
构建知识图谱:从技术到实战的完整指南
一、概述
知识图谱,作为人工智能和语义网技术的重要组成部分,其核心在于将现实世界的对象和概念以及它们之间的多种关系以图形的方式组织起来。它不仅仅是一种数据结构,更是一种知识的表达和存储方式,能够为机器学习提供丰富、结构化的背景知识,从而提升算法的理解和推理能力。
在人工智能领域,知识图谱的重要性不言而喻。它提供了一种机器可读的知识表达方式,使计算机能够更好地理解和处理复杂的人类语言和现实世界的关系。通过构建知识图谱,人工智能系统可以更有效地进行知识的整合、推理和查询,从而在众多应用领域发挥重要作用。
具体到应用场景,知识图谱被广泛应用于搜索引擎优化、智能问答系统、推荐系统、自然语言处理等领域。例如,在搜索引擎中,通过知识图谱可以更精确地理解用户的查询意图和上下文,提供更相关和丰富的搜索结果。在智能问答系统中,知识图谱使得机器能够理解和回答更复杂的问题,实现更准确的信息检索和知识发现。
此外,知识图谱还在医疗健康、金融分析、风险管理等领域展现出巨大潜力。在医疗领域,利用知识图谱可以整合和分析大量的医疗数据,为疾病诊断和药物研发提供支持。在金融领域,则可以通过知识图谱对市场趋势、风险因素进行更深入的分析和预测。
总的来说,知识图谱作为连接数据、知识和智能的桥梁,其在人工智能的各个领域都扮演着至关重要的角色。随着技术的不断进步和应用领域的拓展,知识图谱将在智能化社会中发挥越来越重要的作用。
二、知识图谱的基础理论
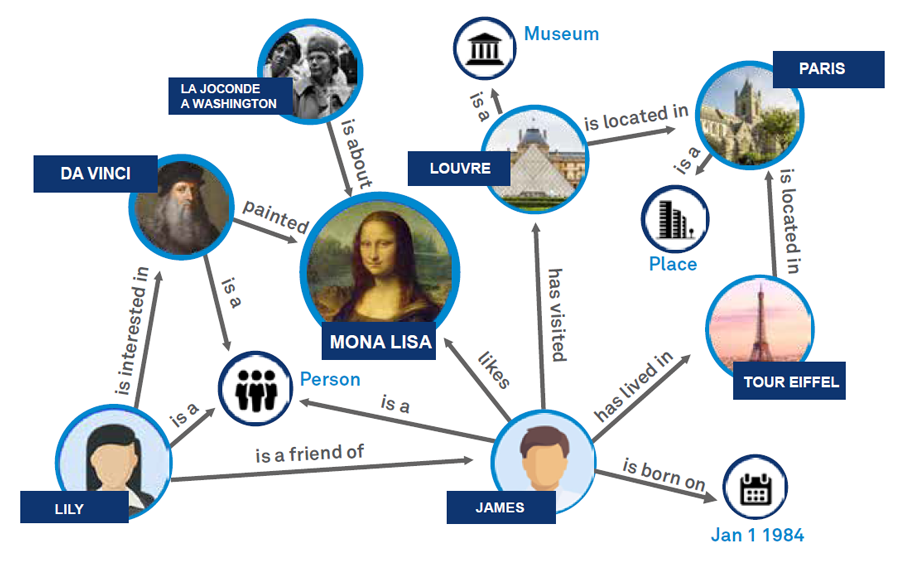
定义与分类
知识图谱是一种通过图形结构表达知识的方法,它通过节点(实体)和边(关系)来表示和存储现实世界中的各种对象及其相互联系。这些实体和关系构成了一个复杂的网络,使得知识的存储不再是孤立的,而是相互关联和支持的。
知识图谱根据其内容和应用领域可以分为多种类型。例如,通用知识图谱旨在覆盖广泛的领域知识,如 Google 的 Knowledge Graph;而领域知识图谱则专注于特定领域,如医疗、金融等。此外,根据构建方法的不同,知识图谱还可以分为基于规则的、基于统计的和混合型知识图谱。
核心组成
知识图谱的核心组成元素包括实体、关系和属性。实体是知识图谱中的基本单位,代表现实世界中的对象,如人、地点、组织等。关系则描述了实体之间的各种联系,例如“属于”、“位于”等。属性是对实体的具体描述,如年龄、位置等。这些元素共同构成了知识图谱的骨架,使得知识的组织和检索变得更加高效和精确。
