
缓存与主副本数据一致性系统设计方案(下篇)

声明:为力求内容的准确性,为大家提供更优质的技术内容。如果您发现文章内容中任何不准确或遗漏的部分。非常希望您能评论指正,我将尽快修正疏漏。
在上篇(https://xie.infoq.cn/article/c4a600269551579fad375af2a)中我们整理分析了 Cache-Aside 模式中数据读取与变更的实现方式。提及数据变更场景下存在更新主副本数据后删除缓存和更新主副本数据后更新缓存两种实现方式。并提出面对缓存组件失效与应用服务并发访问时数据不一致的情况,本文接下来的内容将分别针对两种情况给出设计方案。
应对缓存组件失效改进方案
这里我们将非编码错误导致对缓存操作失败的情况,均认为是缓存组件失效,如网络抖动导致操作失败,缓存节点下线等。首先回顾一下更新主副本数据后删除缓存和更新主副本数据后更新缓存两种方式,在面对缓存组件失效时数据不一致的情况。
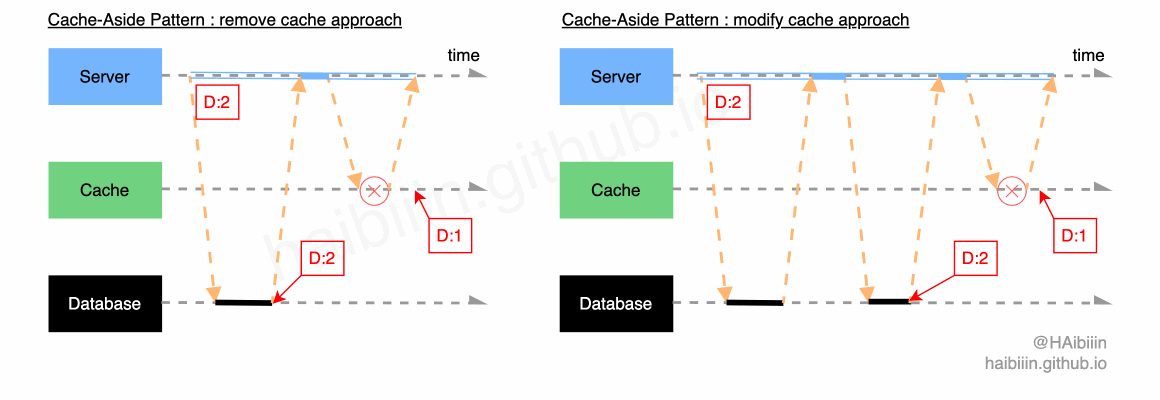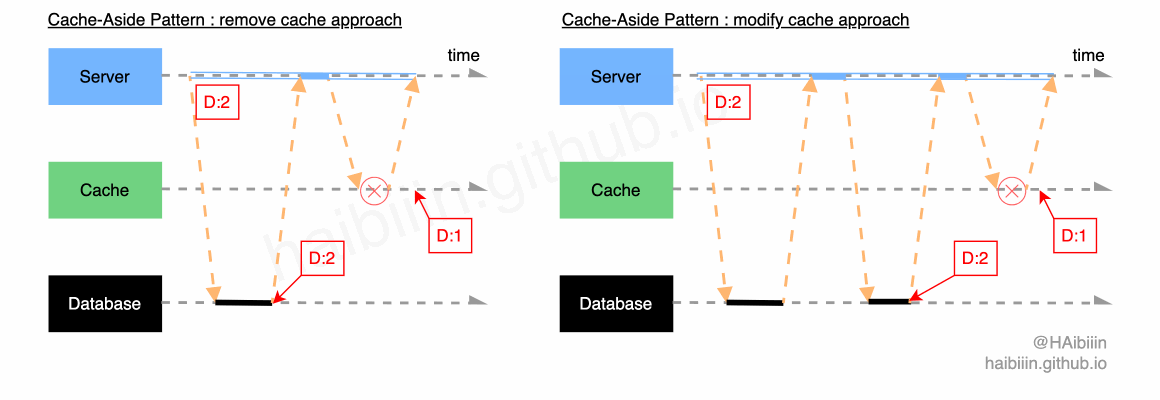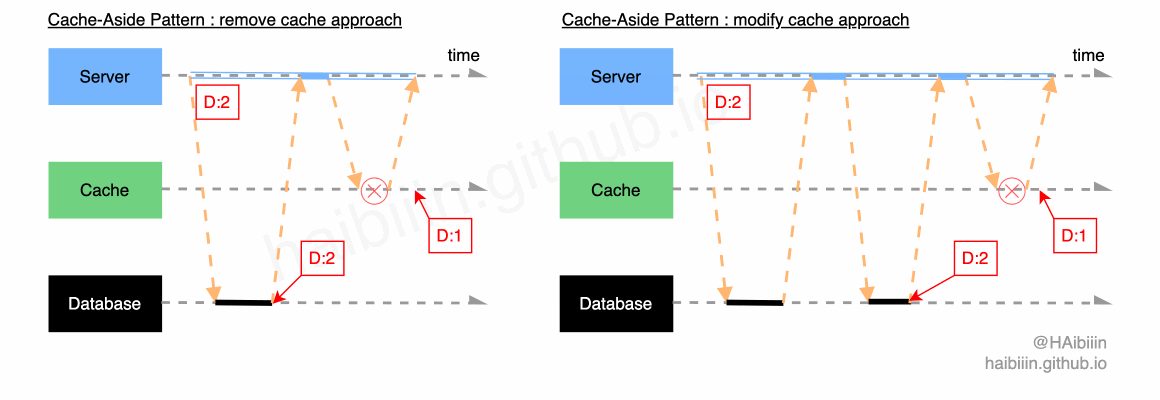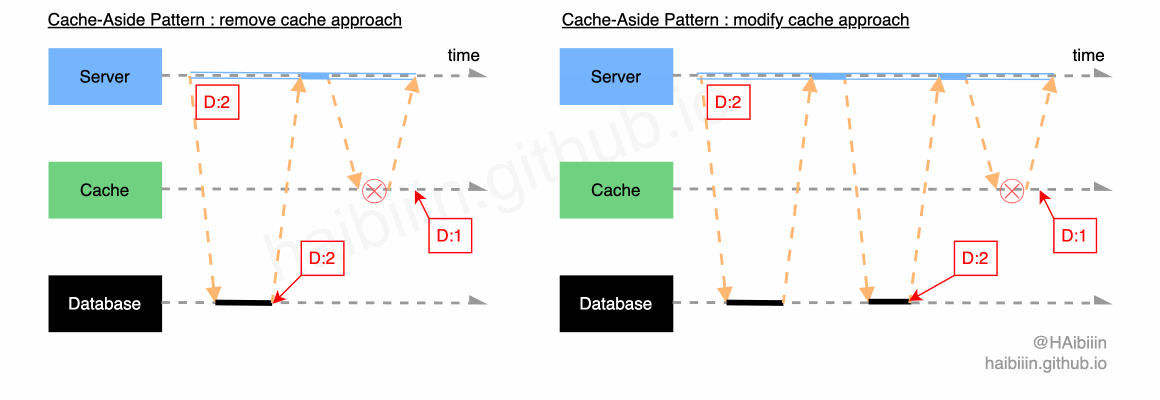
通常我们在架构与运维层面会为缓存等存储系统设计主备架构,针对主节点失效后会切换为备节点,进而实现故障恢复。通常缓存组件失效属于短时性失效,应用系统需要做的便是当缓存组件恢复后,能够将此前失败的操作重新执行。
要实现此功能,最简单的方式便是通过应用服务的轮询重试。为避免对请求的阻塞,通常会启用其他的进程/线程/协程来周期性调度执行,如下图所示。
