
主从副本数据一致性系统设计方案(上篇)

声明:为了力求内容的准确性,为大家提供更优质的技术内容。如果您发现文章内容中任何不准确或遗漏的部分。非常希望您能评论指正,我将尽快修正疏漏。
对应用系统来讲,为提升系统整体性能与并发度,通常会采取为系统添加基于内存的存储系统方案。由该存储系统充当缓存(本文余下内容会采用“缓存 / Cache”指代此类存储系统),实现对应用系统整体的性能提升,并带来更高的并发表现。
通常在引入缓存后,势必会导致系统内存在两个数据存储系统,另一个便是以数据库为代表的数据存储系统。因为两个数据存储系统的存在,从架构上看便天然适配主从架构。因为数据需要在两个副本之间传递复制,这一行为则带来了数据一致性问题。面对主从副本数据一致性解决方案主要分为两类,分别属于强一致性解决方案和弱一致性解决方案。本文接下来讨论的方案属于弱一致性。对于弱一致性而言,最简单的解决方式是对所有非主副本的数据变更,均通过对主副本拷贝来实现。通常多数应用会采用数据库做为数据的主副本。
如果你是一名有经验的工程师,对于缓存与数据库一致性方案一定听说过 Cache-Aside Pattern 与 Write-Through Pattern 两种模式。两种模式的最核心的区别是数据复制到缓存的时机不同。 Cache-Aside 模式不会主动将数据复制到缓存中,而是在缓存未查询到数据时,从数据库复制到缓存中,所以有名 Lazy loading 模式。Write-Through 模式则会主动将数据复制到缓存中,确保数据常驻缓存。
