
一种全新的日志异常检测评估框架:LightAD

本文分享自华为云社区《【AIOps】一种全新的日志异常检测评估框架:LightAD,相关成果已被软工顶会ICSE 2024录用》,作者: DevAI。
深度学习(DL)虽然在日志异常检测中得到了不少应用,但在实际轻量级运维模型选择中,必须仔细考虑异常检测方法与计算成本的关系。具体来说,尽管深度学习方法在日志异常检测方面取得了出色的性能,但它们通常需要更长的时间来进行日志预处理、模型训练和模型推断,从而阻碍了它们在需要快速部署日志异常检测服务的在线分布式云系统中的采用。本文对现有的基于经典机器学习和深度学习方法的日志异常检测方法进行了实证研究,并提出了一种自动化日志异常检测评估框架 LightAD。
1. 日志异常检测介绍
日志是 AIOps 领域需要处理的常见数据,是程序运行过程中由代码打印出的一些非结构化的文本信息,日志通常由时间戳和文本信息组成。日志实时记录了系统的运行状态,包括正常运行状态和故障发生时的状态。因此通过收集和分析日志,可以快速检测和定位出系统中存在的异常。本文研究了深度学习方法在日志异常检测中与更简单技术相比的优越性,在五个公共的日志异常检测数据集上对轻量级传统机器学习方法(如 KNN、SLFN)和深度学习方法(如 CNN、NeuralLog)进行了全面的评估。本文的研究结果表明,通过合适的数据处理方式,轻量级机器学习方法能够在时间效率和准确性方面都优于深度学习方法。为了评估深度学习方法的必要性,本文提出了一种自动化的日志异常检测模型评估框架 LightAD。LightAD 是一种基于贝叶斯优化器的优化训练时间、推断时间和性能得分的评估框架。通过自动化超参数调优,LightAD 可以实现在日志异常检测模型之间进行公正的比较,使运维工程师能够针对不同的在线异常检测目标来选择合适的异常检测模型。