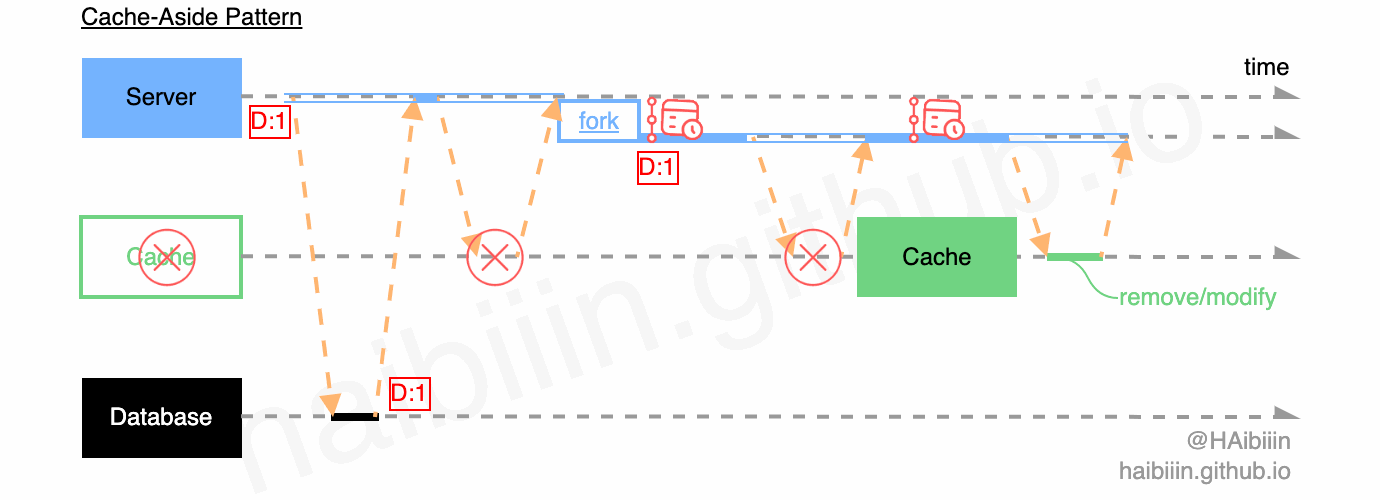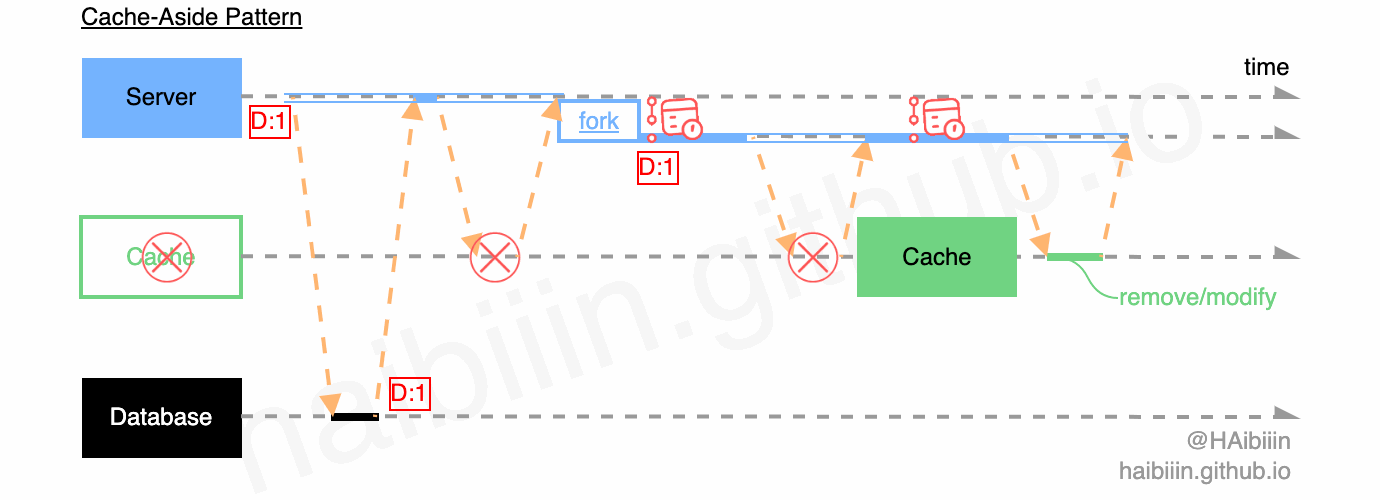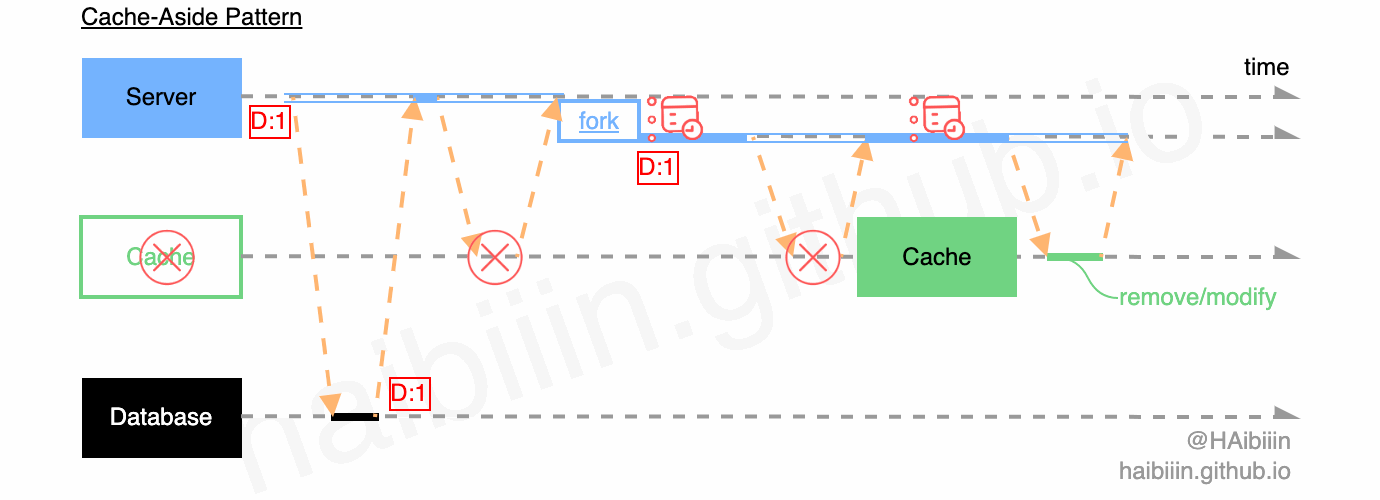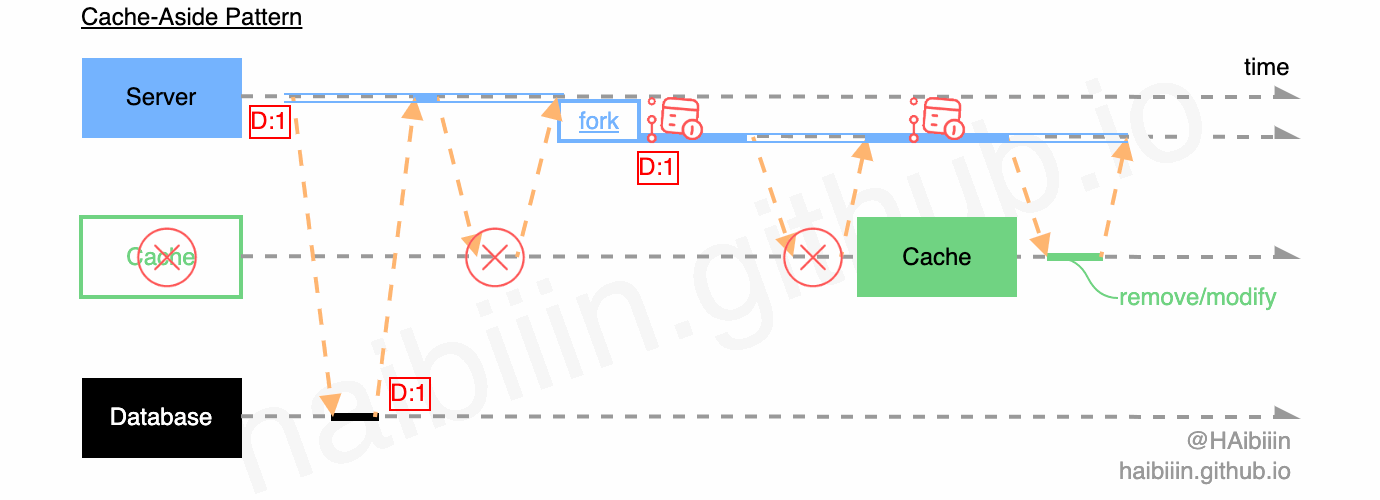
但是此方法虽然实现简单,但是当 Server 意外终止、宕机,其内存中的待执行的缓存操作信息也会随之丢失。同时因为轮询重试功能涵盖在应用服务代码中,如果模块依赖管理不当,代码设计不合理便会产生不必要的耦合,增加代码复杂度,增加后续业务变更复杂度。
我们可以采取将轮询重试抽取到 Batch 组件,或其他类似调度服务等组件中。同时将对缓存的操作信息通过外部持久化存储下来。由 Batch 类组件通过获取到的信息执行对应操作。此种方式可以借鉴 Outbox Pattern 来实现,具体如下图所示:
充当 Outbox 角色的可以是一张消息表,可以同属于业务表所在库,在同一个库的好处时利用数据库事务,确保对缓存的操作信息与业务数据一致性;
图中 1-2 对应的 IPC 请求为应用服务同时发起,一个事务中的操作,只不过 Outbox 表中存储为操作信息;
Batch 组件定时轮询 Outbox 表中信息,基于获取到的新信息执行对缓存的操作,如图中 ii:query data time 所示,获取指定业务数据准备更新缓存(如果采取清理缓存实现,可以省略 query data 这一步操作);
Batch 组件更新缓存后,“移出” 指定 Outbox 消息;
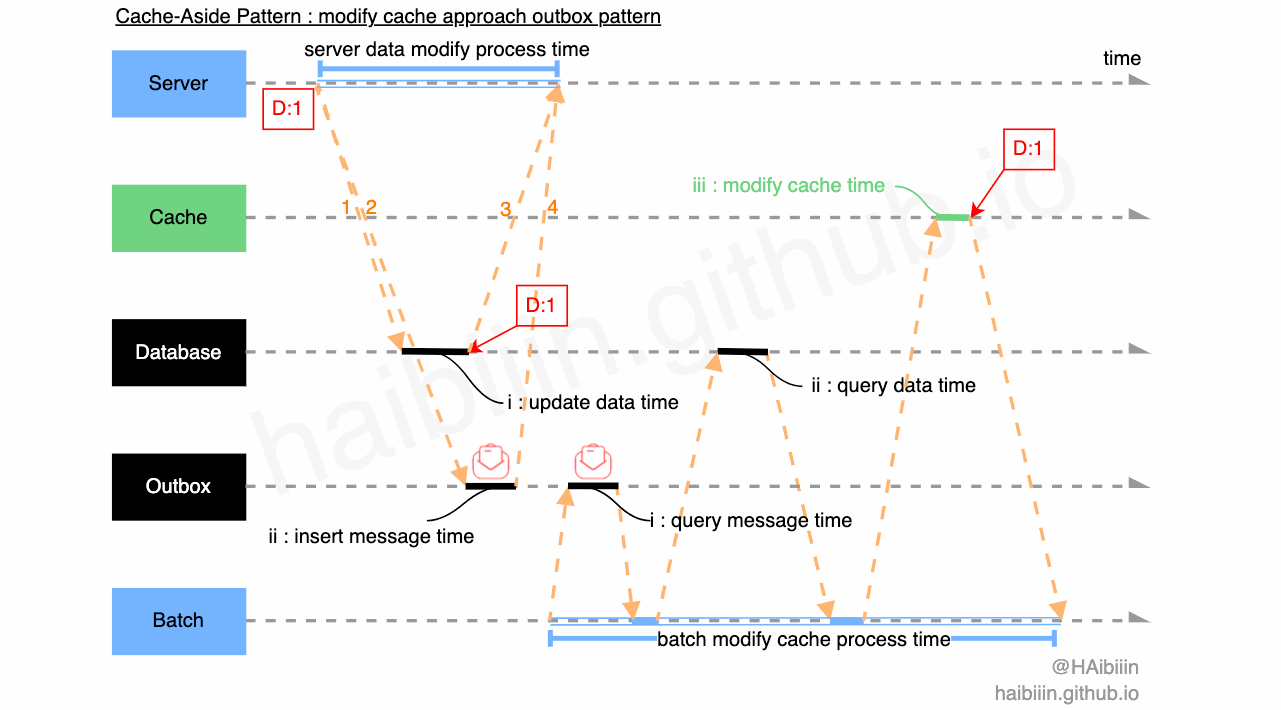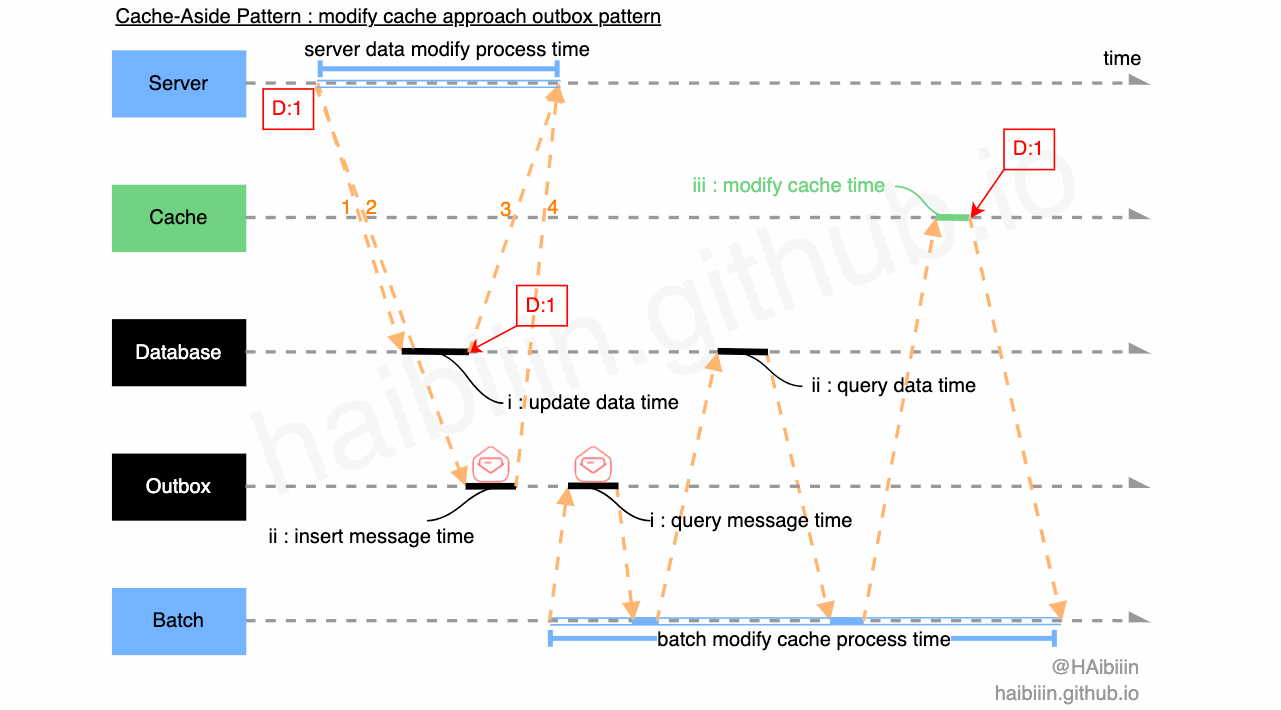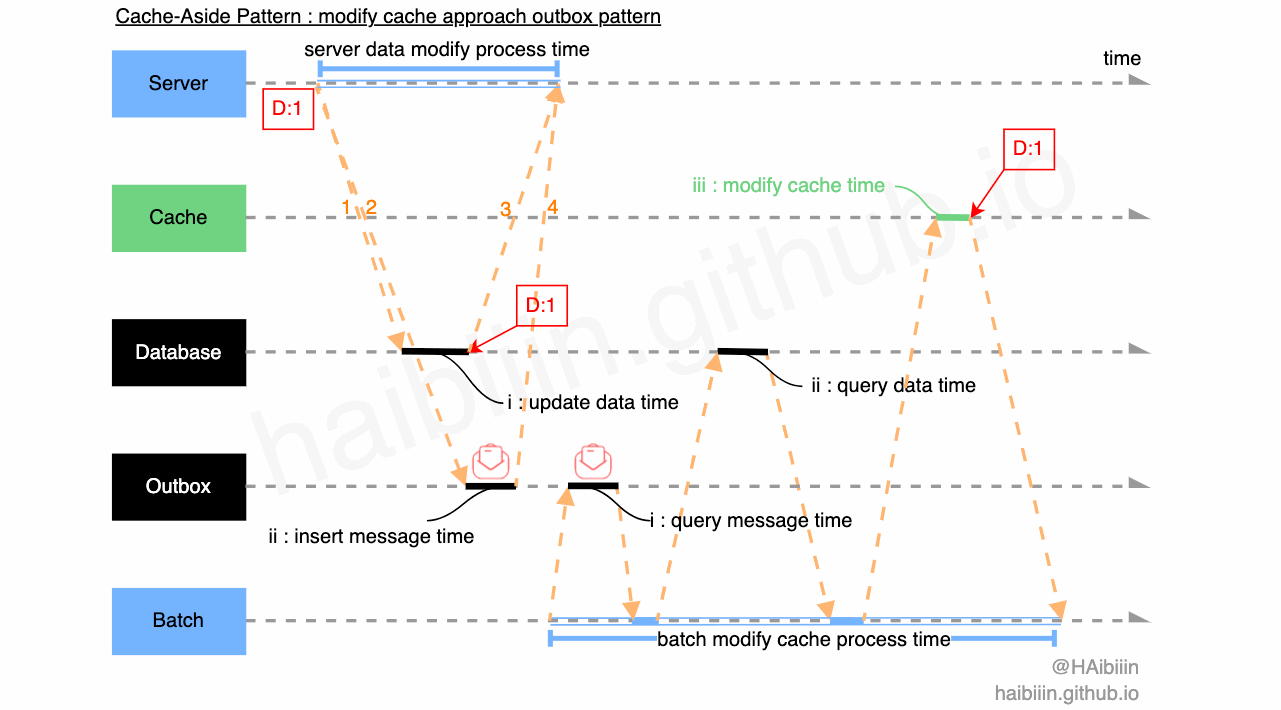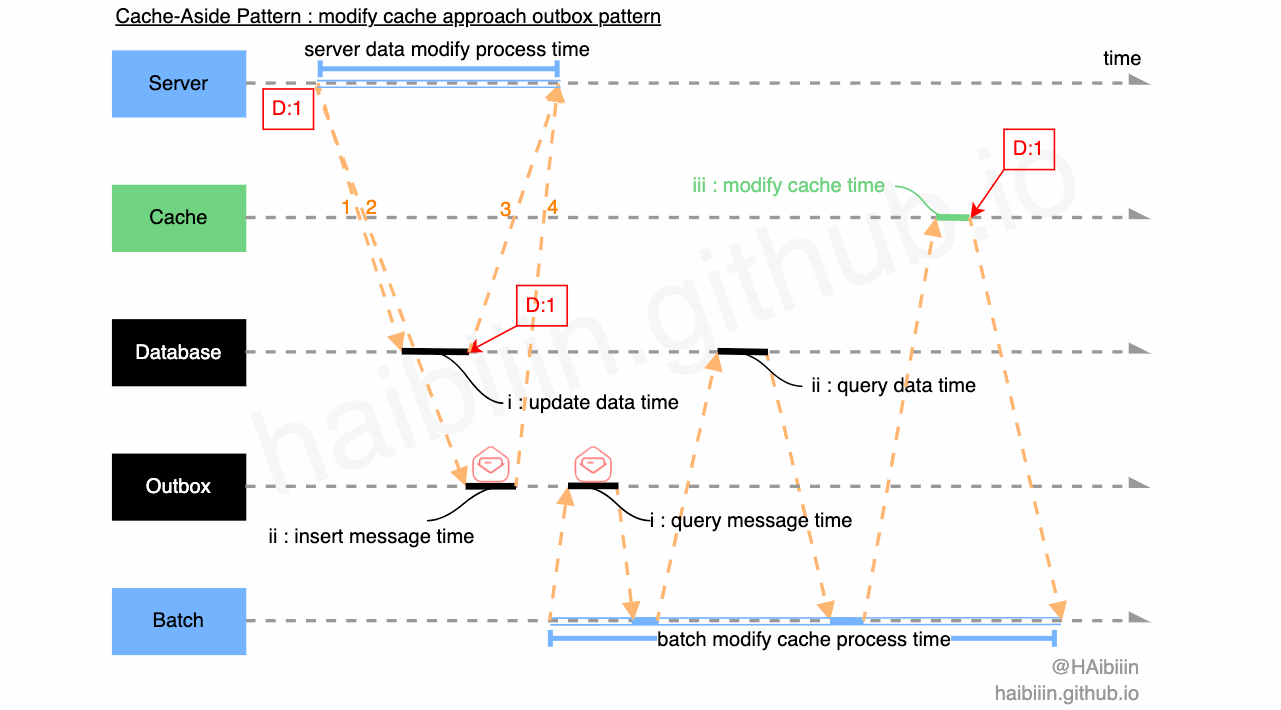
