
OpenMLDB 进阶使用攻略和高级特性介绍

本文整理自 OpenMLDB PMC 张浩在 OpenMLDB Meetup No.6 中的分享 ——《OpenMLDB 进阶使用和高级特性介绍》。

大家好,我是 OpenMLDB PMC 成员 张浩。今天我来给大家分享 OpenMLDB 的一些高级特性以及具体实践时的使用方式。

分享内容会覆盖三部分内容:
首先是介绍线上高可用的机制是如何实现的。
接下来是讲解 OpenMLDB 的双机房容灾技术架构。
最后会为大家展示在线引擎中,数据量很大的情况下,我们是如何通过预聚合技术达到性能优化的。
线上高可用机制介绍和实现
线上引擎整体架构
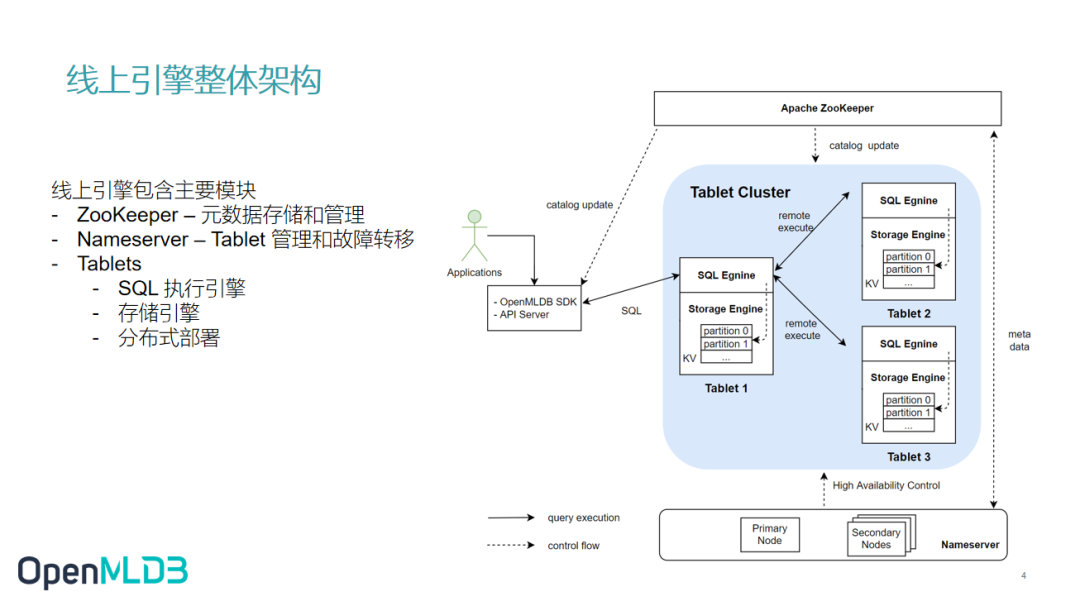
首先让我带大家回顾一下 OpenMLDB 线上引擎的整体架构。
OpenMLDB 线上引擎主要由几部分组成。
第一个模块 ——Zookeeper,负责元信息的存储和管理。
第二个模块 ——Tablet Cluster,由多个节点成的。其中的 Tablets 主要是用于存储数据以及执行 SQL 引擎。
第三个模块 ——Nameserver,主要负责 Tablet 管理和故障迁移。
高可用 - 数据持久化
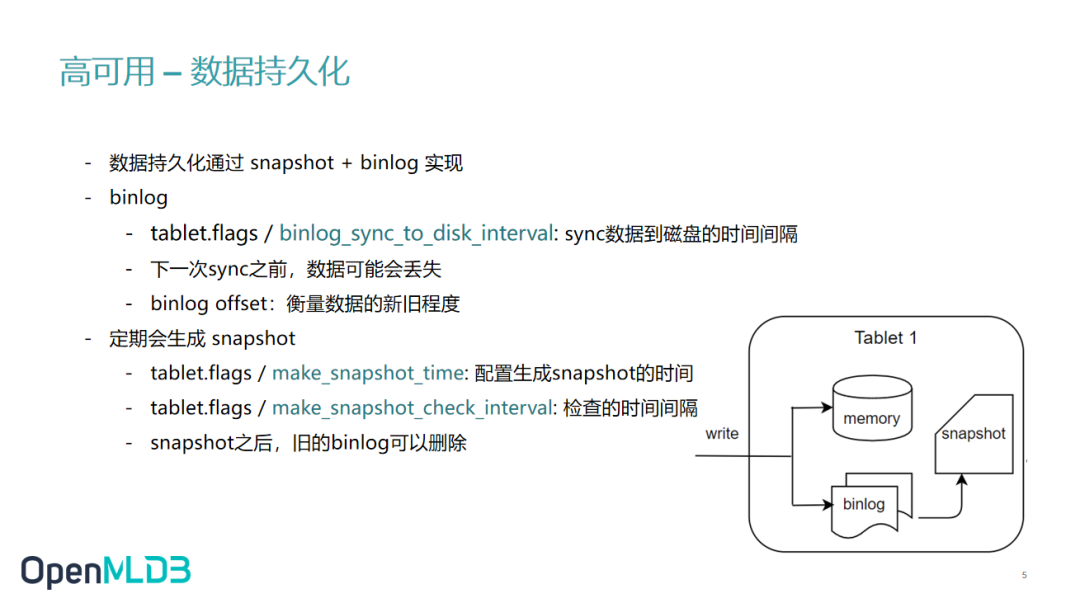
目前,OpenMLDB 提供两种存储模式,一种是基于内存的,一种是基于磁盘的。
在基于内存的存储模式中,我们通过 snapshot 和 binlog 两种方式保证数据的持久化。