两种模式下数据读取方式
两种模式在数据查询场景下,执行逻辑是相同的,其过程如下:
当对于某条数据记录的查询请求到来时,应用服务先确认该数据记录是否存在于缓存中;
如果数据记录在缓存中则直接返回查询结果;
如果数据记录不在缓存中,则查询主副本(数据库)获取该数据记录;
将主副本数据记录复制到缓存中,并返回该数据记录的查询结果。
结合下图与下方的注释说明,可以进一步直观的理解数据读取时的的过程。
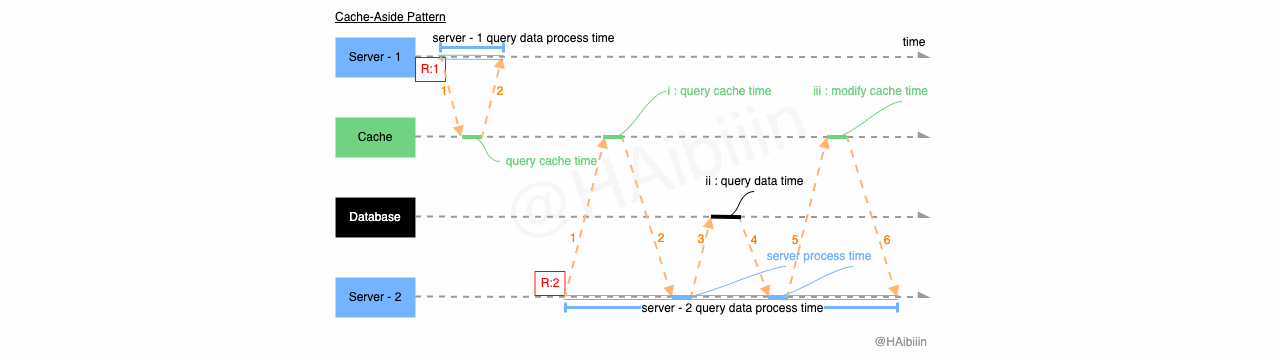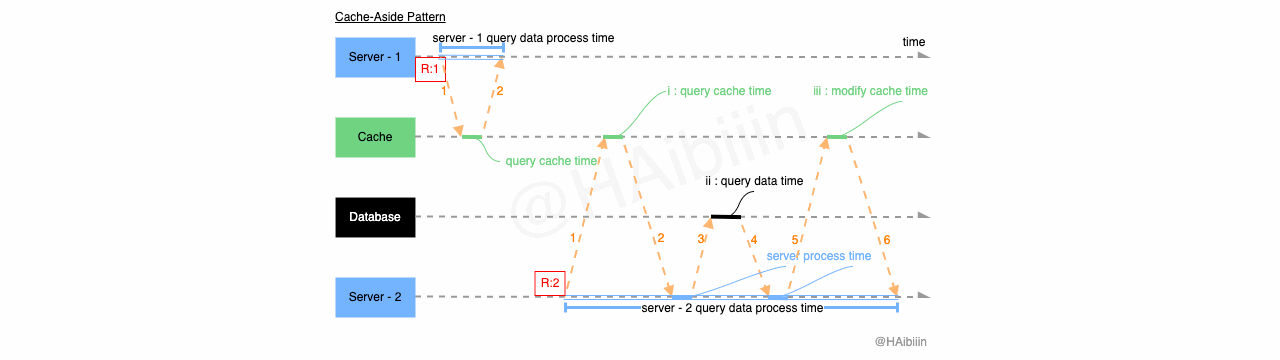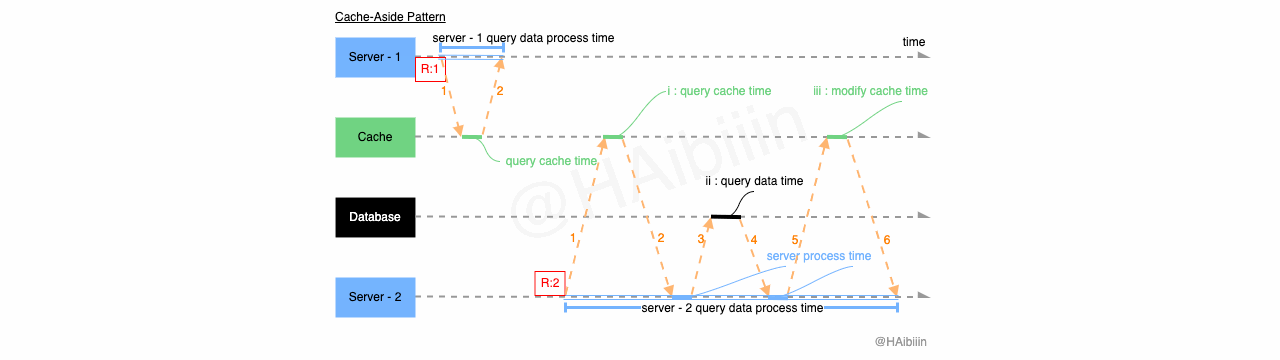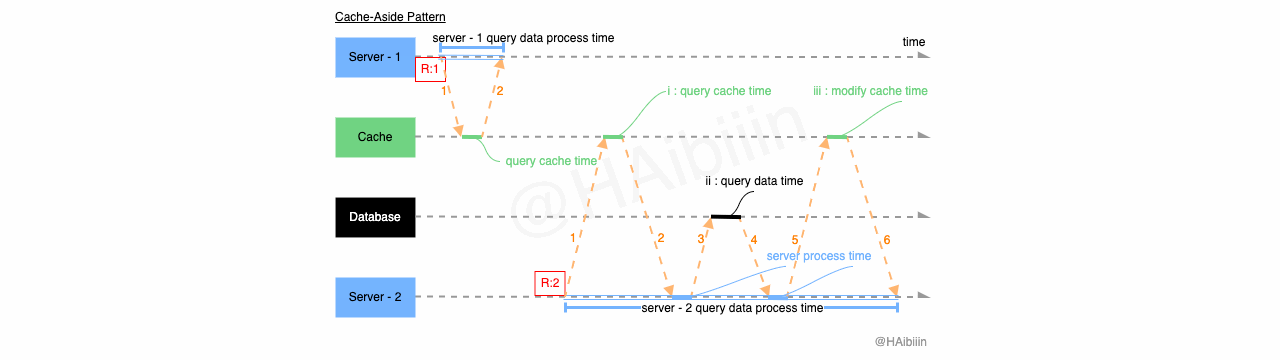
如上图所示我们通过 Server - 1 与 Server - 2 两个应用服务来分别说明两种数据读取场景(本文中的配图均会采取此种表示,后续对于相同内容不在赘述):
缓存中存在查询记录数据:
图中 Server - 1 欲查询数据记录 1 的数据,如图中红色字体所示;
与 Server - 1 相关的数字 1-2 表示 IPC 请求与响应过程,其中可以将线条的斜率理解为该过程的耗时,斜率越大耗时越久;
绿色线条表示缓存执行数据记录查询操作的耗时,如 query cache time 所示;
server - 1 query data process time 所代表的蓝色线条为执行本次缓存记录查询操作的总耗时;
