
Jeff Dean:机器学习在硬件设计中的潜力

作者|Jeff Dean
翻译|沈佳丽、胡燕君、贾川
为什么芯片设计需要很长时间?能不能加速芯片设计周期?能否在几天或几周之内完成芯片的设计?这是一个非常有野心的目标。过去十年,机器学习的发展离不开系统和硬件的进步,现在机器学习正在促使系统和硬件发生变革。
Google 在这个领域已率先出发。在第 58 届 DAC 大会上,Google AI 负责人 Jeff Dean 分享了《机器学习在硬件设计中的潜力》,他介绍了神经网络发展的黄金十年,机器学习如何影响计算机硬件设计以及如何通过机器学习解决硬件设计中的难题,并展望了硬件设计的发展方向。
他的演讲重点在于 Google 如何使用机器学习优化芯片设计流程,这主要包括架构搜索和 RTL 综合、验证、布局与布线(Placement and routing)三大阶段。在架构搜索阶段,Google 提出了 FAST 架构自动优化硬件加速器的设计,而在验证阶段,他们认为使用深度表示学习可提升验证效率,在布局与布线阶段,则主要采用了强化学习技术进行优化。
以下是他的演讲内容,由 OneFlow 社区编译。
1、神经网络的黄金十年
制造出像人一样智能的计算机一直是人工智能研究人员的梦想。而机器学习是人工智能研究的一个子集,它正在取得很多进步。现在大家普遍认为,通过编程让计算机变得“聪明”到能观察世界并理解其含义,比直接将大量知识手动编码到人工智能系统中更容易。
神经网络技术是一种非常重要的机器学习技术。神经网络一词出现于 1980 年代左右,是计算机科学术语中一个相当古老的概念。虽然它当时并没有真正产生巨大的影响,但有些人坚信这是正确的抽象。
本科时,我写了一篇关于神经网络并行训练的论文,我认为如果可以使用 64 个处理器而不是一个处理器来训练神经网络,那就太棒了。然而事实证明,我们需要大约 100 万倍的算力才能让它真正做好工作。
2009 年前后,神经网络技术逐渐火热起来,因为我们开始有了足够的算力让它变得有效,以解决现实世界的问题以及我们不知道如何解决的其他问题。2010 年代至今是机器学习取得显著进步的十年。
是什么导致了神经网络技术的变革?我们现在正在做的很多工作与 1980 年代的通用算法差不多,但我们拥有越来越多的新模型、新优化方法等,因此可以更好地工作,并且我们有更多的算力,可以在更多数据上训练这些模型,支撑我们使用更大型的模型来更好地解决问题。
在探讨设计自动化方面之前,我们先来看看一些真实世界的例子。首先是语音识别。在使用深度学习方法之前,语音识别很难得到实际应用。但随后,使用机器学习和神经网络技术,大幅降低了词语的识别错误率。
几年后,我们将错误率降低到 5%左右,让语音识别更加实用,而现在,在不联网的设备里,我们都可以做到仅仅 4%左右的错误率。这样的模型被部署在人们的手机里面,随时随地帮助人们识别自己的语音。
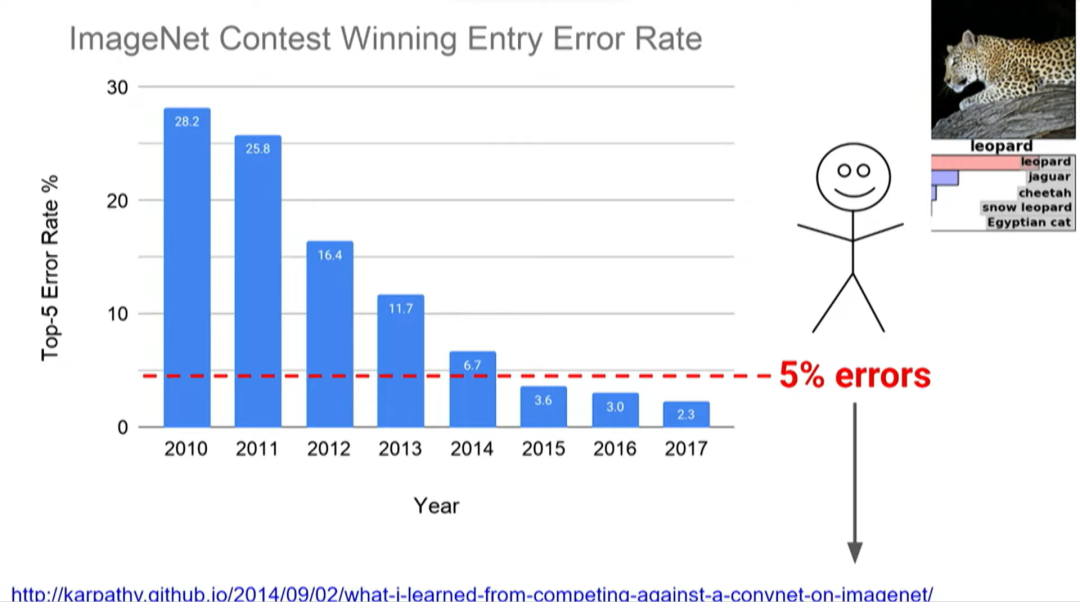
计算机视觉方面也取得了巨大的进步。2012 年左右,Alex Krizhevsky、Ilya Sutskever 和 Geoffrey Hinton 在 ImageNet 比赛中首次使用了 AlexNet,错误率得到显著降低,并在当年夺得桂冠。
后一年的 ImageNet 比赛中,几乎所有参赛者都使用深度学习方法,研究人员则进一步放弃了传统的方法。其中,2015 年,由何恺明等微软研究人员提出 ResNet 更进一步降低了错误率。
当时的斯坦福大学研究生 Andrej Karpathy 正在帮助运营 ImageNet 比赛,他想知道如果人工识别这项艰难的任务,错误率会是多少。在上千个类别中有 40 种狗,你必须能够看着一张照片说:“哦,那是一只罗威纳犬,不是一只大力金刚犬,或者其他品种的狗。” 经过一百个小时的训练,他将错误率降到了 5%。
这是一项非常艰难的任务,将计算机识别错误率从 2011 年的 26%降低到 2017 年的 2%是一件很了不起的事,过去计算机无法识别的东西,现在已经可以识别。自然语言处理、机器翻译和语言理解中也经历了类似的故事。
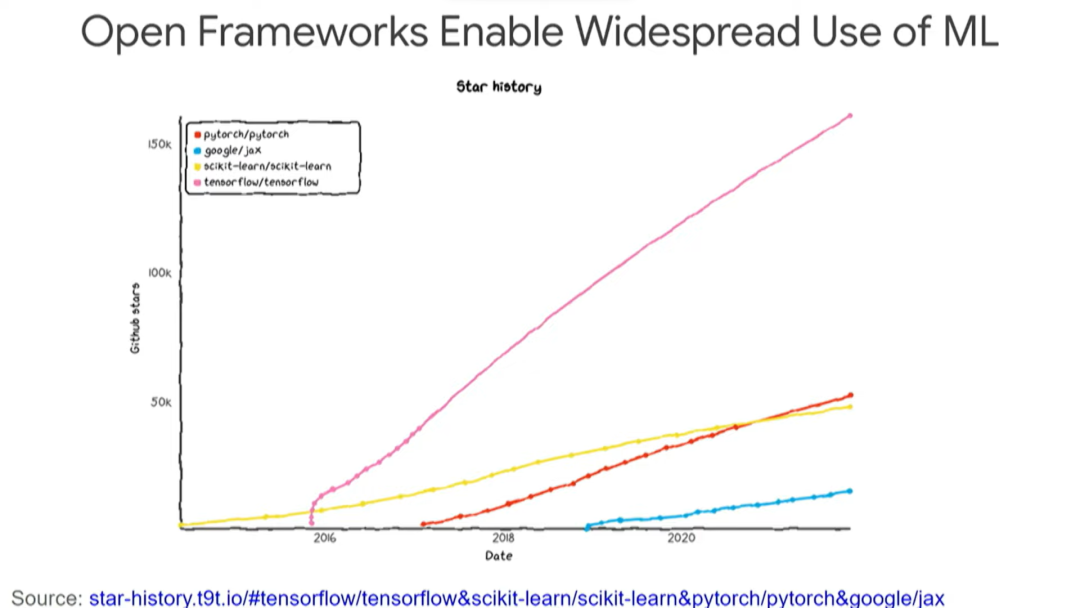
此外,开源框架确实使世界各地的许多人能够应用机器学习技术,TensorFlow 就是其中之一。
大约在 2015 年 11 月,我们开源了 TensorFlow 以及供 Google 内部使用的工具。TensorFlow 对世界产生了相当大的影响,它已经被下载了大约 5000 万次,当然也出现了很多其他框架,比如 JAX、PyTorch 等等。
世界各地的人们能够将机器学习用于各种了不起的用途,例如医疗保健、机器人技术、自动驾驶等等,这些领域都是通过机器学习方法来理解周围的世界,进而推动领域的发展。
2、机器学习改变计算机设计方式

ML 研究社区中的许多成功源自使用更多算力和更大的模型,更多的算力促进了机器学习研究领域中重要成果的产生。深度学习的发展正在深刻改变计算机的结构。现在,我们想围绕机器学习计算类型构建专门的计算机。