binlog 大家可能比较熟悉,一些传统的数据库会通过写 log 的方式使数据持久化。
OpenMLDB 在这里提供了一些参数,方便大家根据使用场景进行调配,包括 binlog 同步到磁盘的间隔。
我们还使用了 binlog offset 的机制。对于某一个表中,binlog offset 是唯一的,所以 offset 会在某些节点挂掉之后用于选主。之后我会介绍这部分的详细内容。
另外一个保持持久化的方式是 OpenMLDB 会定期的生成一次 snapshot。
Snapshot 当于是一个全局内存状态的备份。当 snapshot 生成,就可以删除旧的 binlog,从而节省磁盘的空间。snapshot 的生成参数也可以改动,有需要的用户可以在 tablet.flags 里配置。比如我们可以设定 snapshot 的生成时间,例如在每天凌晨一点生成 snapshot,也可以设置 interval 等等。
所以 snapshot+binlog 可以完整恢复出整个的系统状态。
高可用 - 分片与多副本
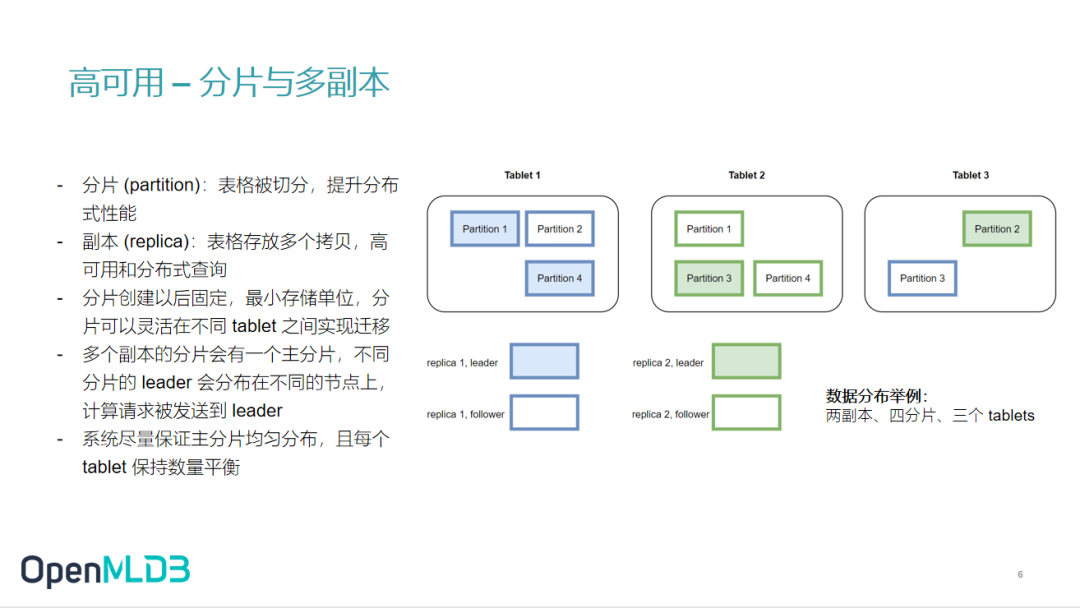
分片是 OpenMLDB 另一个比较重要且通用的技术。为了提升分布式性能,我们会把一个表分成多个 partition,称作分片。分片的数目可以在创建表时进行指定。而 partition 和 partition 之间,大部分是独立的。通过分片,当需要对表进行并行查询时,我们可以落到不同的分片,并行地执行查询任务。
除了在磁盘上设置 snapshot 和 binlog 之外,我们还有一些副本。当我们在创建表时,可以声明此表是单副本,两副本或三副本,这个设计是为了达到高可用。
