
编辑
架构特点
1.高可用服务方式,自动故障转移,读写分离场景
2.支持 10GB-3000GB 数据存储;
3.具备扩展到 5 节点,7 节点副本集的能力。
适用场景
有高可用需求,数据存储<3T
2. DDS 心跳及选举
2.1 DDS 心跳及选举
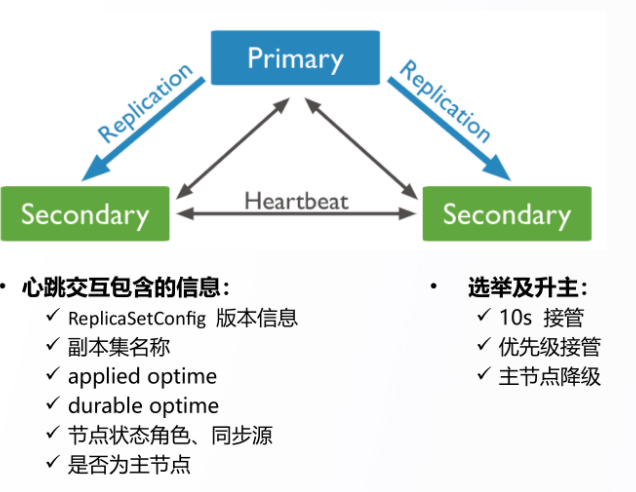
编辑
• 副本集内,节点之间
• 默认情况,间隔 2s
• 10s 未收到主节点响应主动选举
• 实现自动故障转移
胜选:
数据相对最新的节点获得大多数节点选票
2.2 DDS 自动故障转移
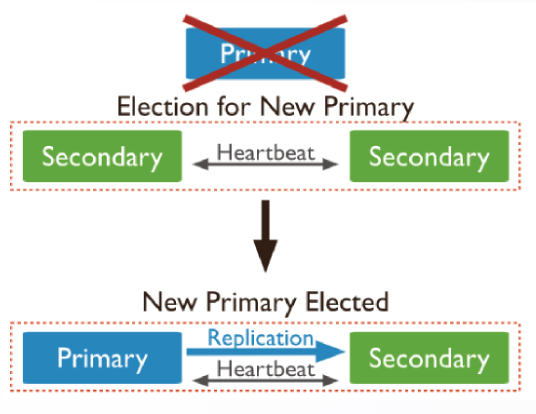
编辑
副本集节点角色:
• Primary
• Secondary
• Hidden
• Arbiter
故障转移
• Primary 发生异常(节点心跳未正常)
• Secondary 发起选举,主动接管
• Driver 连接副本集正常业务读写
2.3 DDS 副本集管理
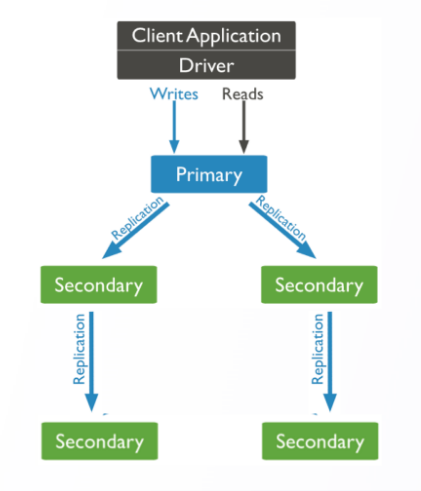
编辑
副本集管理:
• 副本集配置初始化 rs.initiate()
• 副本集添加成员 rs.add()
• 副本集删除成员 rs.remove()
• 副本集配置查看 rs.config()副本集配置重置 rs.reconfig()
• 副本集状态查看 rs.status()
3. DDS 数据同步和复制
3.1 DDS 数据同步
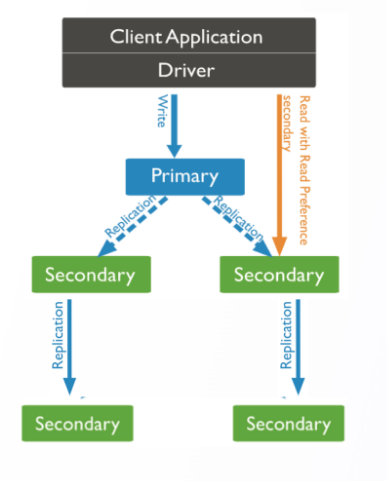
编辑
多个副本集内数据同步:
• 副本集内,一个 Primary,多个 Secondary
• 备节点可以承载读取能力
• 备节点选择同步源:主节点 or 其他比自己数据更新的节点
• 允许链式复制,减缓主节点压力
• 数据通过操作记录重放在备节点
• 随着数据复制推移备节点最新操作时间戳
3.2 DDS 数据同步详解
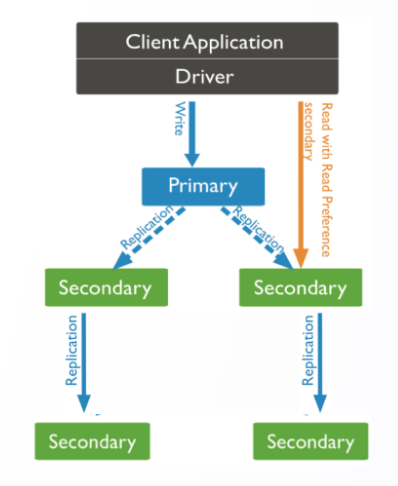
编辑
复制数据关键技术点:
• 主节点写入数据后,记录 oplog
• 备节点拉取 oplog√备节点应用 oplog
• voplog 是固定大小的集合,自然序写入,无索引
• 多线程并行应用 oplog:
• 一个线程内部操作串行执行
• 一个集合的 oplog 会被一个线程处理
• 不同集合的 oplog 会被分配到不同线程处理
• 更新数据库状态,更新最新时间戳
3.3 DDS 数据同步注意事项
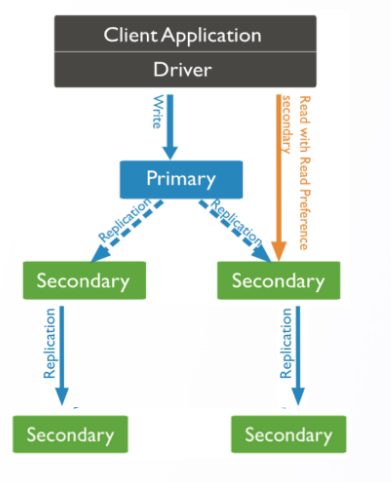
编辑
关于复制的注意事项:
