
GPUStack 0.2:开箱即用的分布式推理、CPU 推理和调度策略

GPUStack 是一个专为运行大语言模型(LLM)设计的开源 GPU 集群管理器,旨在支持基于任何品牌的异构 GPU 构建统一管理的算力集群,无论这些 GPU 运行在 Apple Mac、Windows PC 还是 Linux 服务器上,GPUStack 都能将它们纳入统一的算力集群中。管理员可以从如 Hugging Face 等流行的大语言模型仓库中轻松部署任意 LLM,开发人员则可以像访问 OpenAI 或 Microsoft Azure 等供应商提供的公有 LLM 服务的 API 一样,简便地通过 OpenAI 兼容的 API 访问部署的私有 LLM。
GPUStack 自 7 月底发布以来,国内和海外社区的反响都非常热烈,研发团队收到了大量建议和反馈。我们综合评估了社区的需求和 GPUStack 的 Roadmap 计划,迅速发布了 GPUStack 0.2 版本。该版本新增了单机多卡分布式推理、跨主机分布式推理、纯 CPU 推理、Binpack 和 Spread 放置策略以及指定 Worker 调度、手动指定 GPU 调度等核心特性,并进一步扩展了对 Nvidia GPU 的支持范围,同时针对社区用户反馈的问题进行了增强和修复,以更好地满足各种使用场景的需求。
有关 GPUStack 的详细信息,可以访问:
GitHub 仓库地址: https://github.com/gpustack/gpustack