近年来,我们已经在 Google 做了很多类似的工作,其中 TPU(张量处理单元)是我们构建定制处理器的一种方法,这些处理器专为神经网络和机器学习模型而设计。
TPU v1 是我们第一个针对推理的产品,当你拥有经过训练的模型,并且只想获得已投入生产使用的模型的预测结果,那它就很适合,它已经被用于神经机器翻译的搜索查询、AlphaGo 比赛等应用中。
后来我们还构建了一系列处理器。TPU v2 旨在连接在一起形成称为 Pod 的强大配置,因此其中的 256 个加速器芯片通过高速互联紧紧连接在一起。TPU v3 则增加了水冷装置。
TPU v4 Pod 不仅可以达到 ExaFLOP 级的算力,它还让我们能够在更大的模型训练中达到 SOTA 效果,并尝试做更多的事情。
以 ResNet-50 模型为例,在 8 块 P100 GPU 上训练完 ResNet-50 需要 29 小时,而在 2021 年 6 月的 MLPerf 竞赛中,TPU v4 pod 仅耗时 14 秒就完成了训练。但我们的目的不仅仅是在 14 秒内训练完 ResNet,而是想把这种强大的算力用于训练其他更先进的模型。
可以看到,从一开始的 29 小时到后来的 14 秒,模型的训练速度提高了 7500 倍。我认为实现快速迭代对于机器学习非常重要,这样才能方便研究者试验不同想法。
基于机器学习的计算方式越来越重要,计算机也正在往更适应机器学习计算方式的方向上演进。但深度学习有可能影响计算机的设计方式吗?我认为,答案是肯定的。
3、机器学习缩短芯片设计周期
目前,芯片的设计周期非常长,需要几十甚至几百人的专业团队花费数年的努力。从构思到完成设计,再到成功生产,中间的时间间隔十分漫长。但如果将来设计芯片只需要几个人花费几周时间呢?这是一个非常理想的愿景,也是研发人员当前的目标。
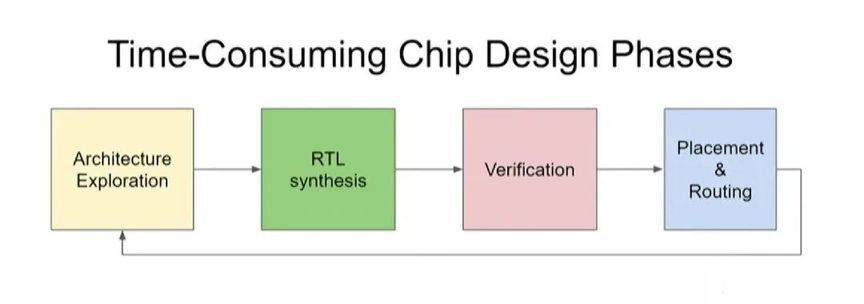
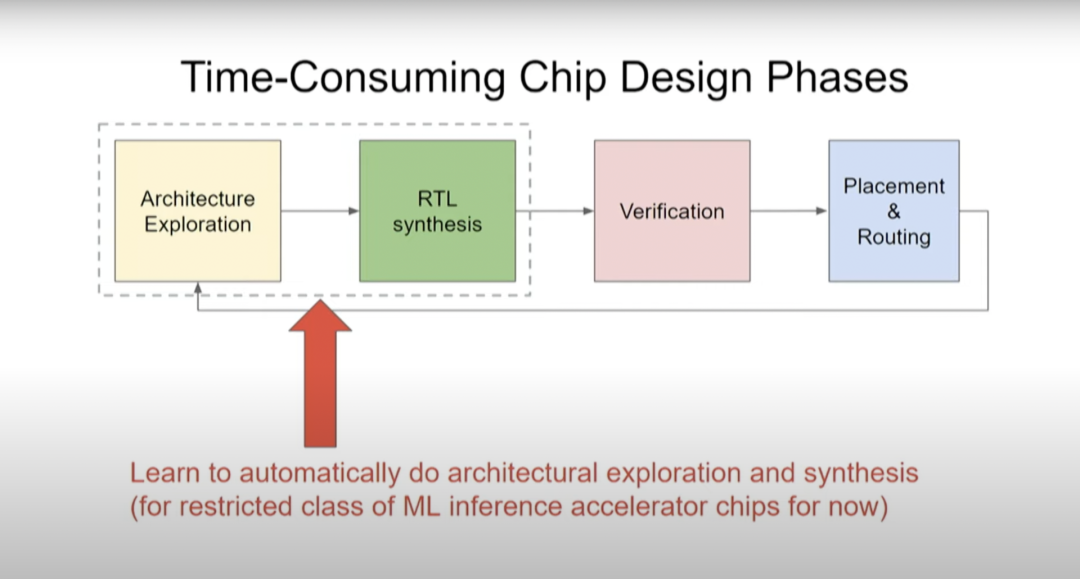
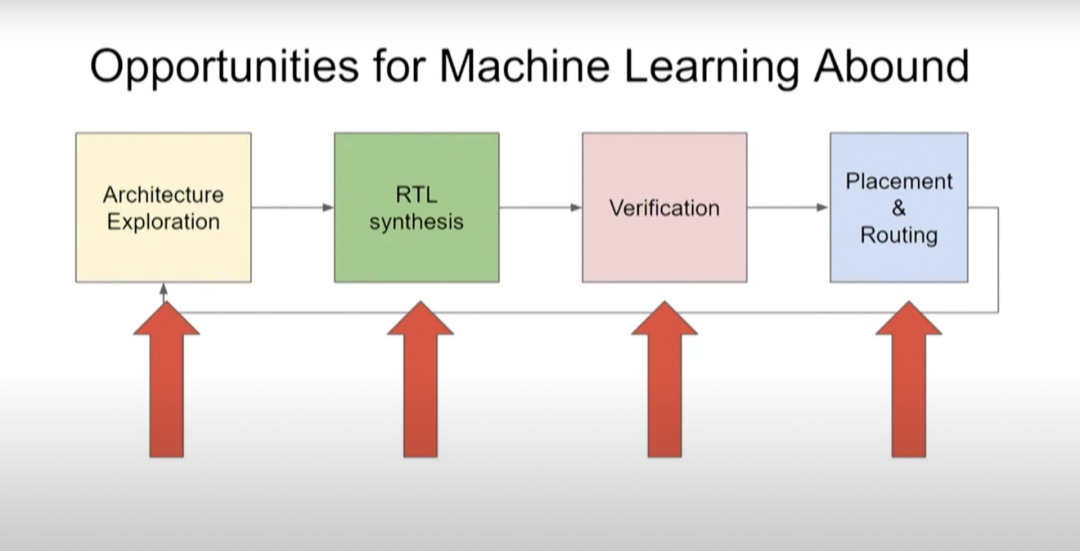
如上图所示,芯片设计包含四个阶段:架构探索→RTL 综合→验证→布局和布线。完成设计之后,在制作生产环节需要进行布局和布线(Placement & Routing),有没有更快、更高质量的布局和布线方法?验证是非常耗时的一步,能不能用更少的测试次数涵盖更多的测试项目?有没有自动进行架构探索和 RTL 综合的方法?目前,我们的芯片架构探索只针对几种重要的应用,但我们终将要把目光扩大。
布局与布线
首先,关于布局和布线,Google 在 2020 年 4 月发表过一篇论文 Chip Placement with Deep Reinforcement Learning,2021 年 6 月又在 Nature 上发表了 A graph placement methodology for fast chip design。
我们知道强化学习的大致原理:机器执行某些决定,然后接收奖励(reward)信号,了解这些决定带来什么结果,再据此调整下一步决定。
因此,强化学习非常适合棋类游戏,比如国际象棋和围棋。棋类游戏有明确的输赢结果,机器下一盘棋,总共有 50 到 100 次走棋,机器可以根据最终的输赢结果评定自己和对手的整套走棋方法的有效性,从而不断调整自己的走棋,提高下棋水平。
那么 ASIC 芯片布局这项任务能不能也由强化学习智能体来完成呢?

这个问题有三个难点。
第一,芯片布局比围棋复杂得多,围棋有 10^{360}种可能情况,芯片布局却有 10^{9000}种。
第二,围棋只有“赢”这一个目标,但芯片布局有多个目标,需要权衡芯片面积、时序、拥塞、设计规则等问题,以找到最佳方案。
第三,使用真实奖励函数(true reward function)来评估效果的成本非常高。当智能体执行了某种芯片布局方案后,就需要判断这个方案好不好。如果使用 EDA 工具,每次迭代都要花上很多个小时,我们希望将每次迭代所需时间缩减为 50 微秒或 50 毫秒。
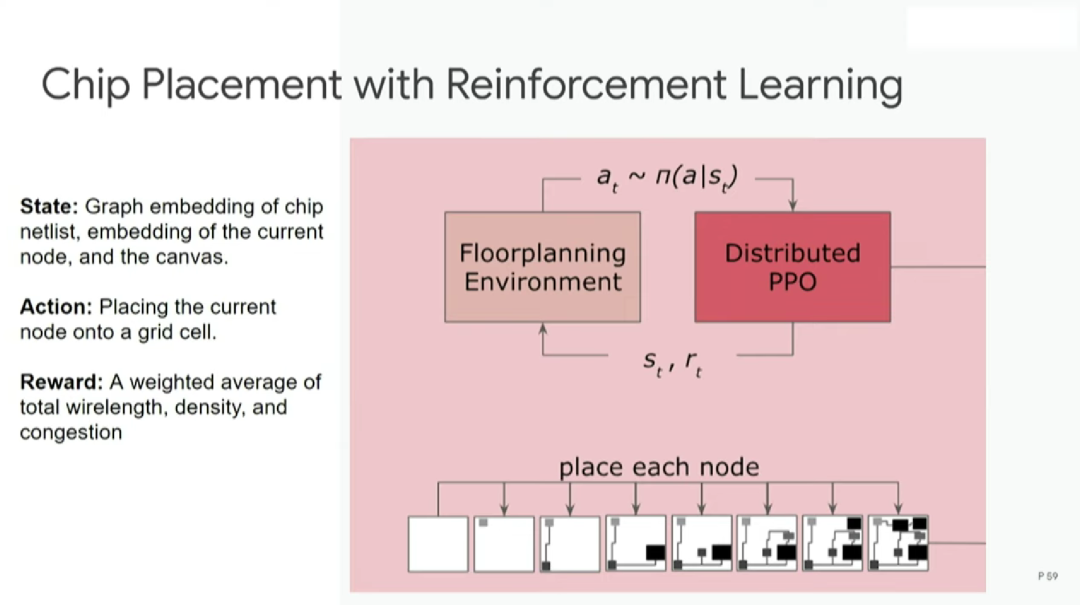
利用强化学习进行芯片布局的步骤如下:首先从空白底座开始,运用分布式 PPO 算法(强化学习的常用算法)进行设计,然后完成每个节点的布局放置,最后进行评估。
评估步骤使用的是代理奖励函数(proxy reward function),效果和真实奖励函数相近,但成本低得多。在一秒或半秒内就可以完成对本次布局方案的评估,然后指出可优化之处。

