
基于 Kubernetes 环境的高扩展机器学习部署利器——KServe

随着 ChatGPT 的发布,人们越来越难以回避利用机器学习的相关技术。从消息应用程序上的文本预测到智能门铃上的面部识别,机器学习(ML)几乎可以在我们今天使用的每一项技术中找到。
如何将机器学习技术交付给消费者是企业在开发过程中必须解决的众多挑战之一。机器学习产品的部署策略对产品的最终用户有重大影响。这可能意味着,iPhone 上的 Siri 和网络浏览器中的 ChatGPT 之间将存在重大差异。
除了 ChatGPT 流畅的用户界面和过于自信的聊天对话之外,还隐藏了部署大型语言机器学习模型所需的复杂机制。ChatGPT 建立在一个高度可扩展的框架上,该框架旨在当模型呈指数级被应用期间提供和支持该模型。事实上,实际的机器学习模型只占整个项目的一小部分。此类项目往往是跨学科的,需要数据工程、数据科学和软件开发方面的专业知识。因此,简化模型部署过程的框架在向生产交付模型方面变得越来越重要,因为这将有助于企业节省时间和金钱。
如果没有适当的运营框架来支持和管理 ML 模型,企业在试图扩大生产中机器学习模型的数量时往往会遇到瓶颈。
虽然在高度饱和的 MLOps 工具包市场上,没有一个工具能成为明显的赢家,但 KServe 正成为一个越来越受欢迎的工具,帮助企业满足机器学习模型的可扩展性要求。
一、什么是 KServe?
KServe 是一个用于 Kubernetes 的高度可扩展的机器学习部署工具包。它是一个构建在 Kubernetes 之上的编排工具,并利用了另外两个开源项目,Knative-Serving 和 Istio;稍后将对此进行详细介绍。

