随着数字内容越来越受欢迎,保护它们免受复制和滥用变得比以往更加重要。抄袭检测工具可以帮助教师评估学生的作业,帮助机构审阅研究论文,帮助作家发现其知识产权被盗的现象。
构建抄袭检测工具可以帮助您理解序列匹配、文件操作和用户界面。您还可以探索自然语言处理(NLP)技术以改进您的应用程序。
一、Tkinter 和 Difflib 模块
要构建抄袭检测器,您将使用 Tkinter 和 Difflib 模块。Tkinter 是一个简单的跨平台库,可以用来快速创建图形用户界面。
Difflib 模块是 Python 标准库的一部分,它提供了用于比较字符串、列表和文件等序列的类和函数。有了它,您可以构建文本自动纠错器、简化版本控制系统或文本摘要工具之类的程序。
二、如何使用 Python 构建抄袭检测器?
导入所需的模块。定义一个方法 load_file_or_display_contents(),它接受 entry 和 text_widget 作为参数。该方法将加载文本文件,并在文本组件中显示内容。
使用 get()方法提取文件路径。如果用户没有输入任何内容,使用 askopenfilename()方法打开文件对话框窗口,选择想要进行抄袭检查的文件。如果用户选择了文件路径,从头到尾清除前一个条目(如果有的话),并插入所选择的路径。
import tkinter as tkfrom tkinter import filedialogfrom difflib import SequenceMatcher
def load_file_or_display_contents(entry, text_widget): file_path = entry.get()
if not file_path: file_path = filedialog.askopenfilename()
if file_path: entry.delete(0, tk.END) entry.insert(tk.END, file_path)
复制代码
以读取模式打开文件,并将内容存储在 text 变量中。清除 text_widget 的内容,并插入前面提取的文本。
with open(file_path, 'r') as file: text = file.read() text_widget.delete(1.0, tk.END) text_widget.insert(tk.END, text)
复制代码
定义一个方法 compare_text(),您将用它来比较两段文本并计算它们的相似度百分比。使用 Difflib 的 SequenceMatcher()类来比较序列并确定相似度。将自定义比较函数设置为 None 以使用默认比较,并传递想要比较的文本。
使用比率方法以浮点格式获得相似度,可以用来计算相似度百分比。使用 get_opcodes()方法检索一组操作,可以用来高亮显示文本的相似部分,并将其与相似度百分比一同返回。
def compare_text(text1, text2): d = SequenceMatcher(None, text1, text2) similarity_ratio = d.ratio() similarity_percentage = int(similarity_ratio * 100)
diff = list(d.get_opcodes()) return similarity_percentage, diff
复制代码
定义一个方法 show_similarity()。使用 get()方法从两个文本框中提取文本,并将它们传递给 compare_text()函数。清除将显示结果的文本框中的内容,插入相似度百分比。从之前的高亮显示中删除“same”标签(如果有的话)。
def show_similarity(): text1 = text_textbox1.get(1.0, tk.END) text2 = text_textbox2.get(1.0, tk.END) similarity_percentage, diff = compare_text(text1, text2) text_textbox_diff.delete(1.0, tk.END) text_textbox_diff.insert(tk.END, f"Similarity: {similarity_percentage}%") text_textbox1.tag_remove("same", "1.0", tk.END) text_textbox2.tag_remove("same", "1.0", tk.END)
复制代码
get_opcode()方法返回五个元组:操作码字符串、第一个序列的开始索引、第一个序列的结束索引、第二个序列的开始索引和第二个序列的结束索引。
操作码字符串可以是四个可能的值之一:replace、delete、insert 和 equal。当两个序列中的一部分文本不同,并且有人把一部分换成另一部分时,您将获得 replace。当文本的一部分存在于第一个序列而不存在于第二个序列时,您将获得 delete。
当文本的一部分在第一个序列中不存在但在第二个序列中存在时,您将获得 insert。当文本的部分相同时,您将获得 equal。将所有这些值存储在适当的变量中。如果操作码字符串是 equal,向文本序列添加 same 标签。
for opcode in diff: tag = opcode[0] start1 = opcode[1] end1 = opcode[2] start2 = opcode[3] end2 = opcode[4]
if tag == "equal": text_textbox1.tag_add("same", f"1.0+{start1}c", f"1.0+{end1}c") text_textbox2.tag_add("same", f"1.0+{start2}c", f"1.0+{end2}c")
复制代码
