
RocketMQ Streams 拓扑构建与数据处理过程

本文作者:倪泽,Apache RocketMQ committer、RSQLDB/RocketMQ Streams Maintainer
01 背景
RocketMQ Streams 1.1.0 版本已于近期发布,相对之前版本有以下改进和优化:
1、API 层面支持泛型,可自定义输入输出数据;
2、去掉冗余逻辑,简化代码,重写拓扑图构建和数据处理过程;
本文章承接上篇:RocketMQ Streams 1.1.0: 轻量级流处理再出发,从实现原理上介绍 RocketMQ Streams 是如何实现流计算拓扑图构建的以及探讨了数据流转过程和流转过程中的状态变化。
02 流处理拓扑构建过程
在使用者书写上述及连表达式时,发生第一次构建,即逻辑节点的添加,前后算子具有父子关系,构建后形成逻辑节点,多个逻辑节点形成链表。
逻辑构建结束后,调用 StreamBuilder#build()方法进行第二次构建,将逻辑节点中可能包含的多个真实节点添加拓扑,形成处理拓扑图。
经过两次两次构建后,处理拓扑已经完整。但是为了区分不同 topic 使用不同拓扑处理,需要在数据来临前的重平衡阶段,创建真实数据处理节点,这是第三次构建。
逻辑构建(第一次构建)
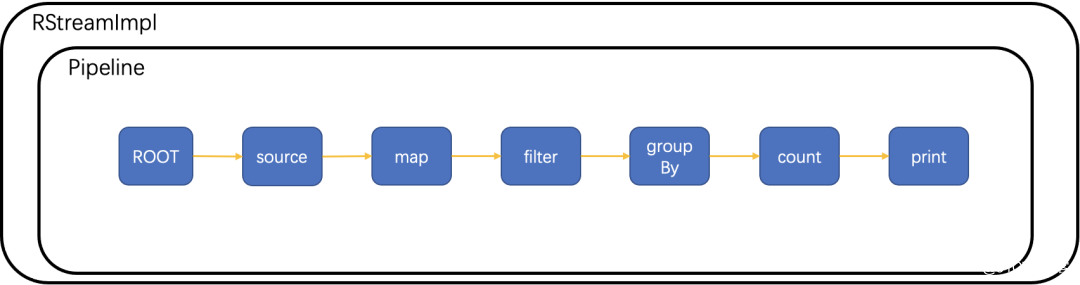
逻辑节点本身不包括实际操作,但是可由逻辑节点继续构建出实际节点,一个逻辑节点可能包含一实际节点,也可能包含多个实际节点,例如 count 逻辑算子不仅仅包含累加这个实际操作,累加前需要对相同 key 的数据路由到同一计算实例上,因此还需要包含 sink、source 两个实际节点,但是这些只会在构建实际节点时体现出来,不会在添加逻辑节点阶段体现。
每个逻辑节点都是 GraphNode 的子类,构建时,将子节点算子加入父节点 child 集合中,将父节点加入子节点 parent 集合中。这个构建过程中使用 Pipeline 均为同一个实例。最终在 Pipeline 中,形成以 root 节点为根节点的链表。
添加逻辑节点逻辑:
可以看到逻辑节点的添加非常通用,实现不同功能的算子,只需要实现算子对应的数据实际处理逻辑即可,如将新增算子形成拓扑图等等后续工作完全不用关心,降低了新算子开发的门槛。
在逻辑节点的构建过程中,有两类比较特殊的算子,一个是实现数据分组的 shuffle 算子,一个是实现双流聚合的 Join 算子。
shuffle 逻辑算子的功能是将含有相同 key 的数据发送到同一个队列中,方便后续算子对相同 key 的数据进行统计。他通常是 keyBy 后面紧跟的算子,例如 keyBy("年级").count(),那么 count 就是一个 shuffle 算子类型。shuffle 逻辑算子包含三个实际处理过程:
将数据按照 Key 的 hash%queueNum 发送到对应队列;
从 RocketMQ 中拉取上述数据到本地;