缓存中不存在查询记录数据:
图中 Server - 2 欲查询数据记录 2 的数据,如图中红色字体所示,但缓存中不存在该数据;
与 Server - 2 相关的数字 1-6 表示 IPC 请求与响应过程,其中可以将线条的斜率理解为该过程的耗时,斜率越大耗时越久;
黑色线条表示数据库执行记录查询操作的耗时,即 i:query data time 所示;
蓝色线条表示应用服务执行操作耗时,如 server process time 所示,均表示收到 IPC 成功响应后准备发起后续 IPC 请求的耗时;
绿色线条表示缓存执行数据记录修改操作的耗时,即 iii:modify cache time 所示;
其中 server - 2 query data process time 所代表的蓝色线条为执行本次数据记录查询操作的总耗时;
两种模式下数据变更方式
上文中提到两种模式最核心的区别是数据复制到缓存的时机不同。因为时机不同,使得两种模式在数据变更(数据变更存在三种,分别是数据的新增、修改和删除)场景下的实现方式差异明显。接下来我们分吧分析一下两种模式数据变更流程。
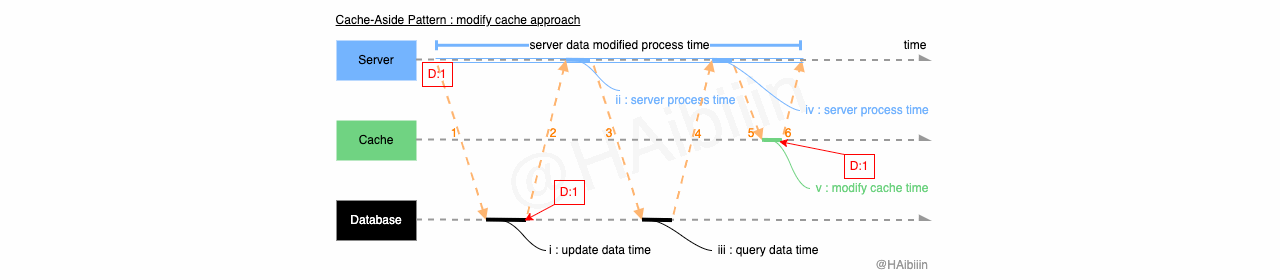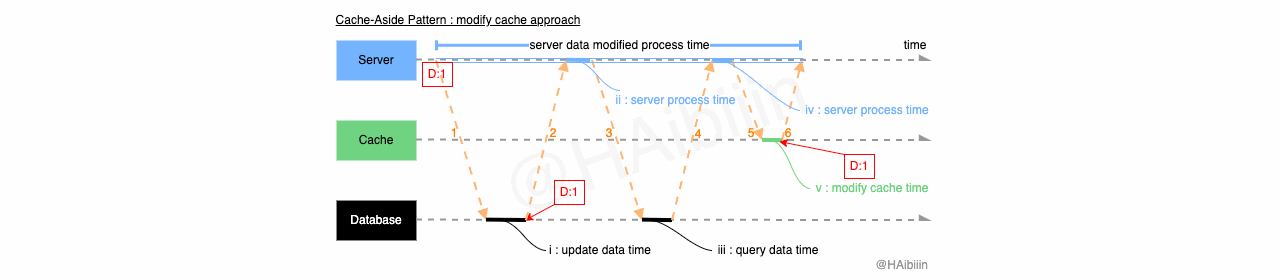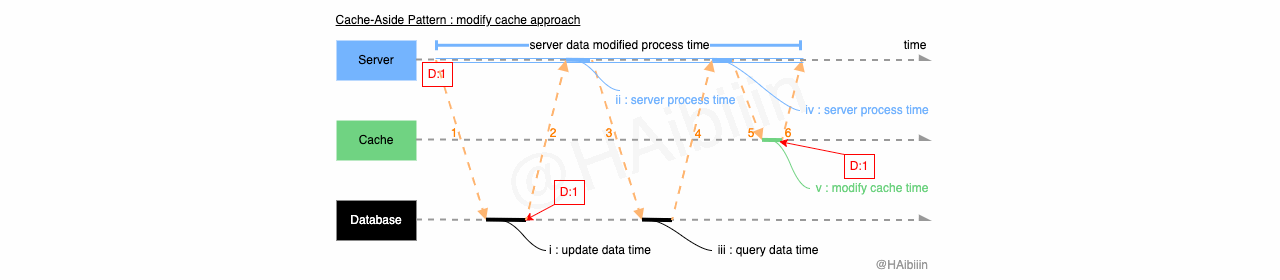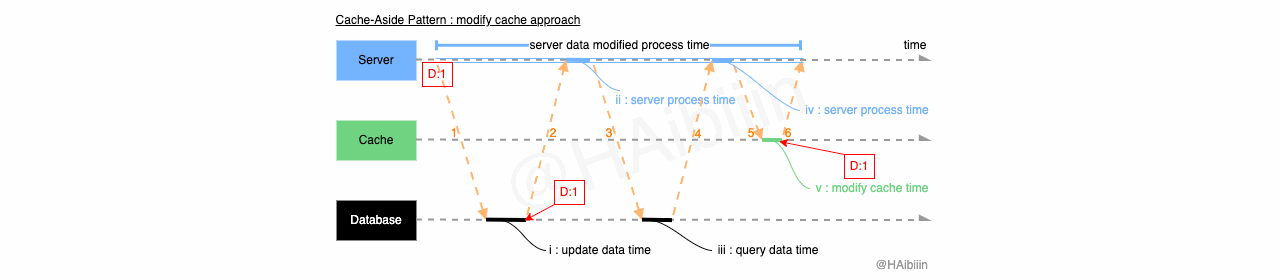