大家可以看到右侧的示例图中的表设计了两副本、四分片。我们会尽量把分片均匀地分布在不同的 tablet 上面,同时不同的副本也会均匀分布在不同的 tablet 上面。
不管是数据迁移还是数据同步,分片始终是我们的最小单位。不同的 tablet 之间做主从之间进行同步的时候,其实也是以 Partition 的力度去做同步的。
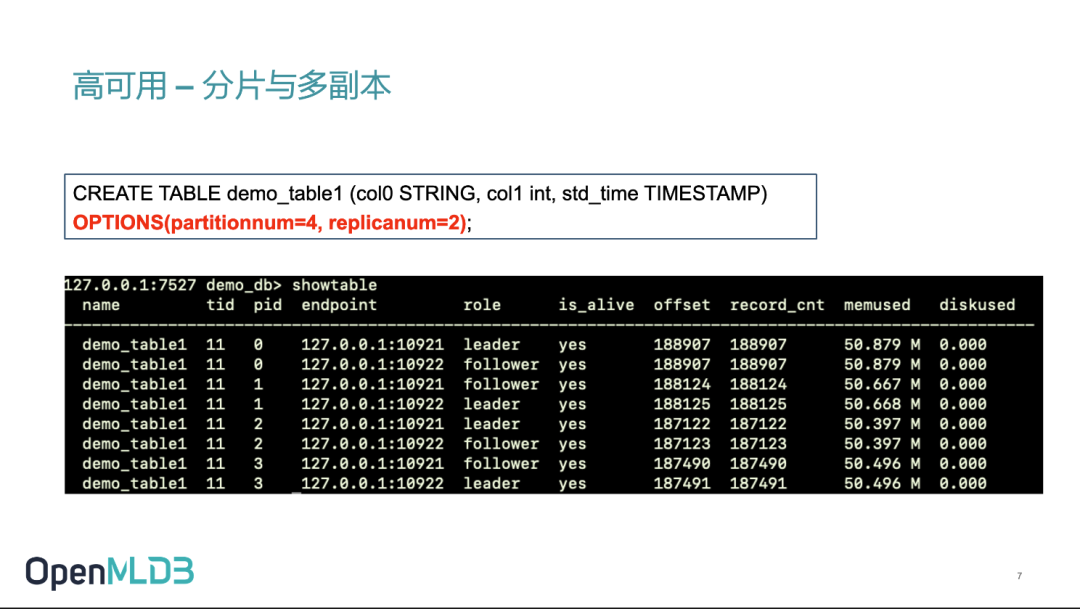
在这里,我们用示例展示一下在 OpenMLDB 里面可以如何进行操作。
大家可能对我们创建表格的 SQL 已经比较熟悉了。观察这个表格的红色部分可以看到,我们在提供了一个 options 的选项,选项中可以声明我们需要的分片个数格式。
可以通过连接 ns client,我们可以查到当前表的状况,就像截图里可以看到我们有创建 4 个 partition,每个 parition 有两个副本。
高可用 - 主从同步
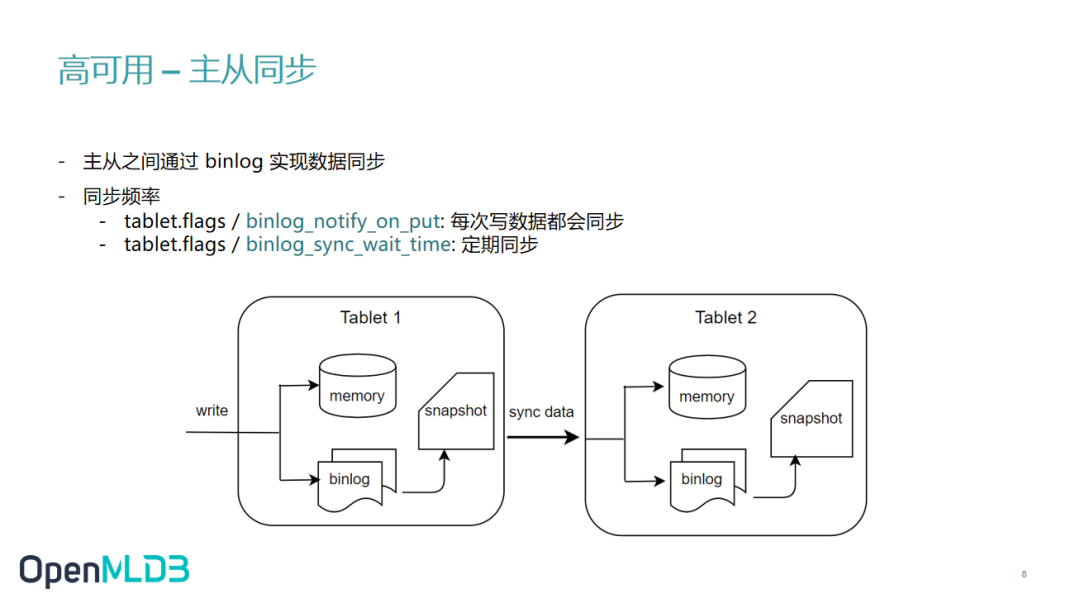
副本之间有一个关键的问题是 —— 如何做到主从同步。
binlog 就可以用来完成主从同步。如图,数据写到 binlog 后会有一个后台线程异步的把数据从 binlog 中读出来然后同步到从节点中。从节点收到同步请求后同样进行写内存和 binlog 操作。Snapshot 可以看作是内存数据的一个镜像,不过出于性能考虑,snapshot 并不是从内存 dump 出来,而是由 binlog 和上一个 snapshot 合并生成。