
对比开源丨 Prometheus 服务多场景存储压测全解析
作者: 智真
在 Gartner 发布的 **《2023 年十大战略技术趋势》 [ 1] **报告中,「应用可观测性」再次成为热门趋势。用户需要建立可观测体系来统筹、整合企业数字化所产生的指标数据,并以此为基础进行反馈并制定决策,这对于提高组织决策有效性和及时性,将是最强有力的支撑。
新需求带来新革命,Prometheus 产品应运而生,引领新一轮可观测技术革命。得益于良好的产品设计,Prometheus 部署与轻度使用体验非常流畅:敲两三个命令就能运行起来,配置几行 yaml 就能收集数据,编辑一个规则就能触发告警,再配合上 Grafana,写一句 PromQL 就能画出趋势图表。一切简单而美好,仿佛 SRE 光明的未来正向我们招手,这一切来的太突然,它真的如此轻易么?
当然不是。
Prometheus 用良好的用户接口掩盖了内部复杂实现。深入其中,我们会看到时序数据存储、大规模数据采集、时间线高基数、数据搅动、长周期查询、历史数据归档等等。像潜藏在宁静湖面下磨牙吮血的鳄鱼,静待不小心掉进坑中的 SRE 们。
客观的讲,这些问题早已存在,并不是 Prometheus 带来的。云原生的到来让这些问题变得更显著且难以回避。想解决这些问题,需要投入大量人力、物力和精力。作为国内领先的云服务提供商,阿里云提供了优秀的可观测全套解决方案,阿里云 Prometheus 服务正是其中重要一环,相比于开源版本 Prometheus,阿里云的 Prometheus 服务无论是易用性、扩展性、性能均有大幅度提升。 今天,我们将结合企业日常运维过程中常见疑难场景,将两者存储能力进行对比。
测前概念解读
在开始前,我们先阐述测试过程中涉及的问题与概念。
1.时间线(Time Series)
时间线的概念在 Prometheus 中非常重要,它表示一组不相同的 label/value 的集合。比如 temperature{city="BJ",country="CN"} 和 temperature{city="SH",country="CN"}就是两条不同的时间线。
因为其中的 city 这个 label 对应的值不同;temperature{city="BJ",country="CN"}和 humidity{city="BJ",country="CN"} 也是两条不相同的时间线,因为在 Prometheus 中,指标名称也对应一个特殊的 label name。时间线中的 label 会被索引以加速查询,所以时间线越多存储压力越大。
2.时间线高基数(High Cardinality)
如果指标设计不合理,label 取值范围宽泛,如 URL,订单号,哈希值等,会造成写入的时间线数量难以预估,会发生爆炸式增长,为采集、存储带来巨大挑战。对于这种情况,我们称之为时间线高基数或者时间线爆炸。时间线基数过高带来的影响是全方位的,如采集压力大,网络和磁盘 IO 压力大,存储成本上升,查询响应迟缓等。
高基数场景常见应对思路有两种:依靠时序存储本身的能力,或更优秀的架构来硬抗压力;或使用预聚合/预计算等手段来主动降低基数。阿里云 Prometheus 在两方面都进行了很多优化和增强,但开源版本中并没有提供完整预聚合/预计算功能,所以此次测试中不会涉及到预聚合/预计算。
3.高搅动率(High Churn Rate)
高搅动率是高基数的特殊场景之一,如果时间线的“寿命”很短,经常被汰换,这种场景我们称之为高搅动率。比如 k8s 场景下,deployment 每次创建新的 pod 时,都会产生新 pod name,即旧 pod 相关时间线被淘汰,新 pod 相关时间线被产生出来。如果经常性发生重启(或类似场景),那么可能从某个时间点来看,时间线并不多,但在较长时间范围来看,时间线总量可能就很庞大。换句话说,在高搅动率场景下,“活跃”的时间线不一定很多,但累积时间线总数非常庞大,所以对时间跨度较大的查询影响尤其严重。
阿里云 Prometheus 服务与开源版本 Prometheus 能力对比↓

Prometheus 官方提供**兼容性测试工具 [ 2] **,阿里云 Prometheus 服务在最主要的 PromQL 测试类别中,**兼容性为 97.06% [ 3] 且无需使用 tweak,综合表现优于 AWS 和 GCP [ 4] **。
测试场景
测试工具和测试数据计算
1.测试环境
本次测试使用的 Prometheus 版本为 2.40.1,即截至 2022-12-20 的最新开源版本。阿里云 Prometheus 服务和部署开源 Prometheus 使用的 ECS 均位于阿里云张家口 Region。
2.测试工具
我们使用 VictoriaMetrics 提供的 **prometheus-benchmark [ 5] **来执行此次测试,在使用过程中我们也发现了此工具存在不支持 query_range 测试,churn 逻辑错误等问题,所以我们进行了 Bug 修复和功能增强,为了保证测试透明及可参考性,**项目存放在 GitHub 上 [ 6] **。测试工具的整体架构如下图:
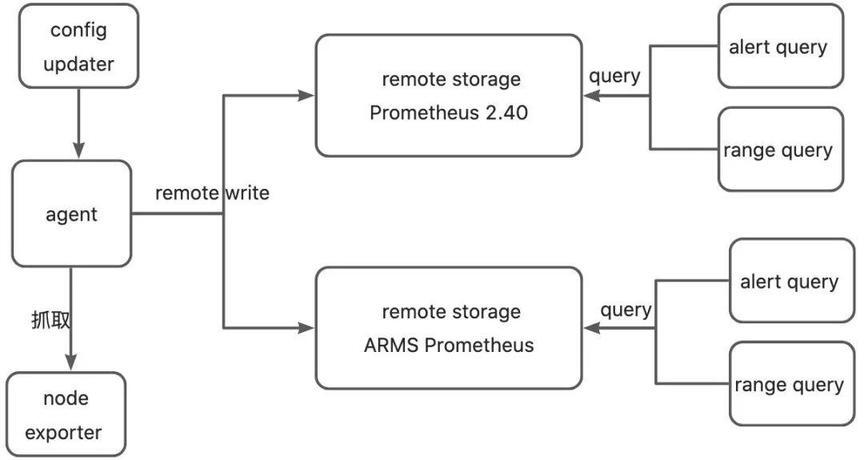
3.测试条件设置
默认使用 node exporter 作为指标数据源,node exporter 产生的时间线数量和物理机器有关,比如 CPU 相关指标和机器核数有关系,FileSystem 相关指标和实际挂载的文件系统数量有关,而运行 pod 较多的机器,挂载的文件系统也会更多。在施压集群机器节点上,我们将单个 node exporter 实际产出的时间线数量控制在(680±5)之间,后续的测试估算中,我们按照 680 per node exporter 的标准来估算。
agent 通过定义多个 static config 抓取同一个 node exporter,同时将 instance 字段 relabel 成 host-idx 的方式,模拟出多个数据源,并写入到 remote storage 中。config updater 组件定时更新 static config 按比率调整 relabel 字段,模拟出时间线搅动场景。
如果将采集周期定义为 10 秒钟,target 数量为 100,那么每秒钟产生的采样点数量,约为(680 x 100) / 10 = 6800 个/秒;如果再将搅动率参数设置为每 10 分钟汰换 10%,那么原始时间线数量为 100 x 680 = 68k,每小时新增的时间线数量为 100x0.1x(60/10)x680 = 41k。
通过两个 query 组件我们可以周期性的发起查询请求,其中 alert query 默认每次发起 33 个告警查询,持续时间基本都在 5 分钟以内;range query 默认每次发起 32 个 range 查询,时间跨度包括 1 小时、3 小时、6 小时、24 小时。
4.测试工具使用
测试工具使用需要两个前提条件:1,所在机器能联通到 k8s 集群;2,机器上安装 helm。编辑 chart/values.yaml 文件,修改其中 remoteStorages 等配置;编辑 chart/files 中 alerts.yaml 和 range_query.yaml,作为带发起的告警查询和范围查询;调整 Makefile 中的 namespace 等配置,使用 make install 安装部署,即可从数据源采集数据并写入到 remoteStorages 中,同时按照配置的频率发起查询。
同时在部署的 pod 上,默认增加了 Prometheus 采集的相关 annotation,如果集群中已经安装了阿里云 Prometheus,会自动采集测试工具的相关指标数据,包括写入速率、写入采样点数量、查询速率、查询成功数量、查询耗时等。
小型集群告警查询场景
集群预设:
集群设置 100 个 target,约等于一个普通的小型 k8s 集群,每秒写入数据为 (100x680)/10 = 6.8k 个采样点,原始时间线为 100x680 = 68k 条,每小时汰换 1% 的 target,即每小时新增 100x680x0.01=680 条时间线,四舍五入约等于零。
查询组件每 3 秒钟发起一批,共计 31 个告警查询,查询时间跨度 2~5 分钟不等。
环境部署:
开源 Prometheus 部署在一套 4C32G 200G SSD 阿里云资源上。
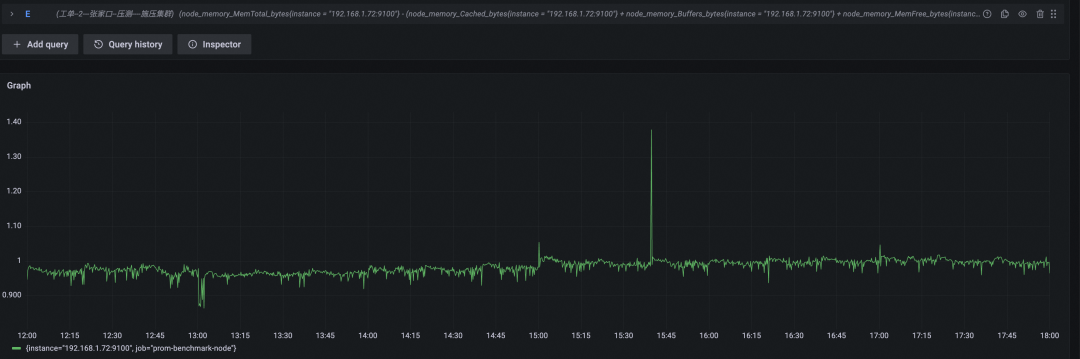
开源 Prometheus 资源使用情况
内存使用(GB)
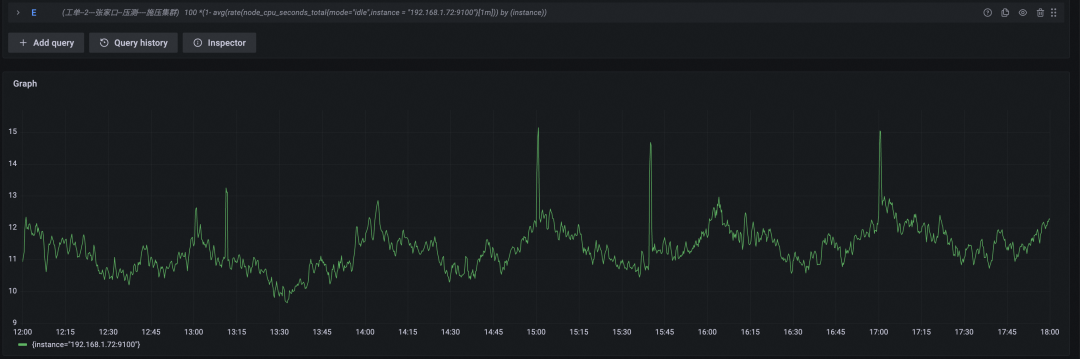
CPU 使用率百分比
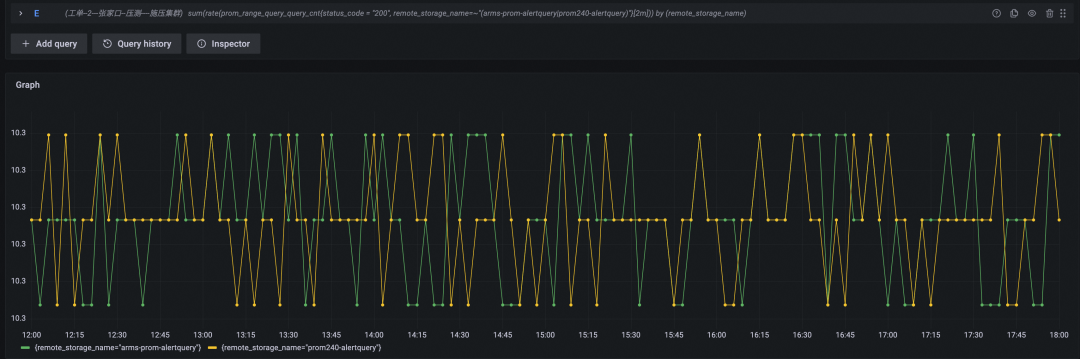
性能表现对比
查询 QPS(黄色为开源 Prometheus 数据曲线,绿色为阿里云 Prometheus 服务数据曲线)
查询耗时(黄色为开源 Prometheus 数据曲线,绿色为阿里云 Prometheus 服务数据曲线)

写入速率对比(KB/s,黄色为开源 Prometheus 数据曲线,绿色为阿里云 Prometheus 服务数据曲线)

测试结论
在这种基础场景下,开源 Prometheus 在六小时的测试期间表现稳定,资源消耗较低,响应速度也能让人满意。
小型集群范围查询场景
经历了第一场热身,双方表现势均力敌。于是我们升级测试项目,增加范围查询场景,尤其在 Prometheus+Grafana 中,大部分都是范围查询。
集群预设:
集群设置 100 个 target,抓取周期为 10s,每小时 1% 的汰换率。
每五秒钟发起一批范围查询,查询跨度统一为 3 小时,查询频率为每 5 秒发起一批,每批 50 条查询语句,超时时间 30 秒钟。
环境部署:
开源 Prometheus 部署在一套 4C32G 200G SSD 阿里云资源上。
开源 Prometheus 资源使用
内存使用(GB)
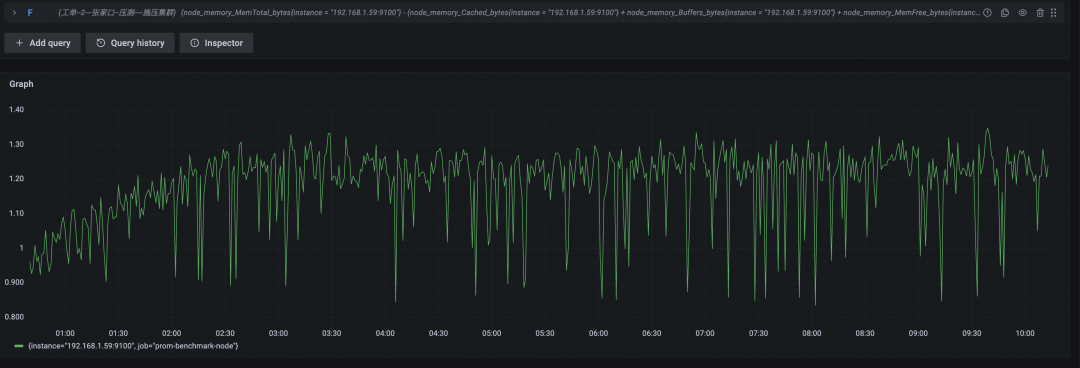
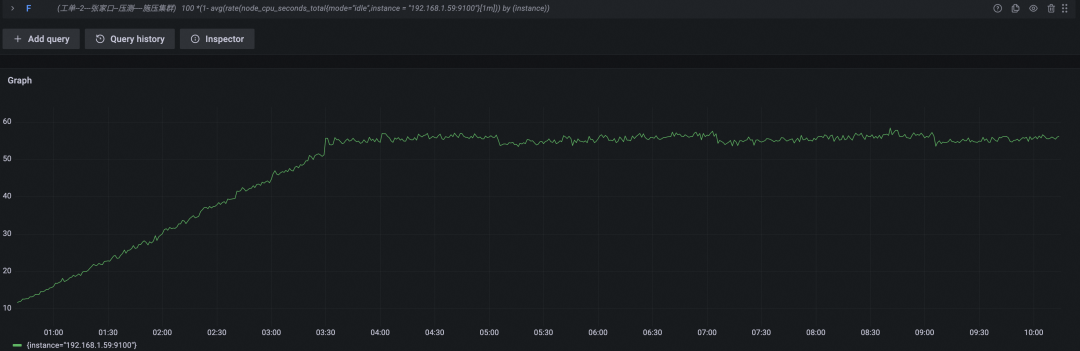
CPU 使用率百分比
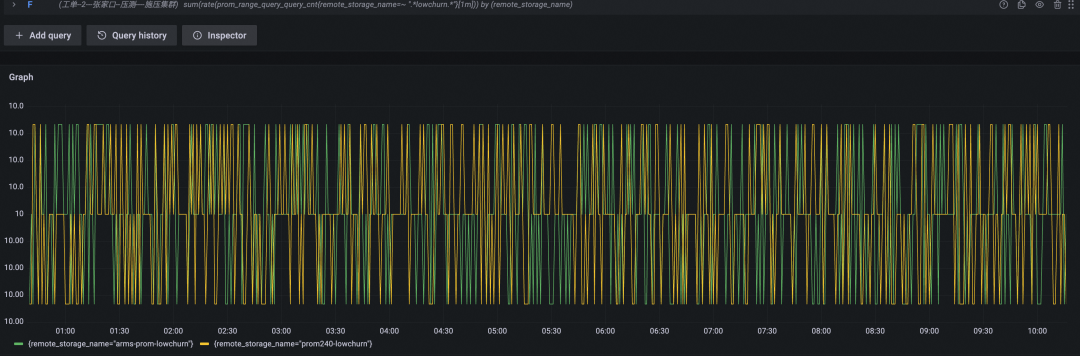
性能表现对比
查询 QPS(黄色为开源 Prometheus 数据曲线,绿色为阿里云 Prometheus 服务数据曲线)
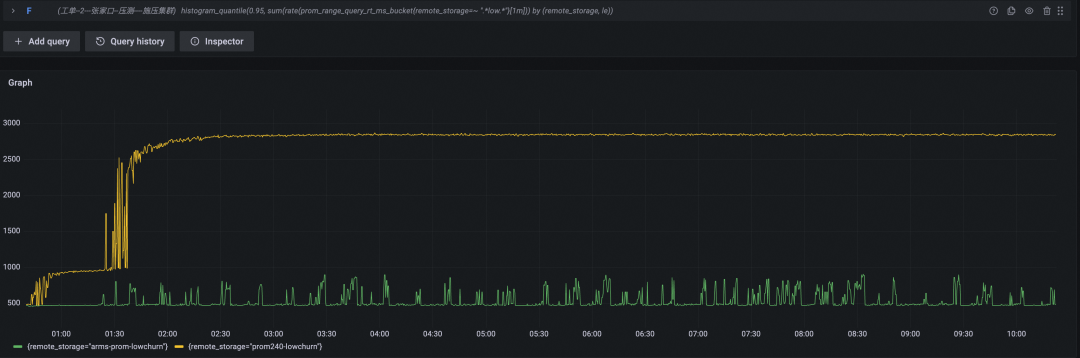
查询耗时(P95,黄色为开源 Prometheus 数据曲线,绿色为阿里云 Prometheus 服务数据曲线)
数据写入速率(KB/s,黄色为开源 Prometheus 数据曲线,绿色为阿里云 Prometheus 服务数据曲线)
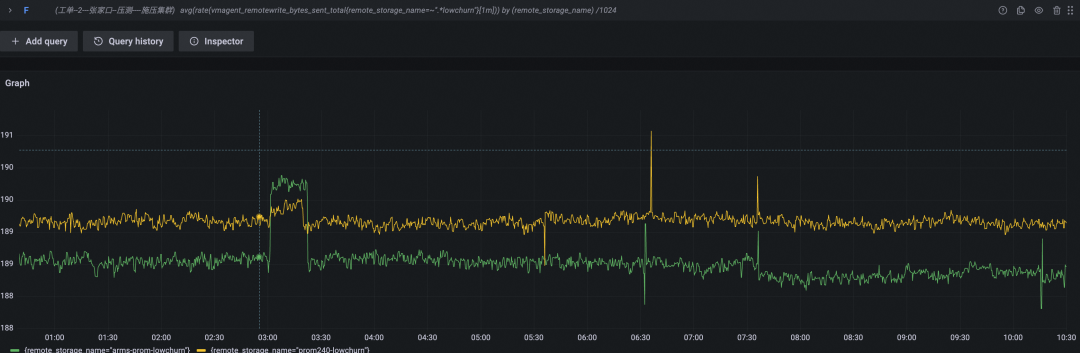
测试结论
相比上一轮,本轮测试数据采集量并没有变化,总数据量基本一致,开源 Prometheus 内存使用同样是持平状态。但我们增加范围查询后,CPU 使用量发生明显变化,长时间持续在 60% 水位,按照 node exporter 默认告警规则,节点 CPU 使用率瞬时值达到 80% 即可触发告警,开源 Prometheus 节点的 CPU 使用率已逼近需要关注水位。
在测试开始后约三个小时(0:30 - 3:30),开源 Prometheus 的 CPU 使用率即达到 60%,根据测试场景预设条件我们可以计算出此时时间线数量和收集的采样点数量。时间线数量约为 100x680 + 3x100x680x0.01 = 70k,采样点数量(3x3600/10)x100x680=7kw,单个采样点长度约 256B,数据压缩率 8%,所以数据文件大小约为 7kwx256Bx0.08/1024/1024=1434M,这个数据量并不大,同时时间线变化很少。
发起的范围查询请求 QPS=10,一般打开一个 Grafana dashboard 时同时发起的查询都在 20~50 左右(不过因为浏览器的限制,这些查询并不是真正的同时发起),再考虑到大盘的定时刷新功能和同时打开多个大盘的情况,这个 QPS 在日常使用中是可以比较容易达到的,但依然使开源 Prometheus 的 CPU 消耗飙升。
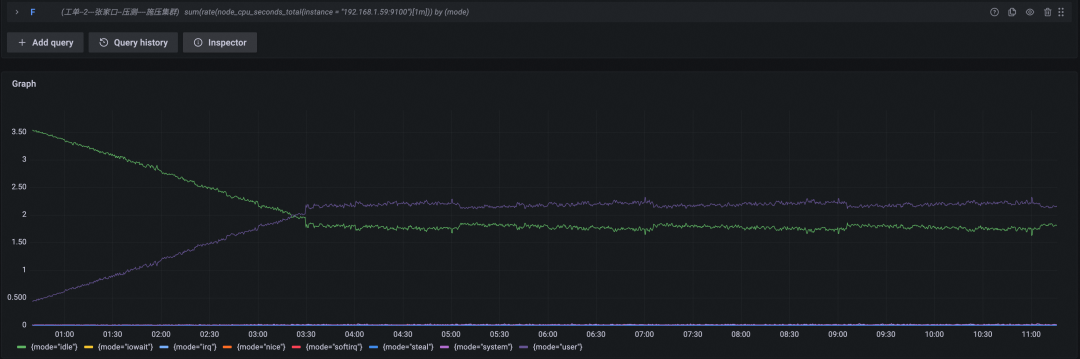
究其原因,我们认为开源 Prometheus 存在两个问题,一是响应时间较长的问题,因为开源 Prometheus 默认只支持 10 个查询并发,大概率会出现请求等待情况,延长的响应时间(但也拉平了 CPU 压力);另一个 CPU 使用率较高问题,我们查看开源版本 Prometheus CPU 使用情况(如下图),大量 CPU 消耗在用户进程上,PromQL 查询中需要对采样点进行各种切分与计算,从而产生大量数值计算,确实很容易把 CPU 打高。同时,开源 Prometheus engine 是单线程处理数据,可以视为要将每个采样点“捋一遍”,这种串行化的处理方式,也是其响应时间远逊于阿里云 Prometheus 服务的原因之一。
小型集群高搅动率场景
在前两轮测试中,我们预设场景都是比较理想的稳定集群,时间线汰换率非常低。实际场景往往没有这么理想,往往因为各种原因产生大量时间线,比如指标设计不合理、pod 频繁重启等。这一轮测试中,我们预设场景就是一个非常不稳定的集群,target 频繁汰换,考验下开源 Prometheus 和阿里云 Prometheus 服务在这种场景下表现如何。
集群设置:
模拟 100 个 node exporter 作为 target,依然是一个小规模 k8s 集群的量级,每十秒钟抓取一次,即写入速率依然为 6.8k/秒。原始时间线数量 680x100 = 680k,搅动率设置为十分钟汰换 99%,即每十分钟会重新产生 680x100 = 68k 时间线,每小时会新产生约 41 万时间线。
每 10 秒钟发起一批 range query,使用测试工具中默认的 32 条 range query,查询时间范围从 1h~24h 不等,查询超时时间为 30 秒。
环境部署:
开源 Prometheus 部署机器配置为 4C32G 200G SSD。
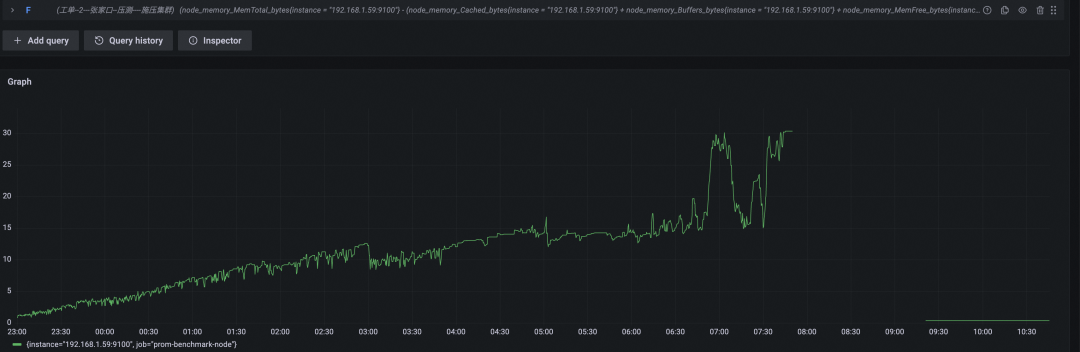
开源 Prometheus 资源使用情况
内存使用(GB)
CPU 使用率百分比

性能表现对比
查询 QPS(黄色为开源 Prometheus 数据曲线,绿色为阿里云 Prometheus 服务数据曲线)
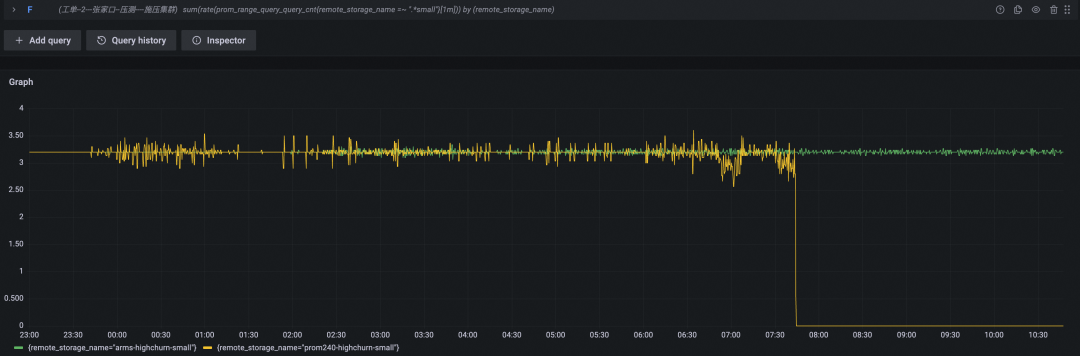
查询耗时(P95,黄色为开源 Prometheus 数据曲线,绿色为阿里云 Prometheus 服务数据曲线)