KServe 通过将部署统一到一个资源定义中,大大简化了机器学习模型在 Kubernetes 集群中的部署过程。它使机器学习部署成为任何机器学习项目的一部分,易于学习,并最终降低了进入壁垒。因此,使用 KServe 部署的模型比使用需要 Flask 或 FastAPI 服务的传统 Kubernetes 部署的模型更容易维护。
借助于 KServe,在使用 HTTPs 协议通过因特网公开模型之前,不需要将模型封装在 FastAPI 或 Flask 应用程序中。KServe 内置的功能基本上复制了这个过程,但不需要维护 API 端点、配置 pod 副本或配置 Kubernetes 上的内部路由网络。我们所要做的就是将 KServe 指向您的模型,然后由它来处理其余的部分。
除了简化部署过程之外,KServe 还提供了许多功能,包括金丝雀部署(译者注:这是一种流行的持续部署策略,其中将一小部分机队更新为应用程序的新版本)、推理自动缩放和请求批处理。这些功能将不会被讨论,因为它超出了本文的范围;然而,本文有望为进一步探索相关知识的理解奠定基础。
首先,我们来谈谈 KServe 附带的两个关键技术,Istio 和 Knative。
1、Istio
如果没有 Istio,KServe 带来的许多功能将很难实现。Istio 是一个服务网格,用于扩展部署在 Kubernetes 中的应用程序。它是一个专用的基础设施层,增加了可观察性、流量管理和安全性等功能。对于那些熟悉 Kubernetes 的人来说,Istio 将取代通常在 Kubernete 集群中找到的标准入口定义。
管理流量和维护可观察性的复杂性只会随着基于 Kubernetes 的系统的扩展而增加。Istio 最好的功能之一是集中控制服务级别的通信。这使开发人员能够对服务之间的通信进行更大的控制和透明度。
有了 Istio,开发人员不需要专门开发那些需要能够处理流量身份验证或授权的应用程序。最终,Istio 有助于降低已部署应用程序的复杂性,并使开发人员能够专注于应用程序的重要组件。
通过利用 Istio 的网络功能,KServe 能够带来包括金丝雀部署、推理图和自定义转换器在内的功能。
2、KNative
另一方面,KNative 是一个开源的企业级解决方案,用于构建无服务器和事件驱动的应用程序。Knative 构建在 Istio 之上,带来了类似于 AWS Lambdas 和 Azure Functions 提供的无服务器代码执行功能。Knative 是一个与平台无关的解决方案,用于在 Kubernetes 中运行无服务器部署。
KNative 最好的功能之一是可扩展到零的功能,当没有需求时,该功能会自动缩减部署。这是 KServe 扩大或缩小 ML 模型部署能力的一个关键组成部分,也是最大限度地提高资源利用率和节省成本的一个组成部分。
3、我应该使用 KServe 吗?
与许多其他工具一样,KServe 不是一个适合您的企业所要求的一刀切式的解决方案。它的入门成本很高,因为需要用户具备一些使用 Kubernetes 的经验。如果你刚开始使用 Kubernetes,网上有很多资源,我强烈建议你在 Youtube 上查看 DevOps(https://www.youtube.com/channel/UCFe9-V_rN9nLqVNiI8Yof3w)之类的资源。尽管如此,即使不深入了解 Kubernetes,也可以学习使用 KServe。
在已经利用 Kubernetes 的企业中,KServe 将是理想的选择,因为这些企业在使用 Kubernete 方面已经拥有现有的知识。它还可能适合那些希望放弃或补充 SageMaker 或 Azure 机器学习等托管服务的组织,以便对您的模型部署过程有更大的控制权。所有权的增加可以显著降低成本,并提高可配置性,以满足项目的特定要求。
尽管如此,正确的云基础设施决策将取决于具体情况,因为不同公司的基础设施要求不同。
二、预备知识
本文接下来将带您了解设置 KServe 所需的步骤。您将了解安装 KServe 并为您的第一个模型提供服务的步骤。
在继续之前,需要满足几个先决条件。您将需要准备以下内容:
lKuectl(https://kubernetes.io/docs/tasks/tools/)安装
lHelm(https://helm.sh/docs/intro/install/)安装
lKuectx(https://github.com/ahmetb/kubectx)安装(可选)
1、Kubernetes 集群
在本教程中,我建议使用 Kind 工具(https://kind.sigs.k8s.io/)对 Kubernetes 集群进行实验。它是一个运行本地 Kubernetes 集群的工具,无需启动云资源。此外,如果您在多个集群中工作,我强烈推荐把 Kuectx 作为一种工具,它能够帮助您在 Kubernetes 上下文之间轻松切换。
但是,在运行生产工作负载时,您需要访问功能齐全的 Kubernetes 集群来配置 DNS 和 HTTPS。
使用 Kind 工具部署 Kubernetes 集群的命令如下:
然后,您可以使用以下命令切换到正确的 Kubernetes 上下文:
2、安装
以下步骤将安装 Istio v1.16、Knative Serving v1.7.2 和 KServe v0.10.0。这些版本最适合本教程,因为 Knative v1.8 以后的版本将需要对入口进行 DNS 配置,这增加了一层超出目前范围的复杂性。
1)安装 Istio:
2)安装 KNative Serving:
3)安装证书管理器。需要证书管理器来管理 HTTPs 流量的有效证书。
4)为模型创建一个命名空间。
5)克隆 KServe 存储库。
6)将 KServe 定制资源定义和 KServe 运行时安装到集群中的模型命名空间中。
我们现在已经在集群上安装了 KServe。接下来,让我们开始部署吧!
三、第一个推理服务
为了确保部署顺利进行,让我们部署一个演示推理服务。您可以在链接https://kserve.github.io/website/0.10/get_started/first_isvc/#1-create-a-namespace处找到部署的完整源代码。
上面的 yaml 资源定义部署了一个测试推理服务,该服务来源于使用 SciKit 学习库训练的公开可用模型。KServe 支持许多不同风格的机器学习库(https://kserve.github.io/website/0.10/modelserving/v1beta1/serving_runtime/)。
其中包括 MLFlow、PyTorch 或 XGBoost 模型;每次发布时都会添加更多的类似支持。如果这些现成的库都不能满足您的要求,KServe 还支持自定义预测器(https://kserve.github.io/website/0.10/modelserving/v1beta1/custom/custom_model/)。
注意,您可以通过获取命名空间中的可用 pod 数量来监控当前部署的状态。

如果在部署中遇到问题,请使用以下方法进行调试:
我们还可以通过以下方式检查推理服务部署的状态:

如果推理服务被标记为 true,我们就可以执行我们的第一个预测了。
四、执行预测
为了进行预测,我们需要确定我们的 Kubernetes 集群是否在支持外部负载均衡器的环境中运行。
1、Kind 群集
值得注意的是,使用 Kind 部署的集群不支持外部负载均衡器;因此,您将拥有一个与下面类似的入口网关。

Kind 外部负载均衡器(图片由作者提供)
在这种情况下,我们必须转发 istio-ingressgateway,这将允许我们通过 localhost 访问它。
端口将 istio-ingress 网关服务转发到本地主机上的端口 8080,使用如下命令:
然后设置入口主机和端口:
2、Kubernetes 集群
如果外部 IP 有效且未显示<pending>,那么我们可以通过 IP 地址的互联网发送推理请求。