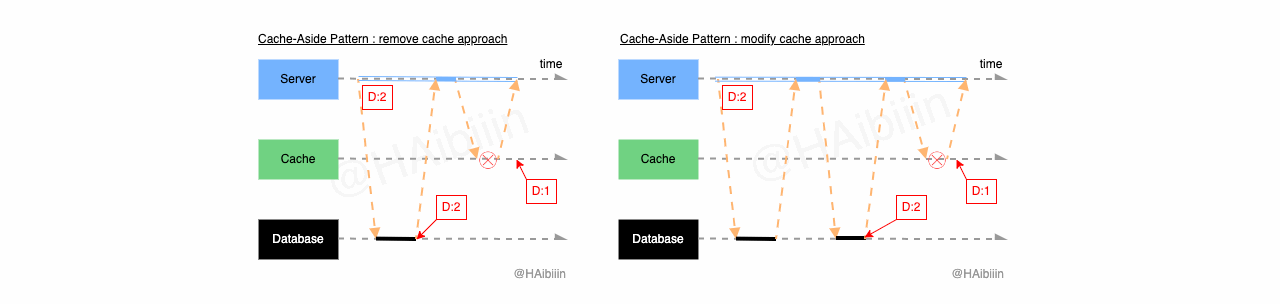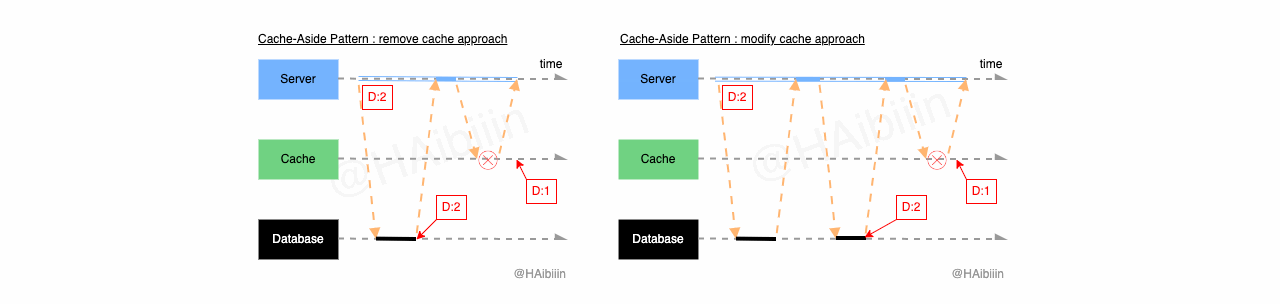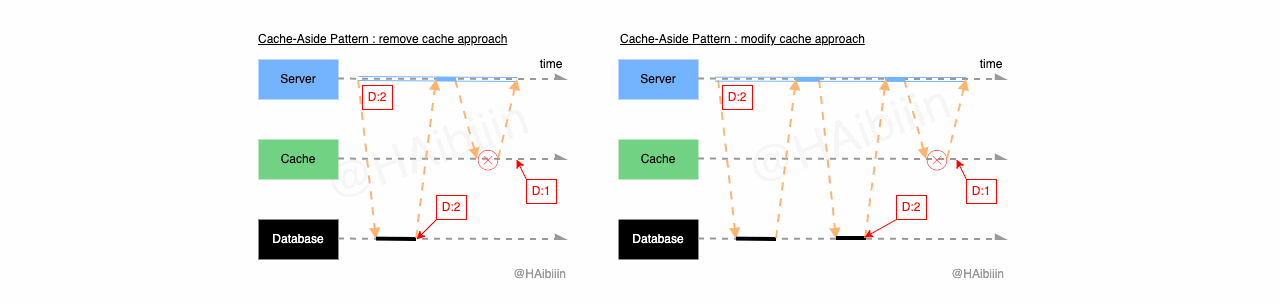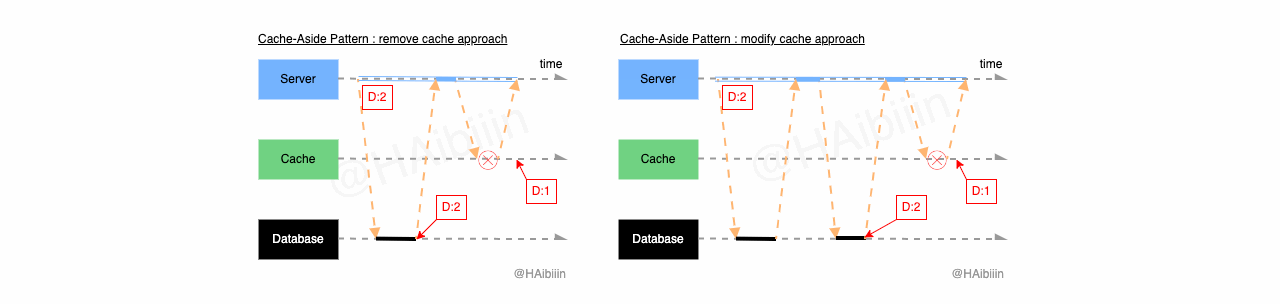
Cache-Aside 采取更新主副本数据后删除缓存方式
结合下方图示,Cache-Aside 的数据变更的实现过程描述如下:
对于某条数据记录的变更请求到来时,应用服务先变更主副本(数据库)对应数据记录;
之后删除缓存中对应数据记录;
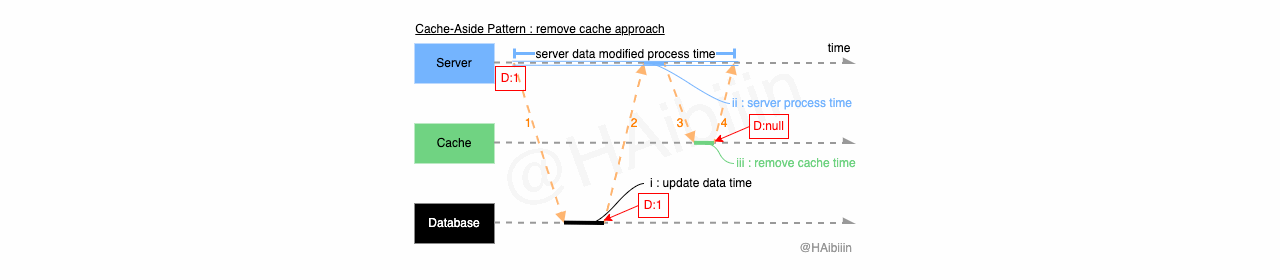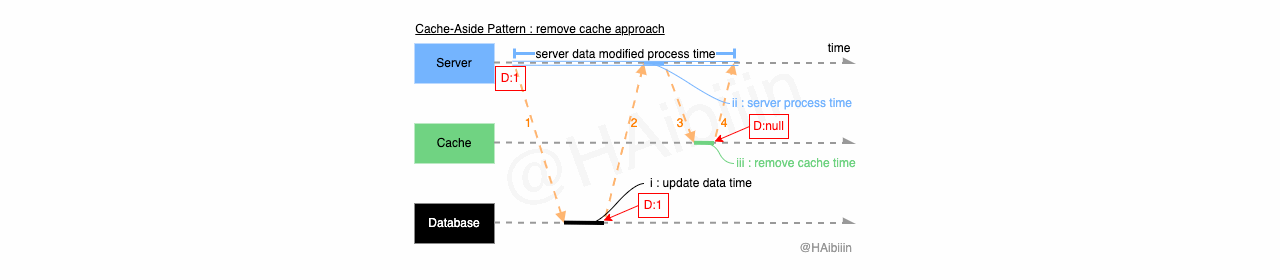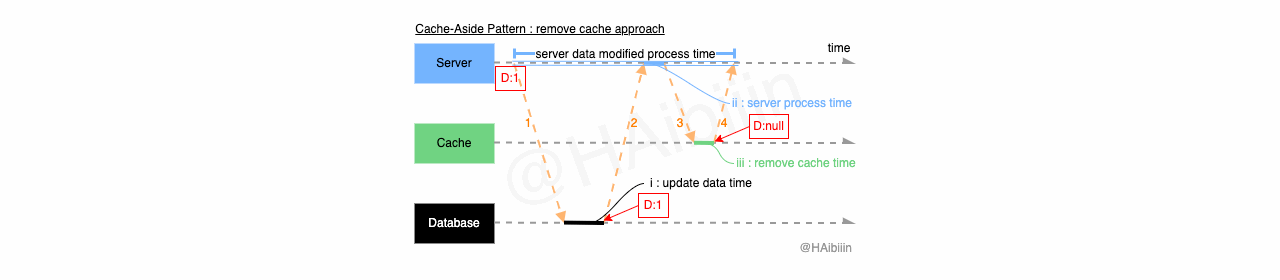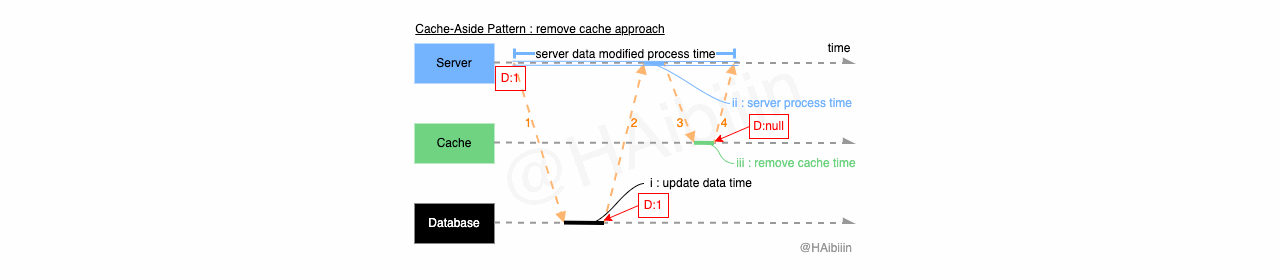
操作完成后数据库对应记录为 1,而缓存中不存在该记录值。
Write-Through 采取更新主副本数据后更新缓存方式:
结合下方图示,Write-Through 的数据变更的实现过程描述如下:
对于某条数据记录的变更请求到来时,应用服务先变更主副本(数据库)对应数据记录;
之后再次向主副本(数据库)发起对该记录的数据查询请求;
将从主副本(数据库)查询到的数据记录更新到缓存中;
操作完成后数据库与缓存中的记录均为 1。
数据不一致的问题