按照 shuffle 节点中定义的逻辑进行处理,例如累加。
Join 算子的功能是实现双流聚合,将两个数据流聚合成一个。
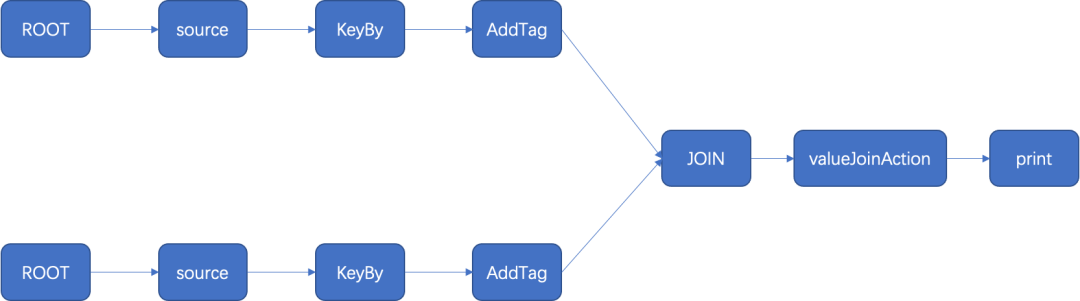
Join 拓扑图
在左流和右流上添加 KeyBy 算子,对左流和右流进行分别过滤;之后在左流和右流上分别添加标签节点,标记此数据是左流还是右流,之后将两个标签节点,指向一个共同的 Join 节点,数据在此完成汇聚,按照使用者给定的 ValueJoinAction 节点处理。
Join 使用方式:
Join 实现伪代码:
实际构建(第二次构建)
构建逻辑节点完毕后,从 ROOT 节点开始遍历,调用 GraphNode 逻辑节点 addRealNode 方法,构建真实节点工厂类。
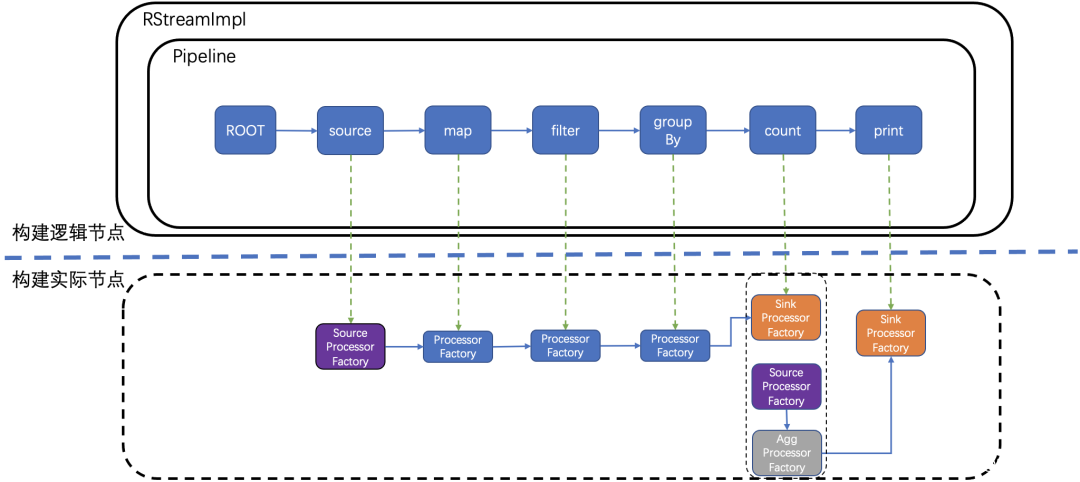
在第二次构建实际节点过程中,会对逻辑节点进行拆解,对于大多数逻辑节点,只需要构建一个实际节点,但是对于某些特殊的逻辑节点需要构建多个实际节点才能与之对应,例如 shuffle 类型逻辑节点,他需要包含三个实际节点:发送数据节点、消费数据节点、处理数据节点。shuffle 类型逻辑节点父节点必须是 GroupBy,例如上图所示的 count 是 shuffle 节点,Window 节点也可以是逻辑节点。
第二次构建并不会直接生成处理数据的 Processor,而是产生 ProcessorFactory 对象。为什么不生成直接能处理数据的 Processor 对象呢?因为一个 RocketMQ Streams 实例需要同时拉取不同队列进行流计算,为了能将不同队列的流计算过程区别开,针对每个队列会由独立的 Processor 实例进行处理,因此第二次构建仅仅构建出 ProcessorFactory,在重平衡确定流处理实例要拉去哪些队列后,再由 ProcessorFactory 实例化 Processor。
第三次构建
客户程序依赖 RocketMQ Streams 获得流计算能力,因此客户程序本质上是就是一个 RocketMQ Client(见方案架构图)。在 RocketMQ Client 发生重平衡时,会将 RocketMQ Server 所包含的队列在客户端中重新分配,第三次构建,也就是由 ProcessorFactory 实例化 Processor,就发生在重平衡发生后,拉取数据前。第三次真实的构建出了处理数据的 Processor,并将子节点 Processor 添加进入父节点 Processor 中。
03 数据处理过程
状态恢复
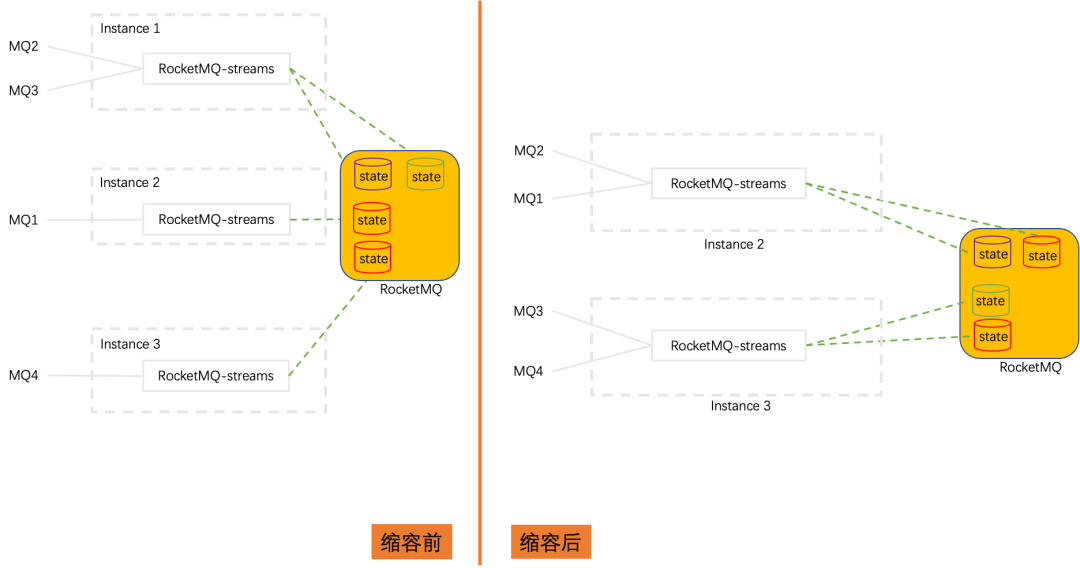
流处理过程中产生的计算状态保存、恢复涉及到流处理过程的正确性。在流处理实例宕机的情况下,该流处理实例上消费的队列会被重平衡到其他流处理实例上。如果对该队列进行了有状态计算,那么产生的状态也需要在新的流计算实例上恢复。如上图中,Instance1 宕机,他消费的 MQ2 和 MQ3 被分别迁移到 Instance2 和 Instance3 上,MQ2 和 MQ3 对应的状态(紫色和蓝色)也需要在 Instance2 和 Instance3 上恢复出来。