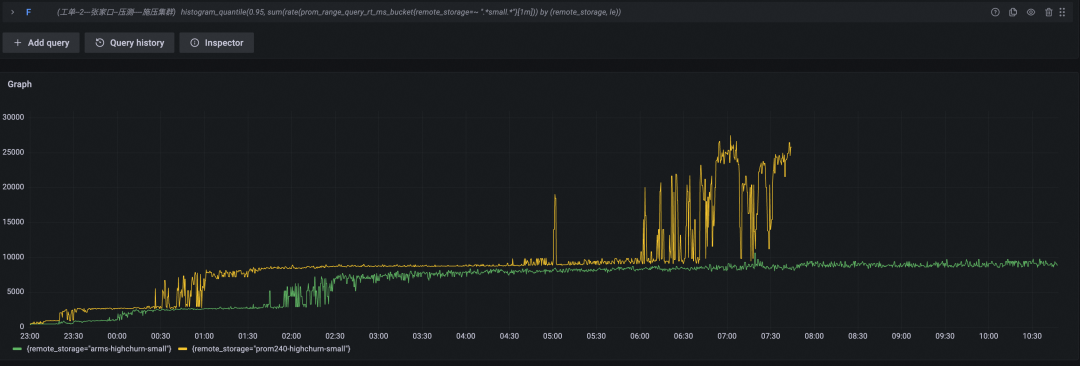
数据写入速率(Byte/s,黄色为开源 Prometheus 数据曲线,绿色为阿里云 Prometheus 服务数据曲线)
测试结论
搅动率较高时,开源 Prometheus 表现非常勉强,内存与 CPU 使用量呈现线性上涨,在坚持了八个多小时之后,机器无响应,直至被 OS kill 掉。
根据测试场景预设,我们可以大致计算下时间线总量,其中初始时间线数量 680x100 = 68000,每小时新增时间线数量 680x100x6x8 = 326w,总量相加一共计 333w。也就是说一台 4C32G 机器,最多只能承受 333w 时间线,实际应用中我们必然需要保留余量,如果按照 50% 水位作为警戒线,约只能承担 333 万 x 50% = 165 万 时间线。此外,考虑到实际应用中,数据保存时间少则半个月,多则半年一年,长时间数据存储也会带来额外内存压力,所以一旦总时间线数量达到 100w 时,就应当提高警惕,小心应对了。
作为对比,在我们截图的时刻,阿里云 Prometheus 服务已经写入了 680x100 + 680x100x6x12 = 4964000 即约 500w 时间线,写入和查询的表现依然稳定。
中型集群高搅动率场景
经历过前面三轮比对,我们对开源 Prometheus 的性能表现有了一定了解:单纯写入性能较好,查询很吃 CPU,时间线数量对性能影响很大,内存消耗会成倍上升,CPU 开销也会暴涨。
面对性能瓶颈,最直接最简单的想法就是垂直扩容,换句话就是告诉老板加机器。加机器就能解决的问题都有一个隐含的前提条件:资源增长是线性的。如果资源是指数增长,那加机器就是一个无底洞:增加十倍的硬件投入,只能提升一倍的性能,这种情况下还走垂直扩容的路子,只能是为硬件厂商打工。
在这一轮测试中,我们提升了开源 Prometheus 的硬件机器规格,使用一台 16C64G 200GSSD 的机器来应对高搅动率场景。
集群设置:
模拟一个中型规模的 k8s 集群,500 个 target,每 10 秒钟抓取一轮,每十分钟汰换 99% 的 target,所以初始时间线数量为 680x500 = 34w,每小时新增时间线数量为 680x500x0.99x6 = 2019600 即每小时新增时间线数量为 200w。
查询请求方面,依然使用工具集中默认的 32 条范围查询,但发起查询的间隔扩大为 30s,查询超时时间依然设置为 30s。
环境部署:
开源 Prometheus 部署机器配置为 16C64G 200GSSD。
开源 Prometheus 资源使用
内存使用(GB)
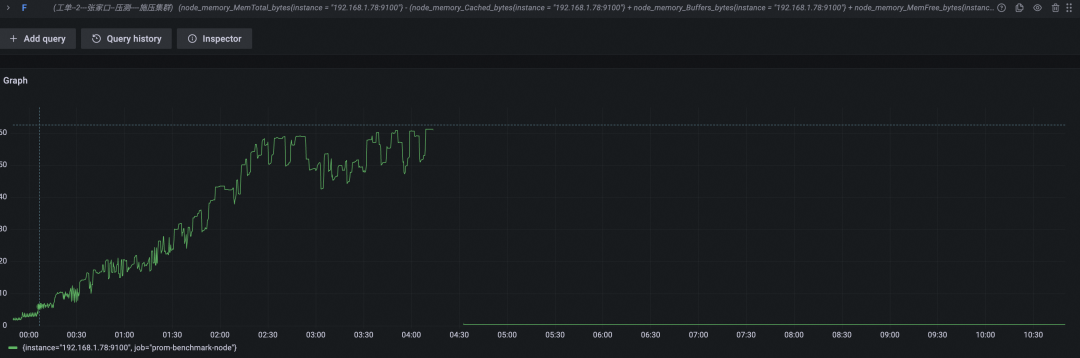
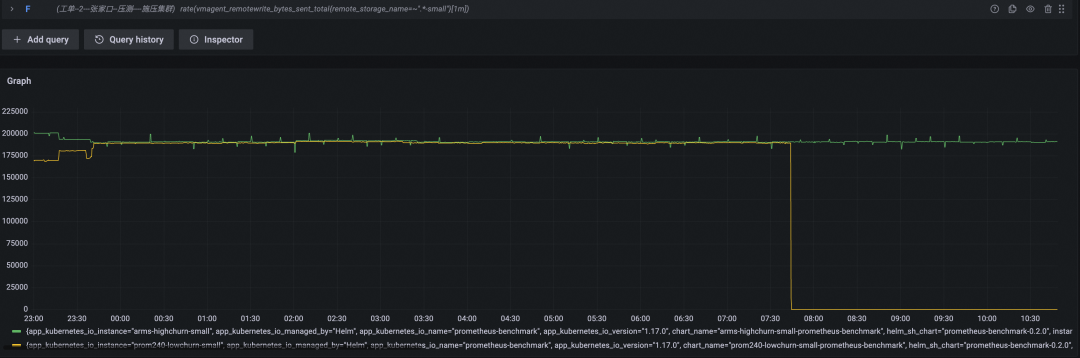
CPU 使用率百分比
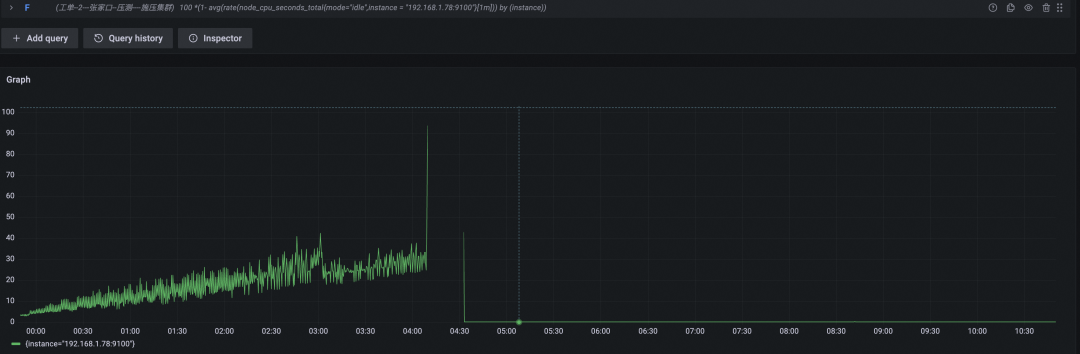
性能表现对比
查询 QPS(黄色为开源 Prometheus 数据曲线,绿色为阿里云 Prometheus 服务数据曲线)
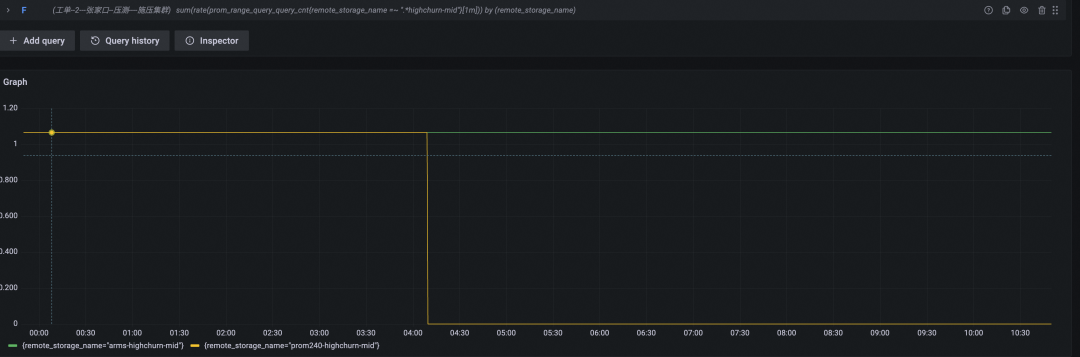
查询耗时(P95,黄色为开源 Prometheus 数据曲线,绿色为阿里云 Prometheus 服务数据曲线)

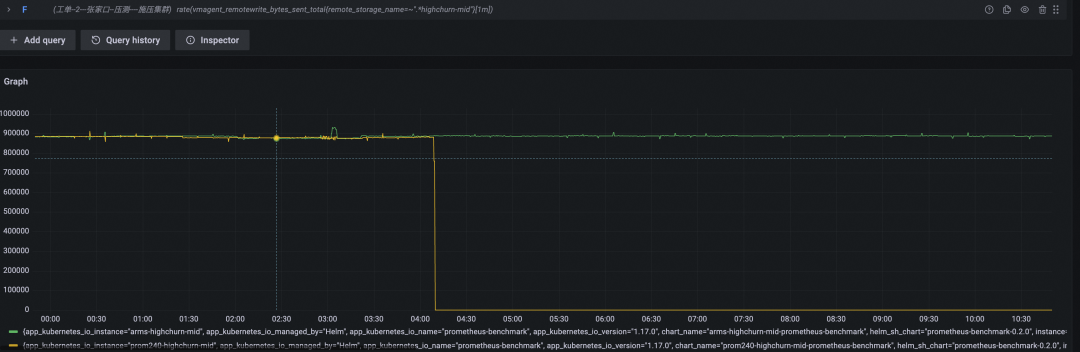
数据写入速率(Byte/s,黄色为开源 Prometheus 数据曲线,绿色为阿里云 Prometheus 服务数据曲线)
测试结论
开源 Prometheus 在坚持四个小时后终于倒下,总计写入的时间线约为 34w + 200w x 4 = 834w。我们将硬件资源提升了四倍,但实际承载的时间线总数只提升了 834w / 333w = 2.5 倍。显然,时间线高基数,对 Prometheus 性能的影响是非线性的,即时间线基数越高,单位资源能承载的平均时间线数量越少。越大规模集群,堆硬件越不划算。
细心的 SRE 们观察到了另一个现象:相较于小型集群的高搅动率场景,这一轮的查询 QPS 下降到了 1/s,而 CPU 资源也没有像上次一样与内存几乎同步耗尽,而是在达到了 40% 的时候,因为内存耗尽导致机器无响应,也凸显了 PromQL 查询对 CPU 的消耗严重性。
开源 Prometheus 倒下后,阿里云 Prometheus 服务并没有停步,最终在测试期间,已经吞下了 34w + 200w x 12 = 1434w 条时间线,依托于云服务无限扩展的特性,对于用户来说,阿里云 Prometheus 服务的承载能力也可以认为是一个“无底洞”,借助各种弹性策略及发现读/写瓶颈时自动水平扩展等手段,保证服务质量。
大型集群高搅动率场景测试