2. 对现有方法的全面评估
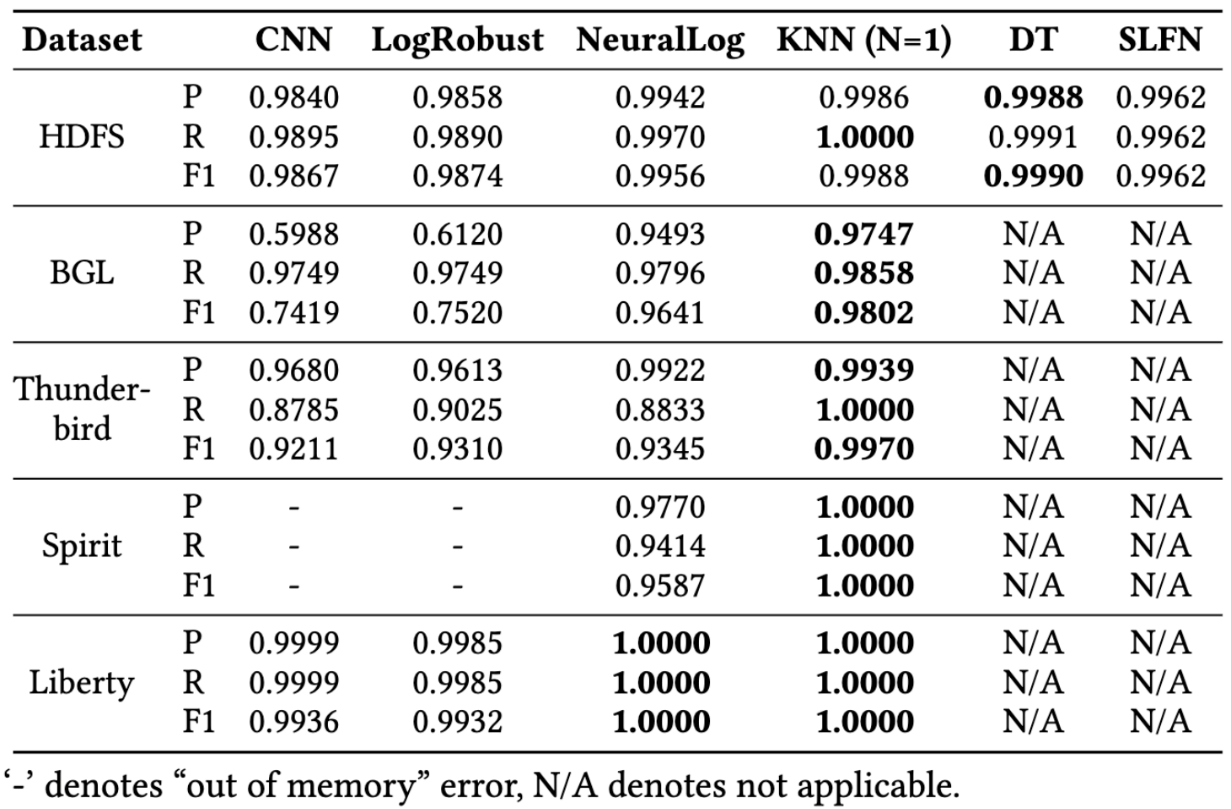
本文主要选用了当前效果最好的深度学习算法(包括 CNN/LogRobust/NeuralLog)与常用的轻量级传统机器学习算法(包括 KNN/DT/SLFN)在 HDFS,BGL,Thunderbird,Spirit,Liberty 等五个公开数据集上进行异常检测准确性的比较,图中展示了这些方法在不同指标上的评估结果。从图中可以看出,从 F1-Score 得分来看,在五个公开的日志异常检测数据集上,轻量级传统机器学习方法都比深度学习方法取得了更好的效果(黑体标出)。
深度学习方法除了本身拥有更多的参数量外,其使用的数据处理方式通常也比较耗时。例如,CNN 方法需要使用日志解析工具对日志进行解析,NeuralLog 需要用深度语言模型 BERT 来对日志进行处理。本文对轻量级传统机器学习方法采用了更高效的日志处理方式。具体而言,本文在处理以日志块来聚合的数据集(如 HDFS)时,从每个文本日志消息中提取标记,以空格分隔,并删除包含数字的标记。本文使用每个块的 ID 将日志消息分组成日志序列,并用事件频率对其进行编码。整个预处理工作流程如下图所示。

对于按消息组织的数据集(如 BGL、Thunderbird、Spirit 和 Liberty),本文使用的异常检测方法更加轻便。下图说明了这种方法,本文首先使用与 HDFS 数据集相同的预处理方式对日志消息进行标记化处理,唯一的区别是,本文不将标记化的日志消息转换为数值向量,而是通过计算 Jaccard 距离来衡量日志消息之间的距离。