通过上述方案可以增加系统可用性,避免人工干预,缩短数据不一致时间。我们可以通过增加 Batch 组件节点,防止其单点失效。当 Batch 组件节点大于 1 个时,可以对 Outbox 中的信息加锁(如利用数据表实现乐观锁,后面会提供详细内容),避免数据重复修改。如果你所在的组织中,基础设施能力足够的话,也可以通过其他类 Pub/Sub 消息中间件来实现 Outbox。你甚至可以在 Batch 组件中将对缓存的操作进行聚类和压缩,以减少缓存变更操作次数等精细化操作等改进。
应对并发访问导致数据不一致改进方案
更新主副本数据后更新缓存并发问题解决方案
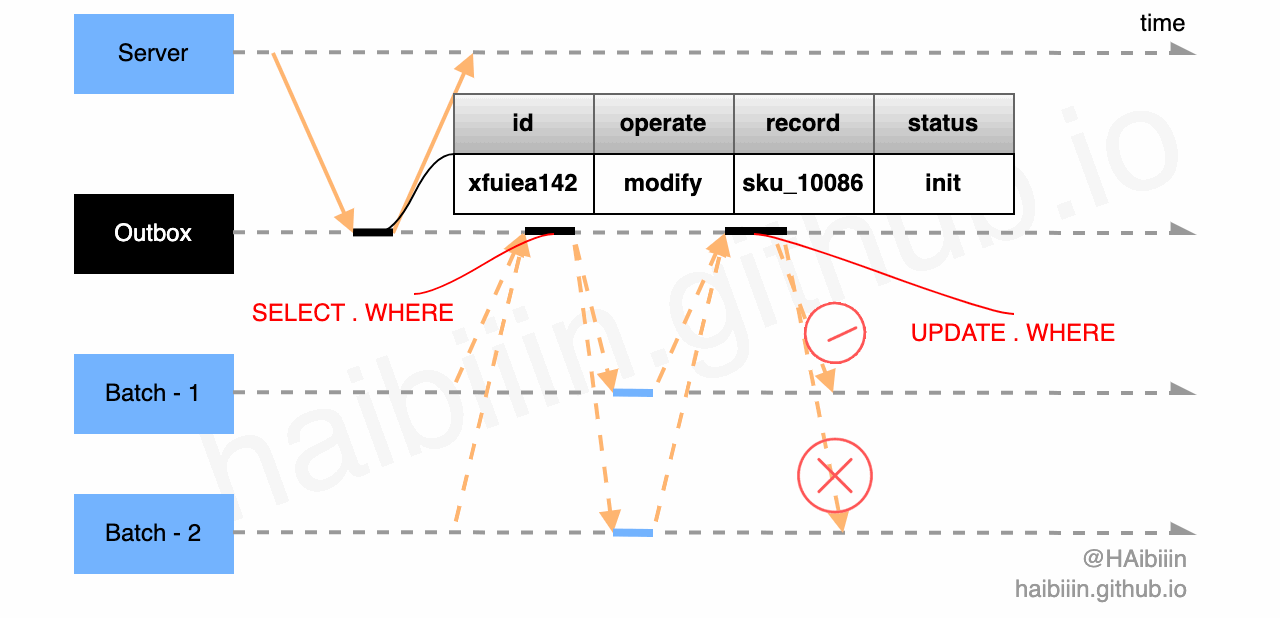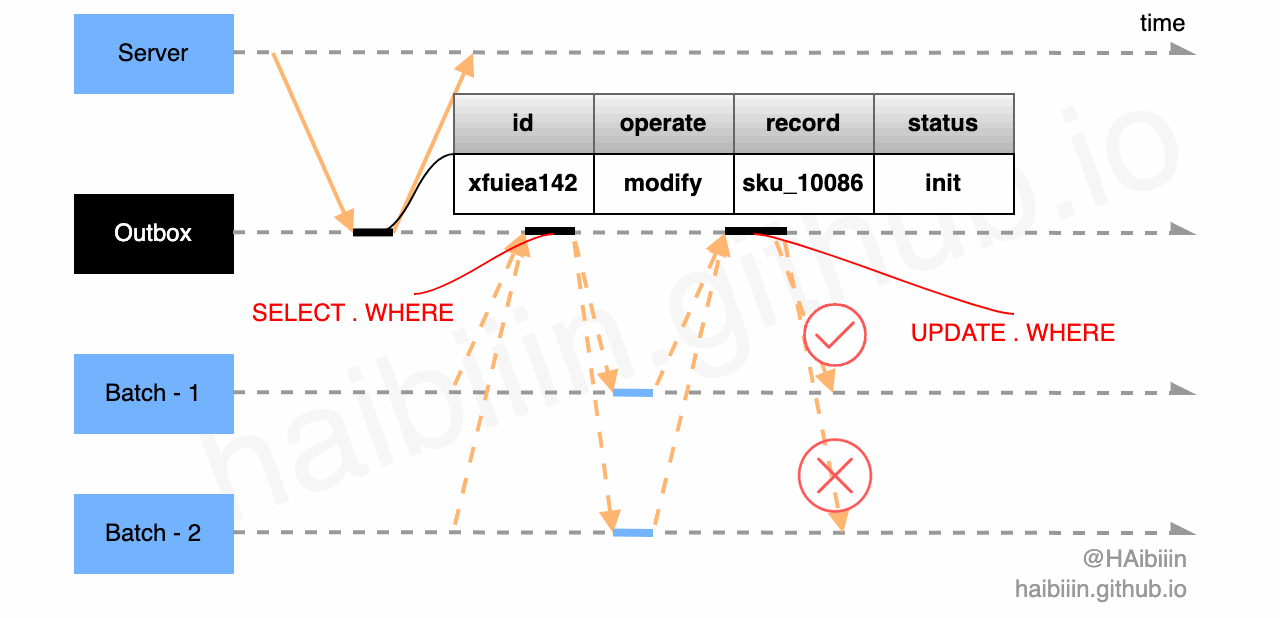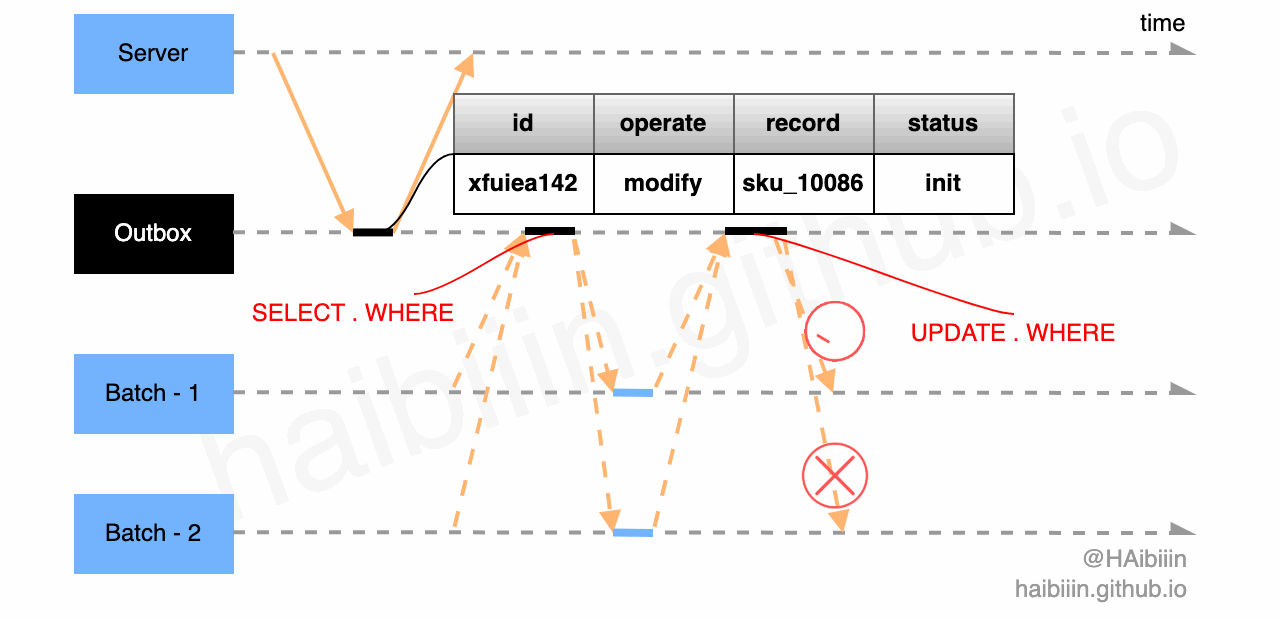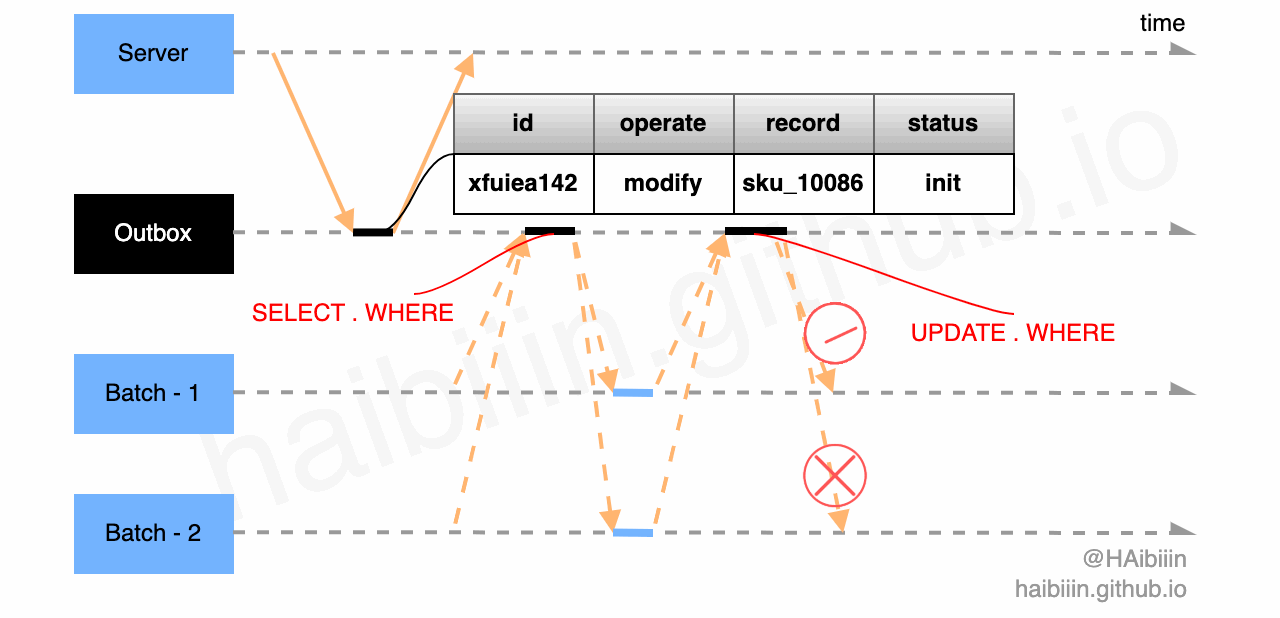
首先,结合下图回顾一下更新主副本数据后更新缓存在并发访问场景下导致数据不一致的情况。因为数据常驻缓存的因为,并发问题只存在于对数据的并发修改情况。如果我们能将并行改为串行则可以解决此类问题。
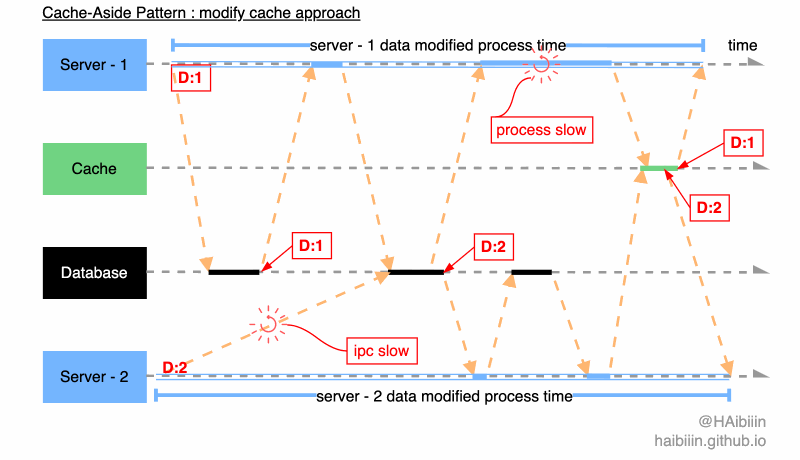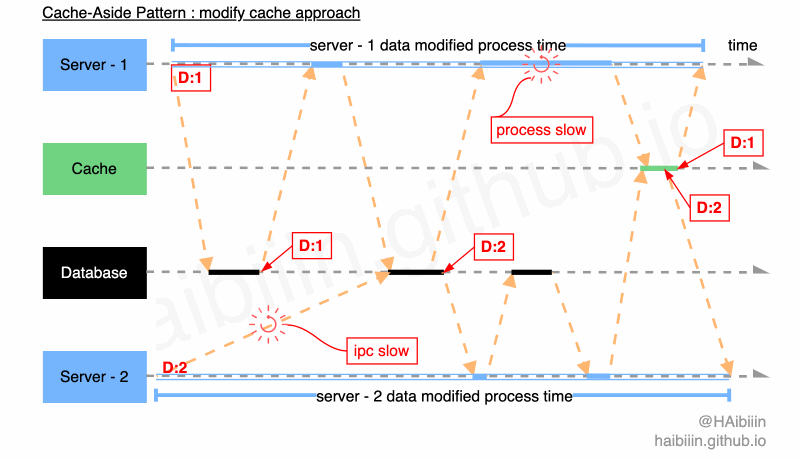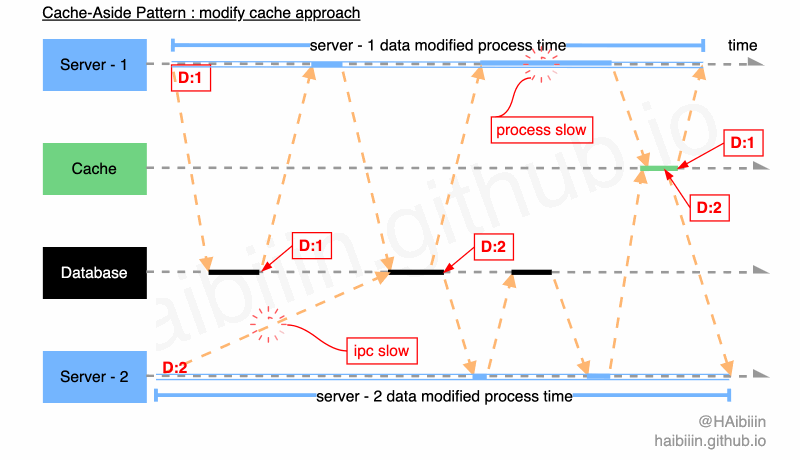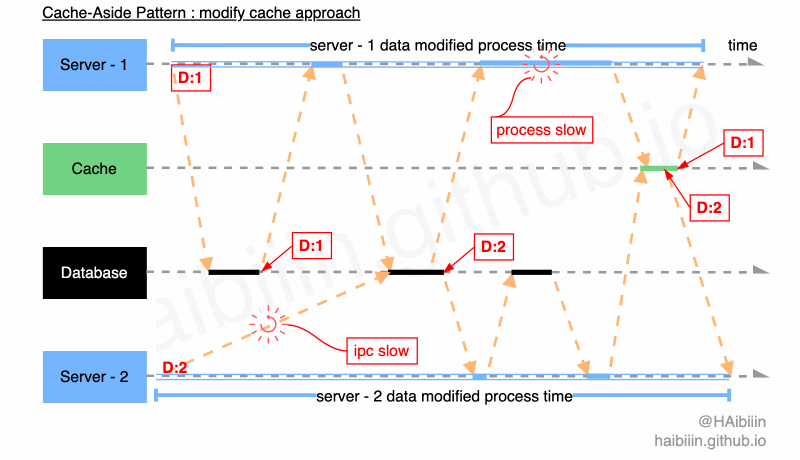
前文中给出解决缓存组件失效的改进方案,即基于 Outbox 模式实现更新主副本数据后更新缓存方式,可以避免并发更新缓存导致的数据不一致问题。我们可以通过单节点 Batch 组件可以完全避免对缓存的并发修改。
