
大模型那么火,教你一键 Modelarts 玩转开源 LlaMA(羊驼) 大模型

本文分享自华为云社区《大模型那么火,教你一键Modelarts玩转开源LlaMA(羊驼)大模型》,作者:码上开花_Lancer 。
近日, LlaMA(羊驼)这个大模型再次冲上热搜!
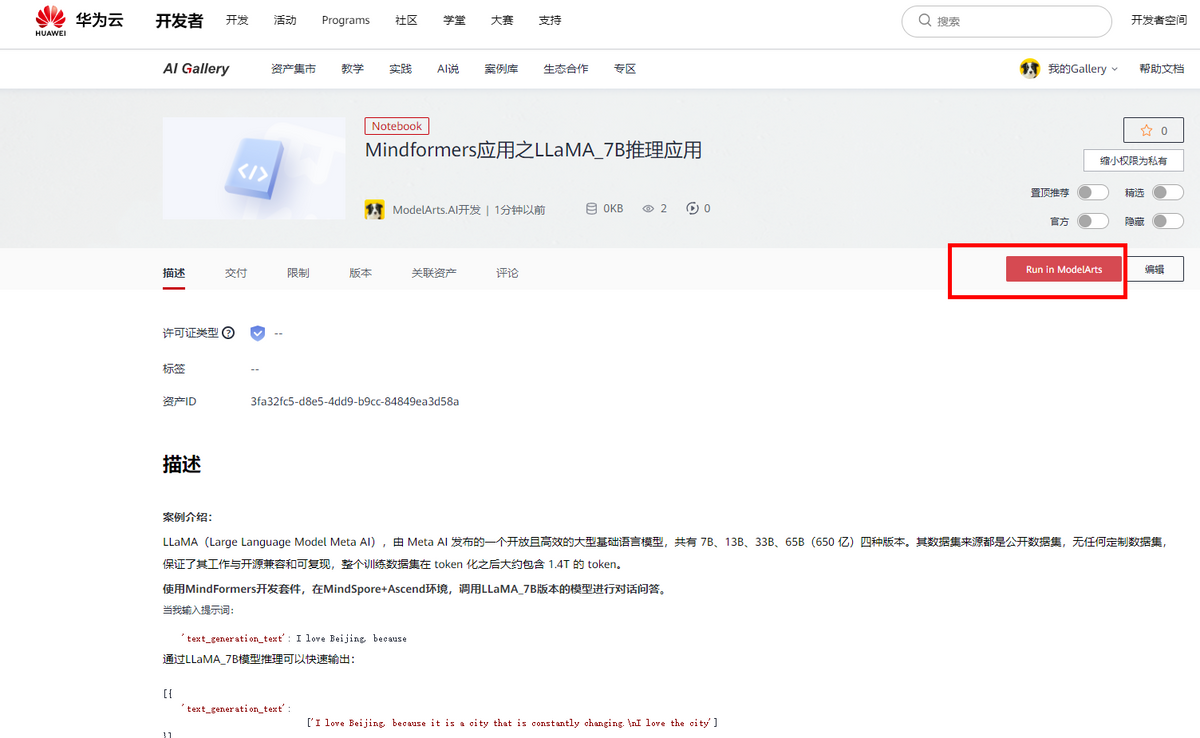
LLaMA(Large Language Model Meta AI),由 Meta AI 发布的一个开放且高效的大型基础语言模型,共有 7B、13B、33B、65B(650 亿)四种版本。其数据集来源都是公开数据集,无任何定制数据集,保证了其工作与开源兼容和可复现,整个训练数据集在 token 化之后大约包含 1.4T 的 token。关于模型性能,LLaMA 的性能非常优异:具有 130 亿参数的 LLaMA 模型「在大多数基准上」可以胜过 GPT-3( 参数量达 1750 亿),而且可以在单块 V100 GPU 上运行;而最大的 650 亿参数的 LLaMA 模型可以媲美谷歌的 Chinchilla-70B 和 PaLM-540B。
上篇文章有介绍了 LLaMA 所采用的 Transformer 结构和细节,与之前所介绍的 Transformer 架构不同的地方包括采用了前置层归一化(Pre-normalization)并使用 RMSNorm 归一化函数(Normalizing Function)、激活函数更换为 SwiGLU,并使用了旋转位置嵌入(RoP),整体 Transformer 架构与 GPT-2 类似,如图 1.1 所示。
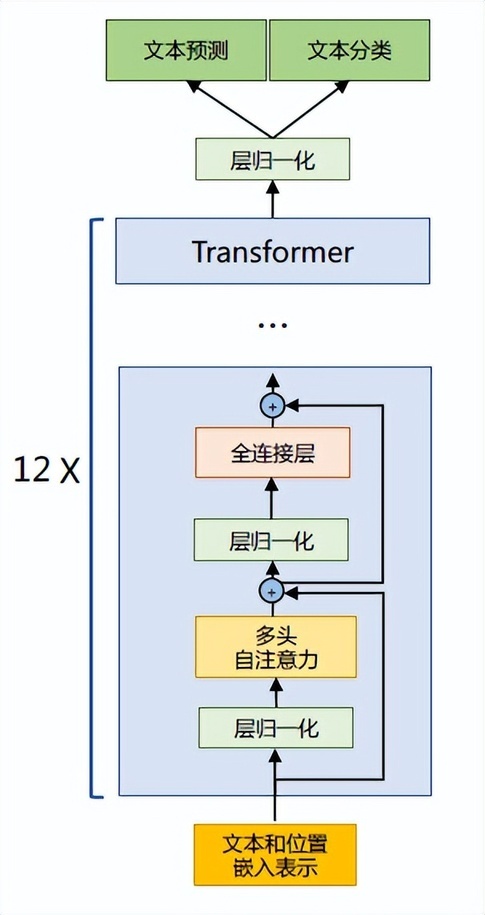
图 1.1 GPT-2 模型结构
关于训练集,其来源都是公开数据集,无任何定制数据集,保证了其工作与开源兼容和可复现。整个训练数据集在 token 化之后大约包含 1.4T 的 token。其中,LLaMA-65B 和 LLaMA-33B 是在 1.4 万亿个 token 上训练的,而最小的模型 LLaMA-7B 是在 1 万亿个 token 上训练的。LLaMA 优势在于其只使用公开可用的数据,这可以保证论文的工作与开源兼容和可复现。之前的大模型要么使用了不公开的数据集去训练从而达到了 state-of-the-art,如 Chinchilla、PaLM 或 GPT-3;要么使用了公开数据集,但模型效果不是最佳无法和 PaLM-62B 或 Chinchilla 相竞争,如 OPT、GPT-NeoX、BLOOM 和 GLM。