构建奖励函数需要结合多个不同的目标函数,例如线长、拥塞和密度,并分别为这些目标函数设定权重。
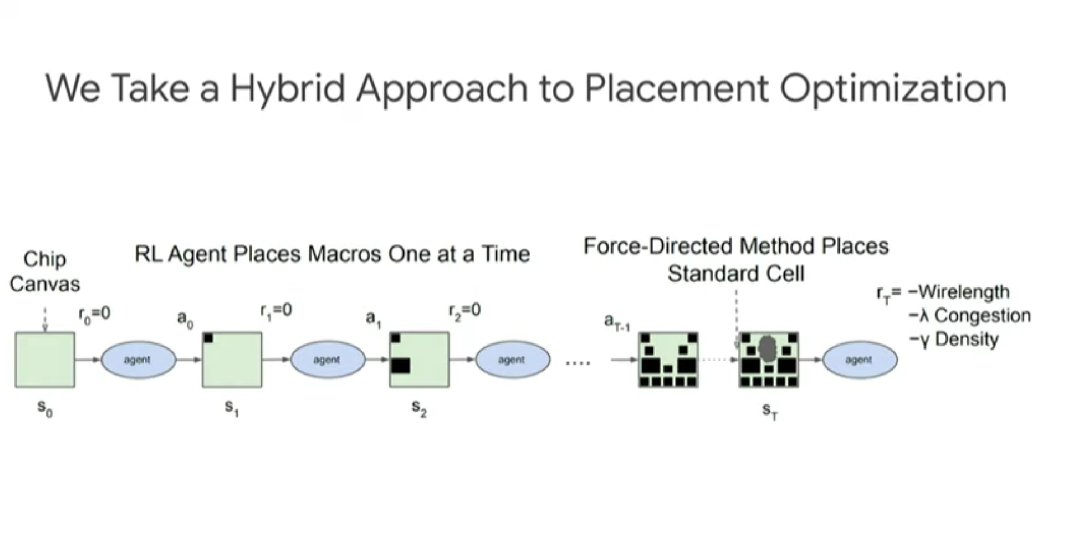
如上图所示,布局优化采取的是混合方式。强化学习智能体每次放置宏(macro),然后通过力导向方法(force-directed method)放置标准单元。
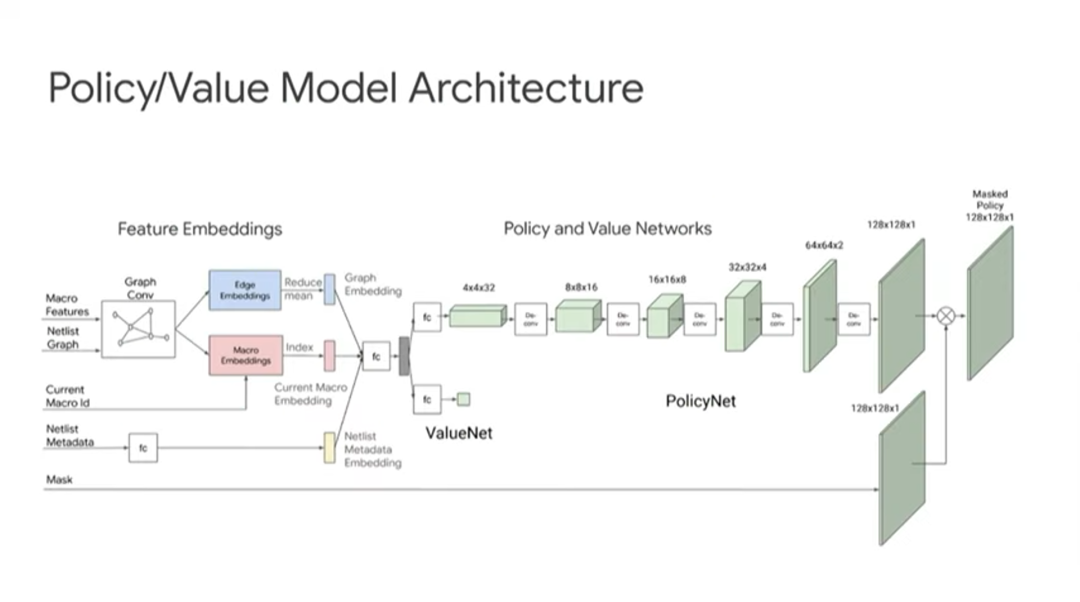
上图来自前面提到的 Nature 论文,展示了更多芯片架构的细节。

