
CUDA 驱动深度学习发展 - 技术全解与实战
全面介绍 CUDA 与 pytorch cuda 实战

一、CUDA:定义与演进
CUDA(Compute Unified Device Architecture)是由 NVIDIA 开发的一个并行计算平台和应用编程接口(API)模型。它允许开发者使用 NVIDIA 的 GPU 进行高效的并行计算,从而加速计算密集型任务。在这一节中,我们将详细探讨 CUDA 的定义和其演进过程,重点关注其关键的技术更新和里程碑。
CUDA 的定义
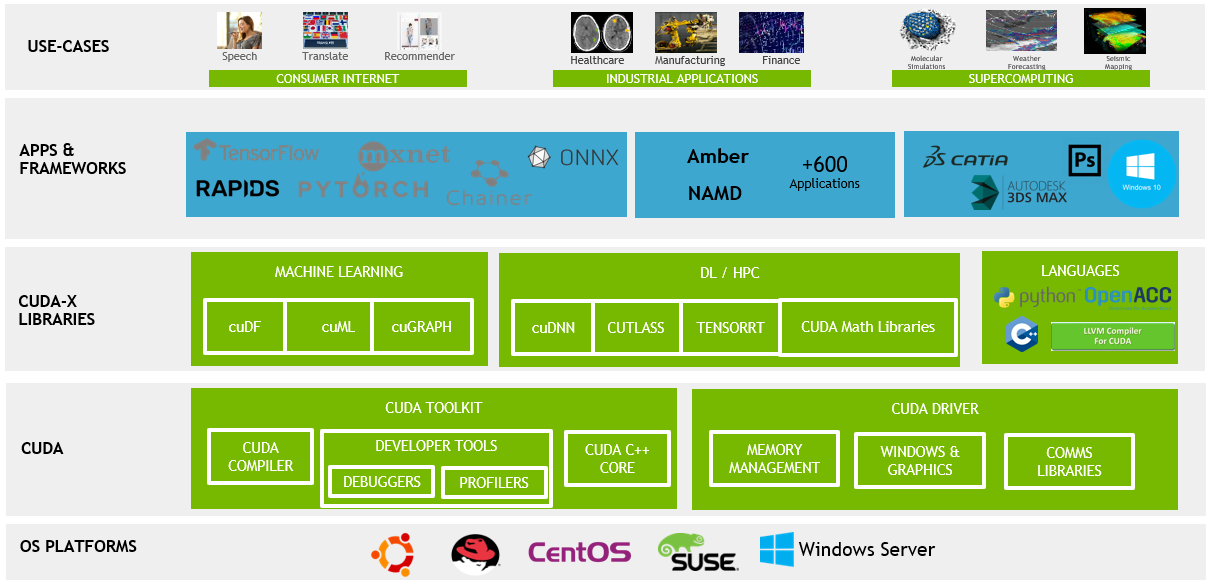
CUDA 是一种允许软件开发者和软件工程师直接访问虚拟指令集和并行计算元素的平台和编程模型。它包括 CUDA 指令集架构(ISA)和并行计算引擎在 GPU 上的实现。CUDA 平台是为了利用 GPU 的强大计算能力而设计,特别适合处理可以并行化的大规模数据计算任务。
CUDA 的演进历程
CUDA 的诞生
2006 年:CUDA 的初现 NVIDIA 在 2006 年发布了 CUDA,这标志着 GPU 计算的一个重大突破。在这之前,GPU 主要被用于图形渲染。
CUDA 的早期版本
CUDA 1.0(2007 年)这是 CUDA 的首个公开可用版本,为开发者提供了一套全新的工具和 API,用于编写 GPU 加速程序。
CUDA 2.0(2008 年)引入了对双精度浮点运算的支持,这对科学计算尤为重要。
CUDA 的持续发展
CUDA 3.0(2010 年)和 CUDA 4.0(2011 年)引入了多项改进,包括对更多 GPU 架构的支持和更高效的内存管理。CUDA 4.0 特别强调了对多 GPU 系统的支持,允许更加灵活的数据共享和任务分配。
CUDA 的成熟期
CUDA 5.0(2012 年)到 CUDA 8.0(2016 年)这一时期 CUDA 的更新聚焦于提高性能、增强易用性和扩展其编程模型。引入了动态并行性,允许 GPU 线程自动启动新的核函数,极大地增强了程序的灵活性和并行处理能力。
CUDA 的现代版本
CUDA 9.0(2017 年)到 CUDA 11.0(2020 年)这些版本继续推动 CUDA 的性能和功能边界。加入了对最新 GPU 架构的支持,如 Volta 和 Ampere 架构,以及改进的编译器和更丰富的库函数。CUDA 11 特别重视对大规模数据集和 AI 模型的支持,以及增强的异构计算能力。
每个 CUDA 版本的发布都是对 NVIDIA 在并行计算领域技术革新的体现。从早期的基础设施搭建到后来的性能优化和功能扩展,CUDA 的发展历程展示了 GPU 计算技术的成熟和深入应用。在深度学习和高性能计算领域,CUDA 已成为一个不可或缺的工具,它不断推动着计算极限的扩展。
通过对 CUDA 定义的理解和其演进历程的回顾,我们可以清楚地看到 CUDA 如何从一个初步的概念发展成为今天广泛应用的高性能计算平台。每一次更新都反映了市场需求的变化和技术的进步,使 CUDA 成为了处理并行计算任务的首选工具。
二、CUDA 与传统 CPU 计算的对比
在深入理解 CUDA 的价值之前,将其与传统的 CPU 计算进行比较是非常有帮助的。这一章节旨在详细探讨 GPU(由 CUDA 驱动)与 CPU 在架构、性能和应用场景上的主要差异,以及这些差异如何影响它们在不同计算任务中的表现。
架构差异
CPU:多功能性与复杂指令集
设计理念:CPU 设计注重通用性和灵活性,适合处理复杂的、串行的计算任务。