GPUStack 用户文档: https://docs.gpustack.ai
新特性介绍
分布式推理
GPUStack 0.2 版本的关键特性是支持开箱即用的单机多卡分布式推理和跨节点分布式推理,管理员无需复杂配置即可将大模型运行在单机的多个 GPU 或跨多个节点的 GPU 上,从而满足单卡无法支持的大参数量模型的运行需求。
单机多卡分布式推理在 0.1 版本,当 GPUStack 中没有任何 GPU 能够满足模型的资源需求时,GPUStack 会采用半卸载方案,通过 CPU 和 GPU 混合推理的方式来运行模型。然而,由于部分依赖 CPU 进行推理,整体性能会受到影响,这种方式无法满足高性能推理的需求。
为了解决这一问题,GPUStack 0.2 版本引入了单机多卡分布式推理特性。这一特性允许将模型的不同层卸载到单台机器的多个 GPU 上,同时利用多个 GPU 进行推理。这样,管理员不仅可以运行更大参数量的模型,还能确保模型在性能和效率方面达到更高的水平。
跨节点分布式推理为了支持 Llama 3.1 405B、Llama 3.1 70B、Qwen2 72B 和其他大参数量模型,GPUStack 0.2 版本引入了跨节点分布式推理特性。当单个 Worker 无法满足模型资源需求时,GPUStack 可以将模型卸载到多个 Worker 中,实现跨主机的分布式推理。
