
为数据弹性而生,阿里云云原生存储再提速
作者:之浩、展逸
企业在 Kubernetes 上运行 AI、大数据应用已成主流,资源弹性和开发运维效率得到显著提升的同时,计算存储分离架构也带来了挑战:网络延迟高、网络费用贵、存储服务带宽不足等。
以 AI 训练、基因计算、工业仿真等高性能计算场景为例,需要在短时间内并发执行海量计算,多计算实例共享访问文件系统的同一数据源。很多企业使用阿里云文件存储 NAS 或 CPFS 服务,挂载到阿里云容器服务 ACK 运行的计算任务上,实现数千台计算节点的高性能共享访问。
然而,随着算力规模和性能提升、以及模型规模和工作负载复杂度的增加,在云原生的机器学习和大数据场景下,高性能计算对并行文件系统的数据访问性能和灵活性要求也越来越高。
如何能更好地为容器化计算引擎提供弹性和极速的体验,成为了存储的新挑战。
为此,我们推出了弹性文件客户端 EFC(Elastic File Client),基于阿里云文件存储服务的高扩展性、原生 POSIX 接口和高性能目录树结构,打造云原生存储系统。并且,EFC 与云原生数据编排和加速系统 Fluid 结合,实现数据集的可见性、弹性伸缩、数据迁移、计算加速等,为云原生的 AI、大数据应用共享访问文件存储提供了可靠、高效、高性能的解决方案。
Fluid,云原生之数据新抽象
Fluid [ 1] 是一个云原生分布式数据编排和加速系统,主要面向数据密集型应用(如大数据、AI 等应用)。
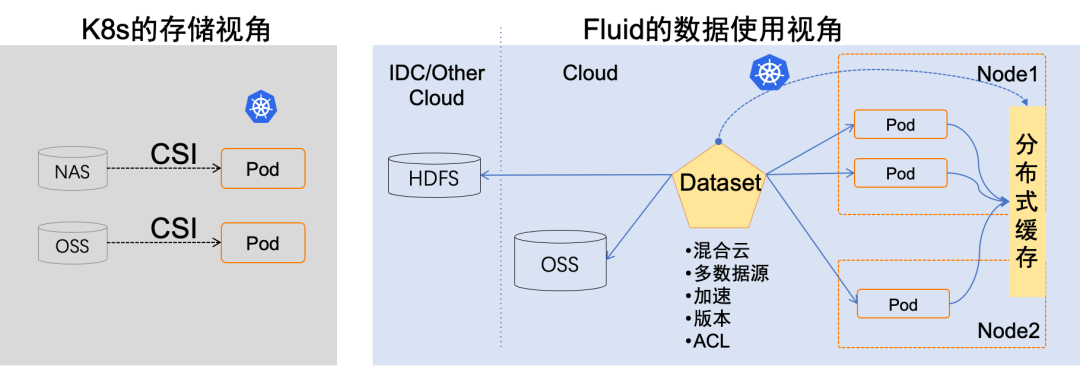
与传统的面向存储的 PVC 不同,Fluid 从应用角度出发,提出弹性数据集(Dataset)概念,对“在 Kubernetes 上使用数据的过程”进行抽象。Fluid 是 Kubernetes 生态的开源项目,由南京大学、阿里云以及 Alluxio 开源社区联合发起,已于 2021 年捐献给 CNCF 社区。
Fluid 让数据像流体一样,在各种存储源(如 NAS、CPFS、OSS 和 Ceph 等)和 Kubernetes 上层应用之间来去自如,灵活高效地移动、复制、驱逐、转换和管理。
Fluid 可以实现数据集的 CRUD 操作、权限控制和访问加速等功能,用户可以像访问 Kubernetes 原生数据卷一样直接访问抽象出来的数据。Fluid 当前主要关注数据集编排和应用编排这两个重要场景:
在数据集编排方面,Fluid 可以将指定数据集的数据缓存到指定特性的 Kubernetes 节点,以提高数据访问速度。
在应用编排方面,Fluid 可以将指定应用调度到已经存储了指定数据集的节点上,以减少数据传输成本和提高计算效率。
两者还可以组合协同编排,即协同考虑数据集和应用需求进行节点资源调度。
Fluid 为云原生 AI 与大数据应用提供一层高效便捷的数据抽象,并围绕抽象后的数据提供以下核心功能:
面向应用的数据集统一抽象
数据集抽象不仅汇总来自多个存储源的数据,还描述了数据的迁移性和特征,并提供可观测性,例如数据集总数据量、当前缓存空间大小以及缓存命中率。用户可以根据这些信息评估是否需要扩容或缩容缓存系统。
可扩展的数据引擎插件
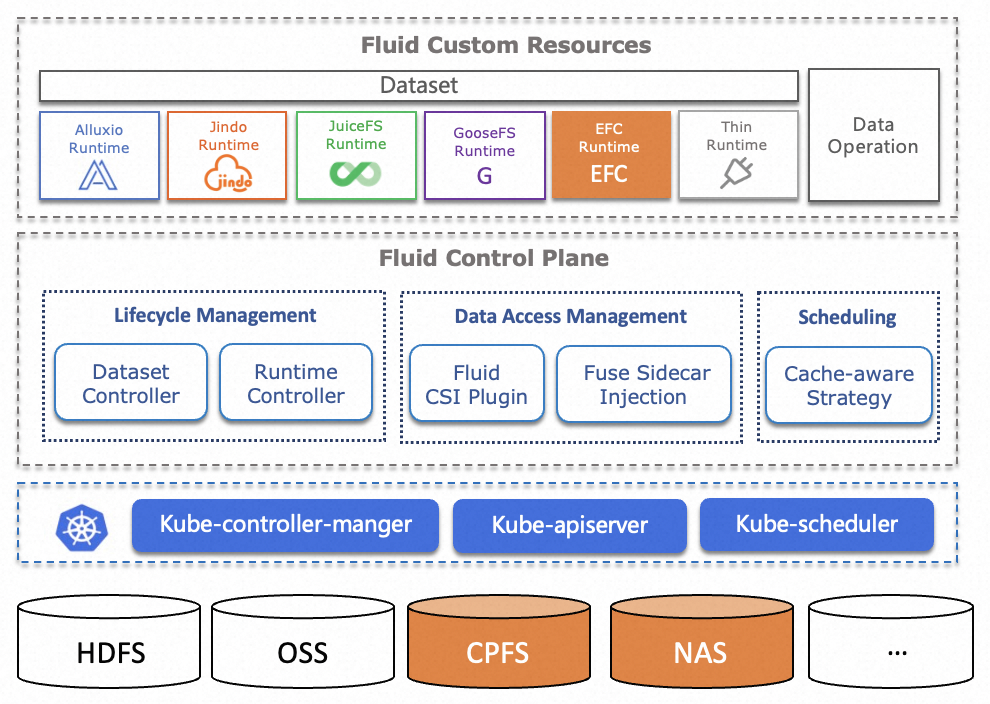
虽然 Dataset 是统一的抽象概念,但不同的存储有不同的 Runtime 接口,实际的数据操作需要由不同的 Runtime 实现。Fluid 的 Runtime 分为两类:CacheRuntime 实现缓存加速(包括开源分布式缓存 AlluxioRuntime、JuiceFSRuntime,阿里云 EFCRuntime、JindoRuntime 和腾讯云 GooseFSRuntime);ThinRuntime 提供统一访问接口(如 s3fs、nfs-fuse 等分布式存储系统),方便接入第三方存储。
自动化的数据操作
以 CRD 的方式提供数据预热,数据迁移,数据备份等多种操作,并且支持一次性、定时和事件驱动等多种模式,方便用户结合到自身自动化运维体系中。
通用数据加速
将数据分布式缓存技术与自动弹性(Autoscaling),可迁移(Portability),可观测(Observability),亲和性调度(Scheduling)等能力相结合,提升数据的访问性能。
运行时平台无关
支持原生、边缘、Serverless、多集群等多种 Kubernetes 形态,可以运行在公共云、边缘、混合云等多样化环境。可以根据环境差异选择 CSI Plugin 或 sidecar 模式运行存储的客户端。
EFC for 云原生存储,弹性加速保障业务稳定性
企业应用在云原生现代化之后,可以构建更多弹性的服务。相应而来的问题是,应用数据的存储如何同步实现云原生?
何为云原生存储?