如果是多节点 Batch 组件可以利用前文中提到的数据表记录实现乐观锁,避免多节点并发修改。如图所示 Batch - 1 和 Batch - 2 通过下方的两条 SQL 争抢,最终 Batch - 1 获取到 id=xfuiea142 消息的处理权限,执行对数据记录 sku_10086 的缓存更新操作。
更新主副本数据后删除缓存并发问题解决方案
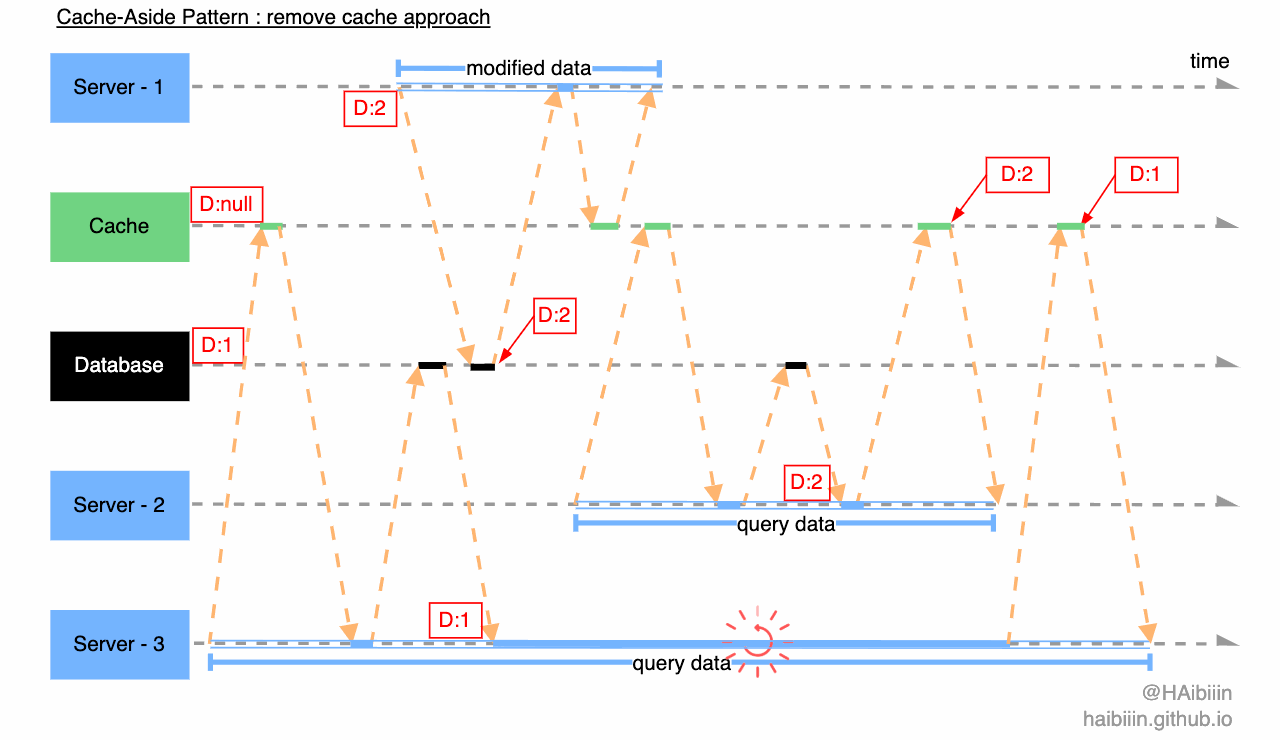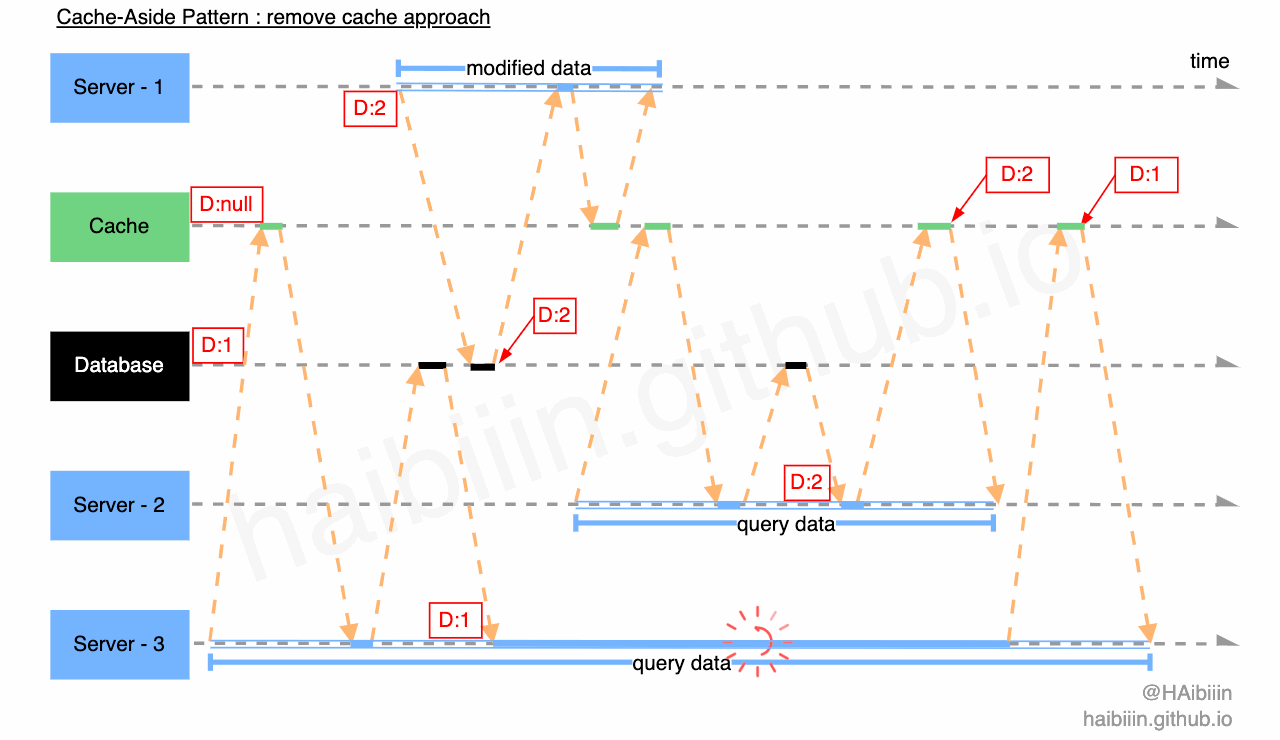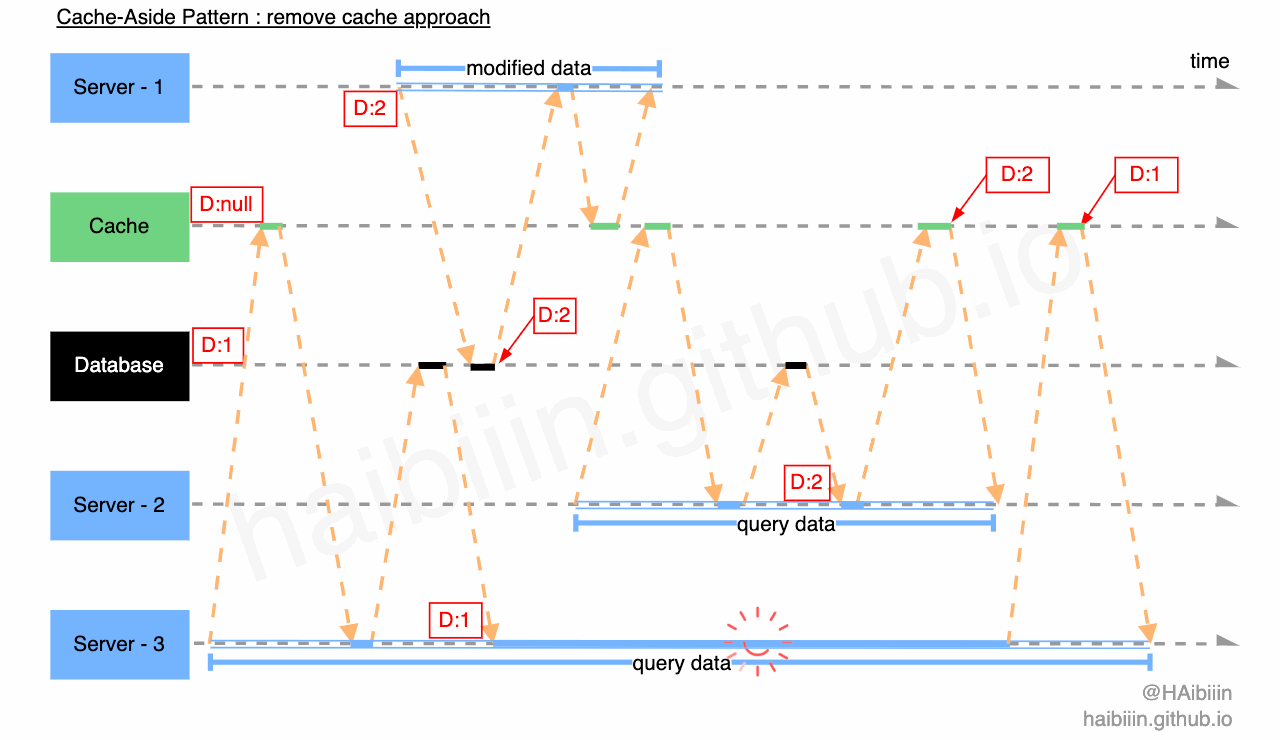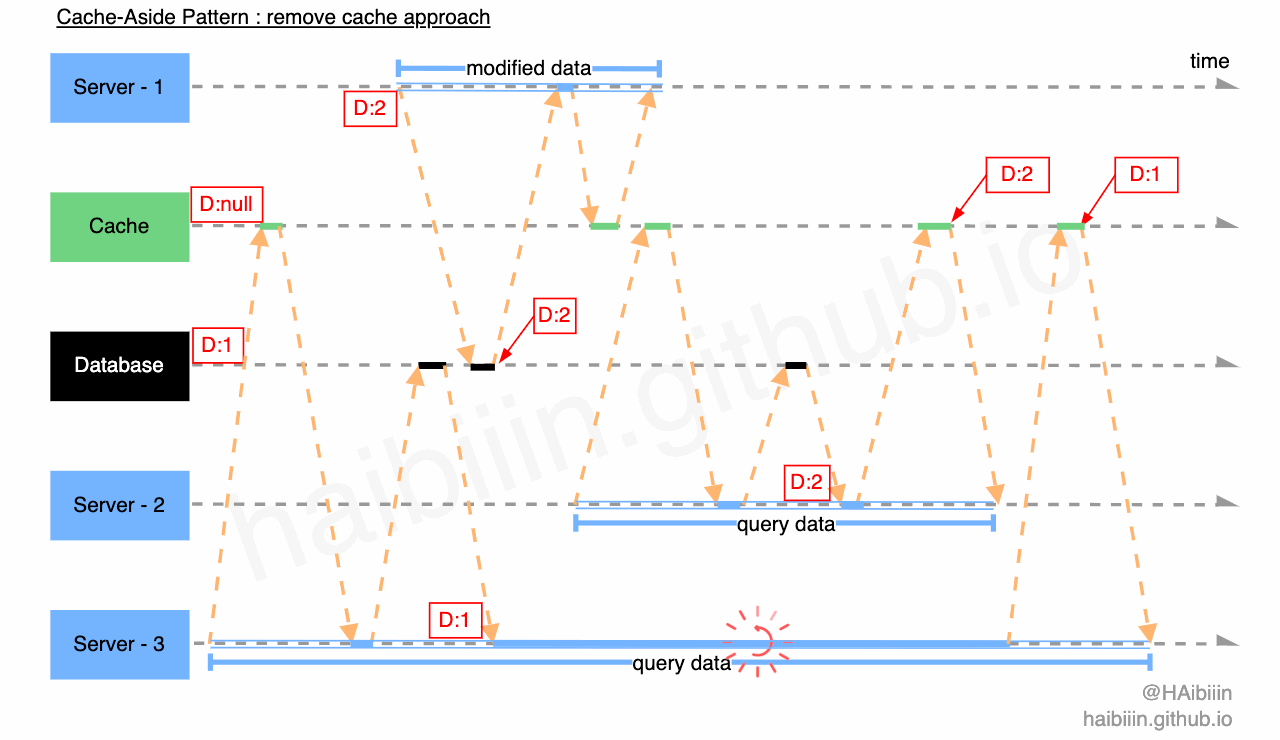
首先,结合下图回顾一下更新主副本数据后删除缓存在并发访问场景下导致数据不一致的情况。因为数据复制到缓存的时机为缓存中不存在时,所以并发问题通常发生在读写并发的场景下。
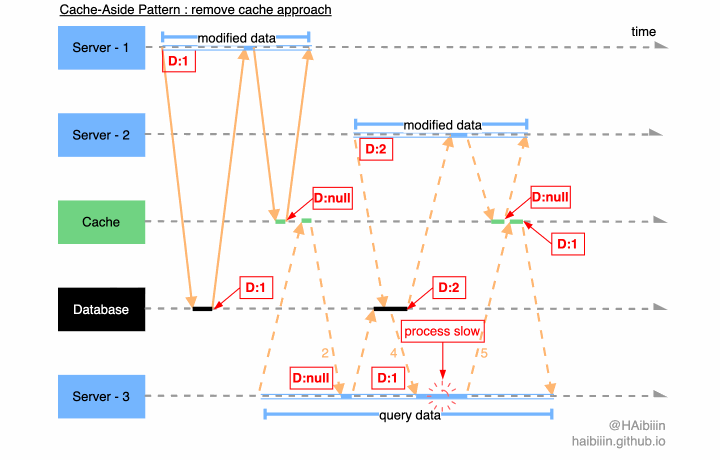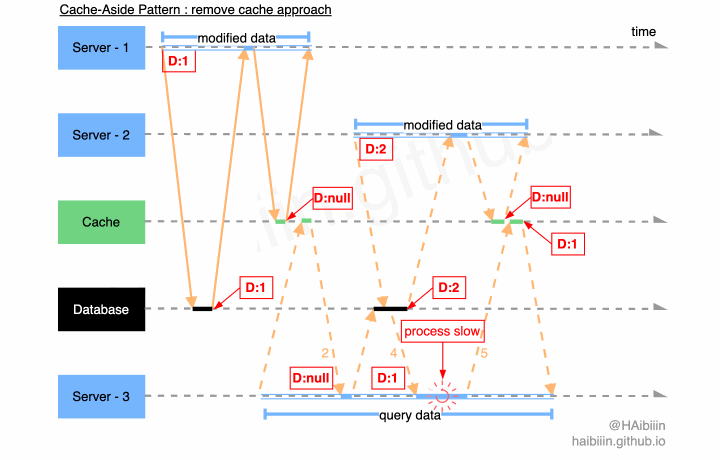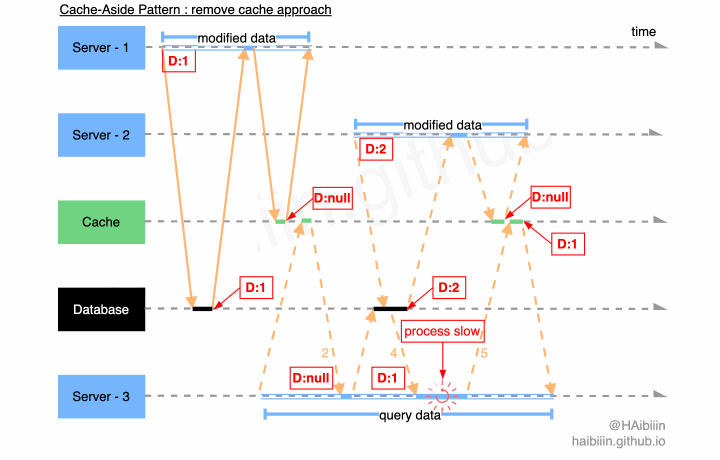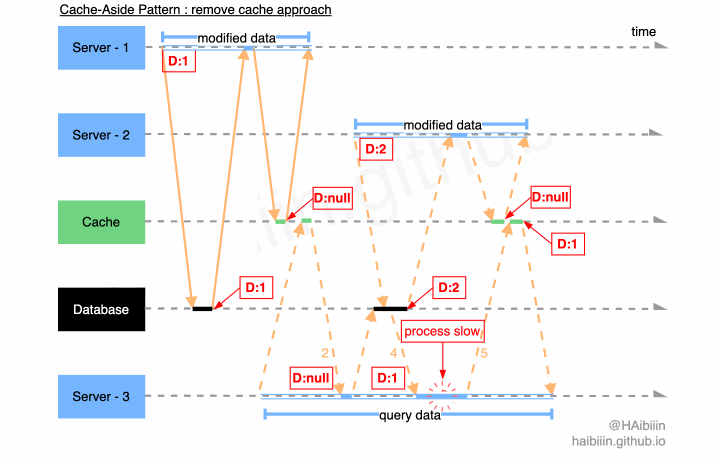
除了在上篇中给出的并发问题导致的数据不一致问题。还存在另一种情况,是由多个应用服务读请求与修改请求下造成的数据不一致,我们结合下图说明,系统初始状态,指定数据记录在数据库中值为 1,而缓存中书籍记录被删除。其中 Server - 3 率先发起数据查询,当完成数据库记录读取后,Server - 1 对该记录再次发起变更操作,随后 Server - 2 也对该记录发起查询操作,Server - 3 因为 GC 等原因导致进程/线程执行受阻。此时,在更新缓存之前,Server - 2 和 Server - 3 对该记录分别持有的值为 2 和 1。而 1 为历史旧值,但 Server - 2 先于 Server - 3 完成了缓存更新操作,最终缓存与数据库中的数据呈现不一致的状态。