在前文的图示中,一直暗含着三类明显的组件。分别是代表主副本的数据库组件,以及缓存组件,余下的便是由多个实例组成的应用服务组件,这三类组件构成了一个分布式系统。
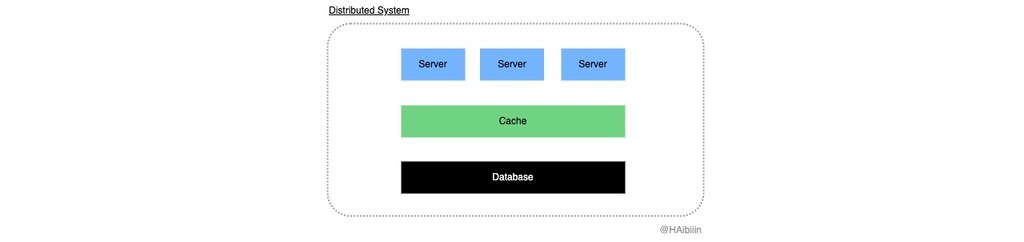
在分布式系统设计中主要面临三大挑战:对组件并发性的支持以及克服全局时钟的缺乏和管理组件的独立失效。两种模式在数据变更场景下不涉及全局时钟的问题,我们围绕对组件并发性与组件独立失效,来分析两种模式下数据不一致的场景。
首先来看面对组件独立失效时,会产生怎样的效果。因为数据库扮演者主副本的角色,所以当数据库不可用时,可以认为整个系统是失去可用性的。此时已经无需再谈及数据一致性问题了。所以我们重点关注缓存组件失效后,会产生的效果。组件失效可能存在多种原因,这里探讨的是对缓存操作失效的情况。结合下图,分别展示了两种方式下缓存操作失效引发的数据不一致。当数据修改操作完成后,数据库中记录值已被修改为 2 ,但是在两种方式下,一种记录旧数据并未删除,另一种是未成功更新缓存中的记录值。
除了针对缓存组件操作失效外,另一种分布式挑战是面对组件的并发访问特性。在面对应用服务的并发操作时,两种实现方式依然存在导致数据不一致的情况。
Cache-Aside 模式下并发访问问题
因为对于缓存的删除操作具有幂等性,所以即便是在多个应用服务并发修改的情况下,缓存数据都会以空值做为最终状态。那么会导致数据不一致的场景必然是混合了数据变更与查询的情况。
