
基于知识图谱的电影知识问答系统:训练 TF-IDF 向量算法和朴素贝叶斯分类器、在 Neo4j 中查询

基于知识图谱的电影知识问答系统:训练 TF-IDF 向量算法和朴素贝叶斯分类器、在 Neo4j 中查询
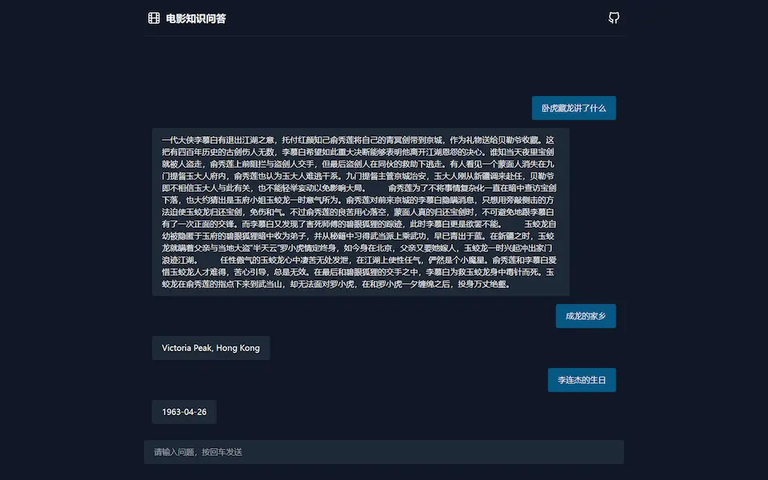
1.项目介绍
训练 TF-IDF 向量算法和朴素贝叶斯分类器,预测用户文本所属的问题类别
使用分词库解析用户文本词性,提取关键词
结合关键词与问题类别,在 Neo4j 中查询问题的答案
通过 Flask 对外提供 RESTful API
前端交互与答案展示
2.项目实操教学
2.1 数据集简介
复制代码
2.2 用户词典
复制代码
2.3 环境依赖
复制代码
2.4 部分代码展示
复制代码
复制代码
2.5 运行项目
在 backend 目录下添加环境变量文件 .env。
复制代码
启动后端服务。
复制代码
在 frontend 目录下添加环境变量文件 .env。
复制代码
启动前端服务。
复制代码
3.技术栈
3.1 数据库
3.2 核心 QA 模块
3.3 后端
3.4 前端
TypeScriptPreactTailwind CSSpnpmViteESLintPrettier
码源链接跳转见文末
更多优质内容请关注公号 &知乎:汀丶人工智能;会提供一些相关的资源和优质文章,免费获取阅读。


版权声明: 本文为 InfoQ 作者【汀丶人工智能】的原创文章。
原文链接:【http://xie.infoq.cn/article/c1b763a272e963c81c3a1ef56】。
本文遵守【CC-BY 4.0】协议,转载请保留原文出处及本版权声明。

本博客将不定期更新关于NLP等领域相关知识 2022-01-06 加入
本博客将不定期更新关于机器学习、强化学习、数据挖掘以及NLP等领域相关知识,以及分享自己学习到的知识技能,感谢大家关注!









评论