上图展示了一个 TPU 设计块的布局与布线结果。白色区域是宏,绿色区域是标准单元群(standard cell clusters)。
图中左边是人类专家完成的设计,从中可以看出一些规律。人类专家倾向于把宏沿边缘放置,把标准单元放在中间。一名人类专家需要 6~8 周完成这个布局,线长为 57.07 米。图中右边是由智能体(ML placer)完成的布局,耗时 24 小时,线长 55.42 米,违反设计规则的地方比人类专家略多,但几乎可以忽略。
可以看出,智能体并不像人类专家一样追求直线布局。为了优化布局,智能体更倾向于弧形布局。我们也希望能训练智能体高效地创造一些前所未有的布局方式。
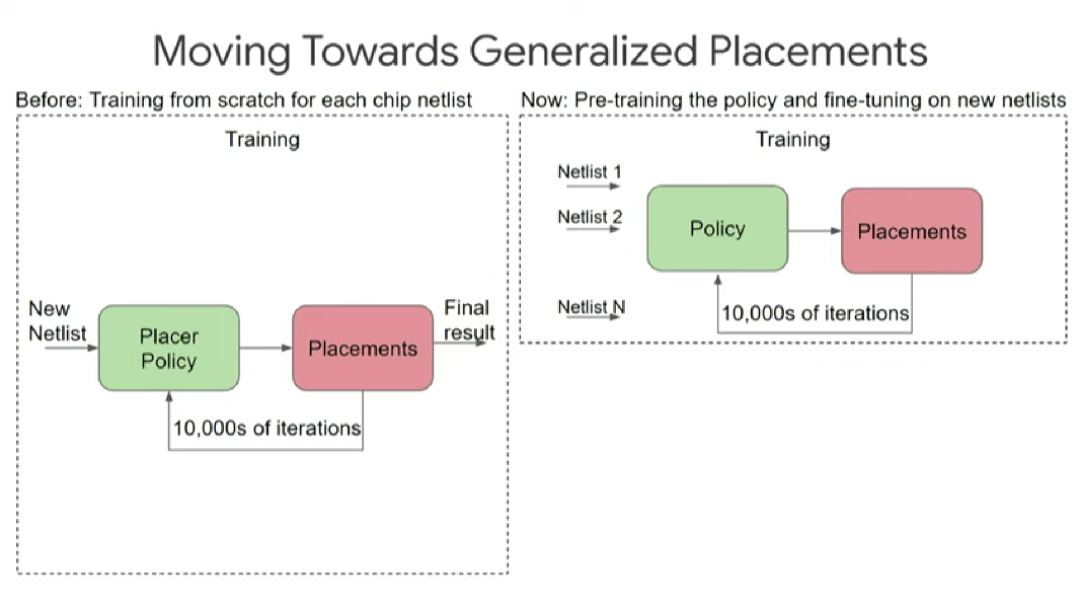
为了实现这个目标,首先,我们运用强化学习算法优化某个芯片设计块的布局,期间需要经历上万次迭代;然后,重复前一步骤,在多个不同的设计块上预训练出一套布局规则,最终让算法在面对前所未见的新设计块时也能给出布局方案。
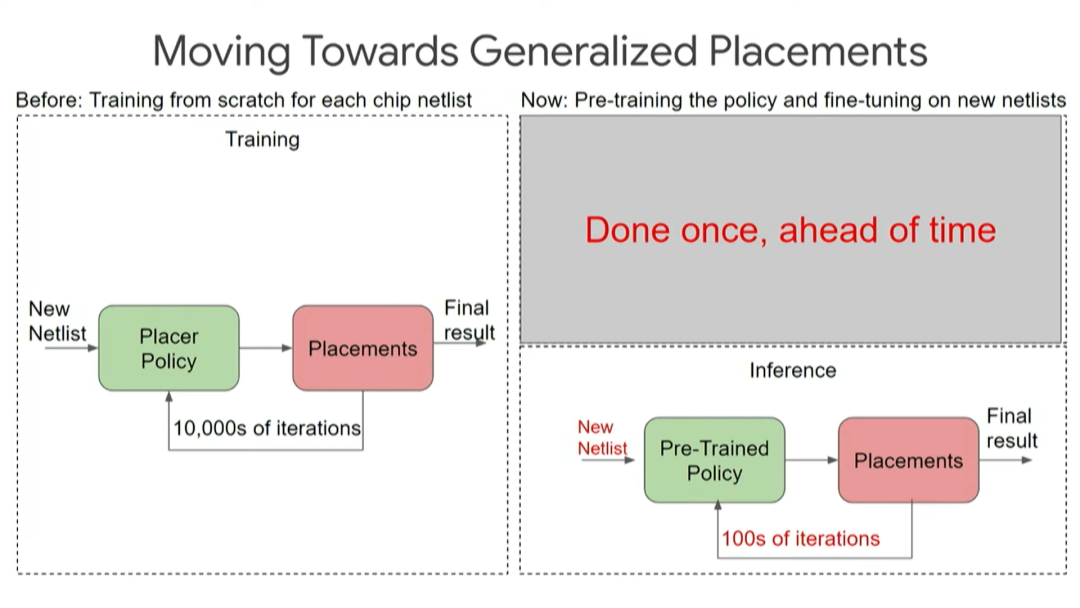
预训练好的策略有助于在推理时做更少的迭代,进行“零次(zero-shot)布局”。我们实际上还没有新算法来优化这个特定的设计,当然我们可以做数百次迭代以得到更好的结果。
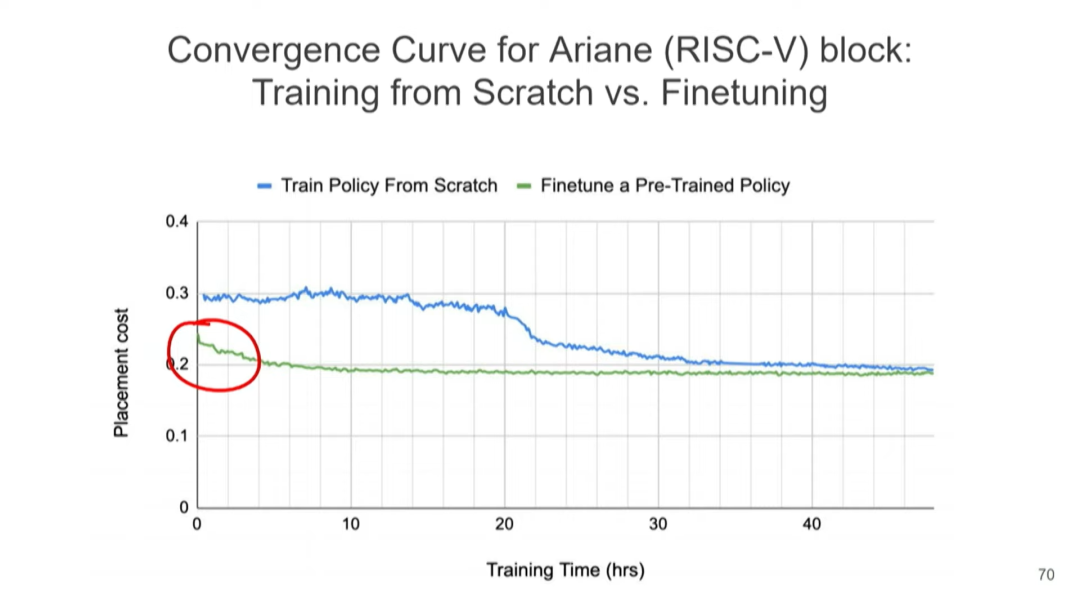
上图展示了使用不同方法时的布局成本。蓝线表示不经过预训练的从头训练策略的布局成本,绿线表示用已预训练的算法优化新设计块的布局,X 轴表示训练时间,可以看到,蓝线在经过 20 多小时的训练后方可大幅降低布局成本,此后仍需经过一段时间才能达到收敛。而绿线只用了极少的训练时间就达到了更低的布局成本并很快收敛。
最令我感到兴奋的是圈红部分。调优预训练策略在短时间内就可实现相当不错的布局,这种实现就是我所说的,在一两秒内完成芯片设计的布局。
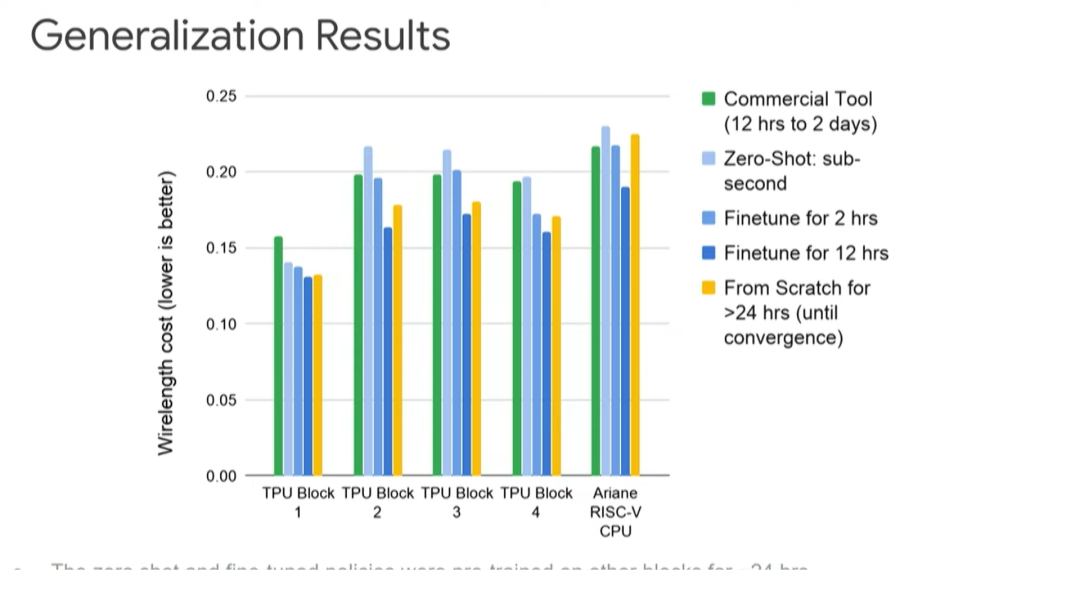
上图展示了更详细的不同设计的情况。Y 轴表示线长成本(越低越好)。绿色表示使用商业工具的线长成本,可以看到,从浅蓝色(零次布局)→蓝色(2 小时微调)→深蓝色(12 小时微调),线长成本越来越低。深蓝色一直比黄色的线长成本要低,因为通过 12 小时的微调能从其他设计中学到最佳布局。
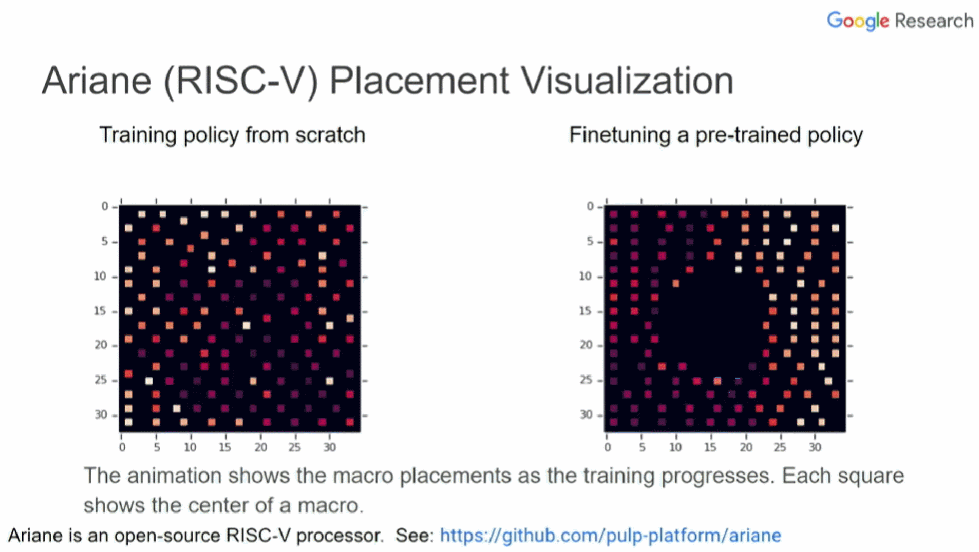
上图中,左边和右边分别展示了从头训练的策略和经过微调预训练策略的芯片布局过程。每个小方块表示一个宏的中心,空白部分表示为标准单元预留的位置。可以看到,右边从一开始就将宏放在边缘,将大片中间区域留空。而左边则要经过很多次迭代才能形成这样的格局。