从上一轮的测试中,我们几乎能确定基数较高时,开源 Prometheus 的资源消耗是指数级上升的,所以使用硬件配置更好的机器,承载能力不可能有成倍的提升。我们将在这一轮测试中尝试证实或证伪这个推论。在这一轮测试中,我们基本沿用了上一轮设置。
集群设置:
target 总数涨到 2000 个。初始时间线数量 680 x 2000 = 136w,每小时新增时间线数量为 680 x2000 x0.99 x6 = 807w。其他配置保持不变。
环境部署:
开源 Prometheus 部署机器配置为 64C 256G。
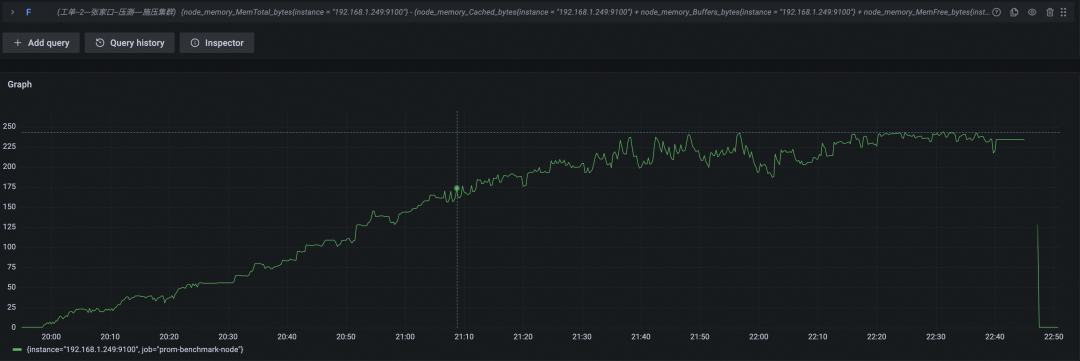
开源 Prometheus 资源使用
内存使用(GB)
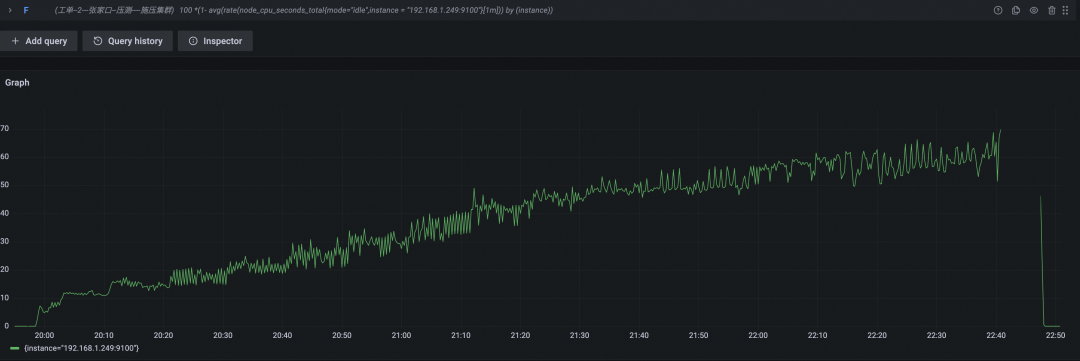
CPU 使用率百分比
性能表现对比
查询 QPS(黄色为开源 Prometheus 数据曲线,绿色为阿里云 Prometheus 服务数据曲线)
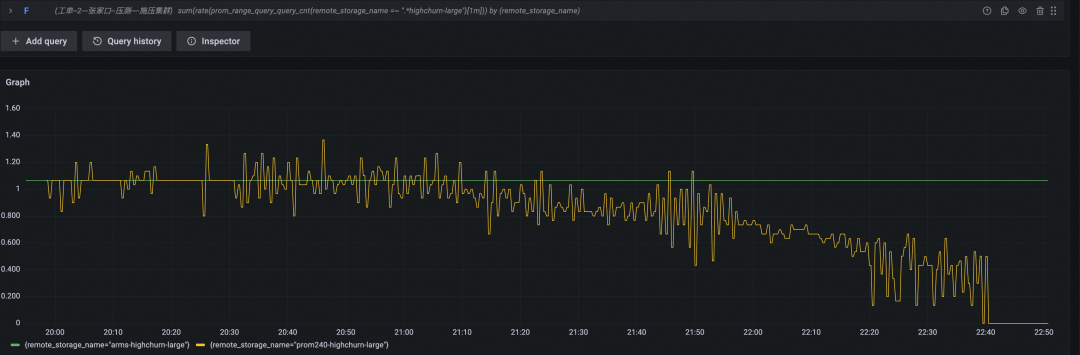
查询耗时(P95,黄色为开源 Prometheus 数据曲线,绿色为阿里云 Prometheus 服务数据曲线)
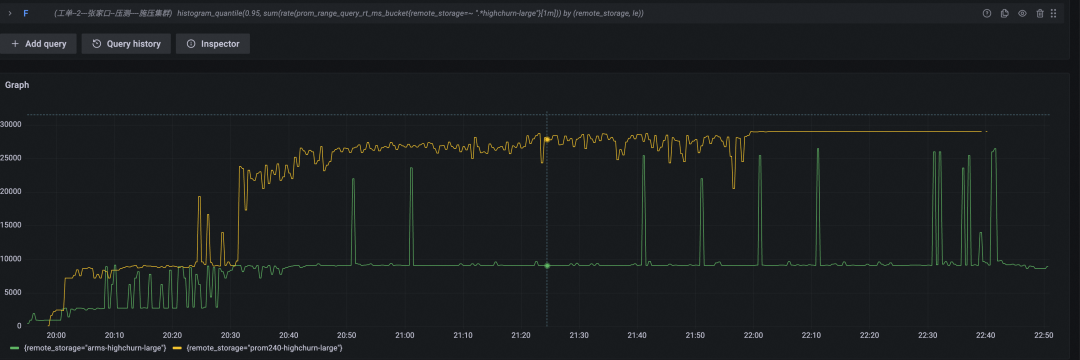
数据写入速率(Byte/s,黄色为开源 Prometheus 数据曲线,绿色为阿里云 Prometheus 服务数据曲线)
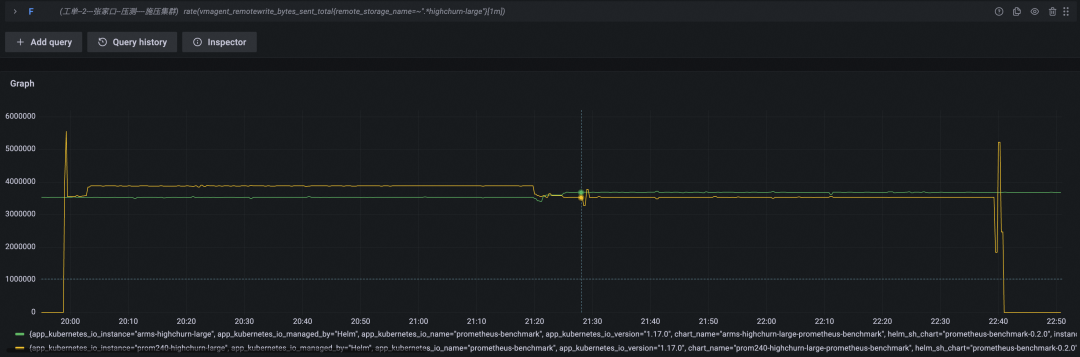
测试结论
本轮中开源 Prometheus 一共坚持了约两小时四十分钟,写入时间线总数为 136w + 800w x 2.67 = 2300w,对比上一轮,在硬件扩容四倍的情况下,实际支撑能力扩大了 2300w /834w = 2.75 倍。进一步印证了其性能消耗非线性增长的结论。
长周期查询场景测试
前面几轮的测试中,我们着重比较了高搅动率/时间线爆炸场景下,开源 Prometheus 和阿里云 Prometheus 服务的性能表现,阿里云 Prometheus 服务对时间线的承载能力远高于开源版本。在日常使用中,另一个经常遇到的,容易触及 Prometheus 性能边界的场景就是长周期查询。较大的查询时间跨度,一方面需要加载更多的时间线和采样点数据,另一方面计算量也会跟着翻倍,直接把 IO/内存/CPU 三大项全都考验了一遍。
因为开源 Prometheus 不接受数据乱序写入,所以这一轮的测试中,我们提前进行了一周时间的数据准备,我们使用 ksm(kube state metrics)作为数据源,模拟了 120 个 ksm,因为测试集群规模较小,单个 ksm 暴露的时间线数量约为 2500,所以总时间线数量为 2500 * 120 = 30w。采集间隔为 30s,所以每月产生的指标总量约为(30w/30) 60602430 = 260 亿,每周产生的指标总量约为(30w/30) 6060247 = 60 亿。
测试集群继续沿用了之前的 64C 256G 高配机器。
五天数据查询
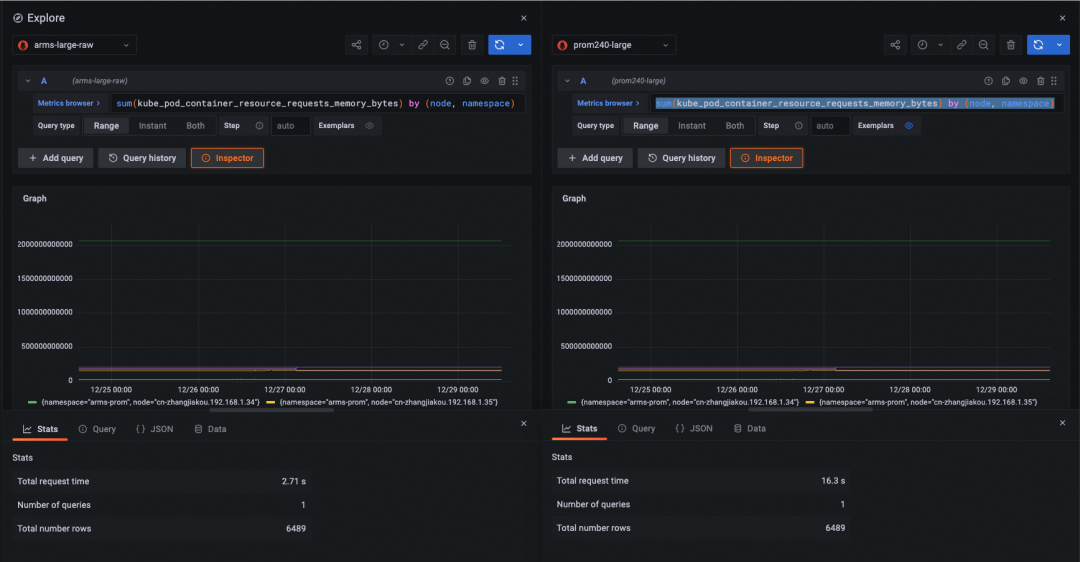
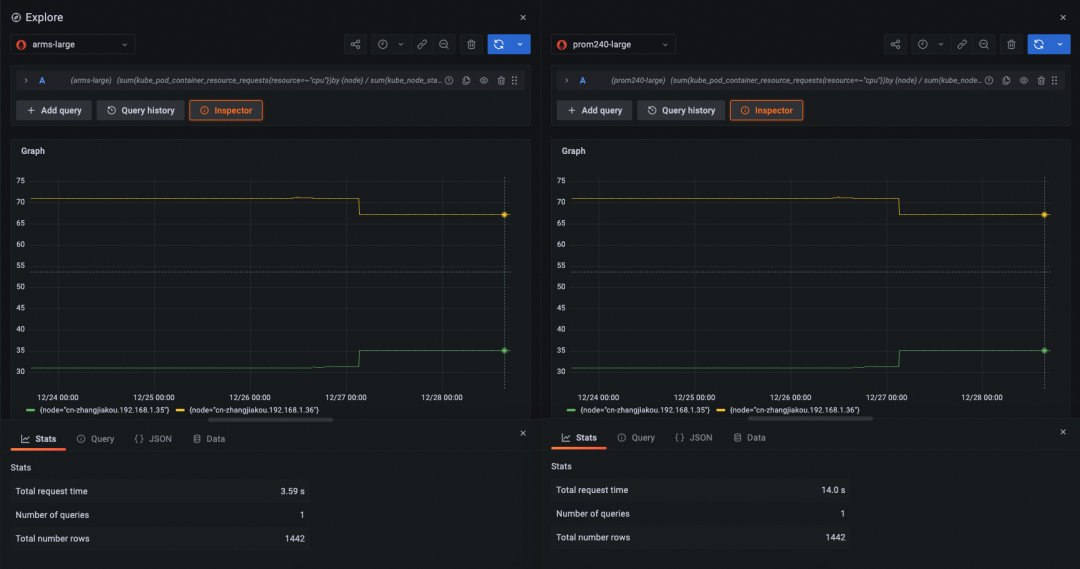
查询语句:sum(kube_pod_container_resource_requests_memory_bytes) by (node, namespace)
查询时间跨度:now - 5d ~ now
查询 step:10m(页面默认)
查询耗时:2.71s(阿里云 Prometheus 服务) 16.3s(开源 Prometheus)
查询语句:(sum(kube_pod_container_resource_requests{resource=~"cpu"})by (node) / sum(kube_node_status_allocatable{resource=~"cpu"})by (node) ) * 100 > 30
查询时间跨度:now -6d ~ now - 1d
查询 step:10m(页面默认)
查询耗时:3.59s(阿里云 Prometheus 服务) 14.0s(开源 Prometheus)
七天跨度批量查询
更多的时候,我们会是在 Grafana dashboard 上发起 Prometheus 查询,一个 dashboard 上会同时发起 20 到 30 个查询。多个查询同时处理时,开源 Prometheus 和阿里云 Prometheus 服务的表现又将如何呢?
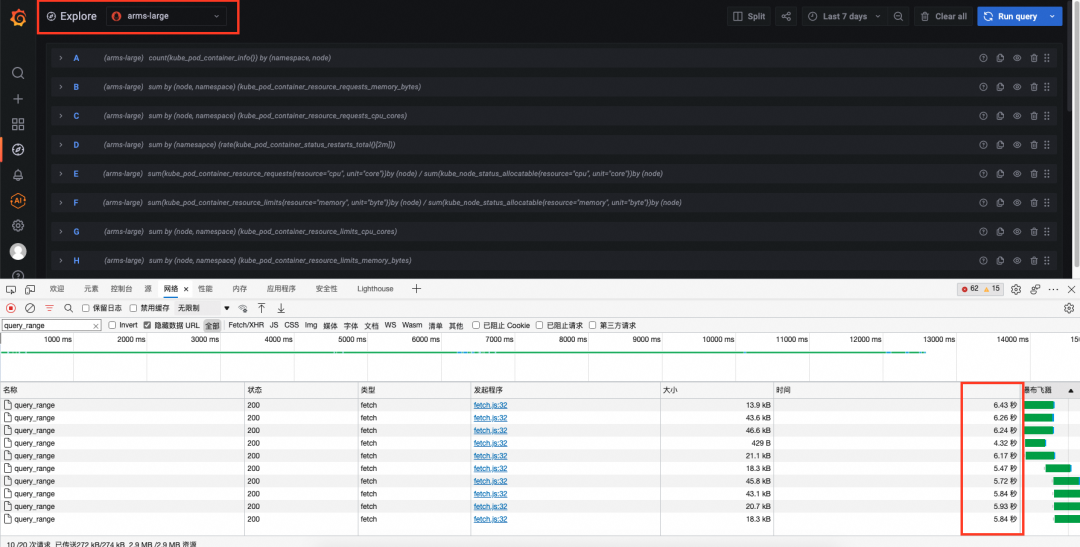
我们在 exporter 中同时发起 10 个查询(事实上因为 Chrome 浏览器并发连接数限制,实际上同时发出的请求数无法达到 10 个),来模拟同时发起多个查询的场景。查询时间跨度设置为七天。查询语句如下:
阿里云 Prometheus 服务总体耗时在 13 秒左右,因为浏览器并发请求数的限制,查询请求不是同时发出的,每个请求的响应时间在 5 到 6 秒左右。
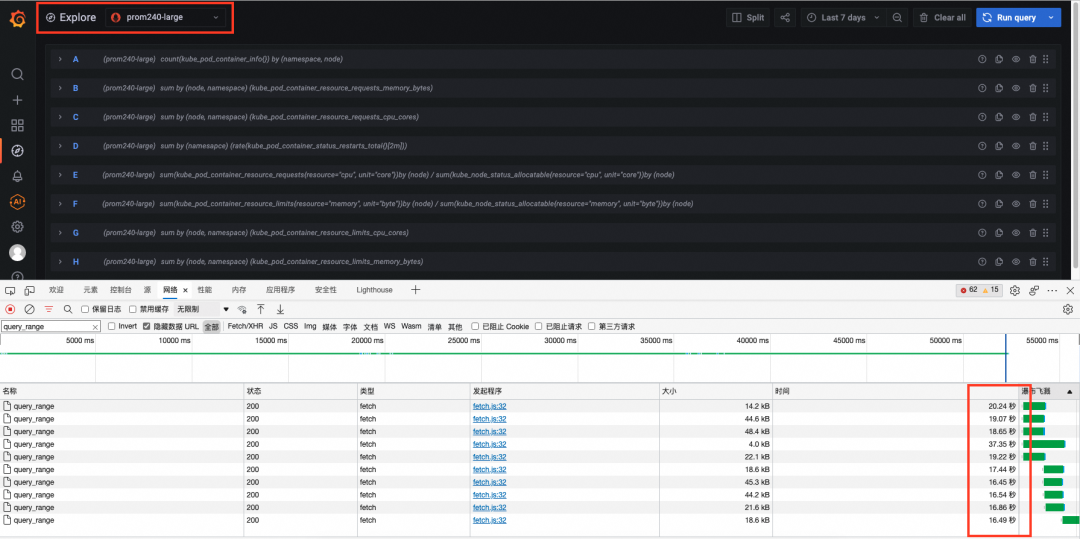
开源 Prometheus 总体耗时在 53 秒左右,因为单个请求耗时更久,叠加并发请求数的限制,导致总体耗时大约是阿里云 Prometheus 服务的 4 倍左右,单个请求的耗时也都在 16 到 37s。
测试结论
在本轮测试中,自建 Prometheus 即使在资源充沛的情况下,长跨度查询速度也远逊于阿里云 Prometheus 服务。这是因为阿里云 Prometheus 服务并不是简单的开源托管,我们在查询方面做了非常多的技术优化,包括算子下推、降采样、函数计算优化等技术手段,综合提升大查询/长时间跨度查询的性能表现。
实际上随着查询时间跨度的继续加长,阿里云 Prometheus 服务的查询性能优势相较于开源 Prometheus 会更加明显。同时开源 Prometheus 默认支持的并发查询只有 20(并发查询 20,并发 remote read 10),而阿里云 Prometheus 服务依托强大的云化计算资源,并发查询能力轻松上千。对于 SRE 而言,从长周期数据中观察系统异常变化规律非常重要,对于 IT 体系管理人员而言,从长周期数据中观察系统的演进趋势也是必不可少的工作,在这种场景下,开源 Prometheus 并不是一个可靠的伙伴。
测试总结
经过了六轮不同角度不同强度的测试,我们也可以得到一些初步的结论:
写入性能一般不会成为 Prometheus 的瓶颈。在大型集群高搅动率场景测试中,我们的写入速率最高,每分钟写入采样点数达到了 816w(136wx60/10 = 816w),但无论是开源 Prometheus 还是阿里云 Prometheus 服务均能很好的承接这种量级的写入。这也符合时序数据库写多读少的设计思路。
查询对 CPU 的消耗远多于写入。在小型集群范围查询场景测试中体现最为明显,仅仅是查询测试期间几个小时的数据,就能轻易将 CPU 使用率拉升到 60% 的高位。因为 Prometheus 的所谓查询,并不是将数据从存储中读出来就完事,更多的是各种 PromQL 的处理,其中包含大量的数据切分、判断、计算,所以如果有大查询/复杂查询/长周期查询/高时间线基数查询时,很容易将 CPU 打满。
时间线数量对 Prometheus 的内存消耗影响很大,且不是线性增长。
在小型集群高搅动率场景、中型集群高搅动率场景、大型集群高搅动率场景下,面对时间线爆炸的情况下,三个集群都没能坚持太久就挂掉,挂掉的原因也都是内存耗尽导致 OOMKill。
时间线增多同样导致查询变慢,在三个场景的查询耗时 P95 中,随着时间线的增多,阿里云 Prometheus 服务的查询响应时间也会相应变长。因为在 promQL 逻辑中,尤其是很多函数计算逻辑中,每条时间线是需要单独计算的,100w 时间线就要计算 100w 轮,所以响应时间自然也要变长。
资源消耗的增长是非线性的。相比小型集群,中型集群的资源扩了四倍,实际承载的时间线数量增长了 2.5 倍;相比中型集群,大型集群的资源也扩了四倍,实际承载的时间线数量增长了 2.75 倍。即如果集群吐出的时间线数量就是很多,加机器硬抗并不是一个明智的选择。
阿里云 Prometheus 服务针对高基数存储/查询做了不少有效的优化,所以在高基数的承载能力、高基数的查询响应上都能将开源 Prometheus 拉开一定距离。
长时间跨度查询除了要消耗大量 CPU 时间,还因为要加载数天的数据,带来更多的 IO 消耗,两相叠加导致查询响应会比较慢。阿里云 Prometheus 服务在这方面做了很多技术优化,包括 TSDB 数据文件优化、文件加载优化、降采样、算子下推、函数计算优化等等,最终的查询效率较开源 Prometheus 高出数倍。
阿里云 Prometheus 服务 VS 开源
成本永远是企业用户说不腻的话题。IT 上云对于降低/拉平企业数字化成本的作用毋庸置疑,而具体到 Prometheus 组件上,云服务的成本表现,相比于自建模式会怎样呢,我们在这里一起做一个简单的比较。以下的自建成本计算中,我们统一使用张家口 region 的 ECS 价格。
场景 1:小规模线上集群
线上这个词在 IT 语境中有着神奇的魔力,任何名词只要前面加上“生产/线上”的前缀,聊天室的气氛都会瞬间严肃起来。不信你在公司群里,发一句“老板咱们线上环境挂了”试试 :)
线上环境里,可观测能力不再是可选项,而是必选项,平时要可用,预警问题要管用,排查问题时更得中用。这就对我们的可观测工具提出了更高的要求,既要有优秀的 SLA,又要好用易用,关键时刻才能成为排查问题的神兵利器,而不只是一个简单花哨的数据展板。
自建一个这样的 Prometheus 工具套件,与使用阿里云 Prometheus 服务的成本又能差多少呢?
