
数据库“啃”不动?CnosDB 带你轻松阅读十万行源码!


最近一直有社区的小伙伴问,我们很感兴趣 CnosDB,但从何开始阅读 CnosDB 的代码呢,其实这个问题在之前的 CnosDB HiTea 直播时就有聊到,今天我们就再来回顾一下。
CnosDB 的源代码主要分为 Query Engine 和 Storage Engine。Query Engine 在 query_sever 下,里面是 query 相关的代码。Storage Engine 在 tskv 目录下,主要是时序存储相关的代码。
Query Engine 的源码阅读

CnosDB 查询步骤大致如下:
1.解析 SQL 语句成 Statement
2.根据 Statement 生成逻辑计划
3.基于规则优化查询逻辑计划
4.根据逻辑计划生成物理计划
5.基于代价优化物理计划
6.执行计划
其中 DDL 语句没有 3、4、5 步骤
CnosDB 查询请求的入口代码在 main/src/http/http_service.rs 中的 query 函数下。一次 http 的 query 请求中,参数携带用户和 DB 名, 根据此进行用户认证,并生成执行 SQL 的上下文。在 query_server/query/src/dispatcher/manager.r 的 execute_query 函数下开始处理 SQL。
1.解析 SQL。解析成 ExtStatement 这个结构体,该结构体代表 SQL 的语法树。ExtStatement 结构体可以在 query_server/spi/src/query/ast.rs 看到。大致分为两类,一类是 DQL 和 DML,其中包括 SELECT、 INSERT 语句,另一类是 DDL,包括 CREATE、 DROP 语句。
2.生成逻辑计划。是根据 Statement 生成逻辑计划,转换的这部分代码在 query_server/query/src/sql/planner.rs。在生成逻辑计划时,会对元数据进行访问,来判断 Statement 的语义是否正确。
3.优化逻辑计划。这部分的入口代码在 query_server/query/src/execution/query.rs 和 query_server/query/src/sql/optimizer.rs 中。逻辑计划的优化是基于规则的,包括谓词下推、简化表达式等规则。其中 DDL 语句,不需要优化逻辑计划,跳过 3、4、5 步。
4.逻辑计划转物理计划。比如连接就有排序连接,哈希连接等不同实现
5.优化物理计划。物理计划的优化是基于代价的,比如根据表的数据量优化连接的主表,这步的入口代码在 query_server/query/src/sql/optimizer.rs 处。
6.执行计划。DDL 的执行大多是访问元数据并修改,这部分代码在 query_server/query/src/execution/ddl 中。而 DQL 往往是扫描表,并用谓词过滤,中间可能有连接操作,投影操作,聚合操作。其中最基础的步骤就是扫描表(TableScan),TableScan 会生成一个表数据的迭代器,迭代器的操作元素是 RecordBatch(是一种 DataFrame 结构)。之后在迭代器返回的 RecordBatch 上执行操作。这些操作包括过滤,连接,聚合,并且往往是向量化执行的。
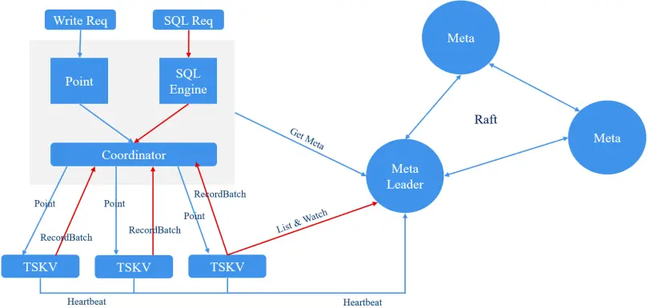
数据流程图
Storage Engine 的源码阅读
关于 TSKV 提供的接口,可以查看 tskv/src/engine.rs 。我们可以从 Storage Engine 的写入接口开始了解 TSKV 的工作原理,接口的实现在 tskv/src/kvcore.rs。写入接口接受一个 write_batch 作为写入的数据,write_batch 为 flatbuffers 生成的代码,原始的 fbs 文件以及一些 grpc 定义可以在 common/protos/proto 中找到。从 write_batch 中可以获取 db、table 以及真正写入的数据。在写入之前,会根据 write_batch 生成 write_group,具体的实现可以看 tskv/src/database.rs,在写入内存之前,会先写 WAL,保证数据恢复,WAL 会写入经过压缩后的 point 以及生成 seq,代码实现在 tskv/src/wal.rs。
写完 WAL 后,开始写入内存,首先会根据 write 接口传入的参数获取具体的 tsfamily,tsfamily 为真正的存储单元,具体实现的逻辑位于 tskv/src/tseries_family.rs。数据写入内存后会根据配置项检查是否应该开始进行 flush,将数据写入磁盘,满足 flush 条件的话会开始进行 flush,flush 代码的实现可以看 tskv/src/compaction/flush.rs。flush 过后,首先会发送 summmary edit 请求,summmary edit 主要用来标记哪些数据以及被 flush,恢复重启时可以不用写入这些数据,summary 有关的逻辑可以查看 tskv/src/summary.rs。compaction 会对磁盘中的数据文件进行合并,具体的 compaction 逻辑可以在 tskv/src/compaction/compact.rs 中看到。
关于分布式
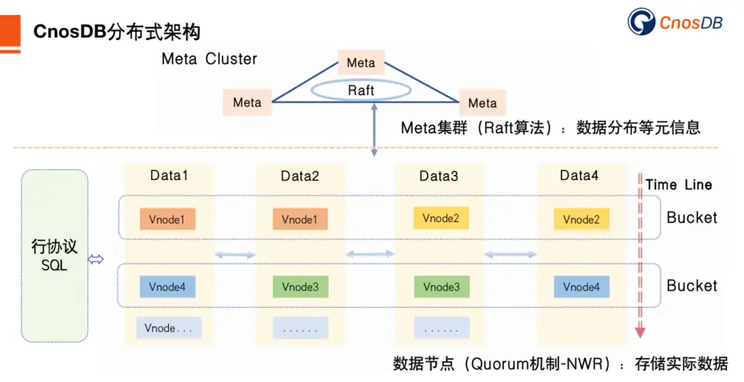
我们还想讲一讲 CnosDB 的分布式功能。CnosDB 分布式由两类节点组成:Meta 节点与 Data 节点。Meta 节点用于存储集群相关的元信息,像数据位置分布、Data 节点信息、用户权限、DB、Table 等相关信息;Meta 是基于 Raft 实现的一套 CP 存储系统,保证元信息存储高可用强一致性。Data 节点用于数据的存储与查询,当前存储与查询相关功能都在 Data 节点实现;后期可能会做计算、存储分离,存储功能单独一个进程,无状态的计算节点单独进程。
CnosDB 的数据分片规则是根据时序数据特有的特点采取基于 time-range 方式分片。每隔一段时间创建一个 bucket(是一个虚拟的逻辑单元),每个 Bucket 又根据 Data 节点个数以及副本数创建多个 Vnode,每个 Vnode 是一个单独的 LSM Tree ,对应 TSFamily 结构体,是一个独立的运行单元,分布到 Data 节点上存储数据。为了确保数据容灾的有效性,Meta 节点在创建 Bucket 分配 Vnode 的时候,可能需要根据机架、电源、控制器和物理位置等信息进行权衡。