我们利用强化学习工具针对 TPU v5 芯片的 37 个设计块进行了布局与布线。其中,26 个设计块的布局与布线质量优于人类专家,7 个设计块的质量与人类专家相近,4 个设计块的质量不如人类专家。目前我们已经把这个强化学习工具投入到芯片设计流程中了。
总的来说,用机器学习进行芯片布局与布线的好处包括:可以快速生成多种布局方案;即使上游设计有重大改动也可以迅速重新布局;大幅减少开发新 ASIC 芯片所需的时间和精力。
验证
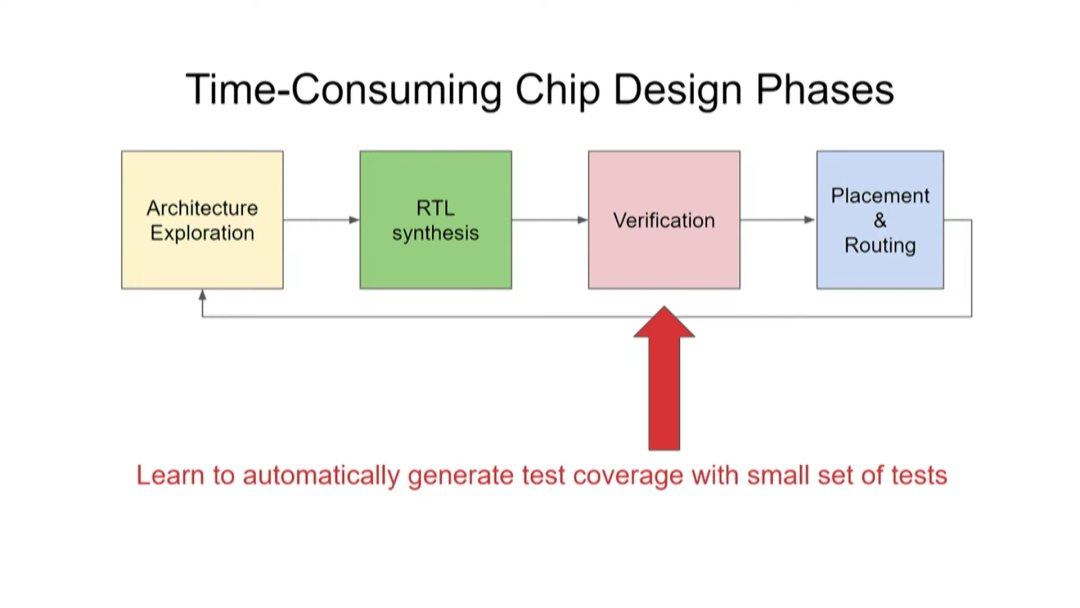
接下来是芯片设计的验证阶段。我们希望用较少的测试次数覆盖多个测试项目。验证是阻碍芯片设计提速的主要瓶颈。据估计,芯片设计过程中,80%的工作量在于验证,而设计本身仅占 20%。因此,验证技术的任何一点进步都会产生重大作用。
Google 在 2021 年 NeurIPS(神经信息处理系统大会)上发表了论文《Learning Semantic Representations to Verify Hardware Designs》,我们能不能运用机器学习生成在更短时间内覆盖更广状态空间的测试用例?
验证阶段的基本问题是可达性(reachability)。目前的芯片设计能否让系统达成需要的状态?我们的想法是,根据当前的芯片设计生成一个连续的表示,从而预测对系统的不同状态的可达性。
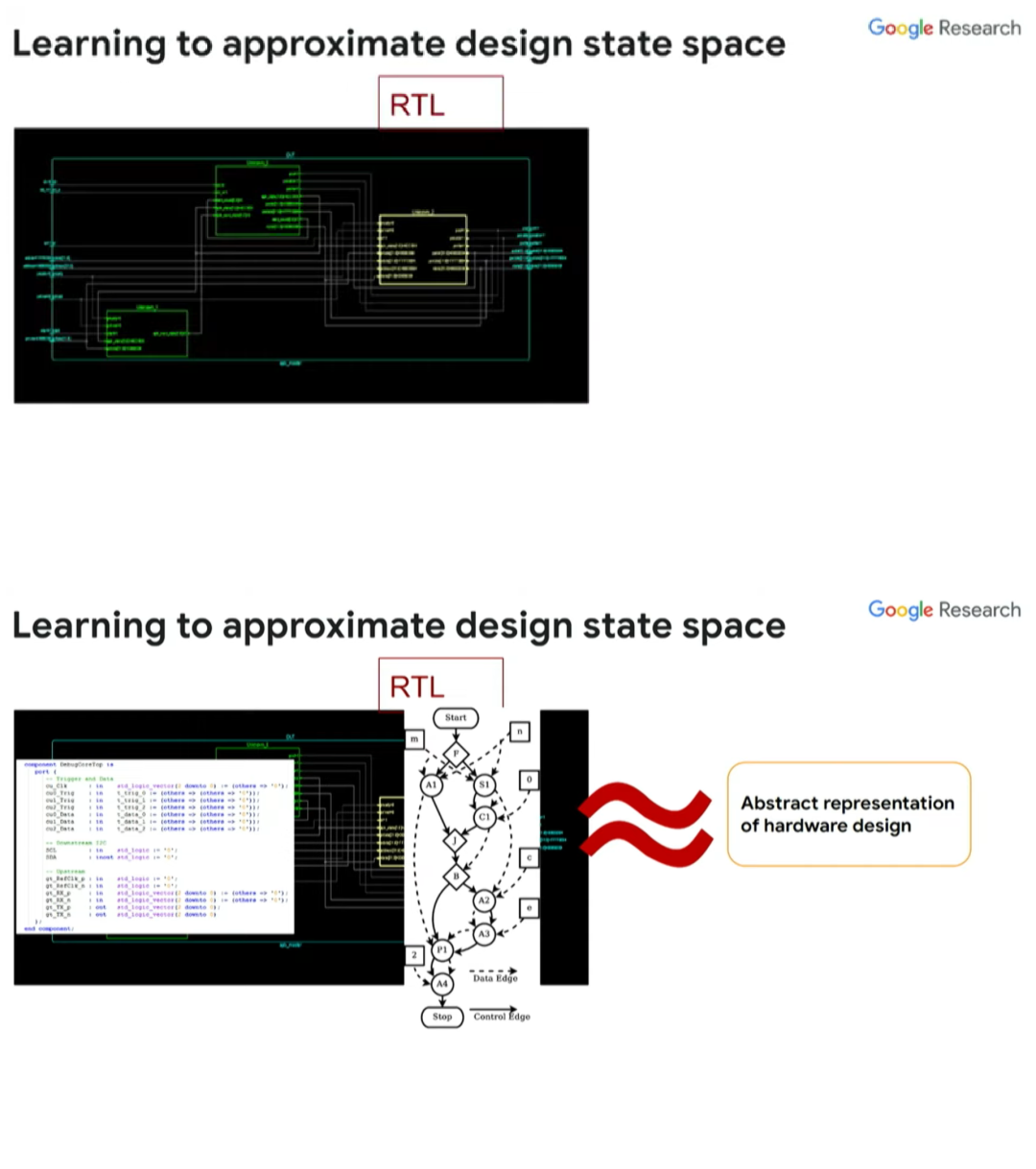
我们可以通过 RTL 将芯片设计抽象为一张图,然后运用基于图的神经网络去了解该图的特性,从而了解其对应芯片设计的特性,继而决定测试覆盖率和测试用例,这给了我们一个很好的设计的抽象表示。
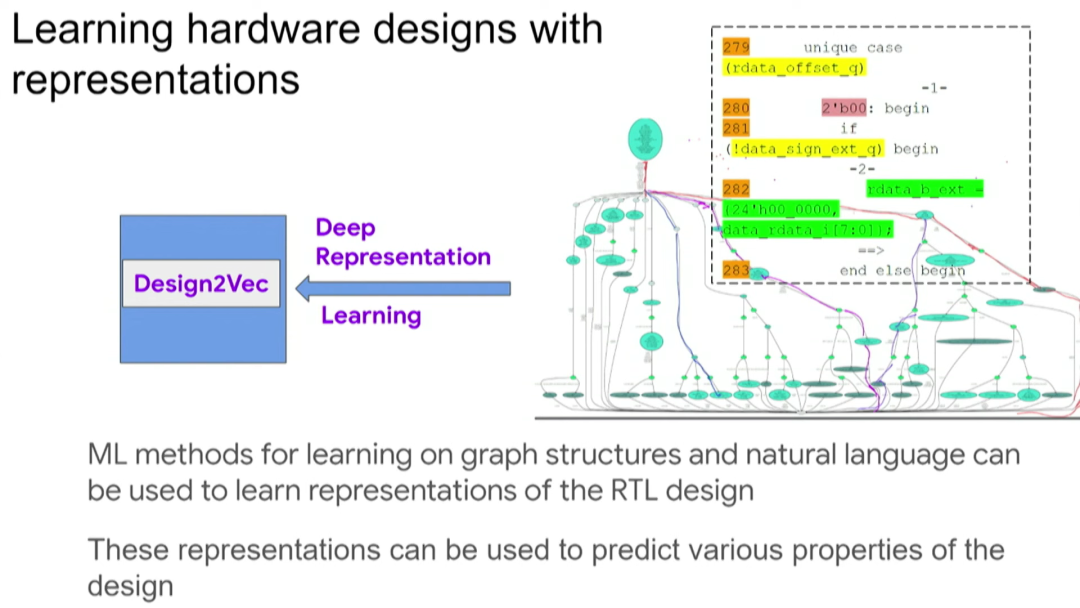
当然,如何将这种方法应用到实际芯片设计中将是另外一个重要话题。用 RTL 生成图表示之后,我们在图神经网络中运用一种叫 Design2Vec 的技术进行深度表示学习,从而帮助我们作出预测。


目前,芯片的验证环节需要大量人力,例如,找 bug、查找测试覆盖率漏洞、分析和解决 bug 等,还需要经历多次如上图所示的流程循环。我们希望上述步骤可以实现自动化,自动生成新的测试用例以解决重要的问题。