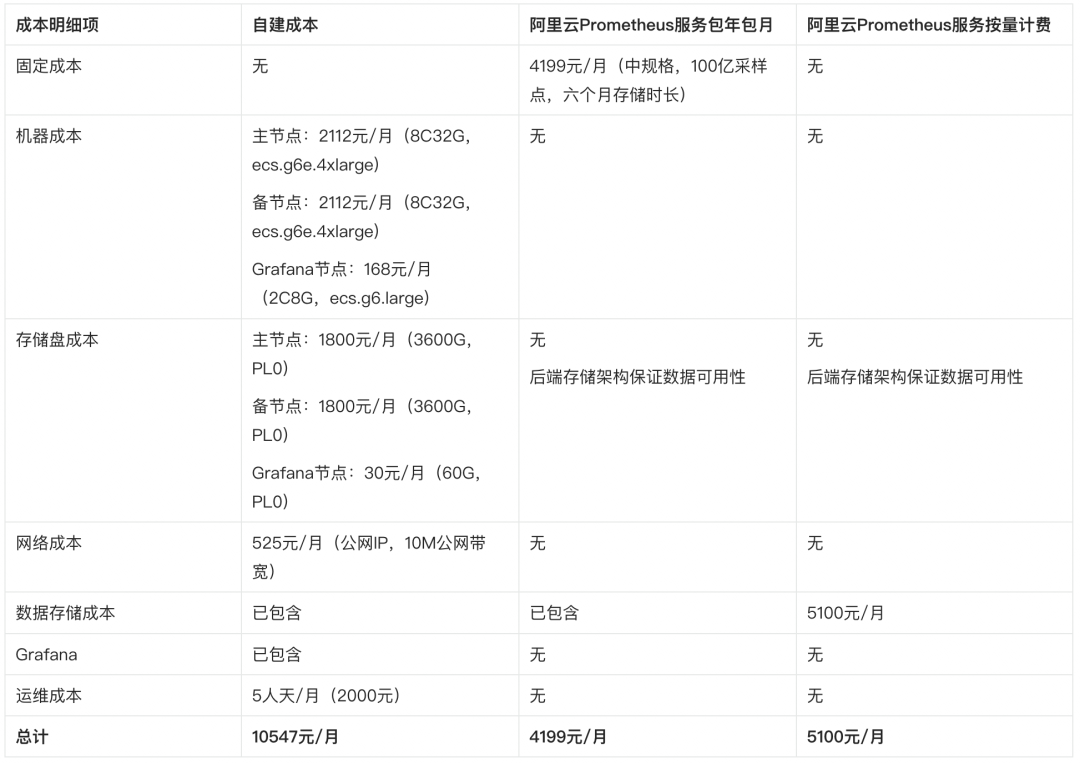
假设我们现在面对的,是一个小型线上集群,五台物理机上运行了 50 个业务 pod,各种依赖的基础设施如 DB,redis 等有 10 个 pod,另外还有 10 个 k8s 的基础组件 pod,共计 70 个 pod 的小集群。这样一个集群里,主要的指标来源有:
node exporter,1200 series per exporter x 5 exporter = 6000 series
kube state metrics,15000 series per exporter = 15000 series
cadvisor,7000 series per exporter x 5 exporter = 35000 series
infra pod,1500 series x 10 pod = 15000 series
其他 pod 指标(JVM 等)10000
按照 30 秒抓取一次,每月抓取 86400 次(2x60x24x30),基础指标(node exporter/kube state metrics/cadvisor)指标量约 48.4 亿,自定义指标(infra pod,其他 pod)指标量约 21.6 亿,日均自定义指标量 72M。我们将采集到的数据通过 remote write 的方式再写一份到备节点,以保证数据的可用,数据保留时长设定为一个月。
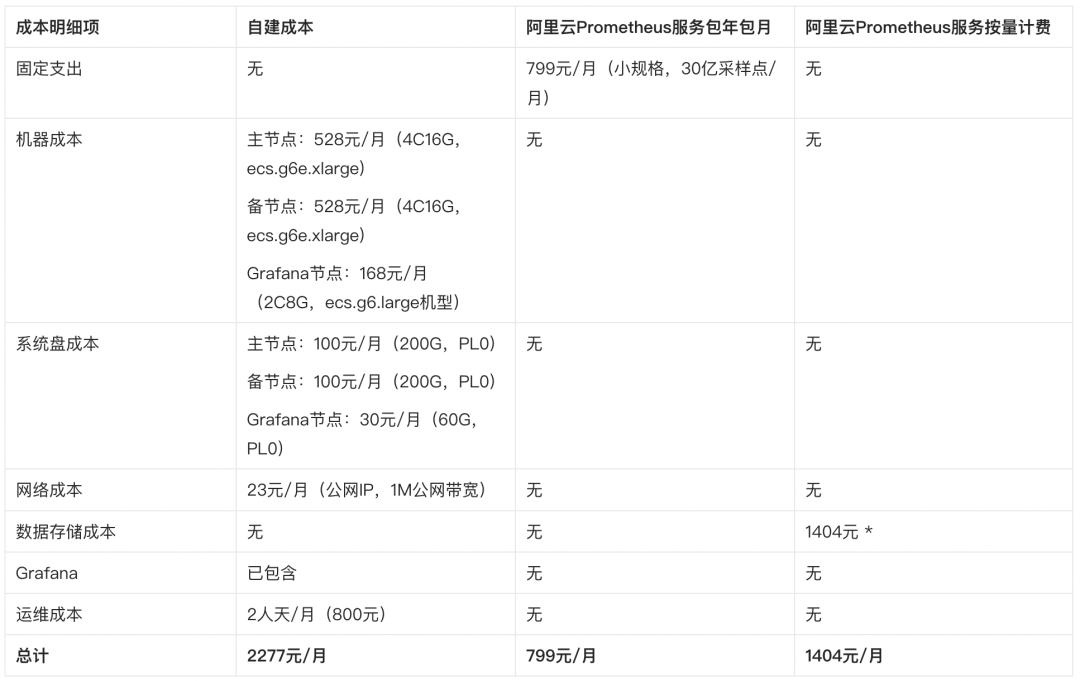
自建的成本每一项都不高,零零碎碎加起来却比阿里云 Prometheus 服务高很多,大约这就是批发和零售的差距吧~ :)
在上面的成本比较中,因为自建 Prometheus 的人力成本会相对复杂,所以我们这里按照 8000 元/月的中高级运维工程师工资计算。实际上,搭建一套完整的可观测系统,人力的投入并不是敲几个命令行将 Prometheus 跑起来那么简单。
在真实的业务应用中,几乎一定会依赖到各种各样的基础设施,包括但不限于 DB、gateway、MQ、redis 等等,这些组件健康与否直接关系整个系统的稳定运行。而对于 SRE 来说,就意味着必须要为这些组件配套 exporter、绘制大盘、配置告警等等,也意味着需要长期持续的优化大盘优化告警,这些细碎而必要的工作带来的额外人力分散在每时每刻,咋一看不起眼,汇总起来却是不小的企业成本。对此,阿里云 Prometheus 服务提供了集成中心功能,其中集成了监控常见的基础设施组件的快捷入口,一键完成 exporter 部署安装、dashboard 绘制、告警规则配置的能力,让客户的精力从这些琐碎的事情中释放出来,聚焦于更有价值的部分。
同时,系统出现异常时,也是可观测系统大显身手的时候,如果我们能有一个优秀的 dashboard,将散落各处的观测数据归集到一起,对于问题处理会有事半功倍的效果。但这方面开源社区并没有太多可供借鉴的东西,开源社区中更多关注大盘的通用性而非易用性。
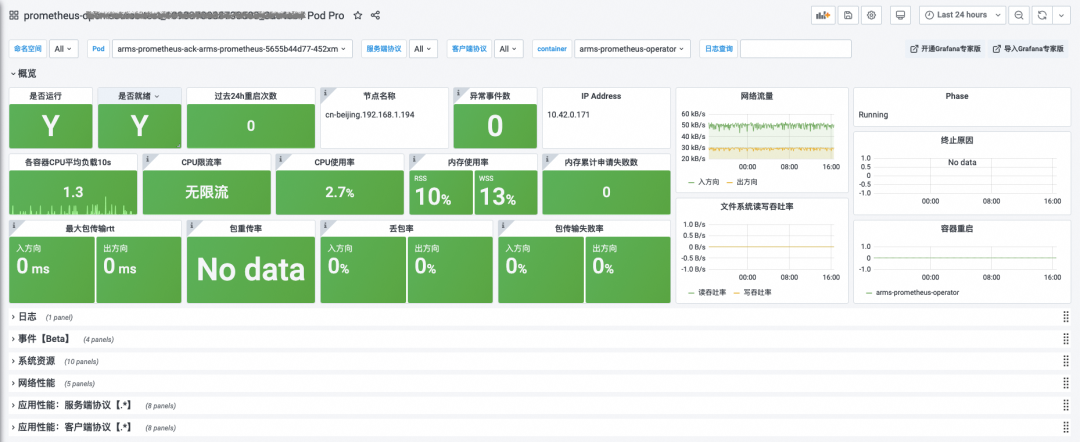
针对 SRE 的现实需求,阿里云 Prometheus 服务依赖自身在可观测领域的多年积淀,以及对我们用户使用场景的总结提炼,针对 POD/NODE/K8s/ingress/Deployment 等场景,在包年包月版本中,特别提供了 Pro 版本大盘,将常用的指标监控和日志、进程、网络、事件、应用性能等分项监控融为一炉,一张大盘通观全局,让角落里的异常也无处遁形。以 Pod Pro 大盘为例,在一张盘中整合了日志、事件、网络、应用性能等多个维度的数据,SRE 们无需手忙脚乱的在各种系统/工具/大盘中切换奔波,便捷高效的定位异常,尽早扼杀问题苗头。更多其他的 Pro 版本大盘,也都在这里 列出 [ 7],供大家参考。
场景 2:随着业务发展壮大
随着业务发展壮大,集群规模也更大了,SRE 肩上的担子有重了许多,我们需要更多资源来应对挑战。
我们预设这是一个中等规格的容器集群,有十台物理机,其中运行了 200 个业务 pod,配套的各种 infrastructure 如 MySQL、redis、MQ、gateway、注册中心、配置中心等共计 50 个 Pod,另外有 k8s 自带的各种 Pod 如网络插件,存储插件等约 30 个。继续沿用主从模式保证可用性。同时我们将数据存储时长延长到六个月,以便长期趋势观察和异常追溯。
集群的时间线数量预估如下:
node exporter,1500 series per exporter x 10 = 15000 series
cadvisor,10000 series per node x 10 = 100000 series
ksm,20000 series = 20000 series
infra pod,1500 series * 50 = 75000 series
其他自定义指标(如 JVM)20000 series
一个月约产生基础指标 116 亿,自定义指标(infrastructure 产生的指标)82 亿。