在合并的过程中会删除掉过期的数据。OpenMLDB 会记录主从同步和合并到 snapshot 中的 offset, 如果一个 binlog 文件中的数据全部被同步到从节点并且也合并到了 snapshot 中,这个 binlog 文件就会被后台线程删除。
高可用 - failover
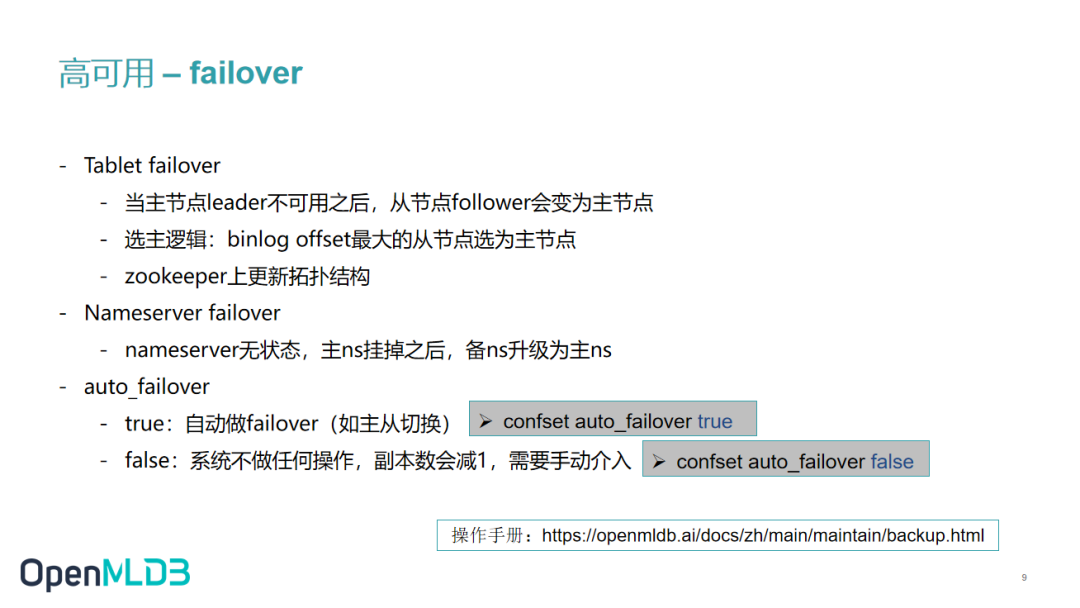
因为我们有多副本,那么如果一个 tablet 挂掉,OpenMLDB 会怎么做呢?
当主节点的主分片不可用时,系统会在从节点的从分片中选择一个成为主节点。刚才我们提到 OpenMLDB 选主的逻辑和其他系统选主逻辑稍有不同。其他系统的大都是通过 Vote 的方式选主,而我们是选择 binlog offset 里最大的节点作为主节点。这主要是为了避免数据丢失的问题,比如某主节点挂掉的话,会造成部分数据的丢失。
针对 nameserver,也存在多个 nameserver 同时 standby 的情况,此时当某主 nameserver 挂掉,其实我们也是通过选择备用 nameserver 直接转为主 nameserver 的方式。nameserver 的 failover 机制比较简单,因为它是无状态的,所以系统可以任意选择一个备用 namesrever 提升为主 namesrever 就可以了。
在真正的实操中,OpenMLDB 有准备好一些配置。我们的高可用 failover 有两种方式使用。