初始化 Tkinter 根窗口。设置窗口的标题,并在其中定义一个框架。在两个方向用适当的填充来组织框架。定义两个标签以显示 Text 1 和 Text 2。设置它应该驻留的父元素和它应该显示的文本。
定义三个文本框,两个用于要比较的文本,一个用于显示结果。声明父元素、宽度和高度,并将换行选项设置为 tk.WORD,以确保程序在最近的边界处对单词换行,并且不中断中间的任何单词。
root = tk.Tk()root.title("Text Comparison Tool")frame = tk.Frame(root)frame.pack(padx=10, pady=10)
text_label1 = tk.Label(frame, text="Text 1:")text_label1.grid(row=0, column=0, padx=5, pady=5)text_textbox1 = tk.Text(frame, wrap=tk.WORD, width=40, height=10)text_textbox1.grid(row=0, column=1, padx=5, pady=5)text_label2 = tk.Label(frame, text="Text 2:")text_label2.grid(row=0, column=2, padx=5, pady=5)text_textbox2 = tk.Text(frame, wrap=tk.WORD, width=40, height=10)text_textbox2.grid(row=0, column=3, padx=5, pady=5)
复制代码
定义三个按钮,两个用于加载文件,一个用于比较。定义父元素、它应该显示的文本,以及它在被点击时应该执行的函数。创建两个输入组件来输入文件路径,并定义父元素及其宽度。
使用网格管理器以行和列的形式组织所有这些元素。使用 pack 来组织 compare_button 和 text_textbox_diff。在必要的地方添加适当的填充。
file_entry1 = tk.Entry(frame, width=50)file_entry1.grid(row=1, column=2, columnspan=2, padx=5, pady=5)load_button1 = tk.Button(frame, text="Load File 1", command=lambda: load_file_or_display_contents(file_entry1, text_textbox1))load_button1.grid(row=1, column=0, padx=5, pady=5, columnspan=2)file_entry2 = tk.Entry(frame, width=50)file_entry2.grid(row=2, column=2, columnspan=2, padx=5, pady=5)load_button2 = tk.Button(frame, text="Load File 2", command=lambda: load_file_or_display_contents(file_entry2, text_textbox2))load_button2.grid(row=2, column=0, padx=5, pady=5, columnspan=2)compare_button = tk.Button(root, text="Compare", command=show_similarity)compare_button.pack(pady=5)text_textbox_diff = tk.Text(root, wrap=tk.WORD, width=80, height=1)text_textbox_diff.pack(padx=10, pady=10)
复制代码
用黄色背景和红色字体高亮显示标记为相同的文本。
text_textbox1.tag_configure("same", foreground="red", background="lightyellow")text_textbox2.tag_configure("same", foreground="red", background="lightyellow")
复制代码
mainloop()函数告诉 Python 运行 Tkinter 事件循环并监听事件,直到您关闭窗口。
把它们放在一起,然后运行代码以检测抄袭。
三、抄袭检测器的输出示例
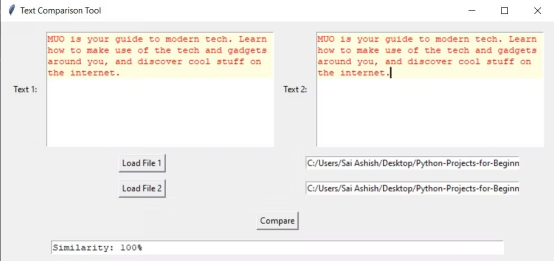
当您运行这个程序时,它会显示一个窗口。点击 Load File 1 按钮后,将打开文件对话框,要求您选择一个文件。选择一个文件后,程序在第一个文本框内显示内容。在输入路径并点击 Load File 2 后,程序将在第二个文本框内显示内容。在点击 Compare 按钮后,您得到的相似度为 100%,它高亮显示相似度 100%的整个文本。
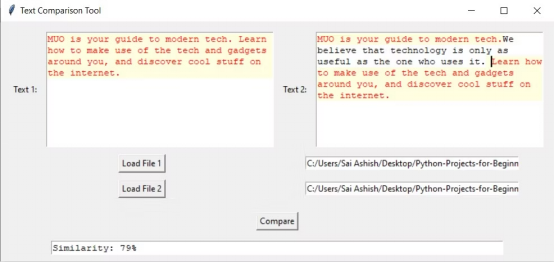
如果您为其中一个文本框添加另一行并点击 Compare,程序将高亮显示相似的部分,并忽略其余部分。
如果几乎没有相似度,程序会高亮显示一些字母或单词,但相似度百分比非常低。
四、使用 NLP 进行抄袭检测
虽然 Difflib 是一种功能强大的文本比较方法,但它对微小的变化很敏感,对上下文的理解有限,并且对于庞大文本而言通常无效。这时候您应该考虑探究自然语言处理,因为它可以执行文本的语义分析,提取有意义的特征,而且能够理解上下文。
此外,您可以针对不同的语言训练模型,并对其进行优化以提高效率。可以用于抄袭检测的一些技术包括 Jaccard 相似性、余弦相似性、单词嵌入、潜在序列分析以及序列到序列模型。
您可以在这个 GitHub 代码仓库中找到使用 Python 构建抄袭检测器的全部源代码:https://github.com/makeuseofcode/Plagiarism-Detector-using-Python













评论