
对线面试官 - MQ 经典面试题之高可用性及幂等性
书接上文继续聊聊 MQ 的问题吧。
面试官:继上次聊的 MQ 的问题,想再问问有了解过 MQ 如何保证其高可用行吗?这个可以简单聊聊吗
派大星:当然可以。
首先说一说 Rabbit MQ 的高可用性
Rabbit MQ 有三种模式**:单机模式-(demo 级别的,生产很少使用,这里就无需再说啦)、**普通集群模式以及镜像集群模式
简单说一下
普通集群模式:它是非分布式非高可用。意思就是在多个机器上启动多个 Rabbit MQ 实例,每个机器启动一个,但是你创建的 queue 只会放在一个 Rabbit MQ 实例上,但是每个实例都去同步 queue 的元数据。这样在你消费的时候实际上如果连接到了另外一个实例,那么这个实例会去 queue 所在的实例上将数据拉取过来。这种方式很麻烦并且没有做到所谓的分布式,就是普通的集群。这样会导致要么消费者每次随机连接一个实例然后拉取数据,要么就固定连接那个 queue 的实例消费数据,前者有数据拉取的开销,后者导致单实例的瓶颈。
它的优点是这种模式只是提高了消费者消费的吞吐量。缺点也显而易见:其一就是可能会在 Rabbit MQ 集群内部产生大量的数据传输,再者就是可用性没有什么保障,如果 queue 所在的节点宕机了,数据就丢失了,因为那个 queue 所在的实例包含元数据和实际数据。
接着说一下
镜像集群模式简单如图所示:
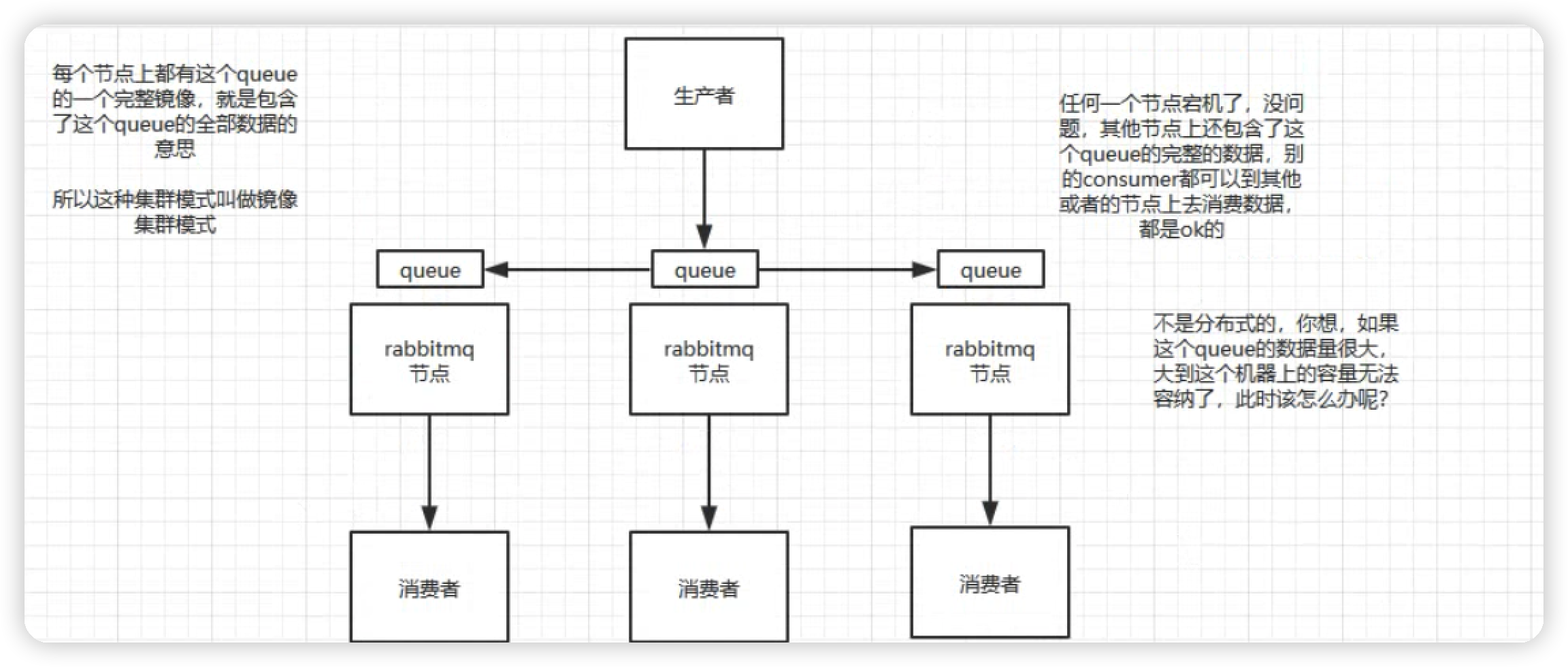