存储介质
使用本地 RocksDB,远程 RocketMQ 的组合,作为状态存储介质。流计算在计算状态时,RocksDB 在使用有限内存情况下,作为状态的临时存储,用于算子交互,在计算结束后提交消费位点时将本次计算产生的状态一并写入 RocketMQ 中。消费位点提交、计算结果写出、状态保存需要保持原子状态,这一内容在后面流计算正确性中讨论。
状态持久化存储
RocketMQ 作为消息临时存储,存在数据最大过期时间,一旦过期后,数据会被删除。但是状态存储介质本质上是以 KV 方式存储数据,不希望 KV 数据随着时间过期而被删除。因此,使用 Compact topic 作为状态存储,他会对同一队列的数据按照 Key 对数据进行压缩,相同 Key 的数据只保留 offset 最大的一条。
但是在 RocketMQ 中队列数会随着 Broker 扩缩容而增加或者减少,扩缩 Broker 数量前后,相同的 Key 可能被发送到不同的队列,那么按照上述规则进行 Compact 后得到某个 key 所在的 queueId 就是错误的,使用 Compact topic 作为 KV 存储就失去了意义。
因此在状态 topic 是 Compact topic 的基础上,再将状态 topic 创建为 Static topic(Logic Queue),即状态 topic 即是 Compact topic 也是 Static topic。这样才能解耦队列数量与 Broker 数量,使队列数量在扩缩 Broker 情况下仍然不变,保证含有相同 Key 的数据能被发送到同一队列中。
状态重放
从被迁移状态队列拉取数据到本地进行重放,需要从队列头开始消费,相同 Key 的数据只保留 offset 最大的数据,形成 K-V 状态对,放入本地临时存储 RocksDB 中;
状态 topic 与 source topic 对应关系
因为状态 topic 中的队列会随着 source topic 队列迁移而迁移,保证对 source topic 队列中数据进行有状态处理得到正确的结果,因此在队列层面,状态 topic 与 source topic 应该是一一对应的关系。即状态 topic 名称与 source topic 名称一一对应,状态 topic 的队列数量等于 source topic 队列数量。source topic 队列的流计算状态保存在状态 topic 的对应队列中。
数据处理
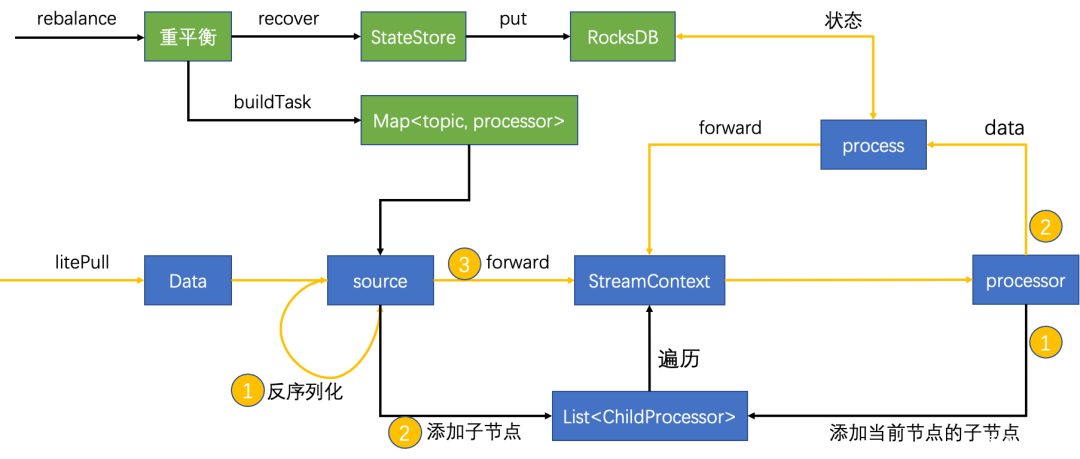
图中黑色线表示控制流,黄色线表示数据流;rebalance 部分先于 litePull 部分被调用。
重平衡部分:
根据分配到的队列,到相应状态 topic 的相应队列中从头拉取数据,到本地重放,获得 KV 状态对,放入到本地 RocksDB 中。
根据数据源 topic,构建对应的数据处理器 processor(即第三次构建过程),保存起来;
数据处理部分:
使用 litePull 模式拉取数据,可以独立控制消费位点提交;
数据反序列化;
使用 topic 查找 processor;
将 processor 的子节点保存起来(子节点在第三次构建过程中添加);
数据向上下文 StreamContext 中传递,由他将数据路由到下游节点;
数据处理前,现将下游节点的子节点保存起来供后续查找;
数据处理,如果有状态算子则与 RocksDB 交互,如果还有下游节点则继续进入 StreamContext,如果没有下游节点则结束处理。
数据每次到下游节点前,先进入 StreamContext 中,由它统一向下游节点传递数据。StreamContext 中包含了处理数据所需要的所有信息,包括数据来源、状态存储、下游子节点等等;
StreamContext 不断递归迭代,将数据向下游传递,最终数据会被拓扑图上所有节点处理,由 sink 节点写出结果。
04 参与贡献
RocketMQ Streams 是 Apache RocketMQ 的子项目,已经在社区开源,并且提出了一些 Good First Issue 供感兴趣同学参加。参与 RocketMQ Streams 相关工作,请参考以下资源:
1、试用 RocketMQ Streams,并阅读相关文档以了解更多信息;
maven 仓库坐标:
RocketMQ Streams 文档:
https://rocketmq.apache.org/zh/docs/streams/01RocketMQ%20Streams%20Overview
2、参与贡献:如果你有任何功能请求或错误报告,请随时提交 Pull Request 来分享你的反馈和想法;
社区仓库:https://github.com/apache/rocketmq-streams
3、联系我们:可以在 GitHub 上创建 Issue,向 RocketMQ 邮件列表发送电子邮件,或在 RocketMQ Streams SIG 交流群与专家共同探讨,RocketMQ Streams SIG 加入方式:添加“小火箭”微信,回复 RocketMQ Streams。
邮件列表:https://lists.apache.org/list.html?dev@rocketmq.apache.org
版权声明: 本文为 InfoQ 作者【Apache RocketMQ】的原创文章。
原文链接:【http://xie.infoq.cn/article/ec1d5cfa81eff42ad3163f416】。文章转载请联系作者。

Apache RocketMQ 官方 2022-11-09 加入
帮助更多企业、更多开发者来学习、了解、体验Apache RocketMQ~









评论