一个是 auto_failover,相当于我们把 failover 交给 OpenMLDB 系统来做。当 OpenMLDB 监测到某些节点挂掉时,它会自动地完成 failover 全流程,然后我们可以通过 confset auto_failover true 来完成配置。
另外一个策略是我们可以把 auto_failover 设为 false。这时候当某一个节点挂掉时,系统不会做任何操作,需要用户手动介入,通过一些运行命令把节点恢复出来。
操作手册:https://openmldb.ai/docs/zh/main/maintain/backup.html
双机房容灾技术架构
上面主要是介绍的是高可用的实现。接下来我将主要介绍 OpenMLDB 双机房容灾的技术架构。
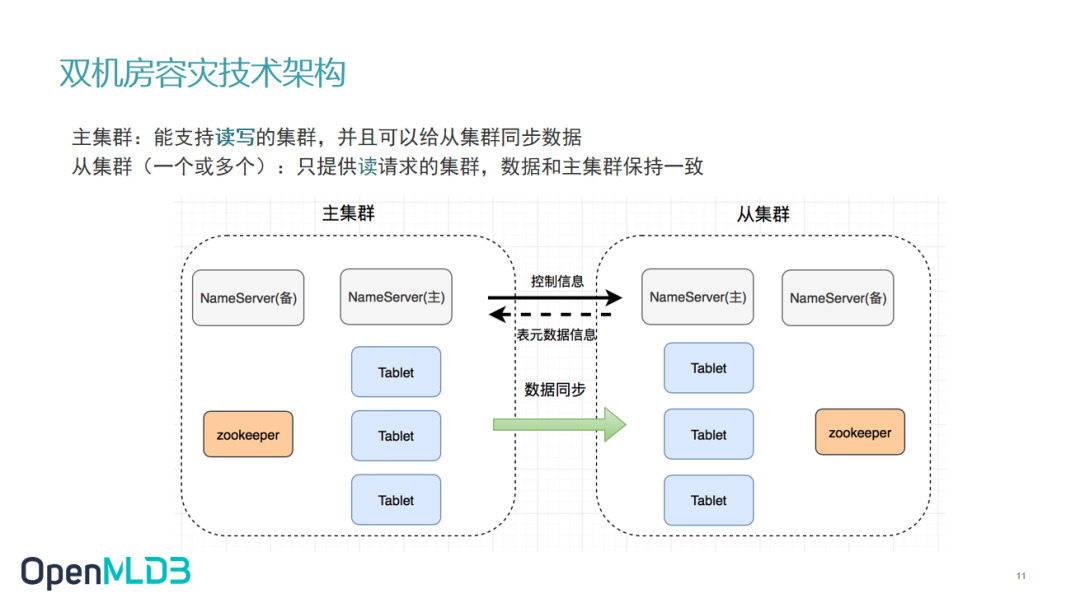
假设我有两个集群,一个主集群,一个从集群。每个集群中,所有 nameserver,tablet,zookeeper 等组件都是完整的。分布在不同机房的集群主要有两个信息需要同步,一个是元信息的同步(比方表的创建分片、增删更改),另外一个数据的同步。
另外一个值得关注的是,根据业务场景的需求我们可以设置多个从集群。从集群只接受读请求,写进请求全都导入到主集群。
双机房架构原理
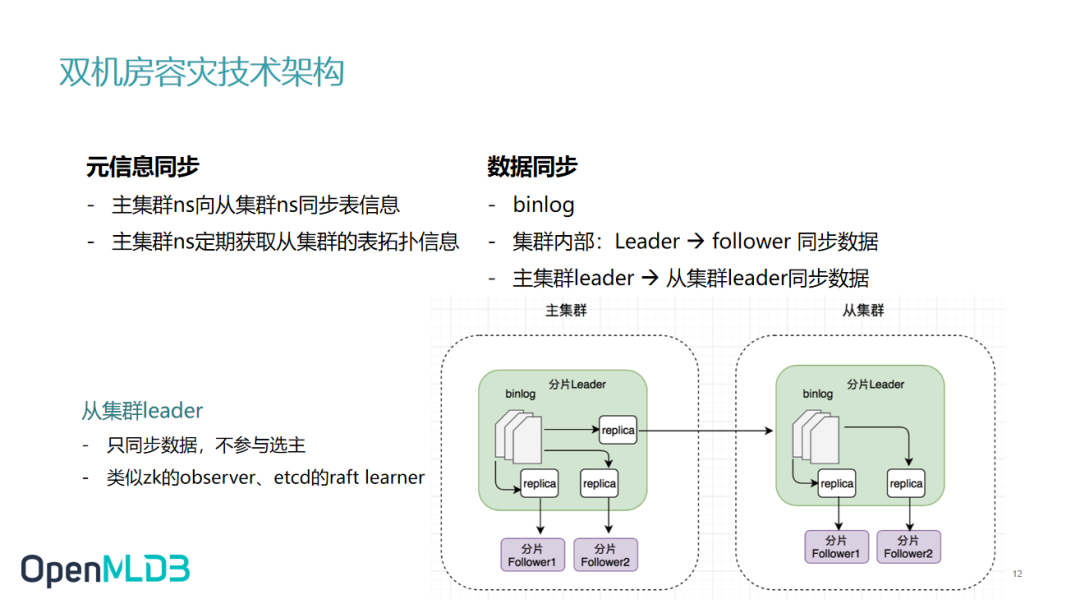
元信息的同步主要通过 nameserver 进行。通过 nameserver,主集群向从集群同步表信息,而从集群更新的拓扑信息会定期同步至主集群。
数据同步和备份之间的同步类似。我们认为从集群分片是主集群分片的备份。所以数据同步大概是分为两个独立的部分,一个是集群内部的同步,另外是一个是集群之间的同步。遵循刚刚所讲的不同分片同步策略,leader 给 follower 同步。