此时,模型的推理性能会受到跨主机网络带宽的限制,可能会显著下降。因此,为了确保较好的推理性能,建议结合高性能网络方案,如 NVLink / NVSwitch、RDMA 等。在消费级场景中,也可以考虑使用 Thunderbolt 互联方案。
此外,由于 Hugging Face 模型仓库中各种大参数量模型的模型文件过大需要切分,为了支持此类模型,0.2 版本中新增了对分片模型进行合并下载和运行的支持。
CPU 推理
GPUStack 0.2 版本现已支持 CPU 推理。在没有 GPU 资源或 GPU 资源不足的情况下,GPUStack 可以将 CPU 作为备用方案,将模型完全加载到内存并通过 CPU 执行推理。这样即便在没有 GPU 的环境中,管理员仍然能够运行一些小参数量的大模型,进一步提升 GPUStack 在边缘和资源受限环境中的适用性。
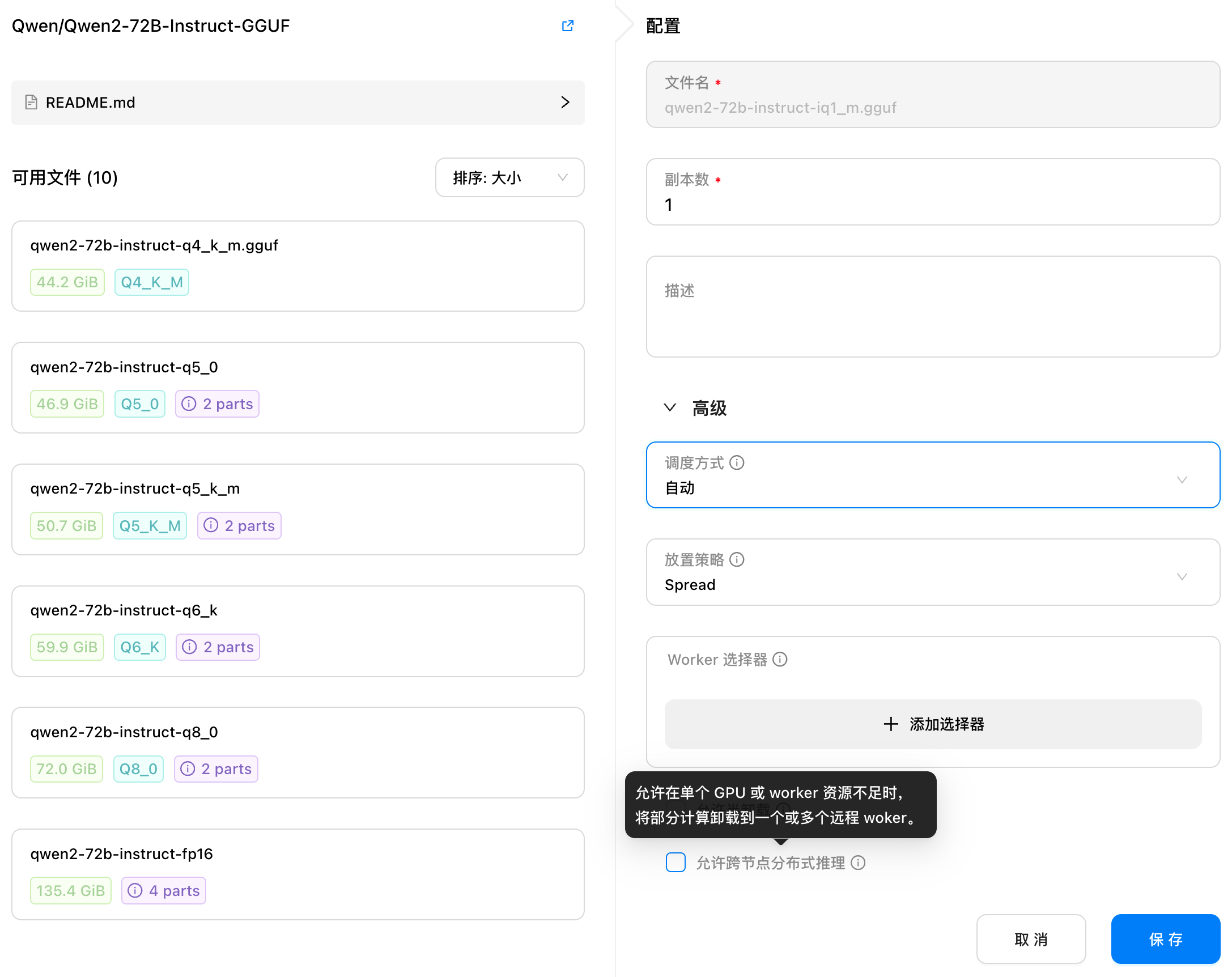
调度策略
降低算力资源碎片化的 Binpack 放置策略 Binpack 放置策略是一种紧凑调度策略。在 GPUStack 的 0.1 版本中,默认采用 Binpack 策略部署模型。当单个 GPU 能够满足模型的资源需求时,该策略会尽量将模型的多个副本集中调度到该 GPU,以最大化其利用率,直到该 GPU 的剩余资源不足以支持新模型时,才会选择其他 GPU。
Binpack 策略的作用是减少资源碎片化,优化整体 GPU 资源的利用率。碎片化指的是各个 GPU 上存在少量未使用的资源,这些资源不足以支持新模型,导致算力资源浪费。通过 Binpack 策略,可以将模型尽可能集中到某些 GPU 上,使其他 GPU 保留完整的算力资源,用于处理更大的模型。