延迟双删策略可能是个糟糕的方法
至此,细心的你一定会发现,在缓存这种读多写少的场景下,上面两种数据不一致的现象,可能发生的概率要远高于更新主副本数据后更新缓存的并发问题。面对这种情况,通常的解决方案是采用简单的延迟双删策略,简单来讲是在删除缓存后间隔一定时间再次删除指定记录的缓存数据。该策略的核心依据是缓存的删除操作的幂等性,但却忽略了引起数据不一致的核心是并发问题。
产生上述现象的背后还有可能是大量读请求的到来。那么延迟双删除策略,会导致数据频繁的 cache miss 势必会造成对主副本的访问压力,也会使得缓存遭遇频繁的更新,引发系统的 thrundering herd (惊群问题)问题。
如何解决并发数据不一致,又能避免延迟双删带来的惊群问题
解决并发问题的出发点并不复杂,要么化解并发访问,改为非并发执行,要么为资源加锁。多年以前 Facebook(今 Meta)发表的论文 “Scaling Memcache at Facebook” 中,便通过 “leases” (这里译为“租约”)机制实现了问题的处理。
租约机制实现方法大致如下:
当有多个请求抵达缓存时,缓存中并不存在该值时会返回给客户端一个 64 位的 token ,这个 token 会记录该请求,同时该 token 会和缓存键作为绑定,该 token 即为上文中的“
leases”,其他请求需要等待这个"leases"过期后才可申请新的“leases”,客户端在更新时需要传递这个 token ,缓存验证通过后会进行数据的存储。