集群之间同步是由主集群的 leader 把收集的数据更新给到从集群的 leader,从集群的 leader 再去把这些数据同步到从集群的 follower 上面,使得我们所有的备份数据都是 in sync 的。
不过,虽然我们的从集群中有一个分片 leader 的概念,但它作为从集群的 leader,不参与选主。这主要是说当我们主集群的 leader 挂掉的时候,从集群的 leader 不参与主集群的选主。
这里面跟一个概念比较相似。zookeeper 有一个 observer 的概念,它只把数据给进行备份,但并不参与选主。同样的,etcd 中我们有个 raft learner 的概念,它也只是对于数据进行一些备份,但不参与就是选主过程。
业界常用架构对比
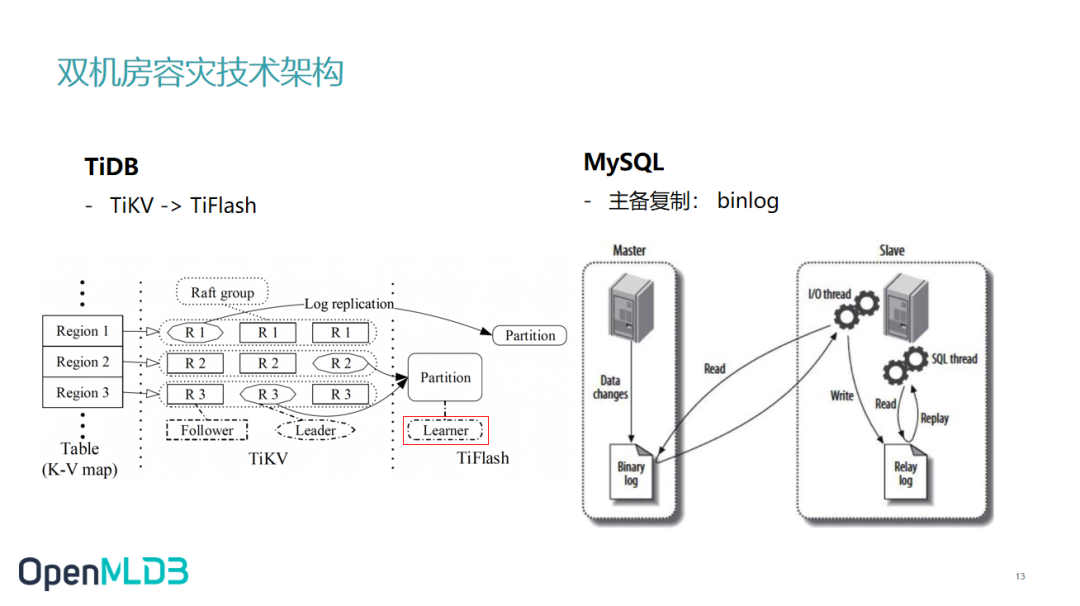
我们在这里列举了两个业界常用的两个架构 TiDB 和 MySQL,看看它们怎么做的。
这两个架构比较相似,TiDB 将数据从 TiKV 传到 TiFlash 也是通过类似方式完成的。TiFlash 有一个 Learner 的概念类似于 OpenMLDB 从集群的 leader。TiKV 会把数据会同步到 learner 上面,然后再由 learner 去做一些数据的同步。
MySQL 的主备复制,跟我们做法也是类似的。它通过一些 binlog,将更新的信息同步到 MySQL 上面。

OpenMLDB 是如何构建双机群的主从备份的呢?