后来我们发现,可以把这个问题转化为一个监督学习问题。如果之前进行了一系列测试,并知道这些测试覆盖哪些测试点,就可以将这些数据用作监督学习中的训练数据。
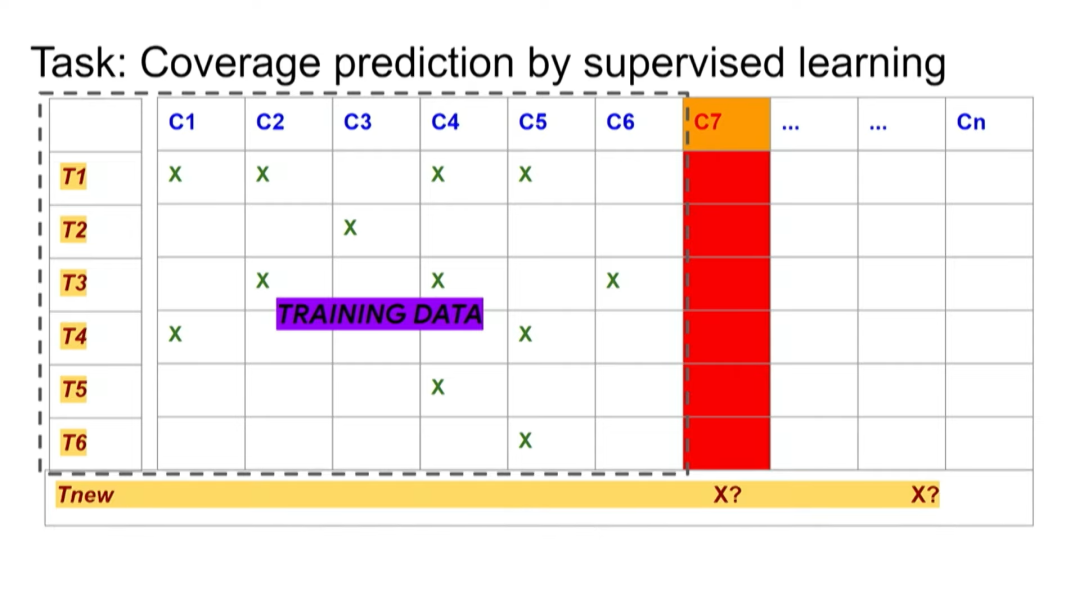
然后,当出现新的测试点时,假设进行一个新的测试,我们需要预测这个测试能否覆盖新的测试点。我们希望能结合之前的训练数据以及芯片设计本身,来实现这种预测。

我们有两个 Baseline,其中一个能够看到测试点(test points)和覆盖点(cover points)的数据,这是一个黑盒测试。
而 Design2Vec 除了能够处理上述数据外,还能处理实际设计、设计的图结构等等。如果你使用一半的测试点作为训练数据,并且设置多个大小不同的训练集,然后对其它测试点进行预测,那么将会得到非常出色的结果,即使是对于相对较少的覆盖点,也能泛化得非常好。相比之下,Baseline 这种方法就不能对此进行很好地泛化。

但使用图神经网络来学习设计、覆盖率和测试属性的方法,实际上比 NeurIPS 论文中的其他所有 Baseline 都要好。
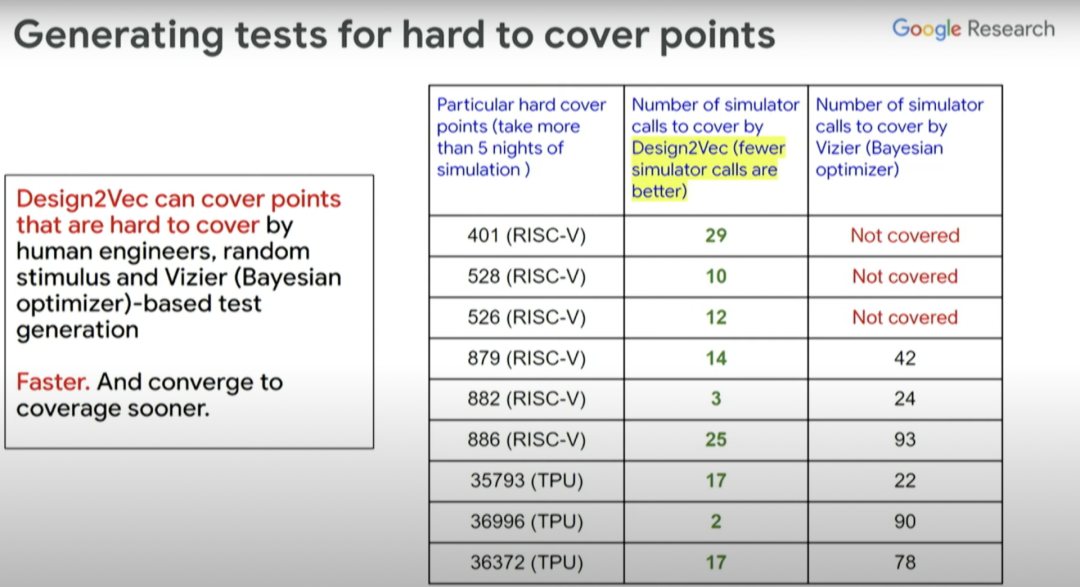
例如,我们常会遇到很多难以生成测试的覆盖点。工程师们发现使用 RISC-V Design 和 TPU Design 这两种不同的设计也很难为这些特定的覆盖点生成测试,于是我们又转向使用贝叶斯优化器来尝试生成测试。
上图右边这一列是贝叶斯优化器覆盖的不同测试点、覆盖点所需的模拟器调用数(simulator calls),中间一列是使用 Design2Vec 所需的模拟器调用数。从中可以看到,为覆盖这些有挑战性的覆盖点。Design2Vec 生成的测试要少于贝叶斯优化器。所以 Design2Vec 非常好,相比之下它更快,能聚焦覆盖范围,还能节省在运行计算模拟器(本身很昂贵)上的开销。