具体过程,我们可以结合上文中给出的数据不一致案例来理解。Server - 3 查询缓存中不存在记录数据,获取租约 leases:x01 ,同时在缓存中该租约信息与对应记录绑定,之后 Server - 3 执行后续逻辑。Server - 2 执行数据更新操作,删除缓存的过程中此前保存的租约信息也被连带删除。但 Server - 3 尝试更新缓存前,需要和缓存比对租约信息发现 leases:x01 与缓存当前租约(当前租约已不存在)不匹配,于是重新获取租约 leases:x02,并再次执行对数据库的查询逻辑,最后完成缓存数据更新操作。
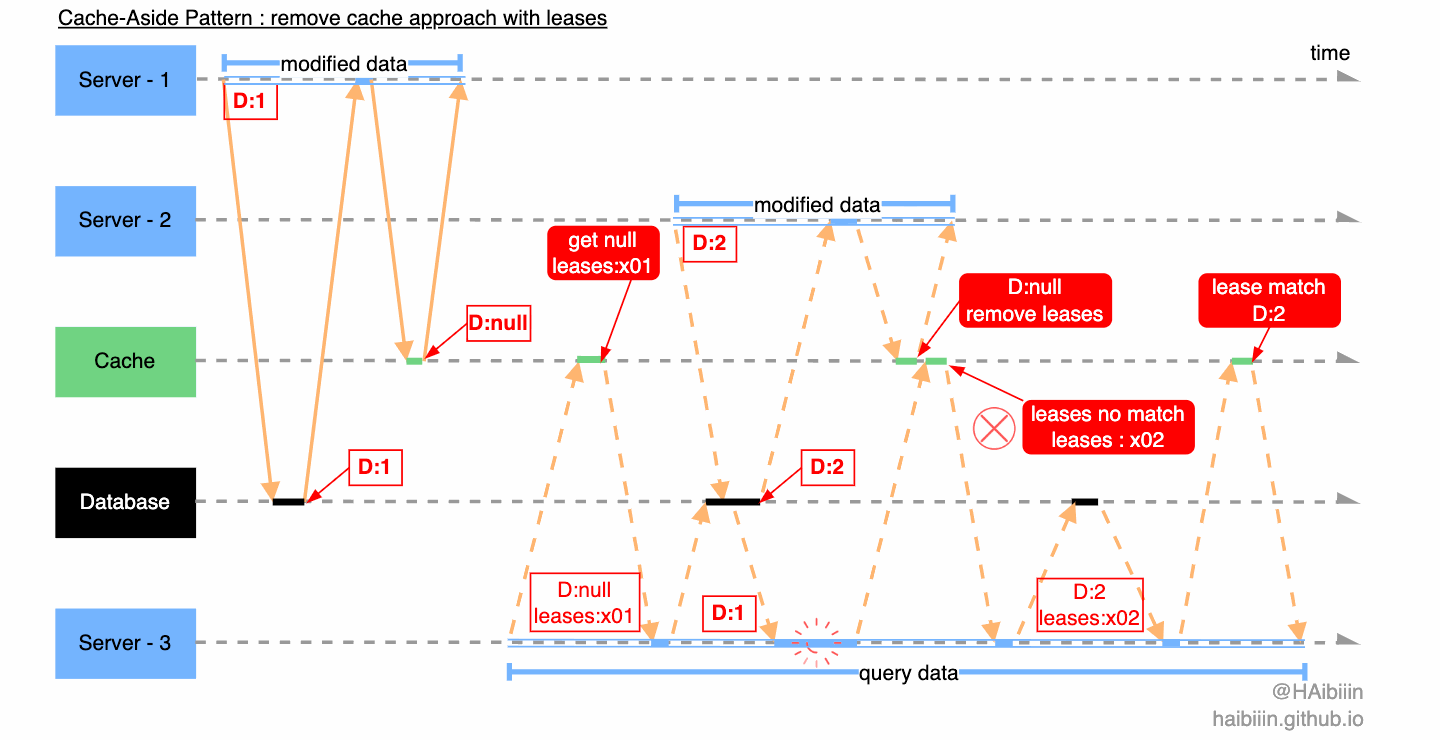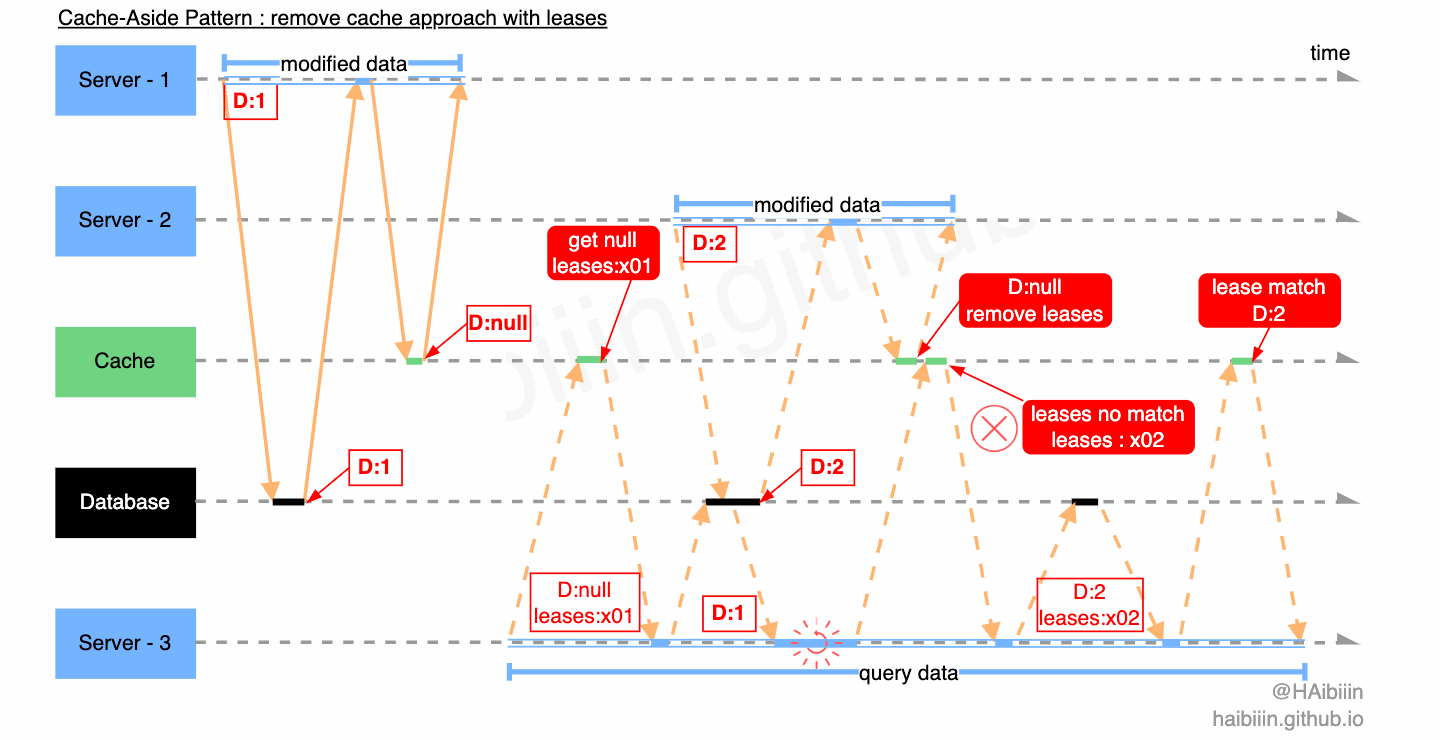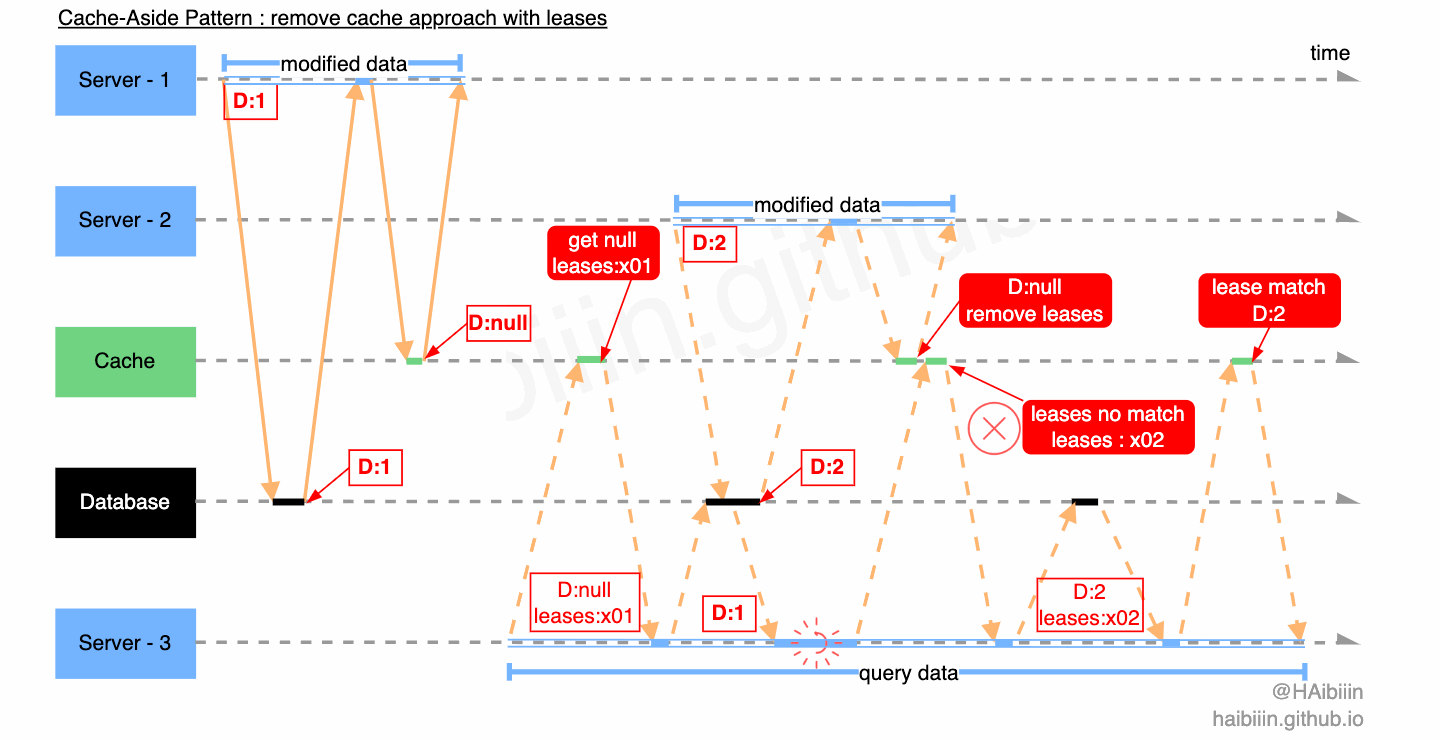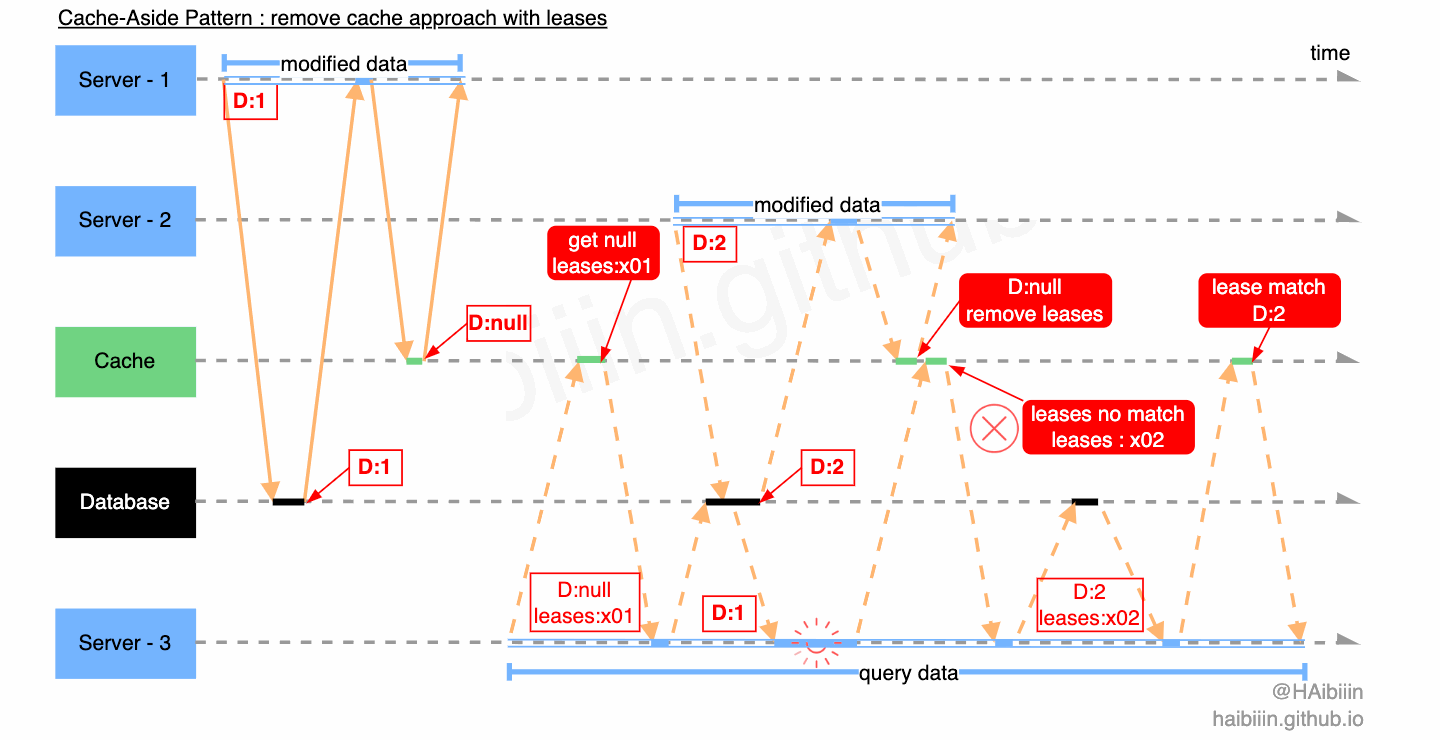
我们继续分析对另一个数据不一致场景的应用。Server - 3 查询缓存中不存在记录数据,获取租约 leases:x01 ,同时在缓存中该租约信息与对应记录绑定,之后 Server - 3 执行后续逻辑。Server - 1 执行数据更新操作,删除缓存的过程中此前保存的租约信息也被连带删除。Server - 2 查询缓存中不存在记录数据,获取租约 leases:x02 ,同时在缓存中该租约信息与对应记录绑定,之后 Server - 2 执行后续逻辑。Server - 2 在更新缓存时检查租约信息与 leases:x02 匹配,完成缓存数据更新并清理租约。之后 Server - 3 带着过期租约 leases:x01 尝试更新缓存,因缓存租约不匹配且记录有数据,则放弃更新直接读取缓存记录数据。
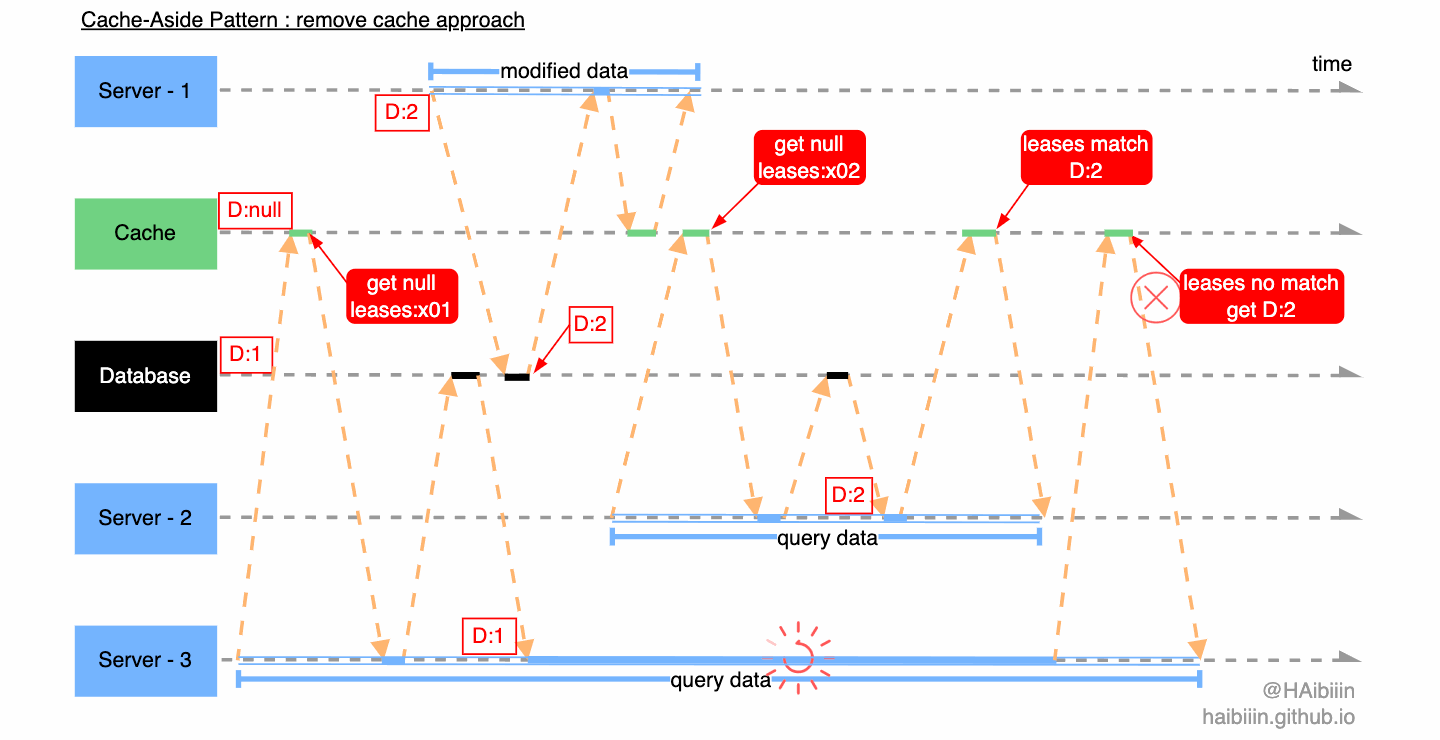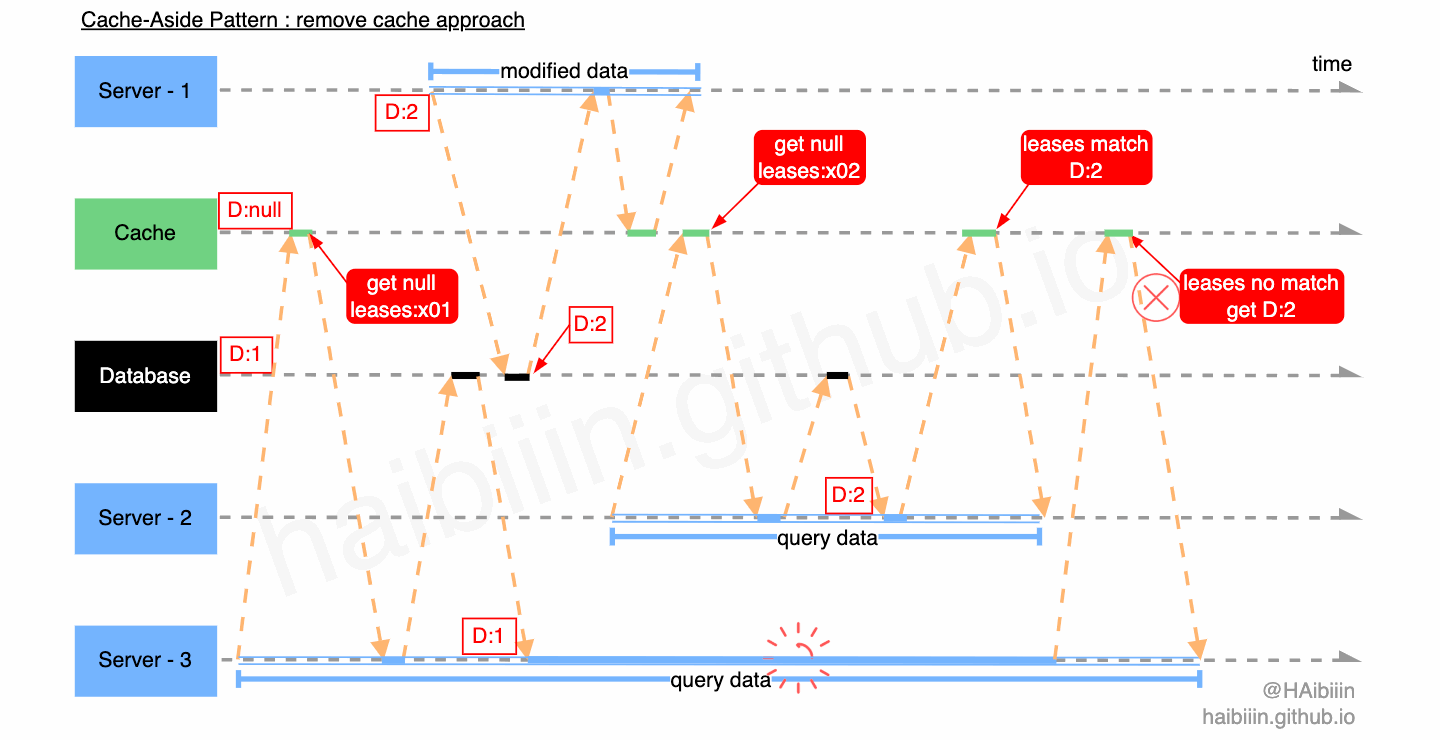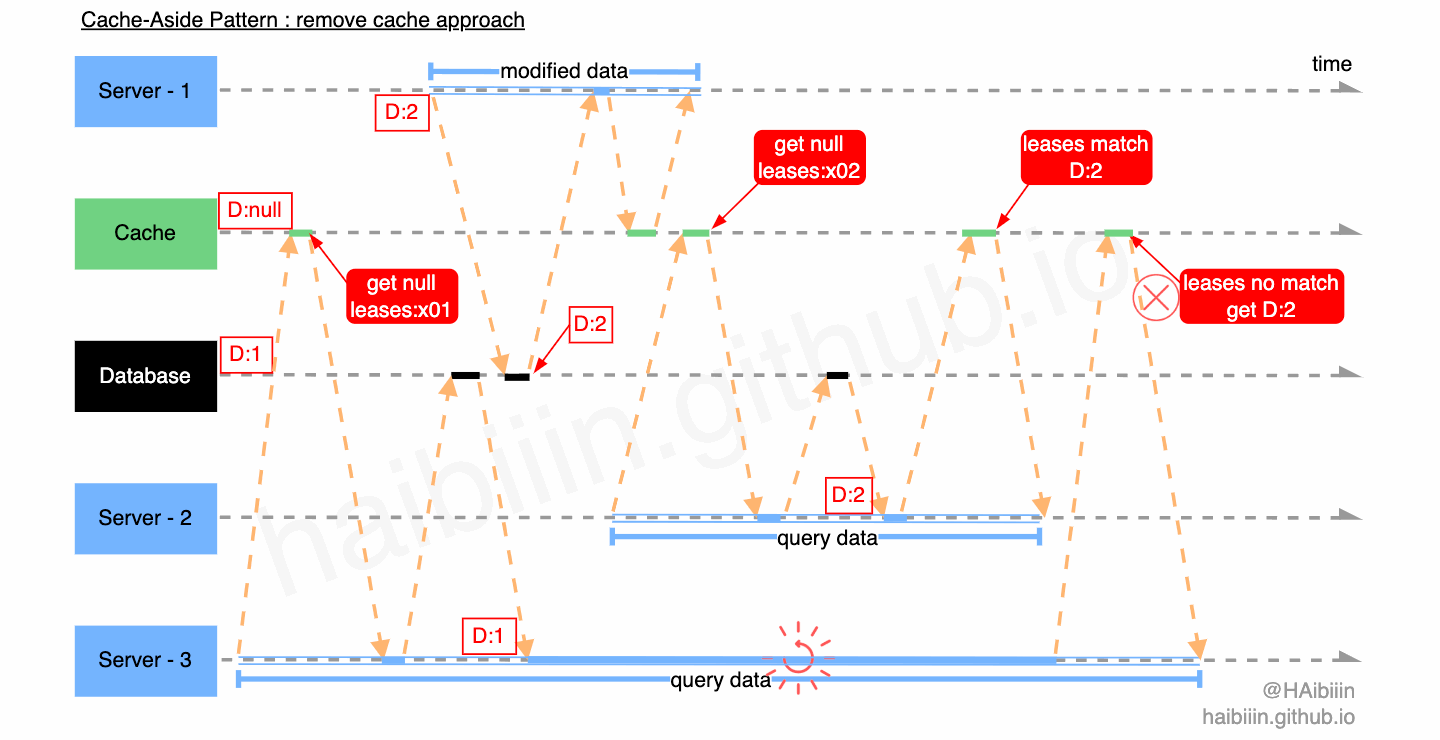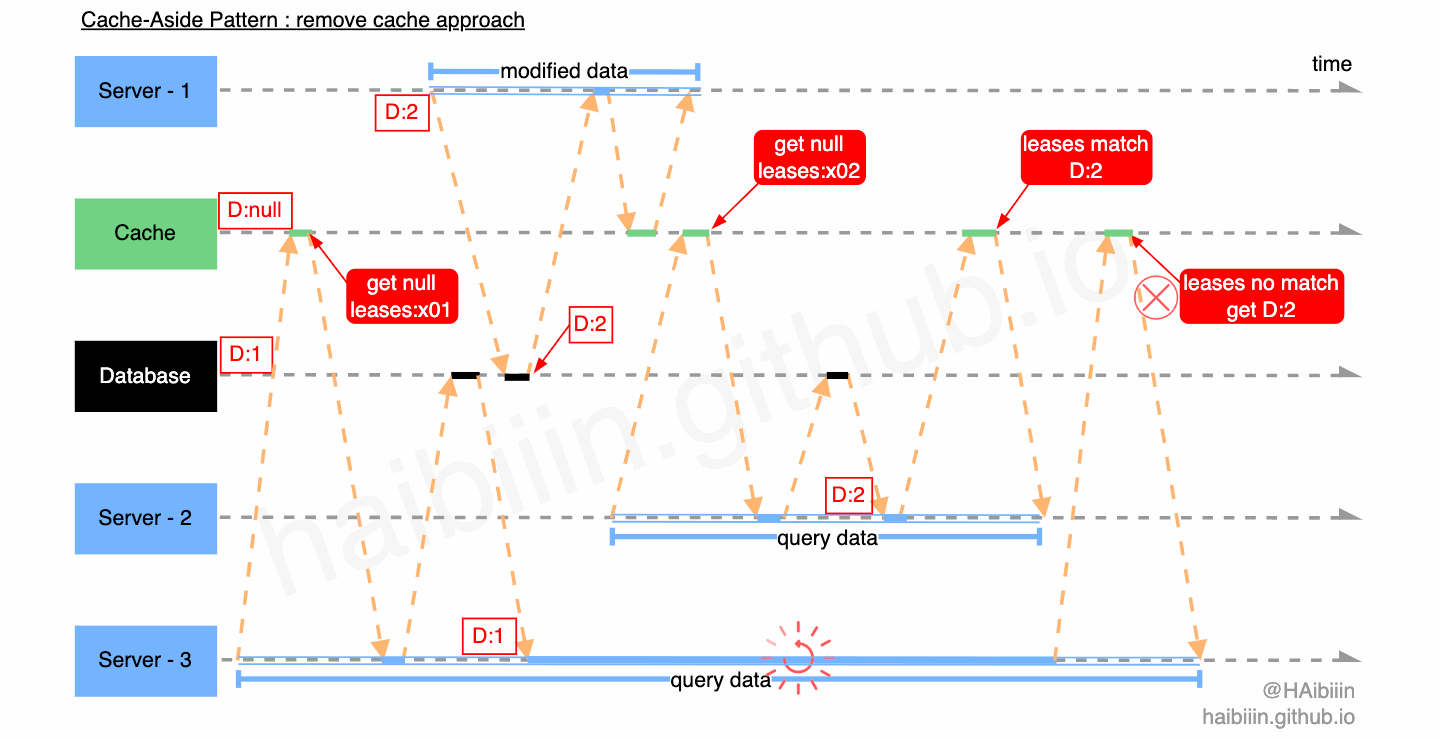