核心结构:CPU 通常包含较少的核心,但每个核心能够处理复杂任务和多任务并发。
GPU:并行性能优化
设计理念:GPU 设计重点在于处理大量的并行任务,适合执行重复且简单的操作。
核心结构:GPU 包含成百上千的小核心,每个核心专注于执行单一任务,但在并行处理大量数据时表现卓越。
性能对比
处理速度
CPU:在执行逻辑复杂、依赖于单线程性能的任务时,CPU 通常表现更优。
GPU:GPU 在处理可以并行化的大规模数据时,如图像处理、科学计算,表现出远超 CPU 的处理速度。
能效比
CPU:在单线程任务中,CPU 提供更高的能效比。
GPU:当任务可以并行化时,GPU 在能效比上通常更有优势,尤其是在大规模计算任务中。
应用场景
CPU 的优势场景
复杂逻辑处理:适合处理需要复杂决策树和分支预测的任务,如数据库查询、服务器应用等。
单线程性能要求高的任务:在需要强大单线程性能的应用中,如某些类型的游戏或应用程序。
GPU 的优势场景
数据并行处理:在需要同时处理大量数据的场景下,如深度学习、大规模图像或视频处理。
高吞吐量计算任务:适用于需要高吞吐量计算的应用,如科学模拟、天气预测等。
了解 CPU 和 GPU 的这些关键差异,可以帮助开发者更好地决定何时使用 CPU,何时又应转向 GPU 加速。在现代计算领域,结合 CPU 和 GPU 的优势,实现异构计算,已成为提高应用性能的重要策略。CUDA 的出现使得原本只能由 CPU 处理的复杂任务现在可以借助 GPU 的强大并行处理能力得到加速。
总体来说,CPU 与 GPU(CUDA)在架构和性能上的差异决定了它们在不同计算任务中的适用性。CPU 更适合处理复杂的、依赖于单线程性能的任务,而 GPU 则在处理大量并行数据时表现出色。
三、CUDA 在深度学习中的应用
深度学习的迅速发展与 CUDA 技术的应用密不可分。这一章节将探讨为什么 CUDA 特别适合于深度学习应用,以及它在此领域中的主要应用场景。
CUDA 与深度学习:为何完美契合
并行处理能力
数据并行性:深度学习模型,特别是神经网络,需要处理大量数据。CUDA 提供的并行处理能力使得这些计算可以同时进行,大幅提高效率。
矩阵运算加速:神经网络的训练涉及大量的矩阵运算(如矩阵乘法)。GPU 的并行架构非常适合这种类型的计算。
高吞吐量
快速处理大型数据集:在深度学习中处理大型数据集时,GPU 能够提供远高于 CPU 的吞吐量,加快模型训练和推理过程。
动态资源分配
灵活的资源管理:CUDA 允许动态分配和管理 GPU 资源,使得深度学习模型训练更为高效。
深度学习中的 CUDA 应用场景
模型训练
加速训练过程:在训练阶段,CUDA 可以显著减少模型对数据的训练时间,尤其是在大规模神经网络和复杂数据集的情况下。
支持大型模型:CUDA 使得训练大型模型成为可能,因为它能够有效处理和存储巨大的网络权重和数据集。
模型推理
实时数据处理:在推理阶段,CUDA 加速了数据的处理速度,使得模型能够快速响应,适用于需要实时反馈的应用,如自动驾驶车辆的视觉系统。
高效资源利用:在边缘计算设备上,CUDA 可以提供高效的计算,使得在资源受限的环境下进行复杂的深度学习推理成为可能。
数据预处理
加速数据加载和转换:在准备训练数据时,CUDA 可以用于快速加载和转换大量的输入数据,如图像或视频内容的预处理。
研究与开发
实验和原型快速迭代:CUDA 的高效计算能力使研究人员和开发者能够快速测试新的模型架构和训练策略,加速研究和产品开发的进程。