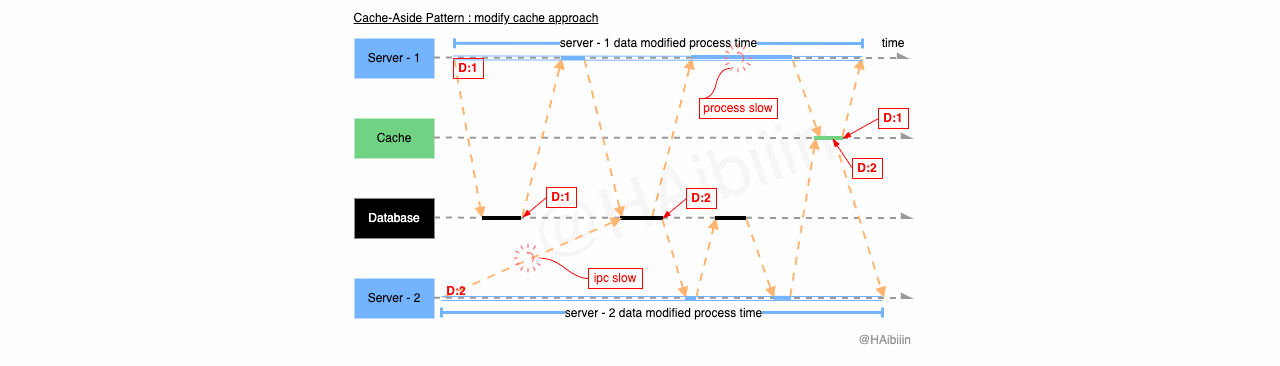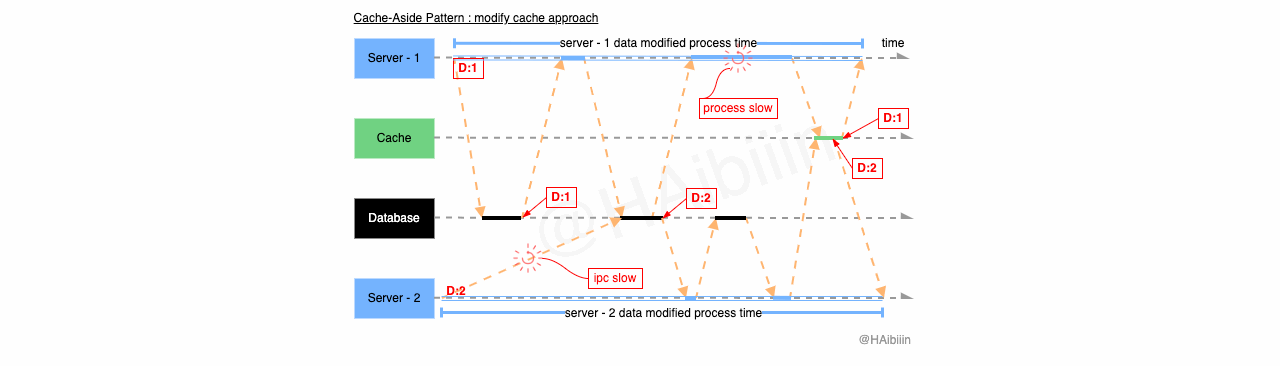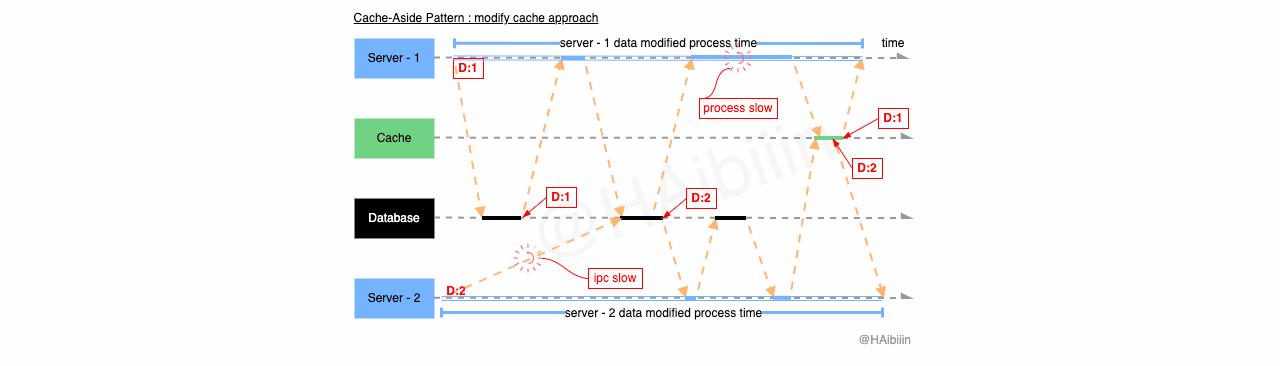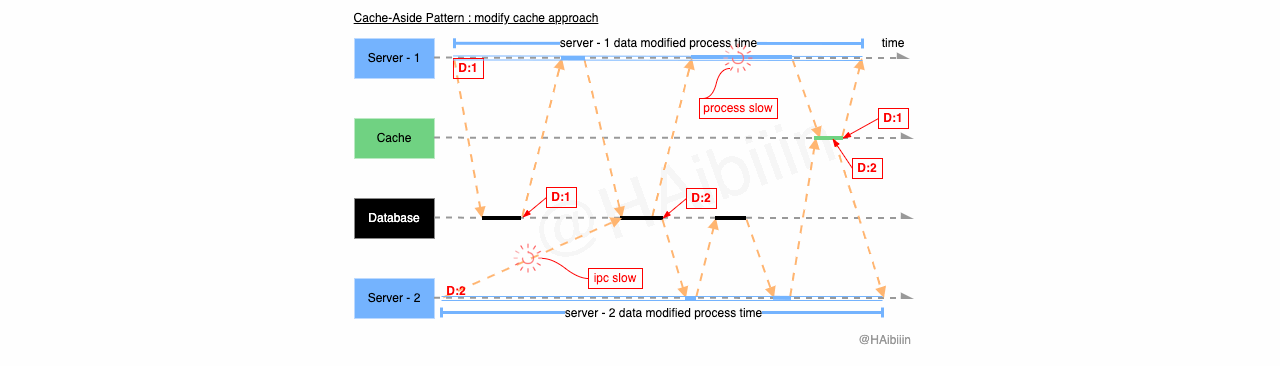
结合下面图示,系统中存在 3 个应用服务,其中服务 1-2 将同一条数据记录分别修改为 1 和 2。当 Server - 1 完成操作后,缓存中的数据已经为空值。在 Server - 2 发起数据修改前 Server - 3 执行数据查询逻辑,因为缓存中数据不存在所以从数据库中获取到记录数据为 1,并准备将其更新到缓存中。在 Server - 3 更新缓存之前 Server - 2 将记录数据更改为 2,并且在 Server - 3 更新缓存前完成了数据修改操作。如图所示 Server - 3 因为 GC 等原因导致进程/线程执行受阻,导致对缓存的更新操作滞后,将记录的历史值更新到了缓存中。最终缓存与数据主副本相同记录的数据呈现不一致的状态。

Write-Through 模式下并发访问问题
通过更新完数据库后,再次获取数据库最新值可以有效降低并发情况下出现的数据不一致现象。因为数据库行级锁的存在,导致对于数据库同一条记录的修改操作必然是顺序执行逻辑。进而对于数据库记录查询操作起到了顺序约束作用,但因为后续操作的并发性依然存在数据不一致的情况。