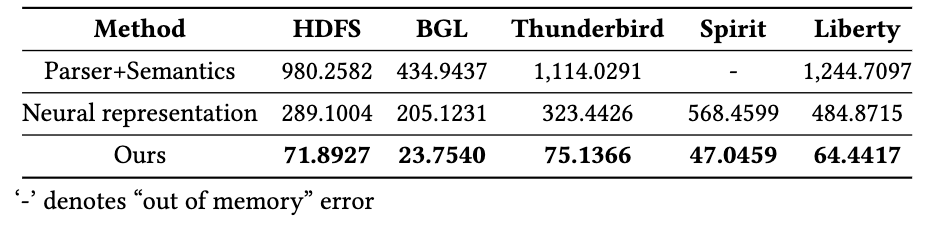
由下图可以看出,本文所使用的处理方法在五个数据集中都只需要最少的执行时间。相比于基于神经网络的表示方法,本文使用的预处理策略运行速度快 4 倍到 12 倍;相比于带语义提取的日志解析方法,则快了 13.6 倍到 19.3 倍。

除数据处理时间外,在训练时间和推理时间评估中,深度学习方法的效率也有较大程度差于轻量级传统机器学习方法。如下图所示,在 HDFS 数据集上,KNN 方法具有最少的训练时间(例如,比 NeuralLog 快 3,225 倍),而 DT 方法具有最少的推断时间(例如,比 NeuralLog 快 185 倍)。对于其他四个数据集而言,轻量级的机器学习方法在训练和推断阶段也都有着显著的效率优势。例如,对于 BGL 数据集而言,KNN 的训练时间比 NeuralLog 快 1,278 倍,KNN 的推断时间比 NeuralLog 快 23 倍。
3. 全新的日志异常检测评估框架:LightAD
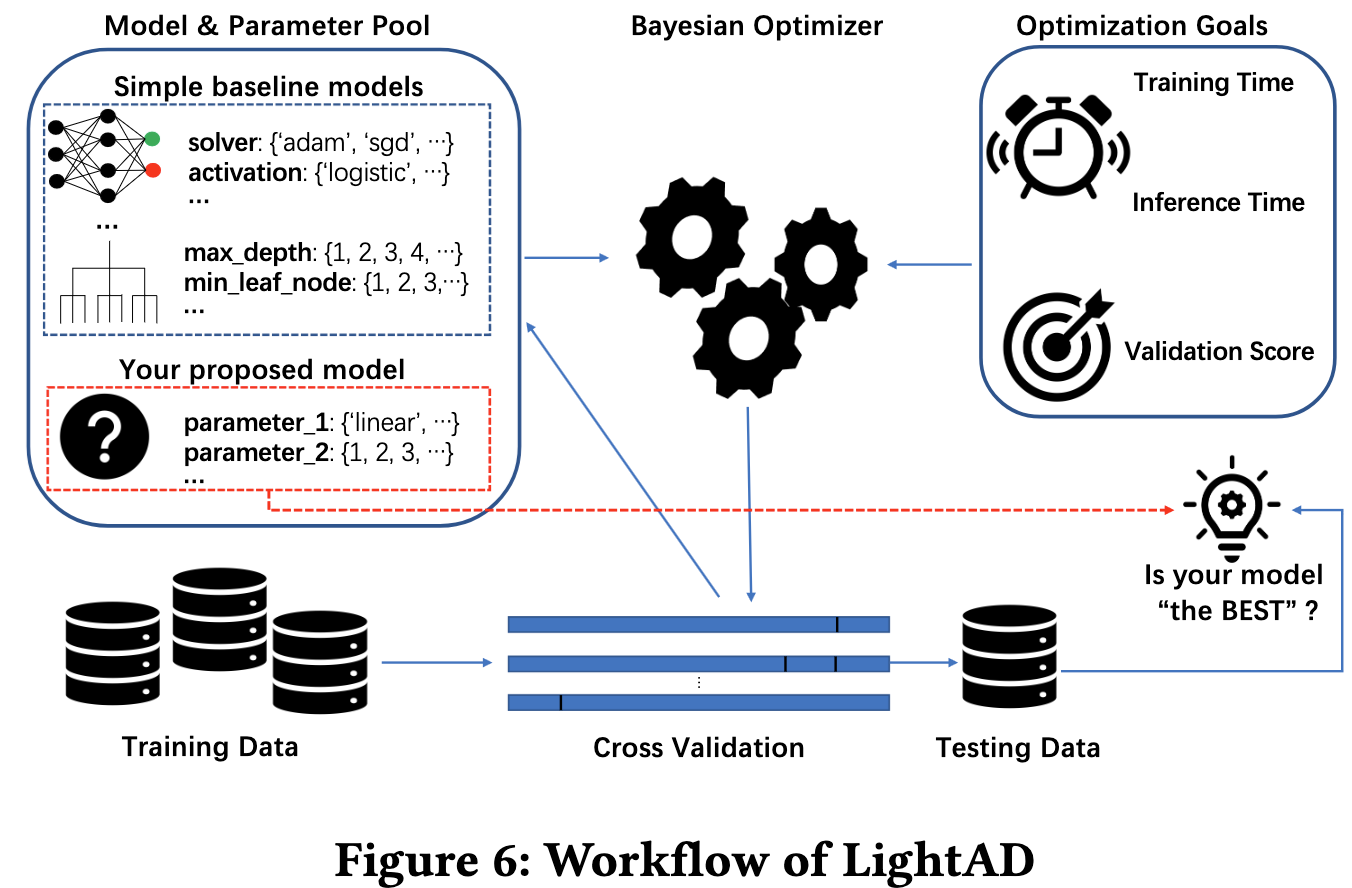
为全面综合评估日志异常检测算法,本文提出了基于贝叶斯优化起的自动化算法优化和评估框架 LightAD,LightAD 结构如下图所示。本文首先准备了一组简单的基准模型及其初始的超参数空间,对于每个模型,本文会自动化的优化模型的超参数。通过综合考虑三个维度的模型收益打分:(1)准确性,(2)每个日志序列的训练时间,以及(3)每个日志序列的推断时间,最终抉择出模型收益分数最高的异常检测算法。