首先我们在主集群里面,连接主集群的 nameserver,然后我们可以通过 addrepcluster 的命令把另外一个集群添加成为从集群。这里我们需要提供从集群的 zookeeper 地址和主从备份双机房的 cluster 名字。如需把双机房关联关系解除,也可以通过 removecluster 的方式实现。
完成上述准备后,集群内部我们可以设成 auto_failover,可以通过 auto_failover 机制保证集群的高可用。而集群之间的 auto_failover 目前还需要用户去判断主集群是否可用,当用户判断主集群不可用时,需要手动提升从集群为主集群,当然提升完成后 OpenMLDB 系统会把读写流量切换到新的主集群上。
当我们挂掉老的主集群又在恢复后重新加入,新的数据依然会通过新集群去同步到原集群。但这整个过程目前还需人工操作。
双机房限制条件

目前的技术方案还存有一些限制条件。
第一,我们双机房是一个集群力度的主从关系,不支持表级别的力度,就是说不支持某一个表的主从关系。
另一个限制是 auto_failover 需要用户做检测加手动切换。
最后还有一个比较通用的问题。当我们做主从切换时,如果不断有写流量进入,可能会造成数据丢失。因为在切换之后,原主集群的数据可能会多于新的主集群,这时候我们还是以新主集群的数据为准,所以部分数据可能会丢失。
预聚合技术原理和性能优化表现
最后一个部分我会主要介绍当在线引擎表数据量很大时,如何通过预聚合技术进行优化。
使用预聚合技术也比较简单的,只要在创建 deploy 的时候添加一个 options 的选项,去声明我们某一个窗口是一个长窗口。例如图中指定 w1 为长窗口,1d 指的是一天的概念,代表预聚合的一个力度。
预聚合原理介绍

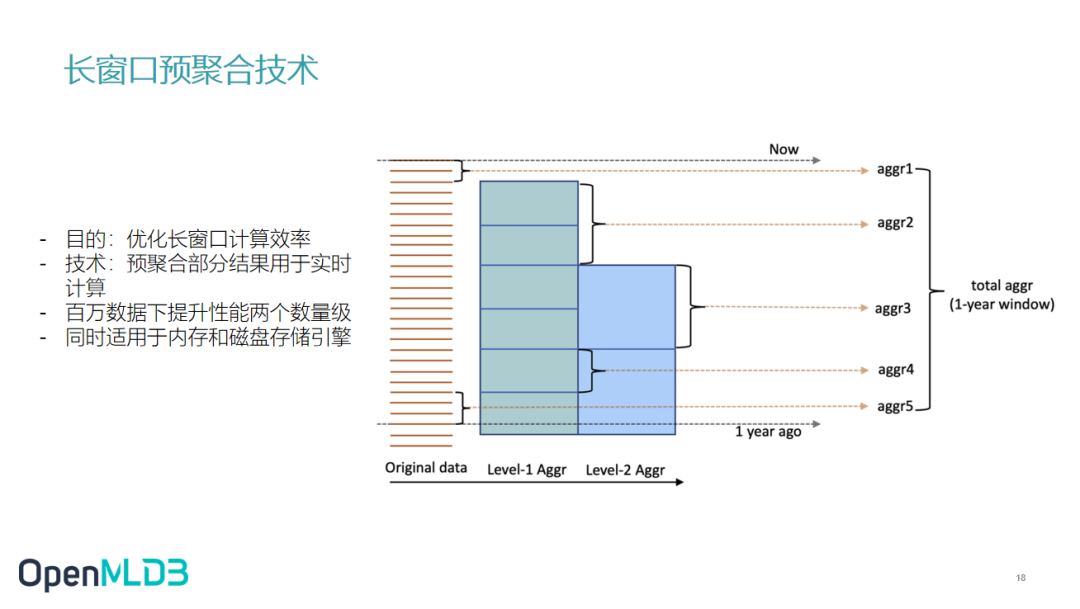
假设最左边为原始数据。声明了某一窗口为长窗口后,我们进行数据插入时,OpenMLDB 就会去做预聚合操作,把原始数据中一天的数据聚合成一条预聚合数据,生成一个预聚合表。但是我们目前实现的是一层预聚合表,之后可能会支持多层。多层预聚合就相当于在第一层的基础上进一步做预聚合。