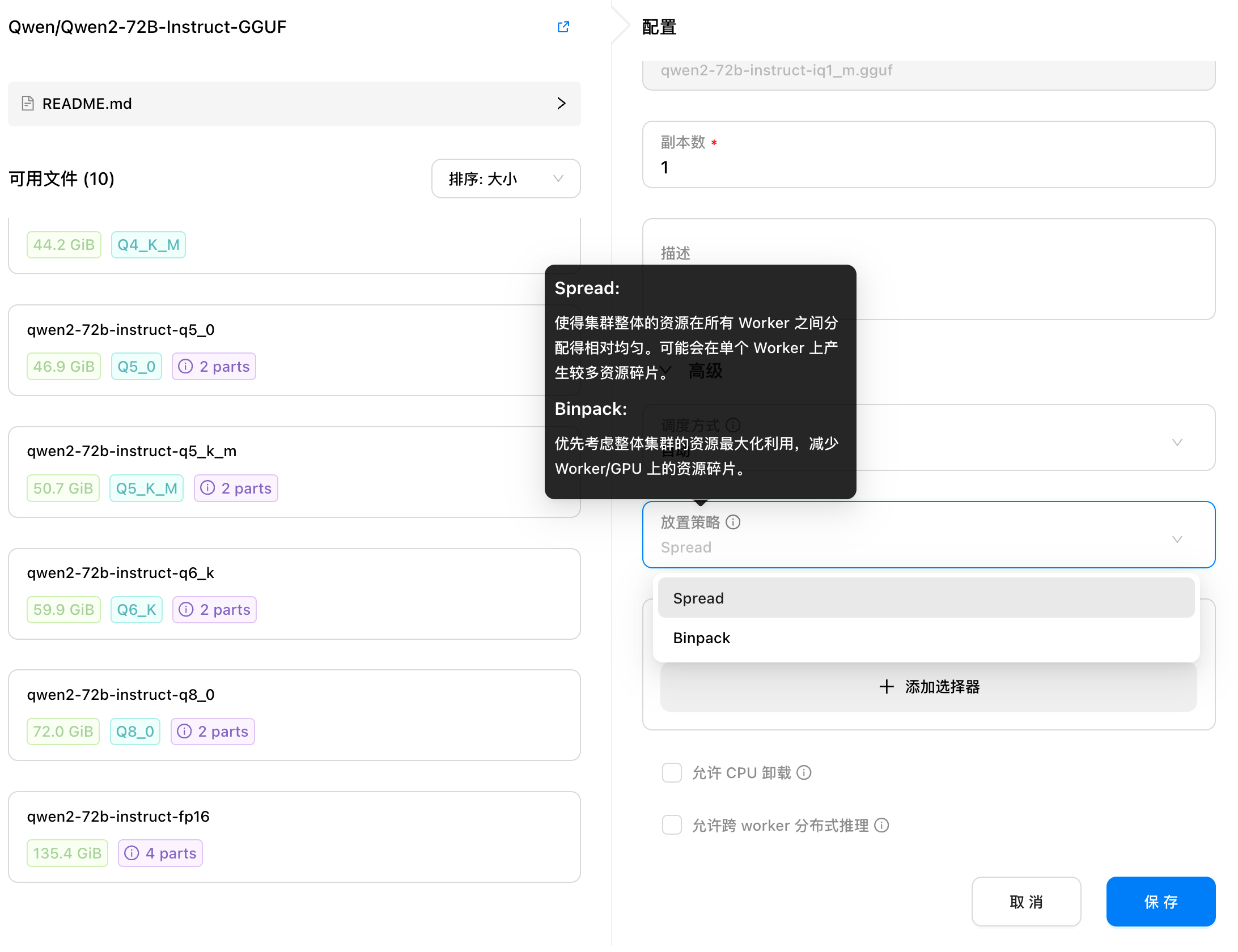
提升算力负载平衡的 Spread 放置策略尽管 Binpack 策略能够减少算力碎片化,最大化单个 GPU 的利用率,但在某些情况下,可能会导致负载过于集中于少数几个 GPU 上,导致其他 GPU 闲置。为了解决这一问题,GPUStack 0.2 版本新增了对 Spread 放置策略的支持。
Spread 策略与 Binpack 的紧凑型调度相反,旨在将模型均匀分布到多个 GPU 上,避免单一 GPU 的资源过度集中使用,确保每个 GPU 的负载更加均衡。这样可以减少资源争用所带来的性能瓶颈,从而提升模型的整体性能和稳定性。
在 Spread 策略下,任务会优先分配给负载较低的 GPU,使得所有 GPU 都能参与推理任务。这种策略特别适用于高并发或高性能场景,可以在资源充足的情况下提高集群的弹性,有效避免单个 GPU 过载。GPUStack 0.2 默认采用 Spread 策略,管理员可根据实际需求灵活选择合适的策略。
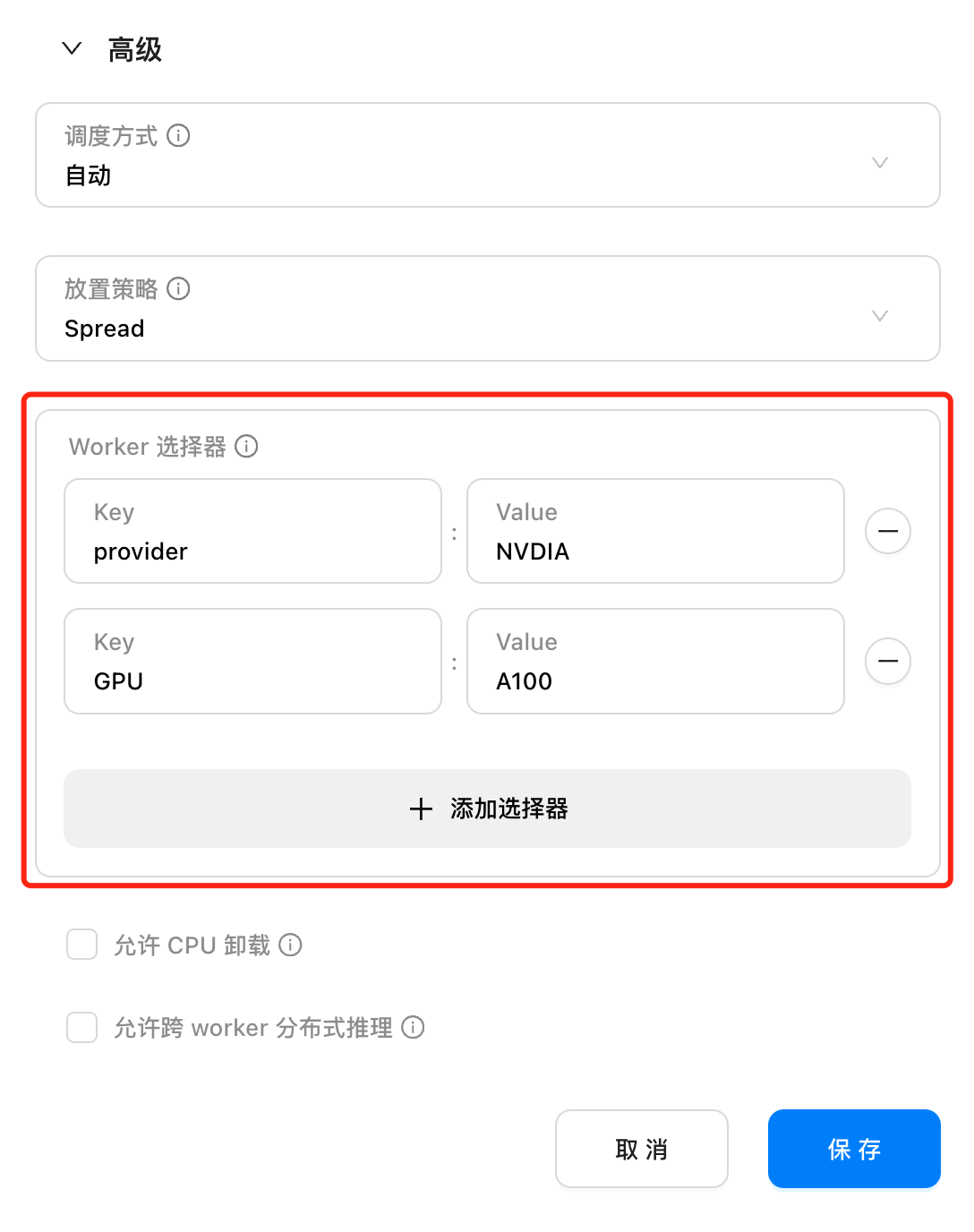
指定 Worker 调度
在 GPUStack 0.2 版本中,管理员可以为不同的 Worker 设置标签,并在模型部署时通过 Worker 选择器指定将模型实例调度到具有特定标签的 Worker 上。这使管理员能够更精准地控制模型的部署,优化资源分配,并满足特定的需求或策略。