和 GPT 系列一样,LLaMA 模型也是 Decoder-only 架构,但结合前人的工作做了一些改进,比如:
Pre-normalization [GPT3]. 为了提高训练稳定性,LLaMA 对每个 transformer 子层的输入进行归一化,使用 RMSNorm 归一化函数,Pre-normalization 由 Zhang 和 Sennrich(2019)引入。
SwiGLU 激活函数 [PaLM]. 将 ReLU 非线性替换为 SwiGLU 激活函数,且使用 2/3*4D 而不是 PaLM 论文中的 4d,SwiGLU 由 Shazeer(2020)引入以提高性能。
Rotary Embeddings [GPTNeo]. 模型的输入不再使用 positional embeddings,而是在网络的每一层添加了 positional embeddings (RoPE),RoPE 方法由 Su 等人(2021)引入。
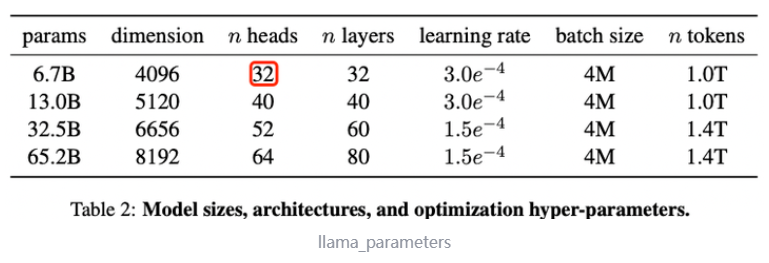
不同模型的超参数详细信息在表 2 中给出,具体可以去看看我上篇文章
具体怎么在华为云的 ModelArts 上玩转 LLAMA 开源大模型呢?
前期准备:
1.登录华为云官方账号:

点击右上角“控制台”,搜索栏输入“ModelArts”
点击“AI Gallery“,选择“北京四”区域
点击"资产集市--Notebook",输入“Mindformers 应用之 LLaMA_7B 推理应用”
点击“Run in ModelArts”,进入
1. 安装 MindFormers 开发套件
编译代码
2.下载 LLaMA 模型和 tokenizer
3.推理-使用 pipeline 接口开启快速推理
- 当我输入提示词:
通过 LLaMA_7B 模型推理可以快速输出:
赶紧来点击试一试,体验下自己写代码调用LLAMA_7B开源大模型的魅力吧!!
版权声明: 本文为 InfoQ 作者【华为云开发者联盟】的原创文章。
原文链接:【http://xie.infoq.cn/article/1b3c871583e3452deade8d918】。文章转载请联系作者。

提供全面深入的云计算技术干货 2020-07-14 加入
生于云,长于云,让开发者成为决定性力量









评论