结合下面图示,系统中存在 2 个应用服务分别将同一条数据记录修改为 1 和 2。Server - 2 因为网络原因导致执行数据更新操作较慢,在 Server - 2 完成对数据记录更新为 2 的操作前,Server - 1 已经完成数据查询操作。此时只要 Server - 2 在 Server - 1 之前完成对缓存的更新操作,便会导致缓存与主副本数据不一致的情况,如图中所示 Server - 1 因 GC 等原因导致进程/线程执行受阻,使得更新缓存操作在 Server - 2 之后完成。最终缓存与数据库主副本相同记录的数据呈现不一致的状态。
分析完两种实现方式下可能存在的数据不一致问题,不论是针对缓存操作失效导致的不一致,还是组件并发性导致的数据不一致。两种实现方式所需要采取的解决方案是一致的,我们会在下篇对如何解决一致性问题给出改进方案。
现阶段两种实现方式的选择
将缓存做为数据从副本引入系统,通常都是为了解决数据访问性能与并发问题,即读多写少的场景。我们上文中提到两种模式的最核心的区别是数据复制到缓存的时机不同。
两者最大的区别也在读取场景下, Cache-Aside 模式存在 cache miss 的情况,而 Write-Through 模式确保数据常驻缓存,不会发生 cache miss 的情况。所以如果你的应用在超高并发访问下,无法承受 cache miss 造成对数据库(主副本)的访问压力时,毫无疑问只能选择 Write-Through 模式。不过代价则是需要更大容量的缓存存储数据,因为 Write-Through 模式下缓存数据是全量复制于主副本。