入口网关 IP 地址(图片由作者提供)
将入口主机和端口设置为:
3、进行推理
为推理请求准备一个输入请求 json 文件。
然后用 curl 命令进行推理:
该请求将通过 istio-ingress 网关发送到 KServe 部署。如果一切正常,我们将从推理服务中获得一个 json 回复,其中每个实例的预测值为[1,1]。

五、零扩展
通过利用 KNative 的功能,KServe 支持零扩展功能。该功能通过将未使用的 pod 扩展为零,从而有效地管理集群中有限的资源。将功能扩展到零允许创建一个响应请求的反应式系统,而不是一个始终处于运行状态的系统。这将有助于在集群中部署比传统部署配置更多的模型。
然而,请注意,对于已经缩小扩展的 pod 副本,存在一个冷启动“处罚”。“处罚”程度将根据图像/模型的大小和可用的集群资源而变化。如果集群需要扩展额外的节点,冷启动可能需要 5 分钟,如果模型已经缓存在节点上,则需要 10 秒。
让我们修改现有的 scikit-learn 推理服务,并通过定义 minReplicas:0 来启用零扩展(scale to zero)功能。
复制
通过将 minReplicas 设置为 0,这将命令 Knative 在没有 HTTP 流量时将推理服务缩减为零。你会注意到,30 秒后,Sklearn 鸢尾花模型的 pod 副本将缩小。
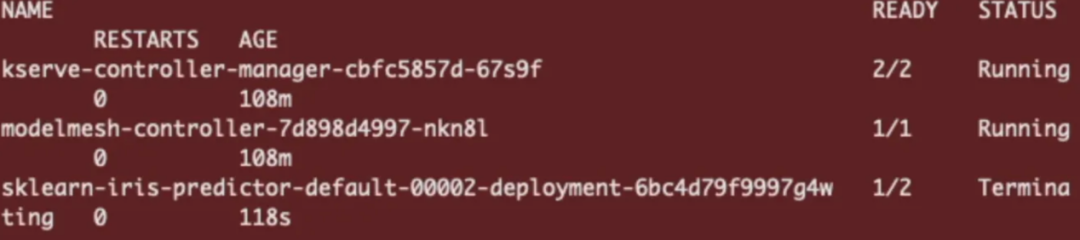
Sklearn 鸢尾花预测因子降到零
若要重新初始化推理服务,请向同一个端点发送预测请求。
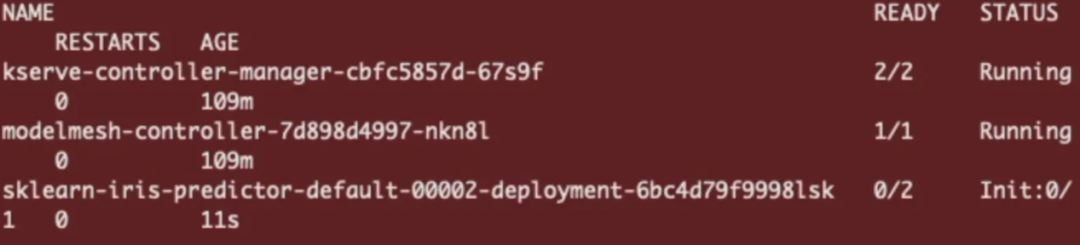
这将从冷启动触发 pod 副本初始化并返回预测。
六、结论
总体来看,KServe 能够简化机器学习部署过程,缩短生产路径。当与 Knative 和 Istio 相结合时,KServe 还有一个额外的好处,那就是高度可定制,并带来了许多可以轻松与托管云解决方案相媲美的功能。
当然,在内部迁移模型部署过程存在其固有的复杂性。然而,平台所有权的增加将在满足项目特定要求方面提供更大的灵活性。凭借正确的 Kubernetes 专业知识,KServe 可以成为一个强大的工具,使企业能够轻松地在任何云提供商中扩展其机器学习部署,以满足日益增长的需求。
版权声明: 本文为 InfoQ 作者【高端章鱼哥】的原创文章。
原文链接:【http://xie.infoq.cn/article/86967da1038f1f0091a203c88】。
本文遵守【CC-BY 4.0】协议,转载请保留原文出处及本版权声明。

还未添加个人签名 2023-06-19 加入
还未添加个人简介









评论