这个能力特别适用于需要对计算资源进行细粒度管理的场景,例如在异构环境下,将模型调度到某一 GPU 厂商或某一 GPU 型号上。通过标签选择机制,GPUStack 允许在复杂的计算环境中实现更高效的资源管理,提升模型部署的灵活性和针对性。
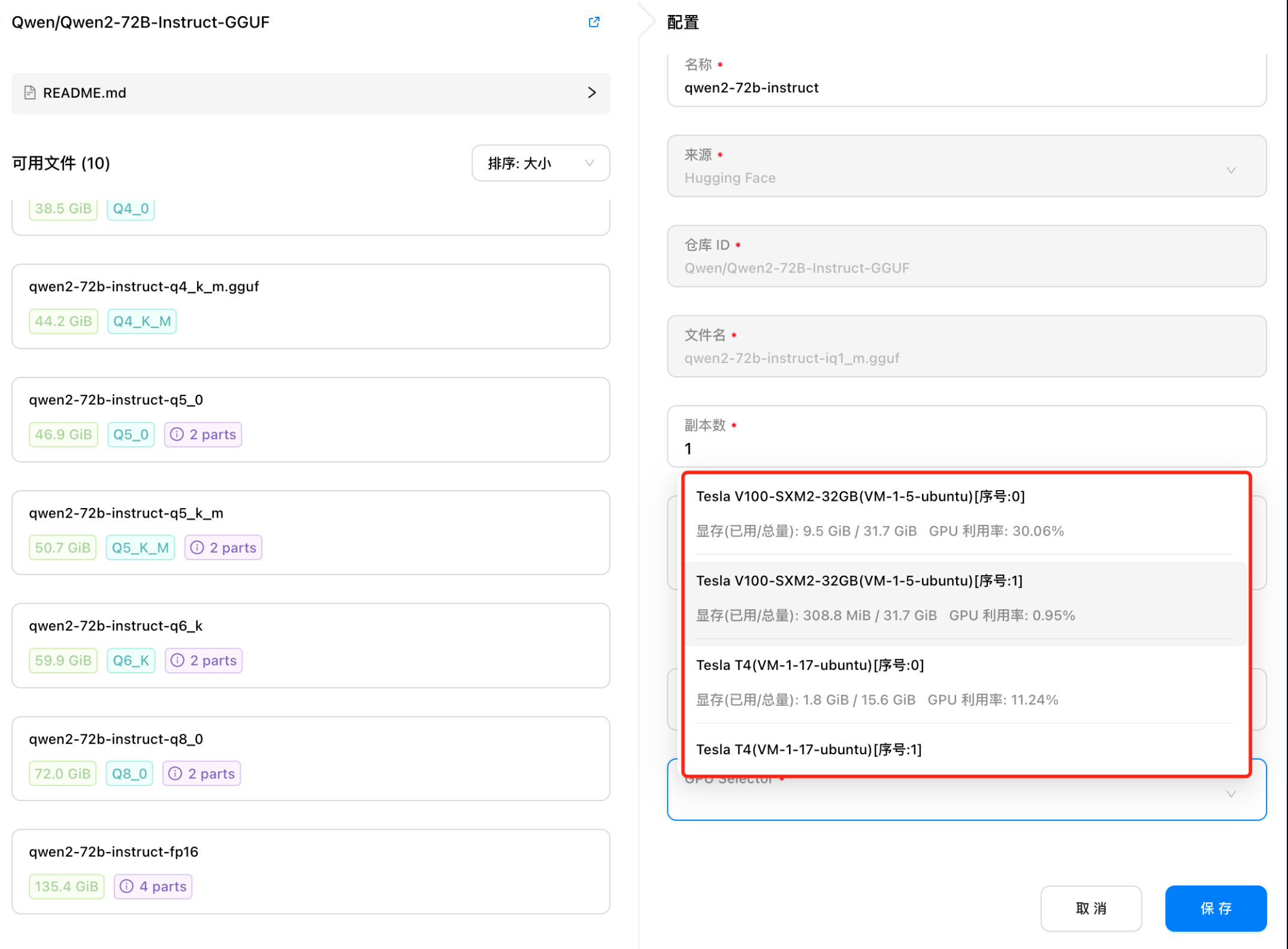
手动指定 GPU 调度
GPUStack 的核心能力之一是提供了自动计算模型资源需求和根据资源需求自动调度的功能。这意味着管理员无需担心如何分配资源或手动调度模型。GPUStack 0.2 版本还支持了 Binpack 和 Spread 放置策略、单机多卡分布式推理、跨主机分布式推理以及指定 Worker 调度等多种调度策略,从而让管理员可以控制模型的调度行为。
为了覆盖更多使用场景,GPUStack 的调度功能在持续丰富和完善中。为了满足一些特定调度需求,GPUStack 也在 0.2 版本中提供了手动调度选项。管理员可以手动将模型调度到指定的 GPU 上运行,从而更精确地控制模型的调度行为。
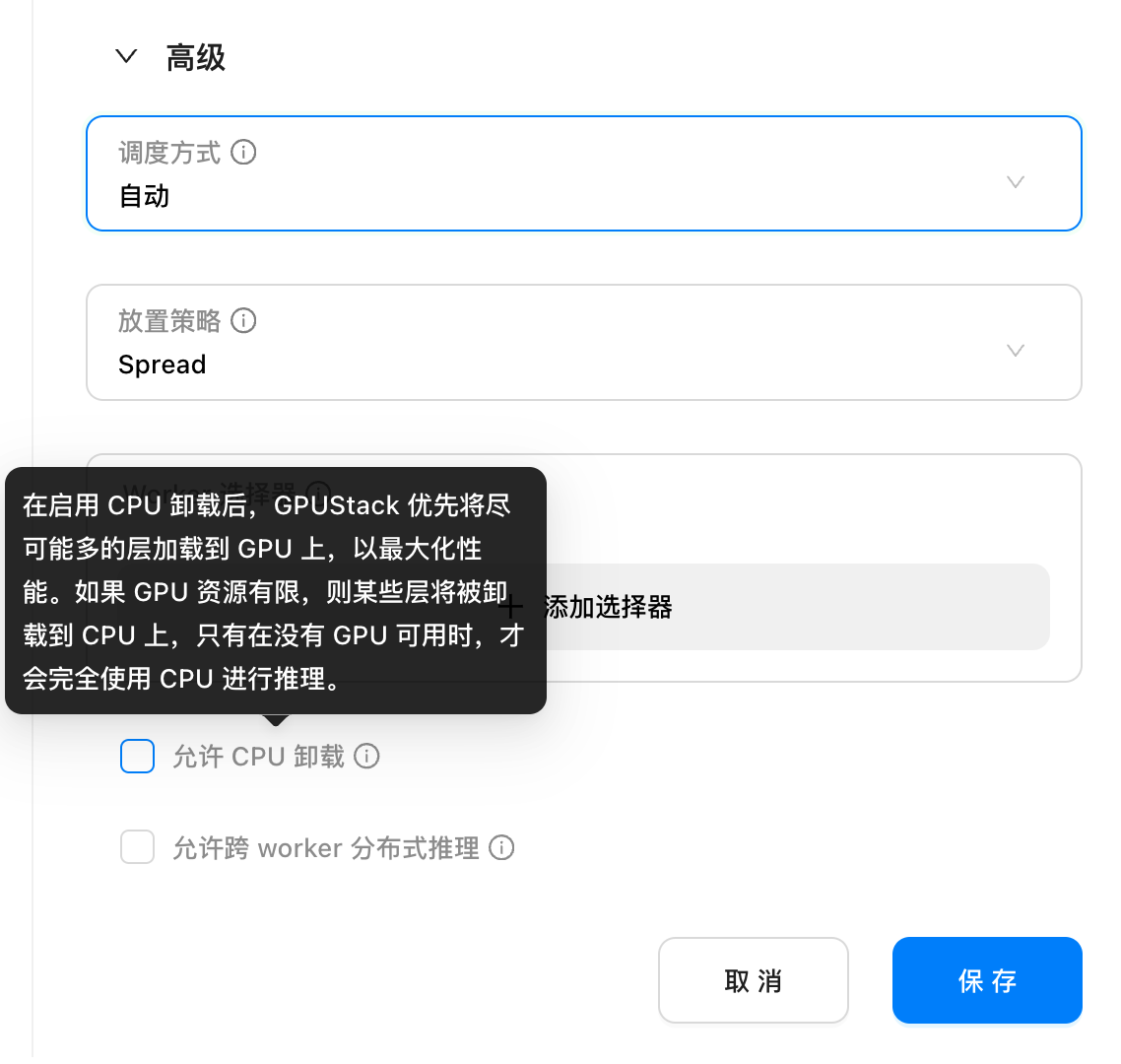
控制是否允许 CPU 卸载
在 0.1 版本中,针对因 GPU 显存不足而无法将模型完全卸载至 GPU 的场景,GPUStack 会根据 GPU 可加载的模型层数,自动将部分层卸载至 GPU 进行加速,另一部分则加载到内存中通过 CPU 进行推理。这种方式称为 CPU 卸载、半卸载或部分卸载,即 CPU 和 GPU 混合推理。