如果我们需要实时线上计算一年的窗口数据时没有预聚合,则要查询一整年的大量数据,可能造成较大的延迟。当我们有了预聚合之后,就可以将之前的预聚合结果和最新的数据相加,更低延迟地生成最终需要的结果。所以避免了大量数据的计算,使性能提升两个数量级。
预聚合技术也能同时适用于内存和磁盘表。
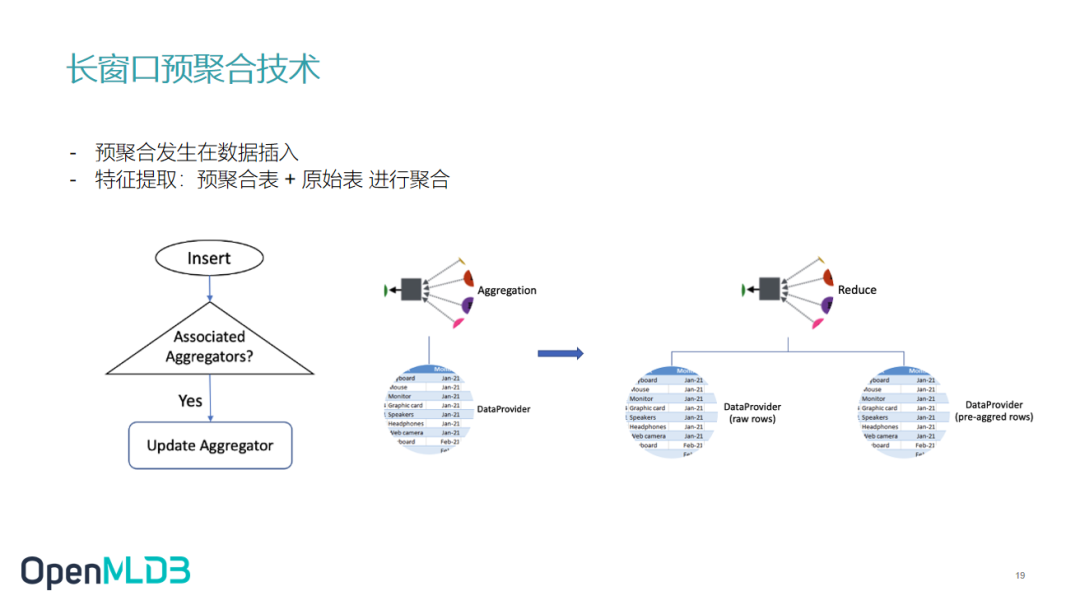
预聚合是在一个数据插入的过程中提前做聚合操作,并把结果更新到预聚合表里面。使用预聚合前,当我们做线上的特征提取时,原始数据完全是从原始表中做聚合。使用预聚合后,我们拥有了两个输入渠道,一个是预聚合表,一个是原始表,OpenMLDB 会先把能用的预聚合数据读取出来,再把缺失的数据读出来,最后做一个 Reduce 操作,节省了我们数据读取及计算的时间。
预聚合测试数据
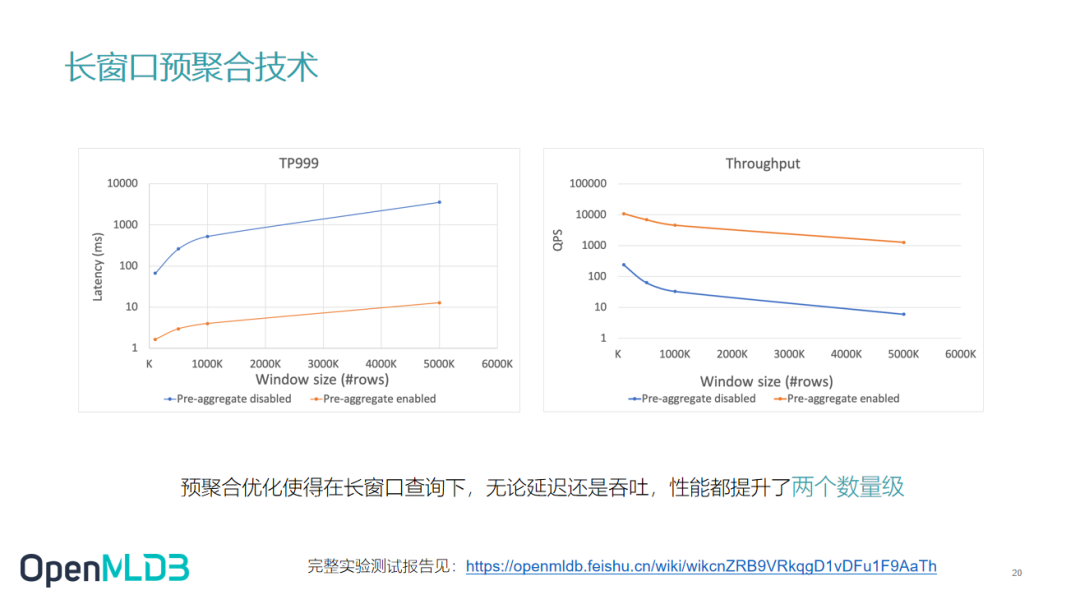
这两张图是预聚合相关的测试数据,使用了预聚合技术的是橙色线,未使用预聚合的是蓝色线。可以对比看出预聚合技术使用后大概得到两个数量级的提升,无论是延迟还是吞吐。
完整实验测试报告见:https://openmldb.feishu.cn/wiki/wikcnZRB9VRkqgD1vDFu1F9AaTh
预聚合使用限制条件

预聚合其实是比较新的一个技术,在使用中会有一定限制条件,比如:
目前只支持一个物理表,不支持包含 Join,Union 的 Selectstmt。
算子我们现在只支持一些通用的常见函数,如 sum, avg, count,min,max 等。
还有一些限制,包括 deploy 的时候,表中不能有数据,*_where 的算子,只能支持内存表以及简单的条件语句。
长窗口使用说明:https://openmldb.ai/docs/zh/v0.6/reference/sql/deployment_manage/DEPLOY_STATEMENT.html

分享就到这里,谢谢大家。
相关链接
✦
OpenMLDB 官网
OpenMLDB github 主页
https://github.com/4paradigm/OpenMLDB
OpenMLDB 微信交流群


AI for every developer,AI for everyone 2021.06.21 加入
还未添加个人简介









评论