• 副本集内 oplogsize 固定,写入数据会淘汰旧的 oplog 数据
• 空载业务的数据库实例,通过 noop 特殊操作推移
• noop 操作每次间隔 10s 写入 oplog,少于 10s 则不写入
• 业务过载,写入速度过快导致复制脱节
• 可以通过 write Concern 确保写入多数节点
• 可以指定读写分离 readPreference
4. DDS 查询计划和其他机制
4.1 DDS 查询计划及索引建议
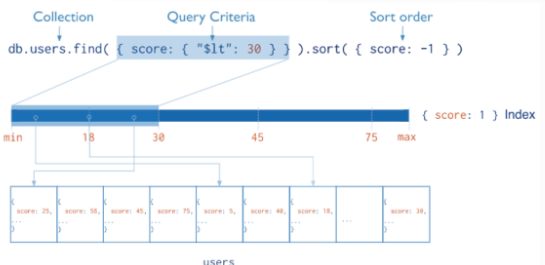
编辑
索引类型:
• 单字段索引
• 组合字段索引
{userid: 1,score:-1}
• 嵌套字段索引
{“addr.zip”}
• 地理位置索引
2dsphere indexes
• 文本索引
• hash 索引
索引属性:
• 唯一索引
• 部分索引
• 稀疏索引
• TTL 索引(Time to Live)
通过查询计划诊断查询效果:
• explain 计划分析:返回文档、扫描文档、是否覆盖索引、是否内存排序
• queryPlanCache 查看查询计划方案缓存情况
4.2 DDS 订阅数据变更场景
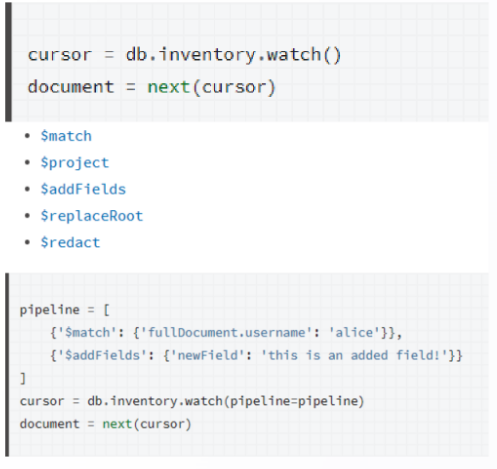
编辑
订阅数据变更:
• 通过 watch 对于一个集合的数据变更进行监听
• 通过 cursor 的 next 持续返回该集合的数据变更
• full_document='updateLookup’返回 update 全文档
• db.bar.watch(0.{“resumeAfter”:<\_id>})从断点恢复
• readConcern=true
• 断点时间可恢复,同理与 oplog 可用窗口
Change Stream 限制:
• 部分 DDL 操作不支持
• fullDocument 返回的 update 全文可能被后续操作更改的
• 全量信息(在频繁快速更改前提下)
• change stream 返回体限制 16M,则原始数据修改需要更小
4.3 DDS 其他机制注意事项
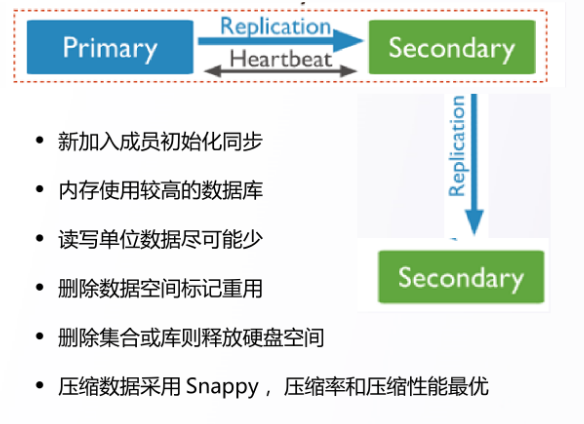
编辑
文档 &集合建议:
• JSON 数据模型(对象模型内聚数据关联)
• 文档 Size 限制 16MB
• 一个集合中不建议存储过量数据
• 有效使用固定集合(size,max)
• 删除数据库快速释放内存
• 集合总体数量过多导致内存占用过高
四、 快速使用分片集群
1.DDS 服务部署模型概述
DDS 服务集部署形态
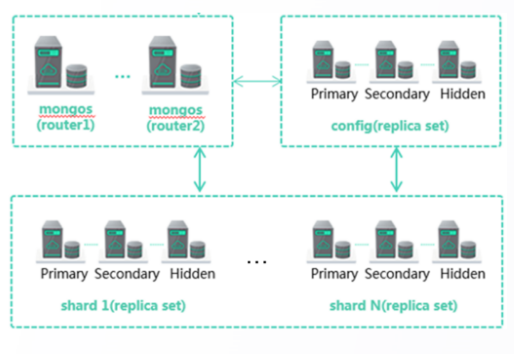
编辑
架构特点