这实现了在显存资源有限的情况下运行更大参数量模型的需求。然而,由于部分推理依赖 CPU,整体性能会受到影响。在对模型性能要求较高的场景中,管理员无法直接判断模型是否完全加载至 GPU,从而难以决定是否需要扩容 GPU 资源以提升性能。
在 0.2 版本中,管理员可以选择是否允许半卸载。该选项默认关闭,仅支持纯 GPU 推理。如果没有满足资源需求的 GPU,模型将不会被部署,而是进入 Pending 状态,直到有合适的 GPU 可用为止。如果管理员能够接受部分卸载带来的性能损失,也可以启用该选项,允许 CPU 和 GPU 进行混合推理。
其他重点特性
新增 Compute Capability 6.0, 6.1, 7.0, 7.5 的 Nvidia GPU 型号支持
在 0.2 版本中,GPUStack 进一步扩大了对 Nvidia GPU 的支持,新增了对 Compute Capability 6.0、6.1、7.0 和 7.5 的 Nvidia GPU 型号的支持,包括 NVIDIA T4、V100、Tesla P100、P40、P4 以及 GeForce GTX 10 系列和 RTX 20 系列等型号。这让 GPUStack 能够覆盖更多数据中心及消费级场景的需求。
目前,GPUStack 支持 Compute Capability 6.0 ~ 8.9 的所有 Nvidia GPU 型号。具体支持的型号可以参考 Nvidia 官方的 GPU Compute Capability 说明:https://developer.nvidia.com/cuda-gpus
其他增强和修复请查看完整变更日志: https://github.com/gpustack/gpustack/releases/tag/0.2.0
加入社区
想要知道更多关于 GPUStack 的信息,可以访问:https://gpustack.ai。
如果你在使用过程中遇到任何问题,或者对 GPUStack 有任何建议,欢迎随时加入我们的 Discord 社区 [https://discord.gg/VXYJzuaqwD],也可以添加 GPUStack 微信小助手(微信号:GPUStack)加入 GPUStack 微信交流群,获得 GPUStack 团队的技术支持,或与社区爱好者共同探讨交流。
我们正在快速迭代 GPUStack 项目,在开始体验 GPUStack 之前,我们非常欢迎你在我们的 GitHub 仓库 gpustack/gpustack 上点亮⭐️关注我们,以便可以即时地接收 GPUStack 未来的新版本通知。我们十分欢迎您一起参与这个开源项目的贡献。

Manage GPU clusters for running LLMs 2020-11-05 加入
公众号:Seal软件 Seal-io












评论