共计约 200 亿采样点,单个采样点体积平均约 256B,压缩率 8%,数据文件体积 200 亿 x 256B x 8% ,即约 410G。六个月数据的总体积约 410G x 6 = 2460G。
当前集群的初始的时间线数量已经达到了 20w+,即使只考虑正常业务更新带来的 pod 启停(pod 启停会带来大量新的时间线,pod 频繁重启则一定会带来时间线爆炸),六个月时间内累计的时间线也能轻松突破 100w,所以我们选用了 ecs.g6e.4xlarge 规格的机器来保证系统裕度。
要维护这样的一套 Prometheus 环境,加上各种周边设施(exporter,Grafana,alert 等),至少需要投入 0.2 个人力,也就意味着每月数千元的人力成本投入。
场景 3:多集群统一监控
对于规模较大的企业,生产集群往往会有多个,一来更加靠近客户,提供更快的响应速度,二来也可以提供一些容灾能力,避免整个线上环境被一锅端。但对于 SRE 而言,这样的架构方式就需要将数据做汇总,开源 Prometheus 提供了联邦集群的方式,阿里云 Prometheus 服务提供了 GlobalView 功能,都可以做到一次查多个集群,针对这两种方式,我们再次来估算下监控成本。
假设我们的应用部署在三个不同 region,集群规模参考上场景 2 中的集群。我们有三种部署方案:
分层联邦模式,三个开源 Prometheus 集群分布在三个不同 region(worker) + 一个高级别的 federate 集群(master),其中 master 集群配置和 worker 保持一致,但不使用备节点。
remote write 模式,将三个 region 的数据 remote write 到一个中心节点,所以中心节点的资源需求也会更高。
使用 ARMS Prometheus 的 GlobalView,三个 ARMS Prometheus 集群分布在三个不同 region(worker) + 一个 GlobalView 集群(master)
remote write 模式,将是哪个 region 的数据 remote write 到同一个 ARMS Prometheus 实例中,使用大规格 Prometheus 实例(250 亿采样点/月)。
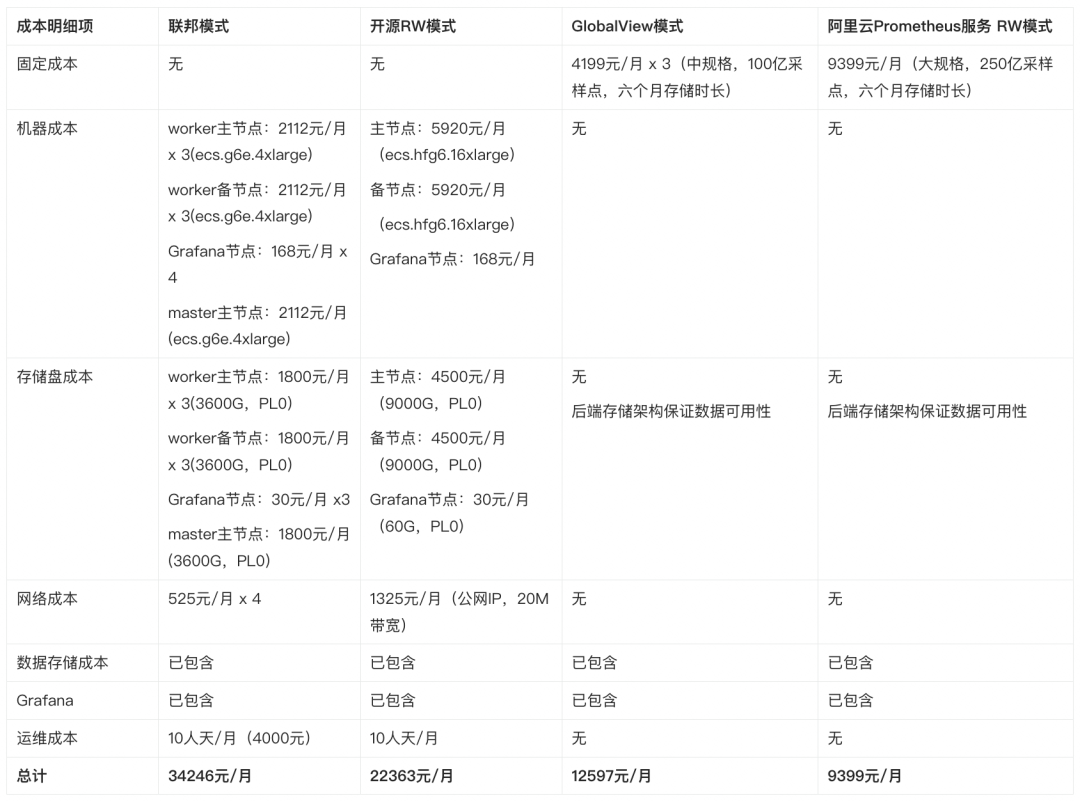
随着数据采集规模的扩大,阿里云 Prometheus 服务的成本优势更加明显,而且免运维的特性更加释放了 SRE 的人力投入。同时配合阿里云云原生可观测家族的其他组件,能够完整的覆盖各种可观测场景(log/trace/metrics),聚力协同,为企业系统的稳定运行保驾护航。
总结
总的来看,开源 Prometheus 在顺风局表现还是不错的,低负载时响应和资源使用都可圈可点。但现实很残酷,理想的场景并不多见,总是会有各种层出不穷的意外挑战 SRE 们紧绷的神经(题外话:解决和预防各种意外,不就是 SRE 的目标么?),对于无论是事前预防,事中告警,事后复盘,一套可靠的可观测体系都能让你事半功倍,用详实准确的数据支撑你的行动。
事实上阿里云 Prometheus 服务工具箱里,不止有性能强悍的存储能力,还有很多其他的神兵利器,比如化繁为简的预聚合,比如高性能且自动扩展的采集 agent,比如 xxx,后续我们会持续为大家介绍。用我们的产品和服务,帮助 SRE 们更加 Reliable!
相关链接
按量付费成本计算请参考
https://help.aliyun.com/document_detail/183914.html
[1] 《2023 年十大战略技术趋势》
https://www.gartner.com/cn/newsroom/press-releases/2023-top-10-strategic-tech-trends
[2] 兼容性测试工具
https://github.com/prometheus/compliance
[3] 兼容性为 97.06%
https://help.aliyun.com/document_detail/408652.html
[4] 优于 AWS 和 GCP
https://promlabs.com/promql-compliance-tests/
[5] prometheus-benchmark
https://github.com/VictoriaMetrics/prometheus-benchmark
[6] 项目存放在 GitHub 上
https://github.com/liushv0/prometheus-benchmark
[7] 这里列出
https://help.aliyun.com/document_detail/440066.html#section-9ot-waf-tt5
版权声明: 本文为 InfoQ 作者【阿里巴巴云原生】的原创文章。
原文链接:【http://xie.infoq.cn/article/80baff165400397ee80f23502】。文章转载请联系作者。

阿里云云原生 2019-05-21 加入
还未添加个人简介










评论