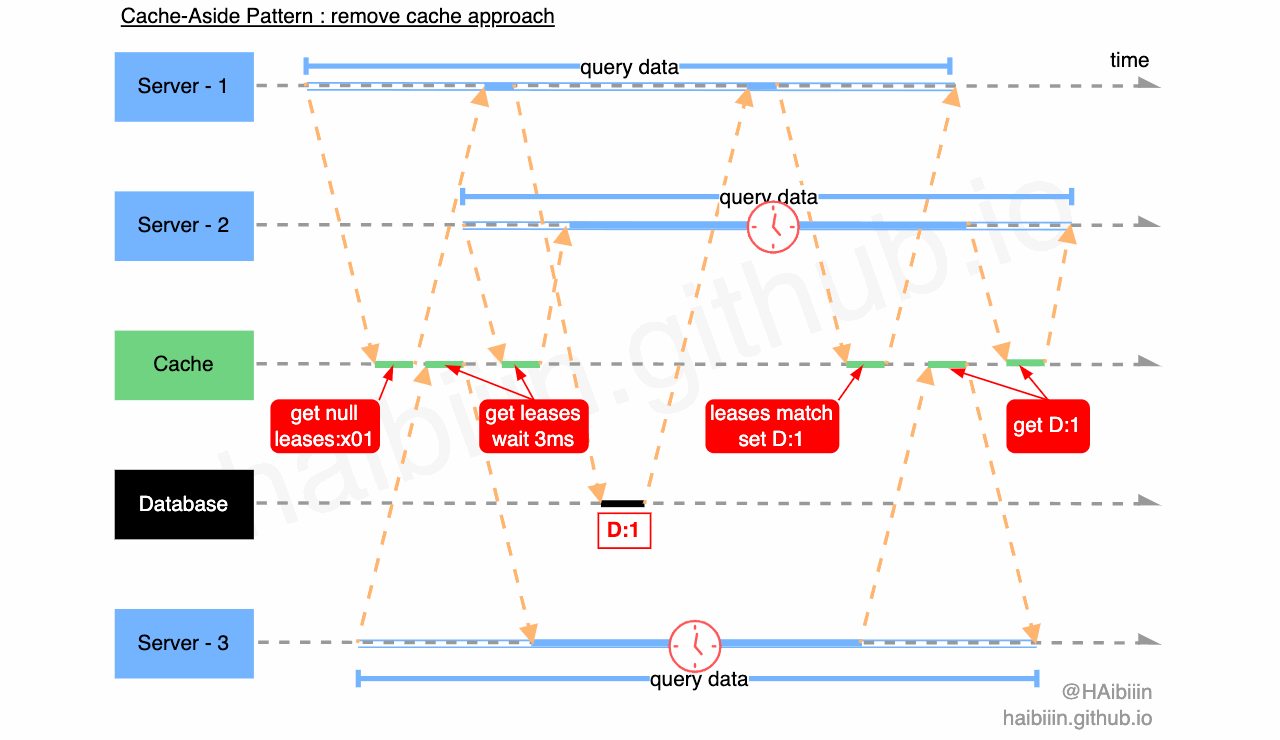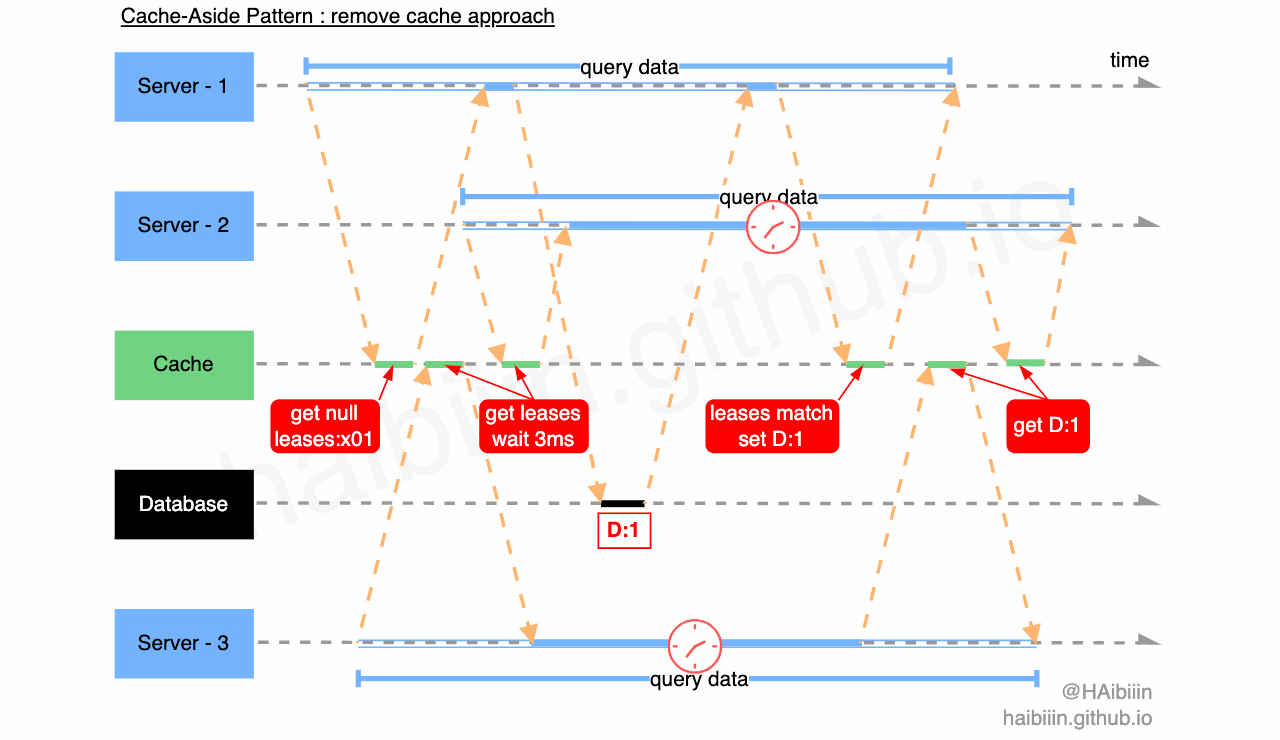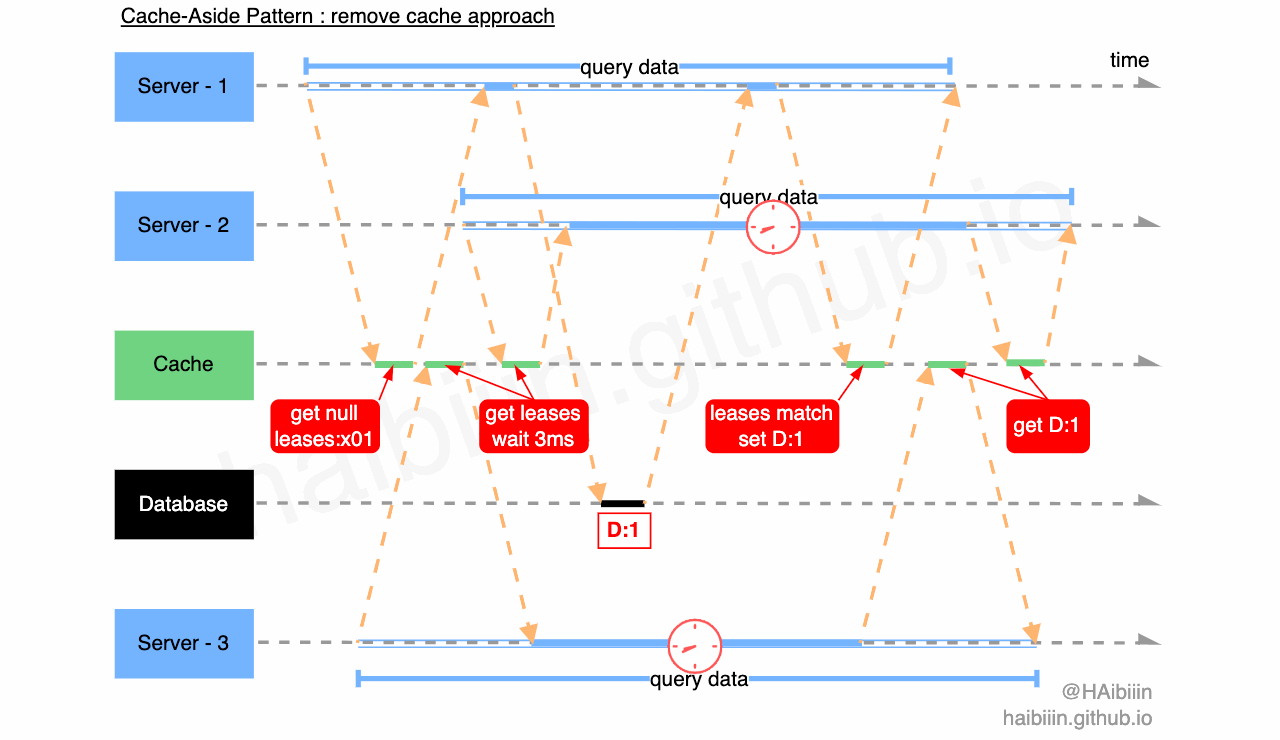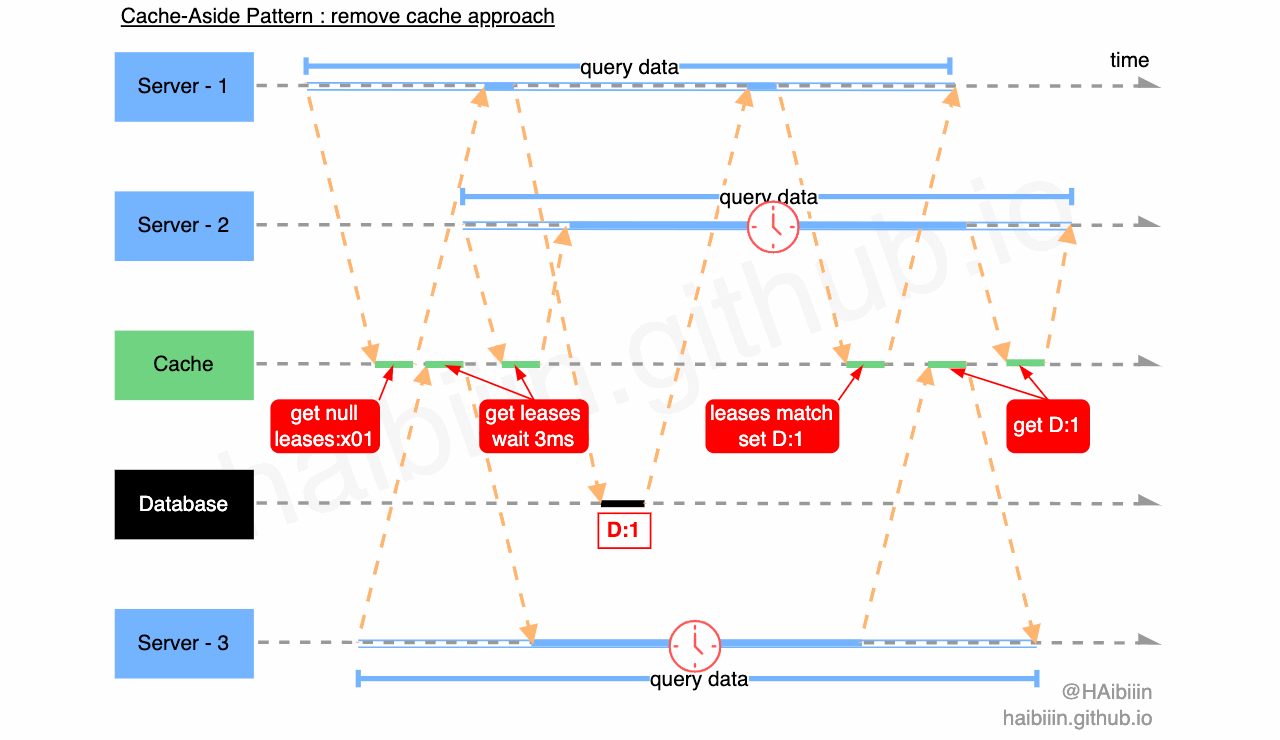
通过上述分析,我们可以发现租约机制可以解决并发问题带来的数据不一致,但是要如何处理惊群问题呢?我们结合下图进一步分析,三个应用服务 Server 1-3 分别发起数据查询请求,其中 Server - 1 先查询缓存中不存在记录数据,获取租约 leases:x01 ,同时在缓存中该租约信息与对应记录绑定。之后 Server - 2 与 3 查询缓存记录,获取到租约信息后分别等待 3ms 再向缓存发起查询请求。期间 Server - 1 完成对数据库的查询,并通过缓存的租约验证成功更新缓存,此时缓存中已经有了记录数据。Server - 2 与 3 再次发起请求时便可以直接获取缓存数据返回。
附:Redis 实现 Leases 机制
要想为 Redis 添加 Leases 机制,需要结合 Lua 脚本来实现,Lua 脚本代码示例如下:
为了与业务数据作区分,脚本中将业务存储键增加了 lease: 前缀,后续可以对指定前缀的键值数据作清理,也可以在上述脚本中对 lease: 前缀数据增加过期时间。
这里返回值对于客户端来讲变成了一个数组,需要对数组中的值进行逻辑判断处理,根据 token 有值的情况进行等待与重试处理。同样对于缓存数据的获取,也不能直接使用 Redis 的指令,需要配合 Lua 脚本实现 token 检查机制,Lua 脚本代码示例如下:
通过上述脚本可以发现,以上操作增加了数据处理复杂度。主要表现为缓存模型的变化,需要应用端做适配改造。在实际制定方案时需根据实际情况,判定是否采用上述方案保证严格的一致性。