1.组件构成:由 mongos(路由)、config(配置)、shard(分片)三种类型的节点构成
2.Shard 分片:每个 shard 都是一个副本集架构,负责存
储业务数据。可创建 2-32 个分片,每个分片 10GB-2000GB。因此,集群空间范围(2-32)*(10GB-2000GB)
3. 扩展能力:在线规格变更、在线横向扩展
适用场景
要求高可用,数据量大且未来横向扩展要求
2. DDS 分片集群基本使用
2.1 DDS 选择集群规模
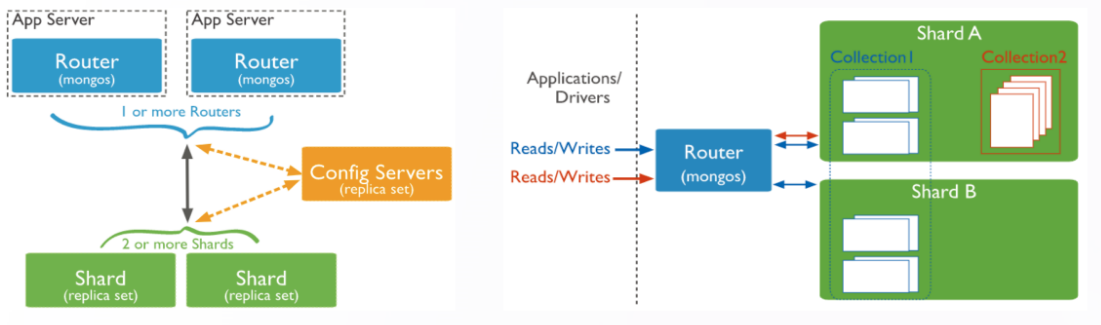
编辑
• 分片集群部署方式,水平分表,横向扩展存储和读写能力
• 2 个 mongos 以上,路由模块提供高可用的接入
• 2 个 shard 以上,具备分片扩展能力
• 一个 shard 内部以副本集方式服务,具备副本集所有属性
• 用户数据库默认创建非分片,需要指定分库及分表方式
2.2 DDS 选择片键关联索引
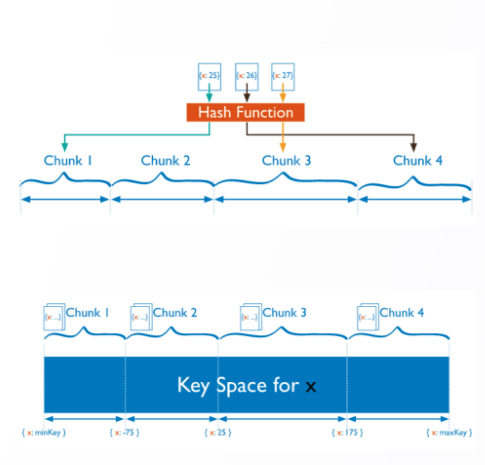
编辑
分片键建议
类似索引选择,取值选择性强的字段、可以是组合字段索引取值单个关联文档过多,容易导致 Jumbo chunk 确保查询包含 shard key,避免 scatter-gather 查询片键类型区分 HashedRange
>sh.shardCollection("database.collection"{<field>:"hashed"})>sh.shardCollection("database.collection",{<shard key>})
分片键举例:海量设备日志类型数据
2.3 DDS 预置 chunk 及其他建议
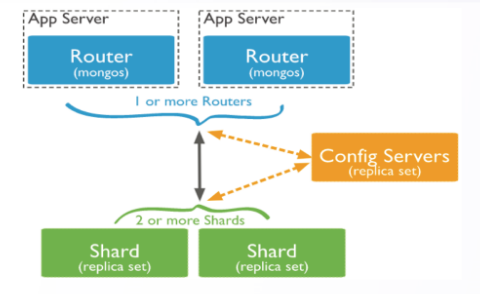
编辑
• 预置 chunk 能够最有效降低均衡带来的性能消耗
• chunksize 默认 64MB、数据聚集的逻辑单位
• shard key 优选,避免 Jumbo chunk
• shard key 取值不超过 512 Bytes
• db.colname.getShardDistribution()#可以查看数据分布
• scatter-gather 查询产生 mongos 输入网卡流量过高
• hash 分片方式,创建集合指定预置初始 chunks 数量
mongos> sh.enableSharding("<database>") mongos> use admin
mongos>db.runCommand({shardcollection:“<database>.<collection>”,key:{“keyname”:“hashed”), numinitialChunks: 1000})
