
你所不知道的端口耗尽(三)
问题背景
在你所不知道的端口耗尽前面的两篇章节中,介绍了经典的客户端端口耗尽和 SNAT 端口耗尽问题,但是对于解决方案只是一笔带过,这篇文章会更详细的介绍解决方案。解决方案主要分为两大类,优化部署和优化应用程序。
优化部署
本篇主要介绍在 Azure 上的部署以及主要是 Azure 集群的部署,针对的是 SNAT 端口耗尽问题。
Load Balancer 增加前端 IP
在(二)中详细介绍过,Load Balancer 的每个前端 IP 可提供 64K 的端口,如果端口耗尽问题发生,最直接的方法是新增可用的 IP。
Load Balancer 调整出站规则
Load Balancer 的默认出站规则是根据后端池大小分配 SNAT 端口。具体如下:
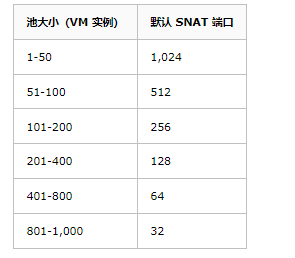
如果按照默认的出站规则,最大才 1024,明显不符合大规模产品的需求,所以一般需要调整为手动端口分配,ports per instance。例如,若已知后端池中最多有 10 个 VM,则可以为每个 VM 最多分配 6,400(64000/10) 个 SNAT 端口,而不是默认的 1,024 个。
使用 NAT 网关
Azure 负载均衡器将固定数量的 SNAT 端口分配给后端池中的每个虚拟机实例。 这种分配方法可能会导致 SNAT 耗尽,尤其遇到流量模式不均衡导致特定虚拟机发送更高的传出连接量的情况。 与负载均衡器不同,NAT 网关在子网中的所有 VM 实例之间动态分配 SNAT 端口。
NAT 网关让子网中的每个实例都可以使用 SNAT 端口。 利用此动态分配,VM 实例可从可用端口池中使用每个实例所需数量的 SNAT 端口进行新连接。 动态分配可降低 SNAT 耗尽的风险
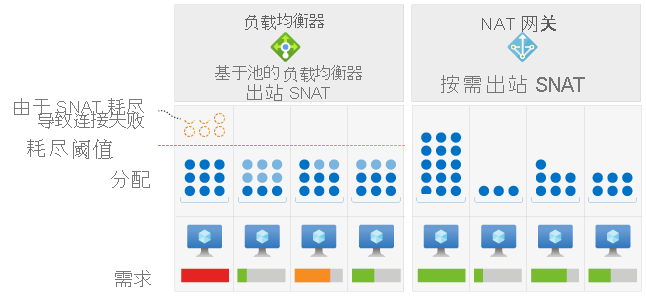
另外,NAT 网关从可用端口池中随机选择端口。 如果没有可用的端口,只要没有与同一目标公共 IP 和端口的现有连接,就会重复使用 SNAT 端口。 NAT 网关的此端口选择和重用行为使得遇到连接超时的可能性较低。
优化应用程序
重复使用连接
建议将应用程序配置为重复使用连接,而不是为每个请求生成单独的原子 TCP 连接。这里介绍一个最典型的例子,net core 中的 HttpClient,对外部网络的请求使用单 instance 或者使用 HttpClientFactory,如果每个请求都构造一个 HttpClient,那么即使同一目标公共 IP 和端口,也会分配不同的端口,这样端口很快就会消耗殆尽。
使用连接池
在应用程序中使用连接池方案,其在一组固定的连接中内部分布请求,并且在可能的情况下,重复使用这些请求。连接池一般存在于正在使用的框架中,所以技术选型和 SDK 时,一定要非常注意是否有连接池。
另外,也可以根据情况调整连接池的最大连接数。
使用节制的重试逻辑方案
当 端口耗尽或应用程序故障发生时,无衰减或回退逻辑的积极重试或暴力重试会使耗尽状况再次发生或一直持续。如果重试过于频繁,则连接可能没有足够的时间关闭和释放 SNAT 端口以供重复使用。 使用节制的重试逻辑,可以降低对端口的需求。
延时重试: 系统可能会在失败后等待一段时间,之后再尝试执行相同的操作。这样做的目的是给予系统或目标资源一些恢复时间。
退避算法: 采用退避算法(如指数退避)来决定两次重试尝试之间的等待时间。例如,每次尝试失败后,系统会将等待时间翻倍,以减少对系统的冲击和避免潜在的连续失败。
限制重试次数: 为了避免无限重试,可能会设置一个最大重试次数的限制。一旦达到这个限制,系统将放弃重试,并可能采取其他处理措施,如发送警告或切换到备份方案。
智能判断: 重试逻辑可能还会包含对当前状态和环境的评估,只有在条件看起来有可能改善时才进行重试。
随机化和分散: 在分布式系统中,如果多个实例几乎同时遇到问题并进行重试,可能会造成资源争用或"flood"效应。因此,引入随机化因素使得重试尝试更加分散可以减少这种风险。
文章转载自:牛角挂书i

还未添加个人签名 2023-06-19 加入
还未添加个人简介






评论