CnosDB 的数据读写流程是数据写入时根据数据的时间戳确定写入哪个 Bucket,然后再根据 Hash 算法确定写入哪个 Vnode 以及对应的副本当中。数据读取时,查询引擎解析完 SQL 后根据过滤条件确定读取的 Vnode 进行读取,然后汇总结果返回。
CnosDB 支持 Hinted Handoff。当跨节点的数据副本写入失败时,会写本地磁盘文件,待网络恢复后再写入目的节点。Hinted Handoff 提高写的高可用性。在公有云环境下,网络抖动和 Region 之间的网络不稳定的情况,具有较大的收益。
小结
本篇文章主要介绍了 CnosDB 中 查询、存储和分布式三大 模块的代码结构。更多的代码阅读内容会在后面的章节中逐步展开,敬请期待。
CnosDB 简介
CnosDB 是一款高性能、高易用性的开源分布式时序数据库,现已正式发布及全部开源。
欢迎关注我们的社区网站:https://www.cnosdb.com
版权声明: 本文为 InfoQ 作者【CnosDB】的原创文章。
原文链接:【http://xie.infoq.cn/article/e96ee33e817bce9664c35e7e3】。文章转载请联系作者。

还未添加个人签名 2022-04-18 加入
打造高性能、高压缩比、高可用的分布式云原生时间序列数据库,引领世界迈向万物智联 欢迎关注 https://www.cnosdb.com









评论