历史与发展
知识图谱的概念最早可以追溯到语义网和链接数据的概念。早期的语义网关注于如何使网络上的数据更加机器可读,而链接数据则强调了数据之间的关联。知识图谱的出现是对这些理念的进一步发展和实践应用,它通过更加高效的数据结构和技术,使得知识的表示、存储和检索更加高效和智能。
随着人工智能和大数据技术的发展,知识图谱在自然语言处理、机器学习等领域得到了广泛应用。例如,知识图谱在提升搜索引擎的智能化、优化推荐系统的准确性等方面发挥了重要作用。此外,随着技术的不断进步,知识图谱的构建和应用也在不断地演变和优化,包括利用深度学习技术进行知识提取和图谱构建,以及在更多领域的应用拓展。
三、知识获取与预处理

数据源选择
知识图谱构建的首要步骤是确定和获取数据源。数据源的选择直接影响知识图谱的质量和应用范围。通常,数据源可以分为两大类:公开数据集和私有数据。公开数据集,如 Wikipedia、Freebase、DBpedia 等,提供了丰富的通用知识,适用于构建通用知识图谱。而私有数据,如企业内部数据库、专业期刊等,则更适用于构建特定领域的知识图谱。
选择数据源时,应考虑数据的可靠性、相关性、完整性和更新频率。可靠性保证了数据的准确性,相关性和完整性直接影响知识图谱的应用价值,而更新频率则关系到知识图谱的时效性。在实践中,通常需要结合多个数据源,以获取更全面和深入的知识覆盖。
数据清洗
获取数据后,下一步是数据清洗。这一过程涉及从原始数据中移除错误、重复或不完整的信息。数据清洗的方法包括去噪声、数据规范化、缺失值处理等。去噪声是移除数据集中的错误和无关数据,例如,去除格式错误的记录或非相关领域的信息。数据规范化涉及将数据转换为一致的格式,如统一日期格式、货币单位等。对于缺失值,可以采用插值、预测或删除不完整记录的方法处理。
数据清洗不仅提高了数据的质量,还能增强后续处理的效率和准确性。因此,这一步骤在知识图谱构建中至关重要。
实体识别
实体识别是指从文本中识别出知识图谱中的实体,这是构建知识图谱的核心步骤之一。实体识别通常依赖于自然语言处理(NLP)技术,特别是命名实体识别(NER)。NER 技术能够从非结构化的文本中识别出具有特定意义的片段,如人名、地名、机构名等。