验证是芯片设计在理论和实践上长期面临的一个挑战。我们认为,深度表示学习能够显著提高验证效率和质量,并且在设计中实现泛化。
即使设计发生了一些改变,这个新设计的版本也能运用之前在众多设计上训练出来的系统,提高验证效率。正如在布局与布线阶段,经过训练后的算法即使面对新设计也能够预测不同测试的覆盖点,以带来好的结果。
架构探索和 RTL 综合
在芯片设计中,另一个比较耗时的方面是要清楚你究竟想要构建何种设计。此时你需要做一些架构探索(architectural exploration),然后做 RTL 综合。目前计算机架构师和其他芯片设计师等具有不同专业知识的人花费大量时间来构建他们真正想要的设计,然后验证、布局和布线,那么我们可以学习自动做架构探索和综合吗?
现在我们正在研究的就是如何为已知的问题实行架构探索。如果我们有一个机器学习模型,并且想要设计一个定制芯片来运行这个模型,这个过程能否实现自动化,并提出真正擅长运行该特定模型的优秀设计。
关于这项工作,我们在 arXiv 发表了论文《A Full-stack Accelerator Search Technique for Vision Applications》,它着眼于很多不同的计算机视觉模型。另外一个进阶版本的论文被 ASPLOS 大会接收了《A Full-stack Search Technique for Domain Optimized Deep Learning Accelerators》。
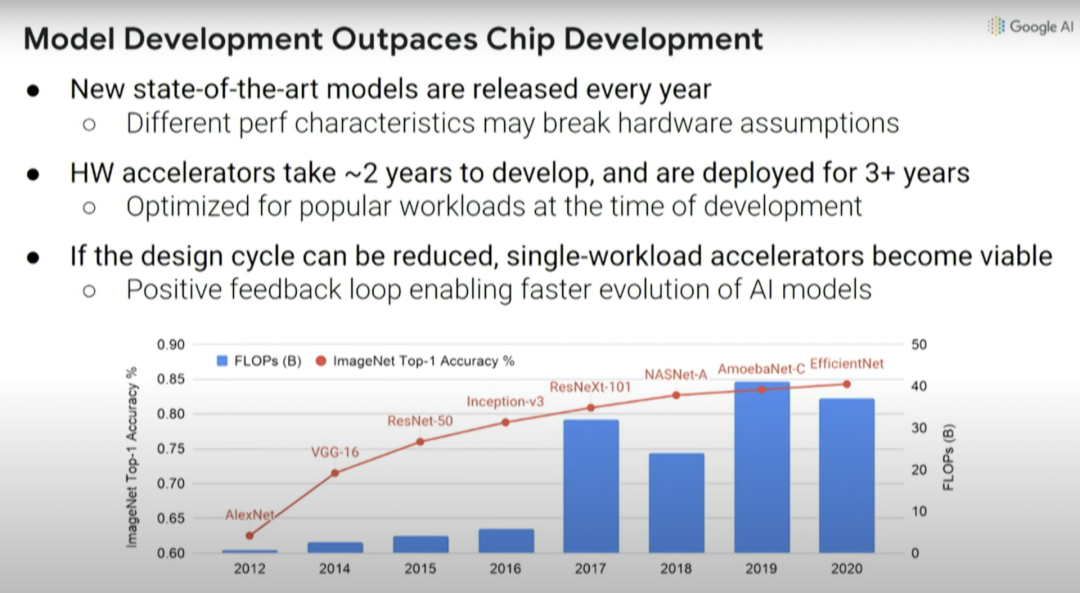
这里要解决的问题是:当你设计一个机器学习加速器时,需要考虑你想在哪个加速器上运行什么样的机器学习模型,而且这个领域的变化非常之快。
上图中的红线是指引入的不同计算机视觉模型,以及通过这些新模型实现的 ImageNet 识别准确率提升。
但问题是,如果你在 2016 年想要尝试设计一个机器学习加速器,那么你需要两年时间来设计芯片,而设计出来的芯片三年后就会被淘汰。你在 2016 年做的决定将会影响计算,要保证在 2018 年-2021 年高效运行,这真的很难。比如在 2016 年推出了 Inception-v3 模型,但此后计算机视觉模型又有四方面的大改进。
因此,如果我们能使设计周期变得更短,那么也许单个工作负载加速器能变得可用。如果我们能在诸多流程中实现自动化,那么我们或许能够得到正反馈循环,即:缩短机器学习加速器的上市时间,使其能更适合我们当下想要运行的模型,而不用等到五年后。
4、用机器学习探索设计空间
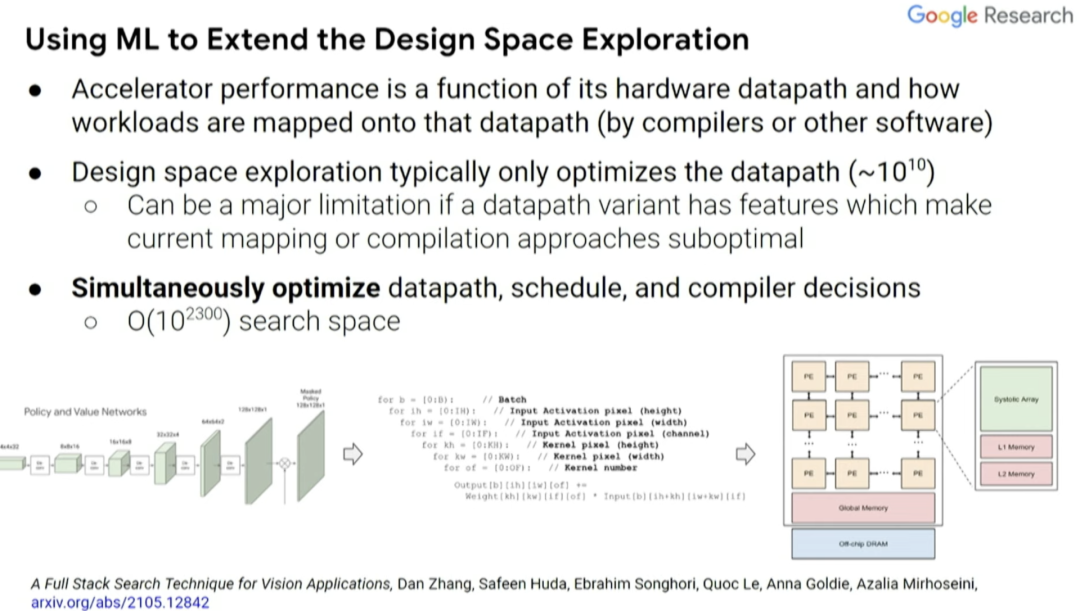
实际上,我们可以使用机器学习来探索设计空间。有两个因素影响加速器性能,一是设计中内置的硬件数据通道,二是工作负载如何通过编译器而不是更高级别的软件映射到该数据通道。通常,设计空间探索实际上只考虑当前编译器优化的数据通道,而不是协同设计的编译器优化和优化数据通道时可能会做的事。
因此,我们能否同时优化数据通道、调度(schedule)和一些编译器决策,并创建一个搜索空间,探索出你希望做出的共同设计的决策。这是一种覆盖计算和内存瓶颈的自动搜索技术,探索不同操作之间的数据通道映射和融合。通常,你希望能够将事物融合在一起,避免内存传输的每次内存负载中执行更多操作。
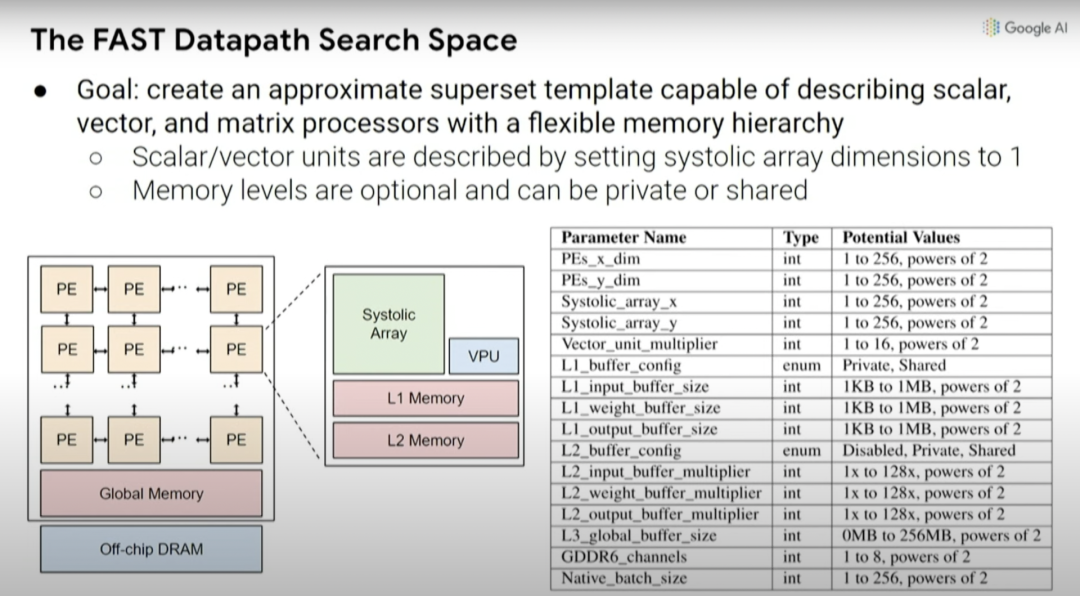
根本上说,我们在机器学习加速器中可能做出的设计决策创建了一种更高级别的元搜索空间,因此,可以探索乘法的脉冲列阵(systolic array)在一维或二维情况下的大小,以及不同的缓存大小等等。
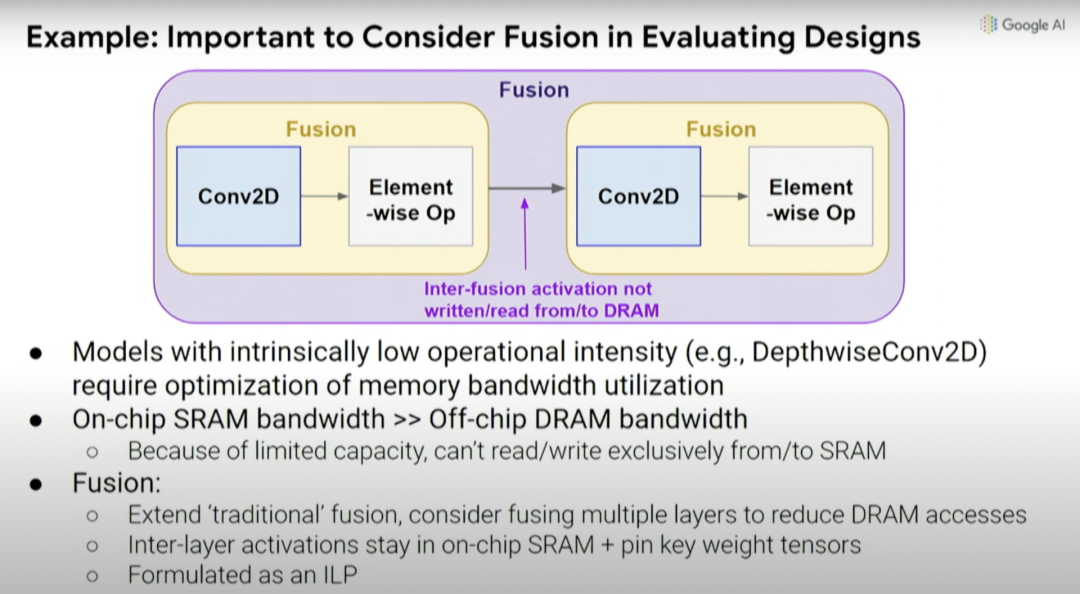
如前所述,考虑编译器优化与硬件设计的协同设计也很重要,因为如果默认编译器不会更改,就无法真正利用处理器中底层设计单元的变化。实际上,不一定要考虑特定设计的所有效果和影响。
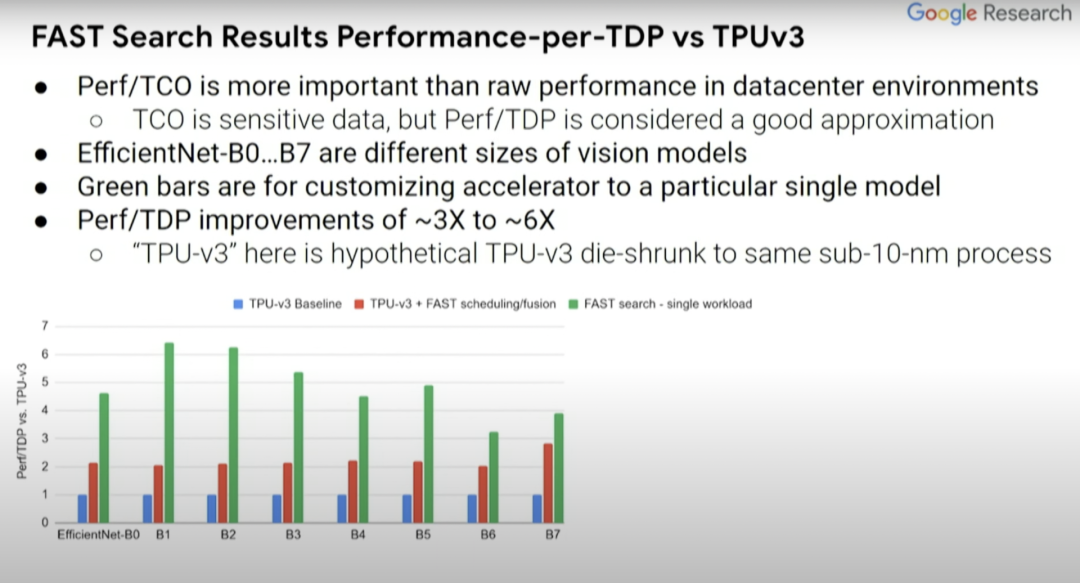
接下来看看这种方式产生的一系列结果,将这些结果与 TPUv3 芯片的 baseline(上图蓝条)进行比较。实际上这是假定型 TPUv3 芯片,其中模拟器已停止了运行。我们已经将其缩小到了 sub-10 纳米工艺。我们还将研究 TPUv3 的软件效用,以及共同探索在设计空间中的编译器优化。
红条和蓝条表示的内容是一致的,但一些探索过的编译器优化不一定在蓝条中得以体现,而这里的绿条则表示的是为单一计算机视觉模型定制的假定型设计。EfficientNet-B0...B7 表示相关但规模不同的计算机视觉模型。与蓝条 baseline 相比,(绿条的)Perf/TDP 的改进大约在 3 到 6 倍之间。
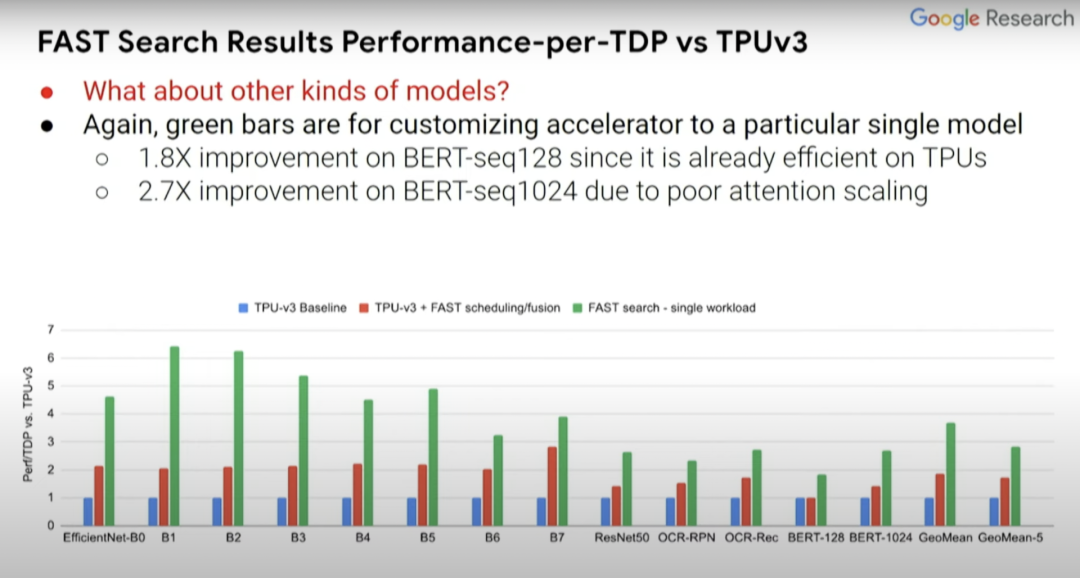
那么除 EfficientNet-B0...B7 外,其他模型的情况如何?在此前所述的 ASPLOS 论文中提出更广泛的模型集,尤其是那些计算机视觉以外的 BERT-seq 128 和 BERT-seq 1024 等 NLP 模型。
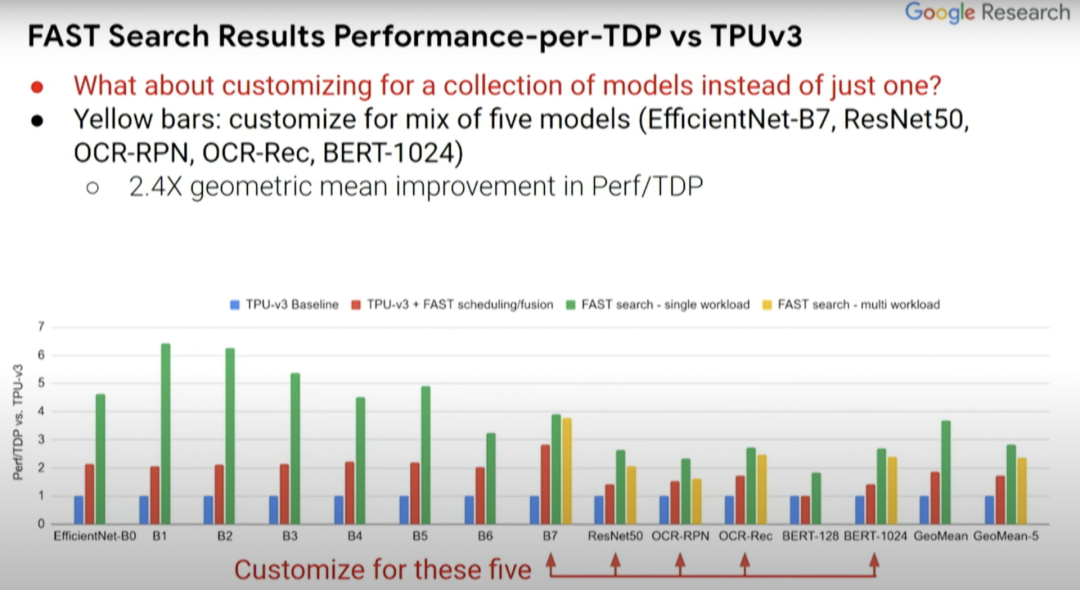
实际上,定制化芯片不只是适用于单个机器学习模型,而是使其适用于一组机器学习模型。你可能不想使你的加速器芯片设计仅针对某一项任务,而是想涵盖你所关注的那一类任务。
上图的黄条代表为五种不同模型设计的定制化芯片,而我们想要一个能同时运行这五种模型(红色箭头所指)的芯片,然后就能看出其性能能达到何种程度。可喜的是,从中可以看到,黄条(单一负载)并不比绿条(多负载)的性能低多少。所以你实际上可以得到一个非常适合这五种模型的加速器设计,这就好比你对其中任何一个模型都进行了优化。它的效果可能不是最好的,但已经很不错了。
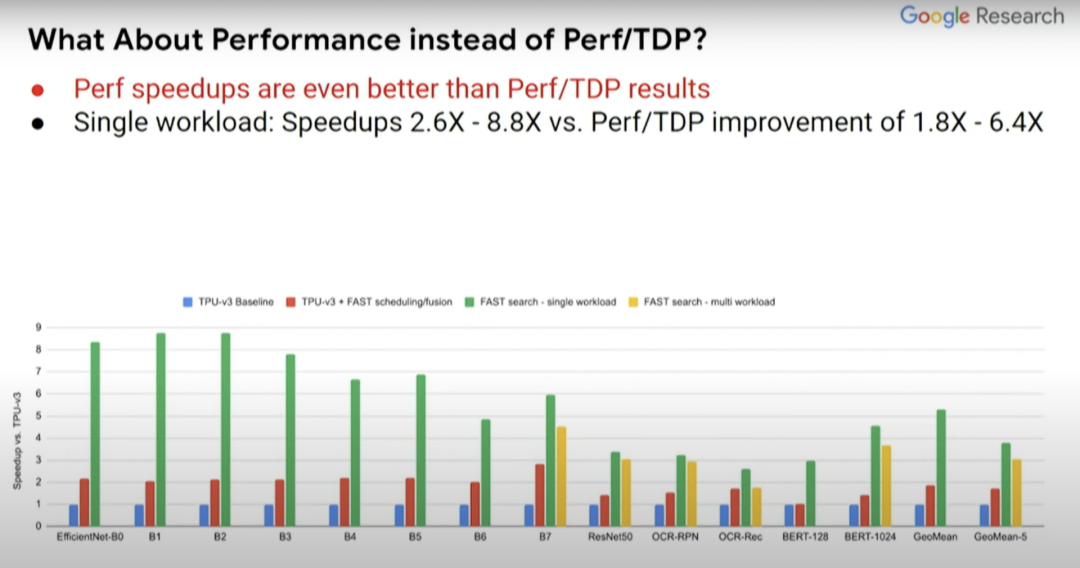
而且,如果你关注的点是性能而非 Perf/TDP,得到的结果实际上会更好。所以结果如何取决于你关注的是什么,是绝对性能还是每瓦性能?在 Perf//TDP 指标中,性能结果甚至提升了 2.6 到 8.8 倍,而非 Perf/TDP 指标下的 1.8 到 6.4 倍。
因此,我们能够针对特定工作负载进行定制和优化,而不用构建更多通用设备。我认为这将会带来显著改进。如果能缩短设计周期,那么我们将能以一种更自动化的方式用定制化芯片解决更多问题。
当前的一大挑战是,如果了解下为新问题构建新设计的固定成本,就会发现固定成本还很高,因此不能广泛用于解决更多问题。但如果我们能大幅降低这些固定成本,那么它的应用面将会越来越广。
5、总结
我认为,在计算机芯片的设计过程中,机器学习将大有作为。
如果机器学习在合适的地方得以正确应用,那么在学习方法(learning approaches)和机器学习计算的加持下,芯片设计周期能不能缩短,只需要几个人花费几周甚至几天完成呢?我们可以用强化学习使得与设计周期有关的流程实现自动化,我认为这是一个很好的发展方向。
目前人们正通过一组或多组实验来进行测验,并基于其结果来决定后续研发方向。如果这个实验过程能实现自动化,并且能获取满足该实验正常运行的各项指标,那么我们完全有能力实现设计周期自动化,这也是缩短芯片设计周期的一个重要方面。

