
图加速数据湖分析 -GeaFlow 和 Hudi 集成
GeaFlow(品牌名 TuGraph-Analytics) 已正式开源,欢迎大家关注!!! 欢迎给我们 Star 哦! GitHub👉https://github.com/TuGraph-family/tugraph-analytics
更多精彩内容,关注我们的博客 https://geaflow.github.io/
表模型现状与问题
关系模型自 1970 年由埃德加·科德提出来以后被广泛应用于数据库和数仓等数据处理系统的数据建模。关系模型以表作为基本的数据结构来定义数据模型,表为二维数据结构,本身缺乏关系的表达能力,关系的运算通过 Join 关联运算来处理。表模型简单且易于理解,在关系模型中被广泛使用。随着互联网信息技术的发展,处理的数据规模越来越大,大数据系统应运而生。表模型作为重要的数据模型依然被 Spark/Hive/Flink 等主流大数据引擎所采用,表模型之上的 SQL 查询语言也被广泛使用在大数据分析处理中。然而随着应用场景的丰富和处理数据规模的变大,表模型的问题也越来越多的暴露出来。
首先,关系运算成本高
表模型本身缺乏关系描述能力,只能通过 Join 运算来完成关系的计算。无论在批处理系统里面还是流计算系统中,Join 都是非常重的操作,需要大量的数据 shuffle 和计算开销,在流计算系统中,还需要存放左右两张流表的历史状态,存储消耗极高。
其次,数据冗余时效性低
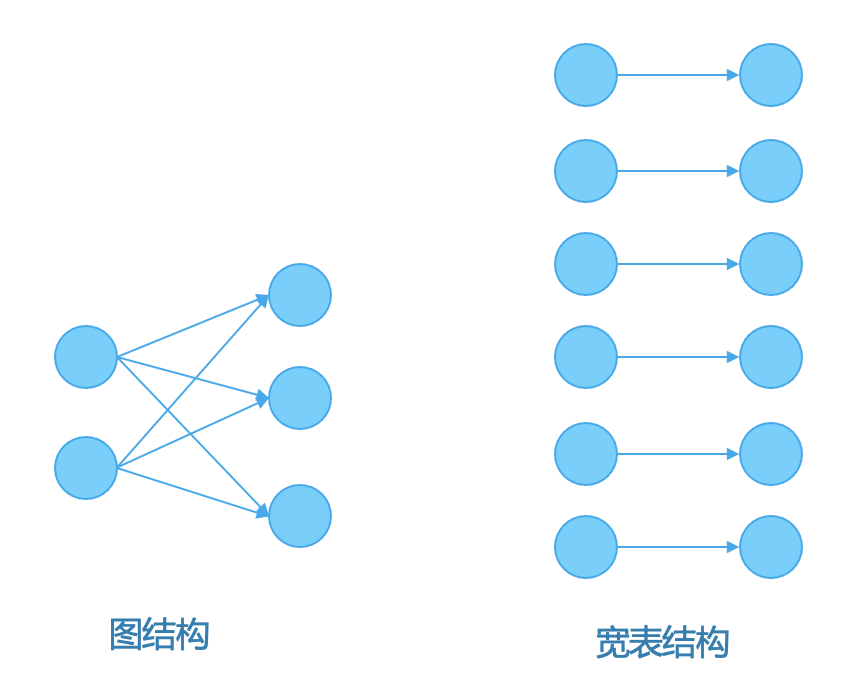
数仓分析的场景为了提高数据查询性能,往往将多张表提前物化成一张大宽表。大宽表虽然可以加速查询性能,然而其数据膨胀和冗余非常严重。需要将多张表 Join 成一张表,表与表之间一对多的关联关系导致一张表的数据通过关联会放大多份,造成数据量指数级膨胀和冗余。而且宽表一旦生成,如需添加新的表进来,需要重新生成新宽表,计算开销大,不灵活。另外,基于 Join 方式成本高,基于宽表方式很难实现数仓实时化。
最后,无法支持复杂关系查询
基于 SQL join 方式很难描述复杂关系查询,比如查询一个人 4 度以内所有好友或者查询最短路径等。这些复杂关联关系通过 SQL 表的 join 方式很难描述。
图模型解决方案
图是关系的天然描述
图是对关系的一种天然描述,图模型是一种以点和边作为基本单元定义的数据模型天然可以描述关联关系。在图模型里面以点代表实体,以边代表关系。比如在人际关系图里面,每一个人可以用一个点来表示,人和人之间的关系通过边来表示,人与人之间可以存在各种各样的复杂关系,这些关系都可以通过不同的边来表示。所以图模型里面天然就包含关系,是对关系最自然的表达。

图是关系的物化