通常情况下,超高并发访问场景也是针对数据而言,极少会存在全量数据均处于高并发情况下。所以我们可以基于热点数据的维度,将两种模式进行结合,以换取较低的缓存容量要求。实现方式会略复杂一些,如果你感兴趣的话,请留言告诉我,我会在后续文章中探讨具体实现。
在实现复杂度上,基于本文目前讨论的方案来讲,两种的实现复杂度几乎相同,如果要区分话 Write-Through 模式相对复杂一点,但是做为决策因素上几乎可以忽略不计。
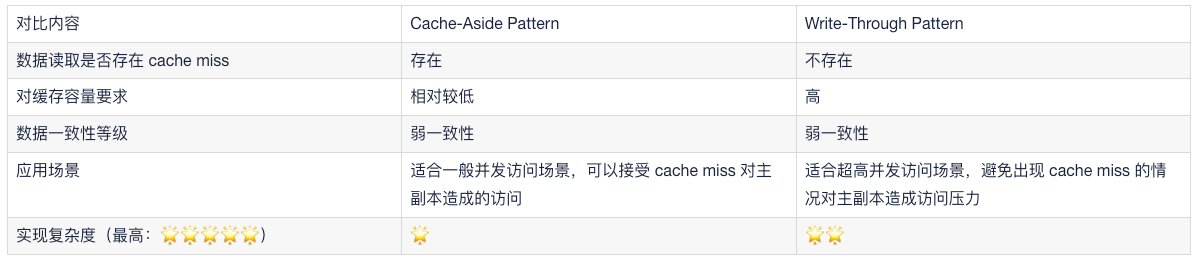
最后,两种实现方式在数据一致性等级方面均属弱一致性,所以依然存在数据不一致情况,我会在下篇中给出解决不一致的方案,到时候我们会对两者的选择再进行一次对比。如果你对数据一致性要求没有那么高的话,可以基于以下表格选择适合于自身应用场景的解决方案。
未完待续
你好,我是 HAibiiin。一名从业十年的软件研发工程师,供职过传统软件公司、金融机构与互联网大厂。目前正在编写架构与系统设计系列文章,如果我的内容对你有所启发或帮助,非常欢迎你能留言告诉我,那会是对我最好的嘉奖。如果你不介意收藏与关注列表多一个陌生人,非常欢迎你的关注,那会是我坚持的动力。
版权声明: 本文为 InfoQ 作者【HAibiiin】的原创文章。
原文链接:【http://xie.infoq.cn/article/c4a600269551579fad375af2a】。文章转载请联系作者。

为自己工作 2018-02-19 加入
大家好,我是一名全靠抱腿工程师,走在成为理论强于实践型架构师的路上......












评论