
在昇腾平台上对 TensorFlow 网络进行性能调优

本文分享自华为云社区《在昇腾平台上对TensorFlow网络进行性能调优》,作者:昇腾 CANN 。
用户将 TensorFlow 训练网络迁移到昇腾平台后,如果存在性能不达标的问题,就需要进行调优。本文就带大家了解在昇腾平台上对 TensorFlow 训练网络进行性能调优的常用手段。
首先了解下性能调优的全流程:
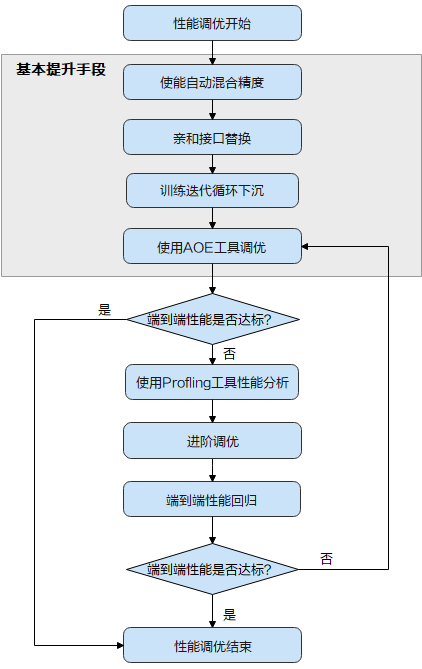
当 TensorFlow 训练网络性能不达标时,首先可尝试昇腾平台提供的“三板斧”操作,即上图中的“基本提升手段”:使能自动混合精度 > 进行亲和接口的替换 > 使能训练迭代循环下沉 > 使用 AOE 工具进行调优。
基本调优操作完成后,需要再次执行模型训练并评估性能,如果性能达标了,调优即可结束;如果未达标,需要使用 Profling 工具采集详细的性能数据进一步分析,从而找到性能瓶颈点,并进一步针对性的解决,这部分调优操作需要用户有一定的经验,难度相对较大,我们将这部分调优操作称为进阶调优。
本文主要带大家详细了解基本调优操作,即上图中的灰色底纹部分。
使能自动混合精度
混合精度是业内通用的性能提升方式,通过降低部分计算精度提升数据计算的并行度。混合计算训练方法通过混合使用 float16 和 float32 数据类型来加速深度神经网络的训练过程,并减少内存使用和存取,从而可以提升训练网络性能,同时又能基本保证使用 float32 训练所能达到的网络精度。
Ascend 平台提供了“precision_mode”参数用于配置网络的精度模式,用户可以在训练脚本的运行配置中添加此参数,并将取值配置为“allow_mix_precision”,从而使能自动混合精度,下面以手工迁移的训练脚本为例,介绍配置方法。
Estimator 模式下,在 NPURunConfig 中添加 precision_mode 参数设置精度模式:npu_config=NPURunConfig( model_dir=FLAGS.model_dir, save_checkpoints_steps=FLAGS.save_checkpoints_steps, session_config=tf.ConfigProto(allow_soft_placement=True,log_device_placement=False), precision_mode="allow_mix_precision" )
sess.run 模式下,通过 session 配置项 precision_mode 设置精度模式:config = tf.ConfigProto(allow_soft_placement=True) custom_op = config.graph_options.rewrite_options.custom_optimizers.add() custom_op.name = "NpuOptimizer" custom_op.parameter_map["use_off_line"].b = True custom_op.parameter_map["precision_mode"].s = tf.compat.as_bytes("allow_mix_precision") … with tf.Session(config=config) as sess: print(sess.run(cost))
亲和接口替换
针对 TensorFlow 训练网络中的 dropout、gelu 接口,Ascend 平台提供了硬件亲和的替换接口,从而使网络获得更优性能。
对于训练脚本中的 nn.dropout,建议替换为 Ascend 对应的 API 实现,以获得更优性能:layers = npu_ops.dropout()
若训练脚本中存在 layers.dropout、tf.layers.Dropout、tf.keras.layers.Dropout、tf.keras.layers.SpatialDropout1D、tf.keras.layers.SpatialDropout2D、tf.keras.layers.SpatialDropout3D 接口,建议增加头文件引用:from npu_bridge.estimator.npu import npu_convert_dropout
对于训练脚本中的 gelu 接口,建议替换为 Ascend 提供的 gelu 接口,以获得更优性能。
例如,TensorFlow 原始代码:
迁移后的代码:
训练迭代循环下沉
训练迭代循环下沉是指在 Host 调用一次,在 Device 执行多次迭代,从而减少 Host 与 Device 间的交互次数,缩短训练时长。用户可通过 iterations_per_loop 参数指定训练迭代的次数,该参数取值大于 1 即可使能训练迭代循环下沉的特性。
使用该特性时,要求训练脚本使用 TF Dataset 方式读数据,并开启数据预处理下沉,即 enable_data_pre_proc 开关配置为 True,例如 sess.run 配置示例如下:
其他使用约束,用户可参见昇腾文档中心的《TensorFlow 模型迁移和训练指南》。
Estimator 模式下,通过 NPURunConfig 中的 iterations_per_loop 参数配置训练迭代循环下沉的示例如下:
AOE 自动调优
昇腾平台提供了 AOE 自动调优工具,可对网络进行子图调优、算子调优与梯度调优,生成最优调度策略,并将最优调度策略固化到知识库。模型再次训练时,无需开启调优,即可享受知识库带来的收益。
建议按照如下顺序使用 AOE 工具进行调优:
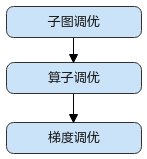
训练场景下使能 AOE 调优有两种方式:
通过设置环境变量启动 AOE 调优。# 1:子图调优 # 2:算子调优 # 4:梯度调优 export AOE_MODE=2
修改训练脚本,通过“aoe_mode”参数指定调优模式,例如:
sess.run 模式,训练脚本修改方法如下:
estimator 模式下,训练脚本修改方法如下:
以上就是 TensorFlow 网络在昇腾平台上进行性能调优的常见手段。关于更多文档介绍,可以在昇腾文档中心查看,您也可在昇腾社区在线课程板块学习视频课程,学习过程中的任何疑问,都可以在昇腾论坛互动交流!
相关参考:
[1]昇腾文档中心
[2]昇腾社区在线课程
[3]昇腾论坛
版权声明: 本文为 InfoQ 作者【华为云开发者联盟】的原创文章。
原文链接:【http://xie.infoq.cn/article/976cff8c9bf29929c8c1502cf】。文章转载请联系作者。

提供全面深入的云计算技术干货 2020-07-14 加入
生于云,长于云,让开发者成为决定性力量









评论