实体识别的方法多种多样,包括基于规则的方法、统计模型以及近年来兴起的基于深度学习的方法。基于规则的方法依赖于预定义的规则来识别实体,适用于结构化程度较高的领域。统计模型,如隐马尔可夫模型(HMM)、条件随机场(CRF)等,通过学习样本数据中的统计特征来识别实体。而基于深度学习的方法,如使用长短时记忆网络(LSTM)或 BERT 等预训练模型,能够更有效地处理语言的复杂性和多样性,提高识别的准确率和鲁棒性。
实体识别不仅需要高准确性,还要考虑到速度和可扩展性,特别是在处理大规模数据集时。因此,选择合适的实体识别技术和优化算法是至关重要的。
四、知识表示方法
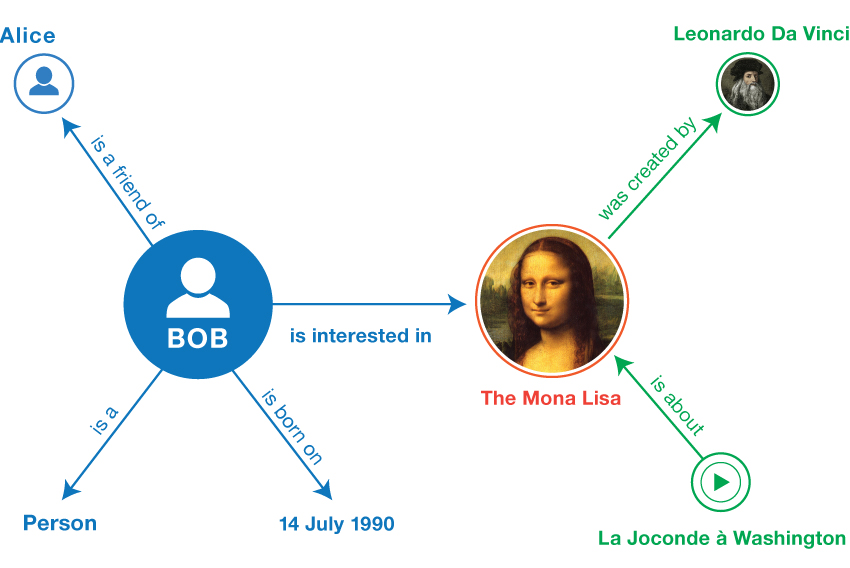
知识表示是知识图谱构建中的核心环节,它涉及将现实世界的复杂信息和关系转化为计算机可理解和处理的格式。有效的知识表示不仅有助于提高知识图谱的查询效率,还能加强知识的推理能力,是实现知识图谱功能的关键。
知识表示模型
知识表示的首要任务是选择合适的模型。当前主流的知识表示模型包括资源描述框架(RDF)、Web 本体语言(OWL)和属性图模型。
RDF
RDF 是一种将信息表示为“主体-谓词-宾语”三元组的模型,它使得知识的表示形式既灵活又标准化。在 RDF 中,每个实体和关系都被赋予一个唯一的 URI(统一资源标识符),以确保其全球唯一性和可互操作性。RDF 的优势在于其简单性和扩展性,但它在表达复杂关系和属性方面存在局限。
OWL
OWL 是基于 RDF 的一种更为复杂和强大的知识表示语言。它支持更丰富的数据类型和关系,包括类、属性、个体等,并能表达复杂的逻辑关系,如等价类、属性限制等。OWL 的优势在于其表达能力和逻辑推理能力,适用于构建复杂的领域知识图谱。
属性图模型
属性图模型通过图结构来表示知识,其中节点代表实体,边代表关系,节点和边都可以附带属性。这种模型直观且易于实现,适用于大规模的图数据处理。它在图数据库中得到了广泛应用,如 Neo4j、ArangoDB 等。
本体构建
本体是知识图谱中用来描述特定领域知识和概念的一组术语和定义。本体的构建是知识图谱构建的重要部分,它定义了知识图谱中的实体类别、属性和关系类型。
本体构建的关键在于准确地把握和表达领域知识。这通常需要领域专家的参与,以确保本体的准确性和全面性。在实际操作中,可以使用本体编辑工具如 Protégé来创建和管理本体,同时结合 NLP 技术自动化提取和维护本体结构。