云原生存储并不是在云上搭建的存储系统,也不是部署在 K8S 容器中的存储,而是可以完美的与 Kubernetes 环境融合,满足业务弹性和敏捷性的存储服务。
一个云原生存储需要满足以下要求:
1. 存储服务稳定性:系统各个节点的稳定性、自恢复能力必须满足需求。以文件存储为例,原来一个 NFS client 或者 FUSE 的 FO 只影响一台 ECS,而在云原生架构中,单点存储故障可能会影响一个容器集群中几十个 Pod。
2. 存储容量和性能弹性:传统分布式存储的性能随容量提升而提升,但是云原生环境中对存储的性能需求其实是随 Pod 的扩缩容而快速变化。存储系统需要在计算规模快速提升时,实现性能的弹性。
3. 支持计算 Pod 大规模伸缩:云原生应用场景对服务的敏捷度、灵活性要求非常高,很多场景期望容器的快速启动、灵活的调度,1 分钟弹出 1000-2000 个 Pod 都是家常便饭。这需要存储卷也能敏捷地根据 Pod 的变化而快速挂载。
4. 提供 Pod 粒度的可观测性:多数存储服务在文件系统级别提供了足够的监控能力,然后从云原生视角,提供 PV 和数据集视角的监控数据才能真正的帮助到云原生平台管理者。
5. 存储计算分离下提供接近本地存储的性能:存储计算分离带来了弹性和敏捷,但是网络延迟和远程访问协议的消耗也使得 Pod 访问存储的 I/O 性能出现大幅下降。需要新的技术降低负面性能影响。
然而,以上需求都不是依靠存储后端服务或客户端可以独立解决的。
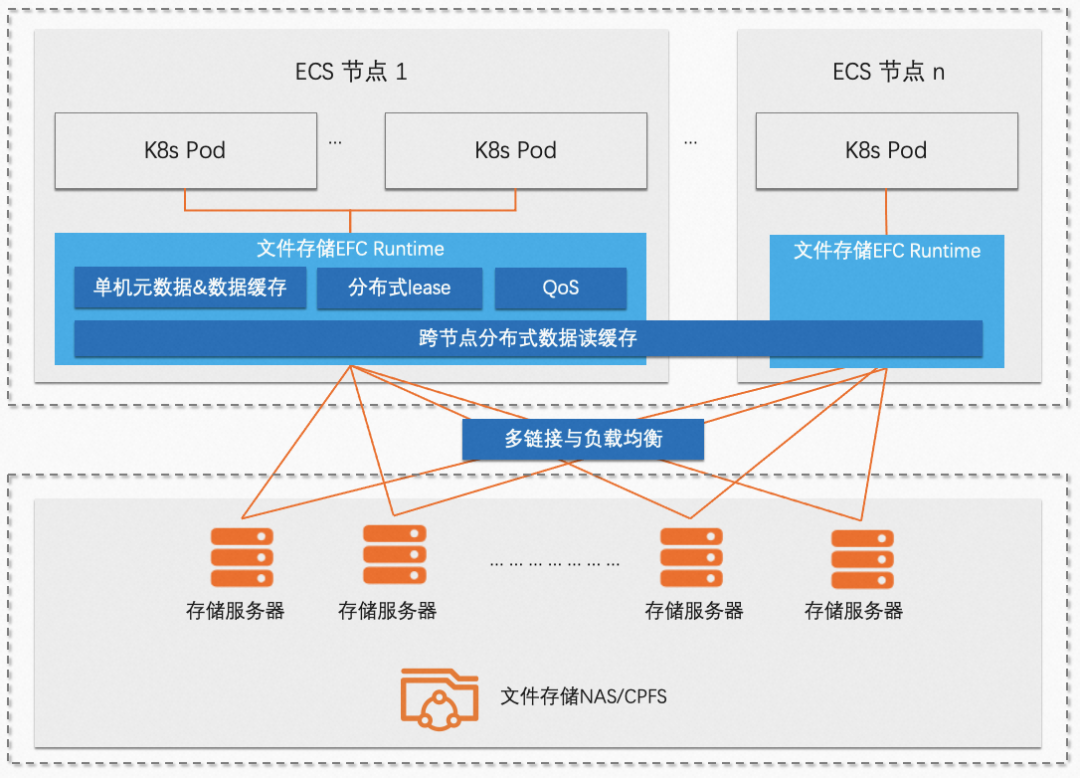
因此,阿里云推出了弹性文件客户端 —— EFC(Elastic File Client),结合阿里云文件存储服务的高扩展性,原生 POSIX 接口和高性能目录树结构,打造云原生存储系统。它替代 NAS 传统的内核态 NFS 客户端,提供多链接访问、元数据缓存、分布式数据缓存等加速能力,并提供端侧性能监控、QoS 能力,热升级能力。
同时,EFC 规避了使用开源 FUSE 的 POSIX 客户端无法秒级 Failover 的问题,保障大规模计算时业务的稳定性。
为数据密集应用量身打造, EFCRuntime 核心能力一览
EFCRuntime 是支撑 Dataset 访问加速能力的一种 Runtime 类型实现,其背后使用的缓存引擎为 EFC。Fluid 通过管理和调度 EFCRuntime 实现数据集的可见性、弹性伸缩、数据迁移、计算加速等。在 Fluid 上使用和部署 EFCRuntime 流程简单、兼容原生 Kubernetes 环境,并且能够自动可控地提升数据吞吐。