图模型中本身包含点边关系的定义,在数据存储层面会按照点边关系存放数据,点和其邻边会存储在一起。所以图存储层面对关系做了物化,相比与表的 Join 方式,可以获取更好的关联计算性能。相比宽表的关系物化方式,由于图结构本身的点边聚合性,不会出现宽表展开导致的数据膨胀,其存储空间会更小,如下图所示。
图加速数据查询
利用图的关系物化的能力,可以加速关系运算的查询,如下例子:学生、课程和教师三个实体表,实体之间存在选课(selectCourse)、考试(examination)和教学(teach)三种关系.这些实体之间的关系查询可以通过图查询来表示。

查询数学考试成绩前十的学生及其分数
对应图查询:
查询选课人数最多的老师 Top 3
对应图查询:
图模型和表模型关系
图模型本身包含点数据集和边数据集,点边数据集来源于表数据,比如 Hive 表、Hudi 表等。所以,图模型是表模型的超集,是对表模型的补充和完善。图模型可以起到类似宽表的作用,物化表的关系,同时能更灵活的定义关系,消耗更小的存储开销.
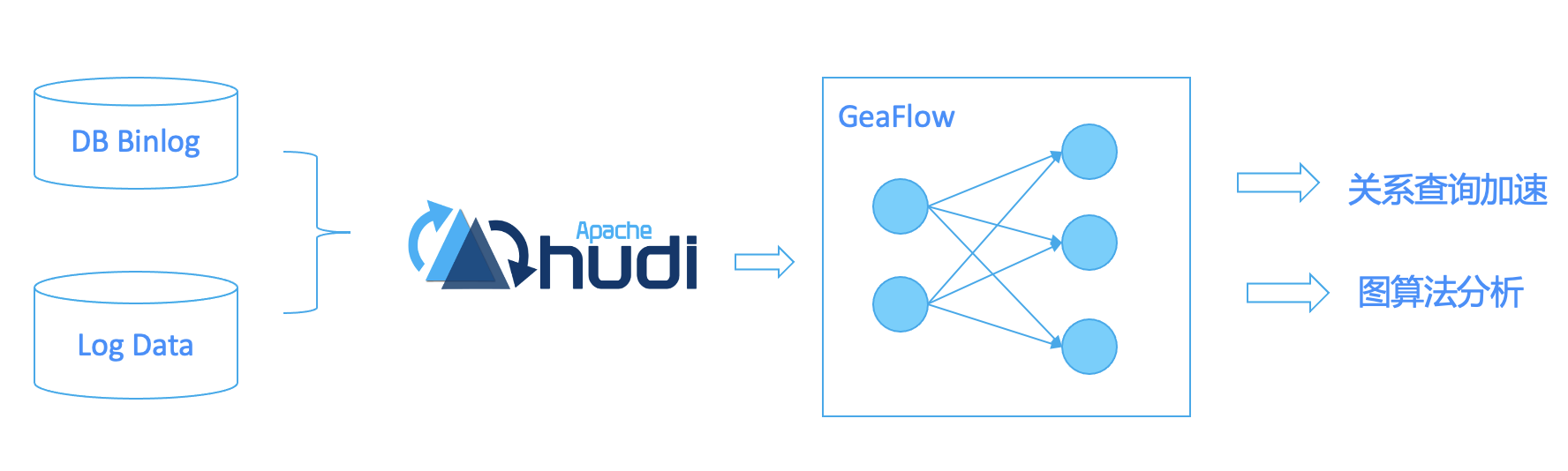
GeaFlow 和 Hudi 集成
GeaFlow(品牌名 TuGraph-Analytics)是蚂蚁自研的分布式实时图计算引擎,兼顾离线图计算能力。GeaFlow 以图模型作为基本的数据模型,在图模型基础之上定义了一套图计算的编程接口,同时和流式处理能力相结合,实现了流式图计算的能力。在 DSL 语言层面,GeaFlow 将表处理语言 SQL 和图查询语言 ISO/GQL 相结合,实现了图表一体的数据分析能力。通过 GeaFlow 图计算的能力,很好的解决了大规模数据关联关系计算的问题。Hudi 是业界热门的数据湖格式,旨在解决数据湖中数据的变更管理问题。Hudi 使用了一种基于日志的存储方式,可以支持数据的实时增量、删除和更新,并且能够保证数据的一致性和可靠性。Hudi 的核心思想是将数据划分成小的数据块,每个数据块都包含了数据的变更历史,可以通过增量方式和全量方式读取和写入数据。Hudi 支持多种数据格式,包括 Parquet、ORC、CSV 等,并且可以与 Hadoop、Spark、Flink 等大数据处理框架无缝集成,可用于数据湖的建设和数据管理。Hudi 的出现大大简化了数据湖的数据变更管理和数据处理流程,是一个非常优秀的数据管理框架。GeaFlow 支持和多种数据源集成,包括 Hudi。利用 GeaFlow 图计算的能力,可以对 Hudi 数据湖数据做关系物化,加速 DWD 层的查询性能和时效性,同时也可以基于图数据做更多复杂的图算法分析。
以下为 GeaFlow 使用 Hudi 构图,然后进行 4 度环路查找和 SSSP 算法计算的例子:
图定义
我们首先需要定义张图,使用 Create Graph 语法定义如下:
这张图定义包含点表 person 和边表 knows. 点表 person 定义了点的属性信息和 id 字段,id 字段唯一标识图里面的点,为点表的主键,通过 ID 关键字来定义。边表 knows 里面定义好友关系,srcId 为关系的起点,通过 SOURCE ID 关键字定义;targetId 为关系的目标点,通过 DESTINATION ID 关键字定义。weight 字段则为边的一个属性字段。一张图的点边或者边表可以包含零个或者多个属性字段。
Hudi 表定义
首先我们需要定义一张 Hudi 点表和 Hudi 边表:
GeaFlow 是一个流式图计算引擎,数据源按照 window size 切分成一系列的 window, 引擎会依次处理这些 window 的数据。如果 window size 设置为-1,则代表一个 All Window,即一次全量处理所有数据。对于 Hudi 这样的批数据源接口,需要设置 window size 为-1 来处理。
构图
构图是将外部数据表的数据写入到图里面,可以通过 Insert 语句来完成。如下语句,分布将 hudi 表里面的数据写入到 friend 图的 person 表和 knows 表里面,完成图数据的构建。
图计算
接下来是对构建好的图数据做图计算,我们以 SSSP(单源最短路径)和四度环路检查为例进行介绍:
首先需要定义一个结果表 result 来存放计算结果,然后通过 USE GRAPH 命令来设置当前计算用到的图。最后通过 CALL 语句来执行 SSSP 算法(其中 SSSP 算法的入参为起始点 id), 并将计算结果写入结果表。四度环路匹配如下语句,通过 Match 匹配一个 4 度环路的 pattern,然后将结果写出结果表.
总结
本文主要分析了表模型的现状和问题,然后介绍了图模型在处理关系运算上的优势,接着介绍了图计算引擎 GeaFlow 和数据湖格式 hudi 的整合,利用图计算引擎加速数据湖上的关系运算.
GeaFlow(品牌名 TuGraph-Analytics) 已正式开源,欢迎大家关注!!!
欢迎给我们 Star 哦!
Welcome to give us a Star!
GitHub👉https://github.com/TuGraph-family/tugraph-analytics
更多精彩内容,关注我们的博客 https://geaflow.github.io/

欢迎访问:geaflow.github.io 2023-07-05 加入
GeaFlow(品牌名TuGraph-Analytics) 是一个分布式流图计算引擎 欢迎给我们 Star 哦! GitHub👉github.com/TuGraph-family/tugraph-analytics 更多精彩内容,关注我们的博客geaflow.github.io









评论