关系提取与表示
关系提取是指从原始数据中识别出实体之间的关系,并将其加入到知识图谱中。这一步骤通常依赖于文本分析和数据挖掘技术。关系提取的方法包括基于规则的方法、机器学习方法和深度学习方法。
关系的表示要考虑到其多样性和复杂性。在简单的情况下,关系可以被直接表示为实体之间的连接。但在复杂情况下,关系可能涉及多个实体和属性,甚至是关系的层次和类型。在这种情况下,需要更复杂的数据结构和算法来准确表示关系。
五、知识图谱构建技术
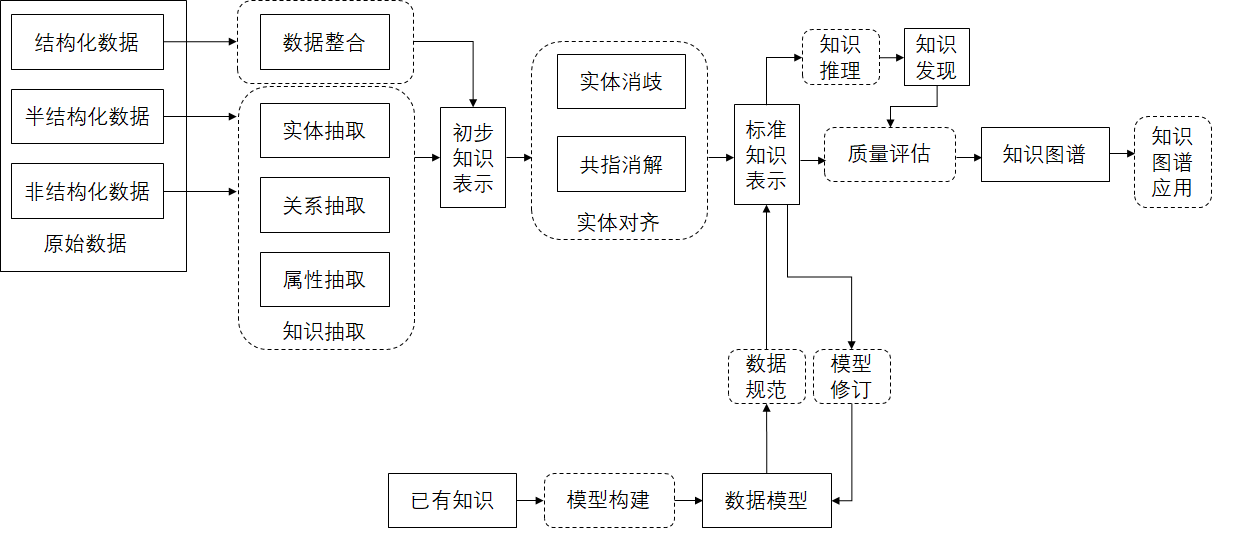
构建知识图谱是一个复杂的过程,涉及数据处理、知识提取、存储管理等多个阶段。本节将详细探讨知识图谱构建的关键技术,并提供具体的代码示例。
图数据库选择
选择合适的图数据库是构建知识图谱的首要步骤。图数据库专为处理图形数据而设计,提供高效的节点、边查询和存储能力。常见的图数据库有 Neo4j、ArangoDB 等。
Neo4j
Neo4j 是一个高性能的 NoSQL 图形数据库,支持 Cypher 查询语言,适合于处理复杂的关系数据。它的优势在于强大的关系处理能力和良好的社区支持。
ArangoDB
ArangoDB 是一个多模型数据库,支持文档、键值及图形数据。它在灵活性和扩展性方面表现出色,适用于多种类型的数据存储需求。
构建流程
构建知识图谱的过程大致可分为数据预处理、实体关系识别、图数据库存储和优化几个阶段。
数据预处理
数据预处理包括数据清洗、实体识别等步骤,目的是将原始数据转换为适合构建知识图谱的格式。
实体关系识别
实体关系识别是从清洗后的数据中提取实体和关系。这里以 Python 和 PyTorch 实现一个简单的命名实体识别模型为例。
图数据库存储
将提取的实体和关系存储到图数据库中。以 Neo4j 为例,展示如何使用 Cypher 语言存储数据。
优化和索引
为提高查询效率,可以在图数据库中创建索引。
深度学习在构建中的应用
深度学习技术在知识图谱构建中主要用于实体识别、关系提取和知识融合。以下展示一个使用深度学习进行关系提取的示例。
在这个模型中,我们使用 LSTM 网络从文本数据中提取特征,并通过全连接层预测实体间的关系类型。
文章转载自:techlead_krischang

还未添加个人签名 2023-06-19 加入
还未添加个人简介






评论