这种模式才是所谓的 Rabbit MQ 真正的高可用模式,与普通集群模式不同的是:你创建的 queue 无论是元数据还是 queue 的消息会存在于多个实例上,每次写消息到 queue 的时候,都会自动把消息与多个实例的 queue 进行消息同步。它的优点就是其中某个机器宕机了,别的机器还可以继续提供服务。缺点:这个性能相比较而言开销较大,消息需要同步所有消息。导致网络带宽压力和消耗很重。还有一点就是所谓的扩展性几乎没有,因为假设某个 queue 的数据负载很重,加机器无法线性去扩展 queue。
面试官:嗯,不错。那你知道如何开启 Rabbit MQ 的镜像模式吗?
派大星:其实就是在管理控制台新增一个镜像集群的策略,要求所有节点同步数据。
面试官:嗯,可以。那你知道 Kafka 的高可用性如何保证吗?
派大星:首先我们要有个基本的认识,简单如图所示:
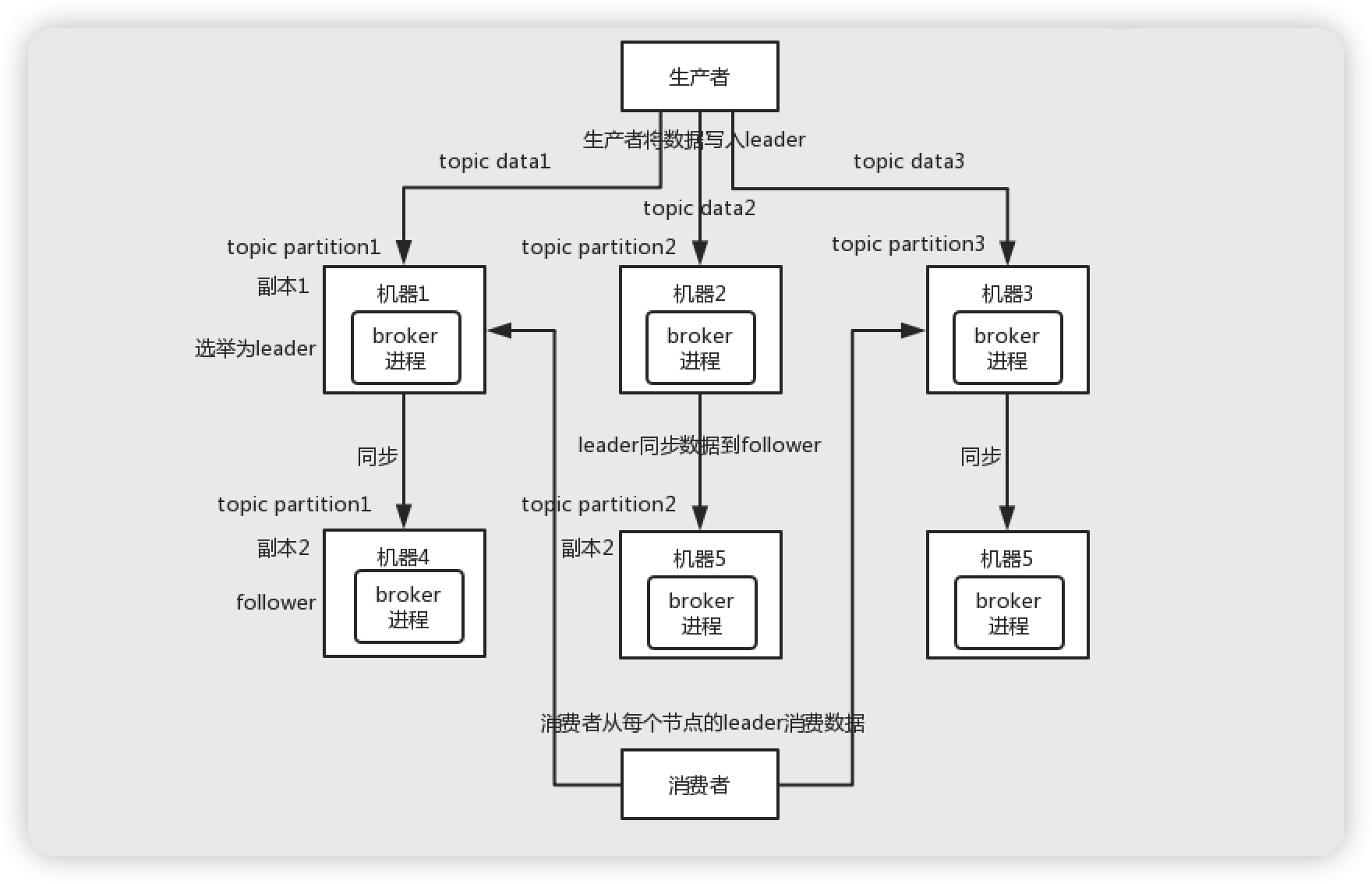
我们都知道 Kafka 是多个 broker 组成,每个 broker 是一个节点,你创建一个 topic,这个 topic 可以划分为多个 partition,每个 partition 可以存在不同的 broker 上,每个 partition 就放一部分数据。天然的分布式消息队列。因为一个topic数据是分散在多个机器上的。每个机器之存放一部分数据。
Tip:
Kafka0.8 之前是没有 HA(高可用)机制的。就是任何一个 broker 宕机了,那么这个 broker 上的 partition 就废了,没法写也没有办法读。Kafka0.8 以后,提供了 HA 机制,就是 replica 副本机制,每个 partition 的数据都会同步到其它机器上,形成自己的多个 replica 副本。然后所有 replica 会选举出一个 leader 出来,那么生产和消费都和这个 leader 打交道,然后其它的 replica 就是 follower。写的时候 leader 只负责把数据同步到 follwer 上,读的时候直接读 leader。如果 leader 宕机 follwer 会变成 leader,follwer 变成 leader 过程无法提供对外服务。
面试官:很好,那在生产环境中如何保证消息不被重复消费呢?或者说如何保证消息的幂等性。
派大星:首先针对于 Kafka 来说,出现这种情况的原因是:消费者 offset 没来得及提交导致重复消费。大致可参考下图:
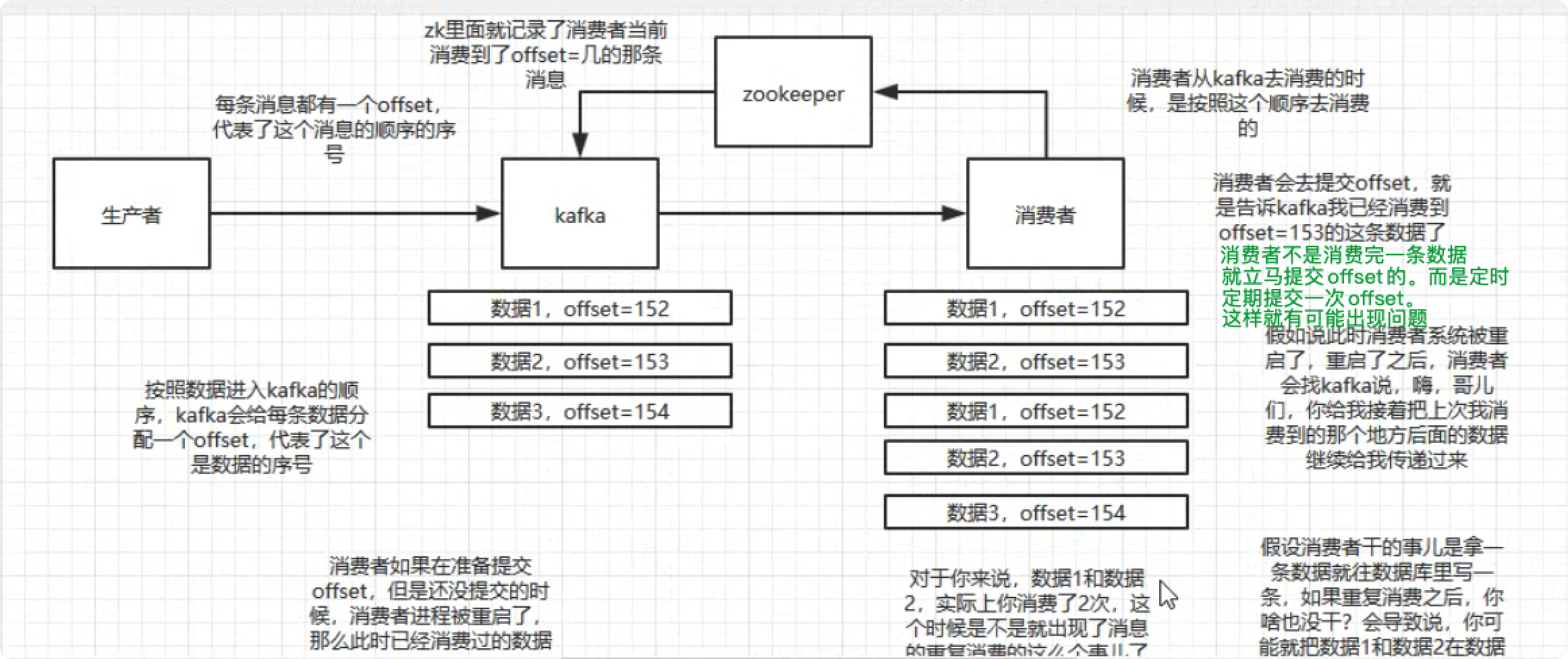
面试官:那你能说说针对幂等性问题有什么解决方案吗?
派大星:方案需要根据不同的场景做不同的应对。情况一:如何生产者不重复发送消息到 MQ。可以通过让 mq 内部可以为每条消息生成一个全局唯一、与业务无关的消息 id,当 mq 接收到消息时,会先根据该 id 判断消息是否重复发送,mq 再决定是否接收该消息。情况二:如何保证消费者不重复消费。其重点在于如何让消费者保证不重复消费的关键在于消费者端做控制,因为 MQ 不能保证不重复发送消息,所以应该在消费者端控制:即使 MQ 重复发送了消息,消费者拿到了消息之后,要判断是否已经消费过,如果已经消费,直接丢弃。所以根据实际业务情况,有下面几种方式:
如果从 MQ 拿到数据是要存到数据库,那么可以根据数据创建唯一约束,这样的话,同样的数据从 MQ 发送过来之后,当插入数据库的时候,会报违反唯一约束,不会插入成功的。(或者可以先查一次,是否在数据库中已经保存了,如果能查到,那就直接丢弃就好了)。
让生产者发送消息时,每条消息加一个全局的唯一 id,然后消费时,将该 id 保存到 redis 里面。消费时先去 redis 里面查一下有么有,没有再消费。(其实原理跟第一点差不多)。
如果拿到的数据是直接放到 redis 的 set 中的话,那就不用考虑了,因为 set 集合就是自动有去重的。
面试官:不错。可不可以再聊聊不同 MQ 如何保证消息传输的可靠性呢?或者说如何处理消息丢失的问题。
派大星:额... .要不下次说吧。这次有点累啦。
如有问题,欢迎加微信交流:w714771310,备注- 技术交流 。或关注微信公众号【码上遇见你】。
版权声明: 本文为 InfoQ 作者【派大星】的原创文章。
原文链接:【http://xie.infoq.cn/article/e7387c85a30f8c62095496b0a】。
本文遵守【CC BY-NC-ND】协议,转载请保留原文出处及本版权声明。

微信搜索【码上遇见你】,获取更多精彩内容 2021-12-13 加入
微信搜索【码上遇见你】,获取更多精彩内容









评论