• range 分片方式,通过采用分裂点初始化 chunks 数量
mongos>db.adminCommand({split:"test.coll2middle:{username:1900}})(多次寻找合适切分点,建议采用 DRS 完整迁移功能)
3. DDS config 及管理操作
3.1DDS config server 及元数据
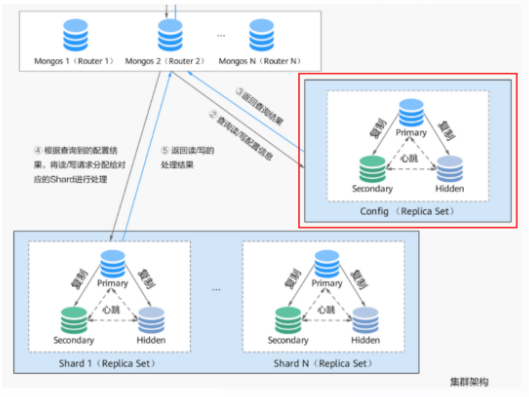
编辑
• config database # mongos> use config
• config.shards #db.shards.find()
• config.databases #db.databases.find()
• config.collections #分片集合
• config.chunks #所有 chunks 的记录
• config.settings #shard cluster 配置信息
• mongos>db.settings.find()
("id" : "chunksize”, "value": NumberLong(64)}
{"id" : "balancer", "stopped": false )
• config server 存储整个分片集群元数据
• 以副本集为单位、高可用部署方式
3.2 DDS 集群管理及最佳实践
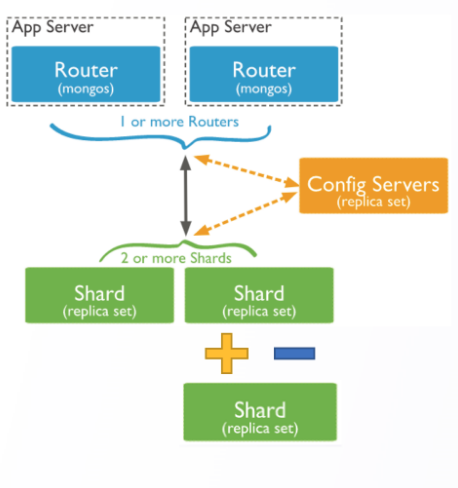
编辑
• 添加分片
db.runCommand({addShard:"repl0/mongodb3examplenet:27327"})
• 删除分片 removeShard 会影响 chunks 的重新分配、运行时间过长
• 查看均衡
mongos>sh.getBalancerState()#查看是否开启均衡
mongos>sh.isBalancerRunning0 #查看是否正在均衡迁移 chunk
• 备份时停止、开启均衡 sh.stopBalancer()
sh.setBalancerState(true)
• 刷新路由信息
db.adminCommand({flushRouterConfig:"<db.collection>"}) db.adminCommand({ flushRouterConfig: "<db>" } )
db.adminCommand( { flushRouterConfig: 1 })
4.DDS 分裂和均衡的基本原理
4.1 DDS 分裂基本原理
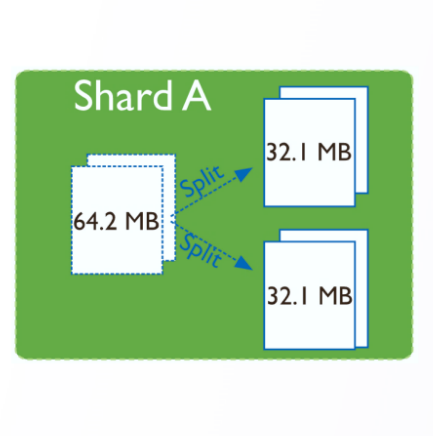
编辑
• 分裂命令
