
昇腾迁移丨 4 个 TensorFlow 模型训练案例解读

本文分享自华为云社区《TensorFlow模型训练常见案例》,作者: 昇腾 CANN。
基于 TensorFlow 的 Python API 开发的训练脚本默认运行在 CPU/GPU/TPU 上,为了使这些脚本能够利用昇腾 AI 处理器的强大算力,需要将其迁移到昇腾平台。
本期分享几个 TensorFlow 网络迁移到昇腾平台后执行失败或者执行性能差的典型案例,并给出原因分析及解决方法。
01 数据预处理中存在资源类算子,导致训练异常
问题现象
TensorFlow 网络执行时,报如下错误:
原因分析
初始化图中存在资源类算子 HaskTableV2 ,数据预处理中存在资源类算子 LookupTableFindV2,两个算子需要配对使用。
昇腾 AI 处理器默认采用计算全下沉模式,即所有的计算类算子(包括初始化图中的资源类算子)全部在 Device 侧执行,数据预处理仍在 Host 执行。这样数据预处理中的 LookupTableFindV2 算子与初始化图中的 HaskTableV2 算子未在同一设备执行,导致网络运行出错。
解决方案
需要修改训练脚本,使能混合计算能力,将资源类算子的初始化图也留在 Host 侧执行,训练脚本修改方法如下:
其中配置参数“mix_compile_mode”是混合计算开启开关,当此开关配置为“True”后,会将需要成对使用的资源类算子留在前端框架在线执行。
补充说明:当用户的预处理脚本中存在需要成对使用的 tf.contrib.lookup 下 Table 类的 API 时,需要参考此方法使能混合计算功能,将初始化图中的对应算子留在 Host 侧执行。
02 数据预处理中存在 tf.Variable,导致训练异常
问题现象
TensorFlow 网络执行时,报如下错误:
原因分析
此问题是由于数据预处理脚本中存在 tf.Variable 变量。训练脚本在昇腾平台运行时,tf.Variable 变量在 Host 侧执行,而 tf.Variable 变量的初始化在 Device 侧执行,变量执行和变量初始化不在同一设备执行,导致训练异常。
使用了 tf.Variable 的训练脚本代码示例如下:
解决方案
需要修改训练脚本,将 tf.Variable 修改成常量,修改示例如下:
03 动态 shape 网络执行时报 v1 控制流算子不支持的错误
问题现象
TensorFlow 1.15 版本的动态 shape 网络执行时,报如下错误:
原因分析
由于当前 TensorFlow 网络为动态 shape 网络,且存在 V1 版本的控制流算子。在昇腾 AI 处理器执行 TensorFlow 动态 shape 网络当前不支持 V1 版本的控制流算子,所以会造成网络运行失败。
解决方案
将网络中的 TensorFlow V1 版本的控制流算子转换为 V2 版本,即可解决此问题。
方法一:通过设置如下环境变量将 TensorFlow V1 版本的控制流算子转换为 V2 版本。
方法二:修改网络脚本,在 import tensorflow as tf 后增加如下两条指令,将 TensorFlow V1 版本的控制流算子转换为 V2 版本。
04 网络调测时 ReduceSum 算子执行性能差
问题现象
网络调测时,网络整体性能较慢。通过 Profiling 工具获取网络的 Profiling 数据,并进行算子的性能数据分析,发现 ReduceSum 算子的性能很差。
查看 Profiling 性能数据中 ReduceSum 算子的详细信息,关键字段如下表蓝色字体所示:
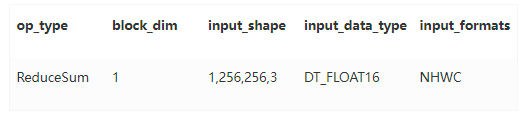
ReduceSum 算子的输入数据类型(input_data_type)为“DT_FLOAT16”,block_dim 字段的值为“1”,说明该算子未开启多核并行计算。
原因分析
针对昇腾 AI 处理器的 ReduceSum 算子,若输入数据类型为 float16,由于硬件限制,某些场景下会无法开启多核计算。
解决方案
ReduceSum 算子输入数据是 float16 的情况可能有如下两种场景:
场景一:
网络调测时未开启混合精度,ReduceSum 算子的输入数据本身就是 float16 类型,此种情况下,若 ReduceSum 算子的性能较差,可尝试在 ReduceSum 算子前插入一个 Cast 算子,将算子的输入数据类型从 float16 转换为 float32。
ReduceSum 算子在输入类型为 float32 的场景下,会使能多核并发计算,从而达到提升该算子性能的效果。
场景二:
网络调测时开启了混合精度,将 ReduceSum 算子的输入数据类型从 float32 转换成了 float16,此种情况下,可将 ReduceSum 算子加入混合精度黑名单,这样网络调测时 ReduceSum 算子就不会被转换成 float16 类型,从而避免该算子性能的劣化。
将 ReduceSum 算子加入混合精度黑名单的方法如下:
1) 修改网络脚本,通过 modify_mixlist 参数指定需要修改的混合精度算子黑名单,修改示例如下:
2) 在 ops_info.json 文件中进行算子黑名单的配置,配置示例如下:
补充说明:仅在 ReduceSum 算子性能较差时,且符合本案例中的问题现象时,可尝试使用此方法进行性能提升。
05 更多介绍
[1]昇腾文档中心:https://www.hiascend.com/zh/document
[2]昇腾社区在线课程:https://www.hiascend.com/zh/edu/courses
[3]昇腾论坛:https://www.hiascend.com/forum
版权声明: 本文为 InfoQ 作者【华为云开发者联盟】的原创文章。
原文链接:【http://xie.infoq.cn/article/c45dea02c9d90b6a3774b4dee】。文章转载请联系作者。

提供全面深入的云计算技术干货 2020-07-14 加入
生于云,长于云,让开发者成为决定性力量









评论