两种实现方式的选择
至此关于缓存与主副本数据一致性系统设计算是拥有完整的解决方案。为应对缓存组件失效我们需要独立出 Batch 类组件,进行缓存操作的轮询重试。为进一步解决并发问题我们必须利用 “锁” 的机制。基于上文中给出的方案,我们会发现为了解决更新主副本后删除缓存方式的两个问题,技术实现复杂度与成本其实要高于更新主副本后更新缓存方式。但删除缓存方式在缓存空间要求上有着巨大优势。所以最终要根据实际场景下,各方因素的考量进行选择。
不过我们依然可以得出一个结论,当需要缓存的数据量不大,且存在超高并发访问的场景下,并且对数据一致性要求较高的背景下,可以采用改进后更新主副本后更新缓存方式。而潜在缓存数据量较大,同样存在超高并发访问的场景下,并且对数据一致性要求较高的背景下,可以采用改进后更新主副本后删除缓存方式。
你好,我是 HAibiiin,目前正在编写架构与系统设计系列文章。系统设计能力对于许多从业人员来讲相对薄弱,一方面缺乏实际经验的锻炼,另一方面简中互联网缺乏同类型内容。当你背了很多八股,刷了许多算法,但是面对系统设计却无从下手。当你迈过了中高级工程师的门槛,却苦于简中互联网技术内容在深度与实用性上的匮乏,而迷失了成长方向时。希望我的系列文章能给你帮助。

版权声明: 本文为 InfoQ 作者【HAibiiin】的原创文章。
原文链接:【http://xie.infoq.cn/article/9f6961ff28f723ea2092fb02d】。文章转载请联系作者。

为自己工作 2018-02-19 加入
你好,我是 HAibiiin。一名从业十年的软件研发工程师,供职过传统软件公司、金融机构与互联网大厂。擅长古法纯手工软件制作工艺,也算半个手艺人。偶尔写作擅长熵增加,记录对自我与技术的好奇。












评论