这是本次演讲的部分参考文献以及相关论文,主要涉及机器学习在芯片设计和计算机系统优化中的应用。

机器学习正在很大程度上改变人们对计算的看法。我们想要的是一个可以从数据和现实世界中学习的系统,其计算方法与传统的手工编码系统完全不同,这意味着我们要采取新方式,才能创建出我们想要的那种计算设备和芯片。同时,机器学习也对芯片种类和芯片设计的方法论产生了影响。
我认为,加速定制化芯片设计过程中应该将机器学习视为一个非常重要的工具。那么,到底能否将芯片设计周期缩短到几天或者几周呢?这是可能的,我们都应该为之奋斗。
(原视频:https://www.youtube.com/watch?v=FraDFZ2t__A)
其他人都在看
欢迎下载体验 OneFlow v0.8.0 最新版本:https://github.com/Oneflow-Inc/oneflow/
版权声明: 本文为 InfoQ 作者【OneFlow】的原创文章。
原文链接:【http://xie.infoq.cn/article/b62a0c28f0c5faa8c2600a8e4】。文章转载请联系作者。

不至于成为世界上最快的深度学习框架。 2022.03.23 加入
★ OneFlow深度学习框架:github.com/Oneflow-Inc/oneflow ★ OF云平台:oneflow.cloud









评论