sh.splitFind("records.people"{"zipcode":"63109"})
#匹配 zipcode:63109 的 chunk,分裂为 2 个或多个 chunk sh.splitAt( “records.people”,{ “zipcode”: “63109”))#以 zipcode:63109 为分裂点,分裂为 2 个 chunk
• 分裂基本过程
sharding.autoSplit 自动分裂默认开启
插入、更新、删除数据时,mongos 判断 chunk 是否超过阈值,触发 chunk 分裂
chunk 分裂是逻辑动作,基于元数据进行标记数据边界左开右闭[)
chunk 内数据 shard key 是相同的一个值,则无法分裂形成 Jumbo chunk
4.2 DDS 均衡基本原理
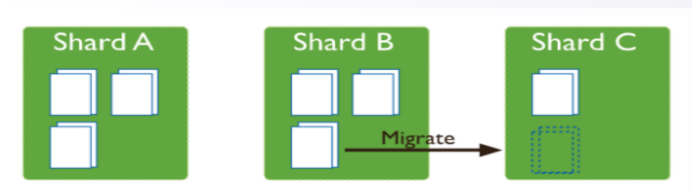
编辑
• 迁移命令
db.adminCommand{moveChunk:<namespace>
find : <query>.
to: <string>,
_secondaryThrottle<boolean>,
writeConcern:<document>,
• 迁移命令
db.adminCommand{moveChunk:<namespace>
find : <query>.
to: <string>,
_secondaryThrottle<boolean>,
writeConcern:<document>,
_waitForDelete<boolean>})
• 迁移基本过程
• 由 config server 通知发送方 shard,并指定迁移 chunk 任务(一时迁移一个 chunk)
• 发送方 shard 通知接收方 shard 主动分批次拷贝数据、增量应用到接收方
• 发送方判断 chunk 数据迁移完毕后进入临界区,写入操作挂起直到退出临界区
• 接收方最后拷贝 chunk 最后一次增量数据完成 commit,完成后接受方退出临界区
• 接收方最后进行异步删除本地 chunk(孤儿 chunk)
• 均衡窗口
use config
db.settings.update({id:"balancer}.{$set:
{activeWindow:{start:“02:00stop:"06:00"}}} {upsert: true })
版权声明: 本文为 InfoQ 作者【程思扬】的原创文章。
原文链接:【http://xie.infoq.cn/article/03f152b8313510e7192f22797】。文章转载请联系作者。

会的越多,不会的越多 2022.01.03 加入
还未添加个人简介









评论