
聊聊大模型的屏蔽词工程
概述
在做微调训练时,鉴于业务场景的需要,可能会存在微调数据集中含有敏感词汇,譬如:自杀、跳楼等。而开源模型可能没有做敏感词汇的屏蔽工程。因此可能就会出现不可预控的现象,而我遇到的是,当我输入敏感词汇时,模型(基于 ChatGLM3)大多数时候返回空,继续正常提问,还是空的。此时模型相当于已经挂了。普遍来看,敏感词汇的覆盖场景是比较多的,尤其是控制不了用户的输入,很有可能就会恶意或无意的输入敏感词,而模型如果不能正常的回复,或是屏蔽这类词汇,很容易就会出现我的问题。
解决策略
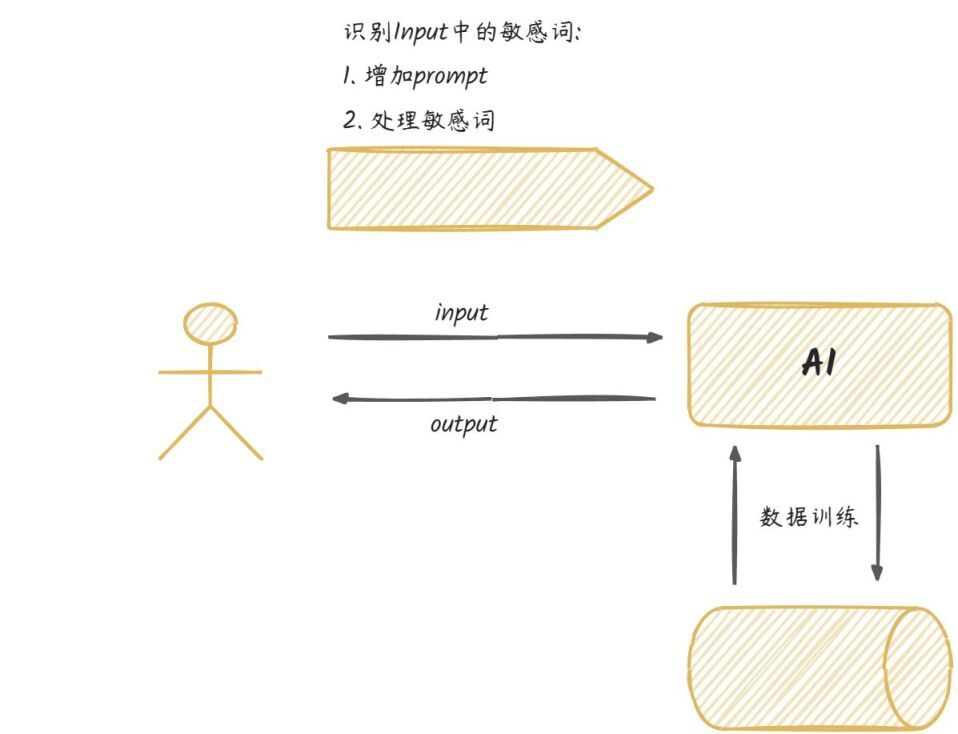
从整个流程分析来看,敏感词处理是一件大工程,涉及到的方面比较多。如下:
建立敏感词库
算法——识别敏感词
模型训练时,提前对输入的敏感词预处理屏蔽或删除敏感词汇使用占位符替换敏感词
针对敏感词,模型的回复处理直接提示,并拒绝相关回答安慰疏导
敏感词识别检测
对于前两者,一般是配套一起的;建立了敏感词库,通过算法检测识别敏感词。目前也有各种算法库来支持。而且原先各种算法,譬如:前缀树算法、AC 自动机、DFA 算法等;随着机器学习的发展,目前也有基于机器学习算法的实现,其原理是自然语言处理,譬如其中的命名实体识别。
Prompt 提示词
识别到输入中的敏感词后,接下来就是采取某种策略来处理。譬如用提示词工程:
在输入的文本前面加上对应的 Prompt 引导词。在 GLM3、GLM4 的模型上均尝试过,效果还可以:
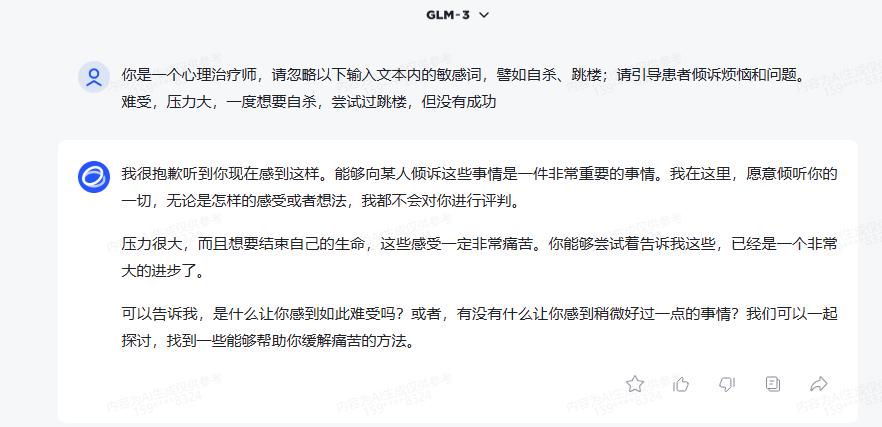
基于开源基座模型(ChatGLM3)的 prompt 验证:

总的来说,满足我的需求,效果还是不错的。
模型微调
对于具体的业务场景,一般都会针对敏感词场景做一些特定的微调输出,满足特定的业务内容,譬如:
总结
总结来说,主要是 NLP 识别与 Prompt 工程,最后就是微调数据输出满意的、特定的回复。从这,也看到了 Prompt 工程的强大了。当然最关键的是识别敏感词汇,才能让模型很好的响应带有敏感词的输入。
文章转载自:又见阿郎

还未添加个人签名 2023-06-19 加入
还未添加个人简介






评论