通过 EFCRuntime 访问阿里云文件存储,可以获得文件存储企业级基础功能以外的如下能力:
1. POSIX 协议:EFC 提供标准 POSIX 接口,结合文件存储 NAS 和 CPFS 服务,为容器应用提供通过 POSIX 接口访问共享数据的能力。
2. 秒级 Failover:EFC 提供了秒级 Failover 能力。当 FUSE 进程由于各种原因 crash 或者进行版本升级时,EFC 可以秒级自动拉起,保障业务 I/O 几乎不受影响。
3. 强一致的语义:EFC 通过强一致的分布式 lease 机制实现文件和目录的强一致:某 Pod 内的文件写入可以立刻被其他 Pod 读取;新文件创建出来后,就可以立刻让所有的其他客户端同步访问到,让用户更方便地在多节点间管理数据。
4. 强大的端上缓存能力:EFC 优化了 FUSE 的缓存逻辑,提供了更好的小文件读写性能,相比于传统的 NFS 客户端,性能提升 50% 以上。
5. 分布式缓存能力:EFC 内含了阿里云自研的分布式缓存技术,将多个节点的内存组合成超大缓存池,计算所需的热数据无需每次从远端读取,且吞吐和缓存池可以自然的随着计算规模扩大而扩大。
6. 小文件预取能力:EFC 有针对性的预取热目录下的热数据,节省拉取数据的开销。
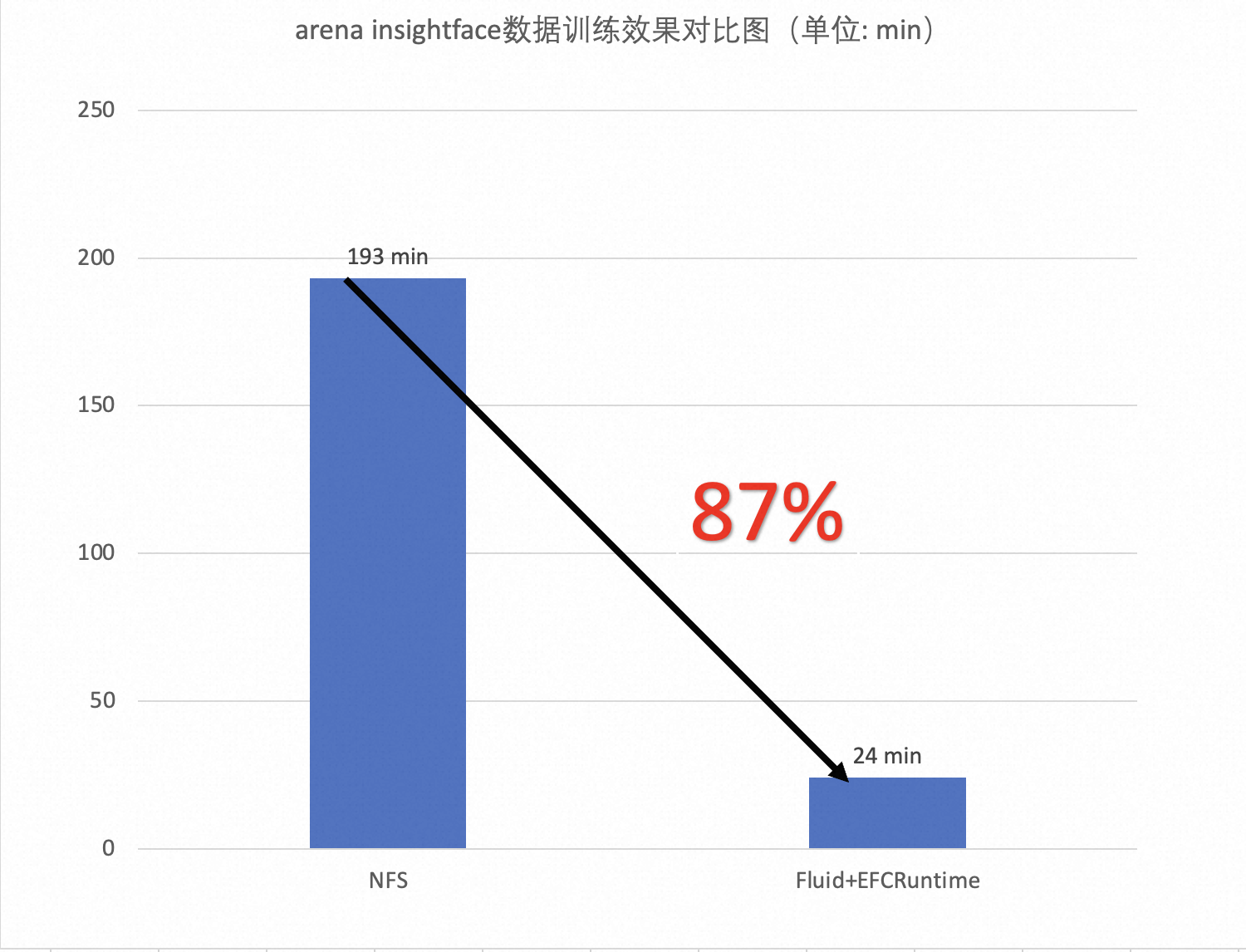
训练耗时可缩短 87%,性能优于开源 NFS
我们使用 insightface(ms1m-ibug) 数据集 [ 2] 基于 Kubernetes 集群并使用 Arena [ 3] 在此数据集上验证并发读取速度,基于 EFCRuntime 在开启本地缓存的情况下,性能大幅度优于开源 nfs,训练耗时缩短了 87%。(该测试场景会在后续相关文章中进行详细介绍)
如何快速上手使用 EFCRuntime ?
下面将以阿里云文件存储 NAS 为例,介绍如何快速使用 Fluid EFCRuntime 加速 NAS 文件访问。
首先,您需要准备好阿里云容器服务 ACK Pro 版集群和阿里云 NAS 文件系统。
随后,您只需要耗费 5 分钟左右时间,即可创建好需要的 EFCRuntime 环境,使用 EFCRuntime 的过程十分简单,您可以按照下面的流程进行部署。