CUDA 在深度学习中的应用不仅加速了模型的训练和推理过程,而且推动了整个领域的发展。它使得更复杂、更精确的模型成为可能,同时降低了处理大规模数据集所需的时间和资源。此外,CUDA 的普及也促进了深度学习技术的民主化,使得更多的研究者和开发者能够访问到高效的计算资源。
总的来说,CUDA 在深度学习中的应用极大地加速了模型的训练和推理过程,使得处理复杂和大规模数据集成为可能。
四、CUDA 编程实例
在本章中,我们将通过一个具体的 CUDA 编程实例来展示如何在 PyTorch 环境中利用 CUDA 进行高效的并行计算。这个实例将聚焦于深度学习中的一个常见任务:矩阵乘法。我们将展示如何使用 PyTorch 和 CUDA 来加速这一计算密集型操作,并提供深入的技术洞见和细节。
选择矩阵乘法作为示例
矩阵乘法是深度学习和科学计算中常见的计算任务,它非常适合并行化处理。在 GPU 上执行矩阵乘法可以显著加速计算过程,是理解 CUDA 加速的理想案例。
环境准备
在开始之前,确保你的环境中安装了 PyTorch,并且支持 CUDA。你可以通过以下命令进行检查:
这段代码会输出 PyTorch 的版本并检查 CUDA 是否可用。
示例:加速矩阵乘法
以下是一个使用 PyTorch 进行矩阵乘法的示例,我们将比较 CPU 和 GPU(CUDA)上的执行时间。
准备数据
首先,我们创建两个大型随机矩阵:
在 CPU 上进行矩阵乘法
接下来,我们在 CPU 上执行矩阵乘法,并测量时间:
在 GPU 上进行矩阵乘法
现在,我们将相同的操作转移到 GPU 上,并比较时间:
在这个示例中,你会注意到使用 GPU 进行矩阵乘法通常比 CPU 快得多。这是因为 GPU 可以同时处理大量的运算任务,而 CPU 在执行这些任务时则是顺序的。
深入理解
数据传输的重要性
在使用 CUDA 进行计算时,数据传输是一个重要的考虑因素。在我们的例子中,我们首先将数据从 CPU 内存传输到 GPU 内存。这一过程虽然有一定的时间开销,但对于大规模的计算任务来说,这种开销是值得的。
并行处理的潜力
GPU 的并行处理能力使得它在处理类似矩阵乘法这样的操作时极为高效。在深度学习中,这种能力可以被用来加速网络的训练和推理过程。
优化策略
为了最大化 GPU 的使用效率,合理的优化策略包括精细控制线程布局、合理使用共享内存等。在更复杂的应用中,这些优化可以带来显著的性能提升。
五、PyTorch CUDA 深度学习案例实战
在本章节中,我们将通过一个实际的深度学习项目来展示如何在 PyTorch 中结合使用 CUDA。我们选择了一个经典的深度学习任务——图像分类,使用 CIFAR-10 数据集。此案例将详细介绍从数据加载、模型构建、训练到评估的整个流程,并展示如何利用 CUDA 加速这个过程。
环境设置
首先,确保你的环境已经安装了 PyTorch,并支持 CUDA。可以通过以下代码来检查:
如果输出显示 CUDA 可用,则可以继续。
CIFAR-10 数据加载
CIFAR-10 是一个常用的图像分类数据集,包含 10 个类别的 60000 张 32x32 彩色图像。
加载数据集
使用 PyTorch 提供的工具来加载和归一化 CIFAR-10:
构建神经网络
接下来,我们定义一个简单的卷积神经网络(CNN):
CUDA 加速
将网络转移到 CUDA 上:
训练网络
使用 CUDA 加速训练过程:
测试网络
最后,我们在测试集上评估网络性能:
文章转载自:techlead_krischang

还未添加个人签名 2023-06-19 加入
还未添加个人简介






评论