模型收益的多目标优化公式如下:
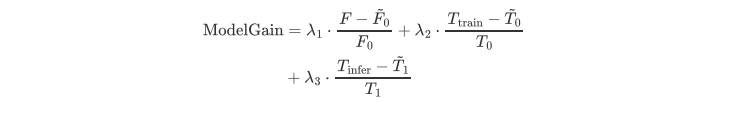
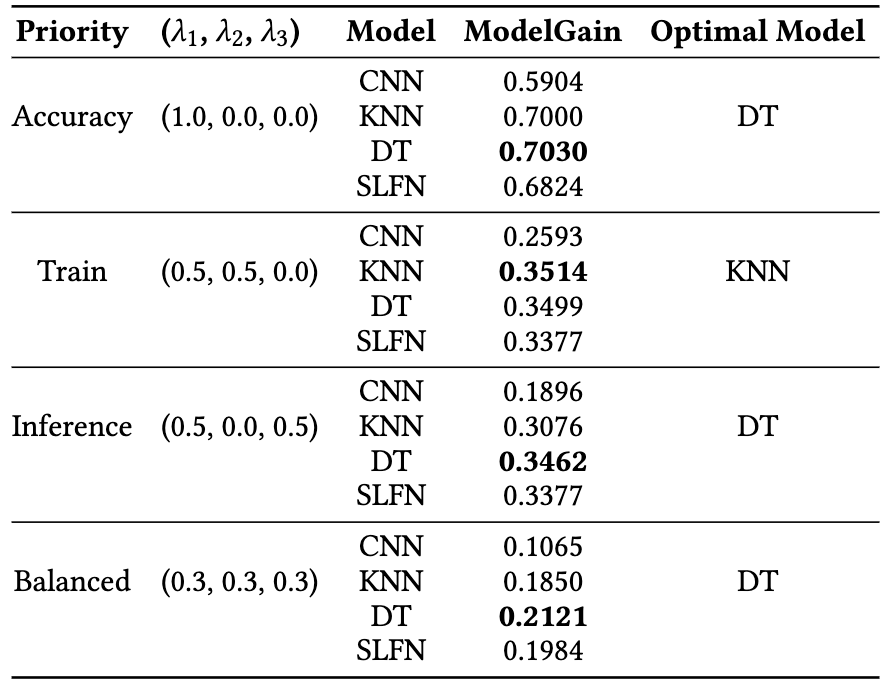
下图是在去除重复数据的 HDFS 数据集上使用 LightAD 进行异常检测方法优化和评估的结果,最高模型收益的分数由黑色加粗标识。从图中可以看出,LightAD 挑选出的模型都是轻量级的机器学习方法。
4. 总结
本文来自华为云 PaaS 技术创新 Lab 和香港中文大学(深圳)贺品嘉助理教授团队合作项目成果产出,相关研究成果已被软件工程领域顶会 ICSE 2024(CCF A 类)正式录用,文章详细内容即将公开,敬请关注。
文章来自:PaaS 技术创新 Lab,PaaS 技术创新 Lab 隶属于华为云,致力于综合利用软件分析、数据挖掘、机器学习等技术,为软件研发人员提供下一代智能研发工具服务的核心引擎和智慧大脑。我们将聚焦软件工程领域硬核能力,不断构筑研发利器,持续交付高价值商业特性!加入我们,一起开创研发新“境界”!
PaaS 技术创新 Lab 主页链接:https://www.huaweicloud.com/lab/paas/home.html
版权声明: 本文为 InfoQ 作者【华为云开发者联盟】的原创文章。
原文链接:【http://xie.infoq.cn/article/9b44c8fb3a67e04e199f6f980】。文章转载请联系作者。

提供全面深入的云计算技术干货 2020-07-14 加入
生于云,长于云,让开发者成为决定性力量









评论