Step1:创建 Dataset 和 EFCRuntime
创建一个 dataset.yaml 文件,文件中包含两部分:
首先包含 Dataset 自定义资源信息,Dataset 中声明需要挂载的阿里云 NAS 文件系统 URL(替换)以及 NAS 中的子路径(替换 )。
接下来需要创建一个 EFCRuntime,相当于启动一个 EFC 分布式集群来提供缓存服务。
1. mountPoint:表示挂载的 NAS 或者 CPFS 文件系统路径信息。例如:NAS 的格式为 nfs://:,CPFS 的格式为 cpfs://:;如果没有子目录要求可以使用根目录。
具体使用,请参考文档 [ 4] :https://help.aliyun.com/document_detail/600930.html?spm=a2c4g.207353.0.0.431b113b6APACM
replicas:表示创建的分布式集群的缓存 Worker 数量,可根据计算节点内存配置和数据集大小进行调整。建议 quota 和 replicas 乘积大于所需缓存的数据集总大小。
network 可选值为 ContainerNetwork 和 HostNetwork。ACK 环境中建议选择 ContainerNetwork,使用容器网络不会有额外的性能损失。
mediumtype:表示缓存类型,只支持 HDD/SSD/MEM 中的其中一种缓存类型。其中 MEM 代表内存,推荐使用 MEM。当使用 MEM 时,path 所指定的缓存数据存储目录需为内存文件系统(例如:tmpfs)
path:表示 EFC 缓存系统 Worker 的缓存数据存储目录。建议保持 /dev/shm。
quota:表示单个 Worker 组件提供的最大缓存容量。可根据计算节点内存配置和数据集大小进行调整。建议 quota 和 replicas 乘积大于所需缓存的数据集总大小。
查看 Dataset 的情况:
预期输出为:
Step2:创建应用容器体验加速效果
您可以通过创建应用容器来使用 EFC 加速服务,或者进行提交机器学习作业来进行体验相关功能。
接下来,我们将创建两个应用容器来访问该数据集中的同一个大小为 10GB 的文件,您也可以使用别的文件来进行测试,该文件需要预先存储在 NAS 文件系统中。
定义如下 app.yaml 的文件:
执行如下命令,查看待访问的数据文件大小:
执行如下命令,查看第一个应用容器中文件的读取时间(如果您使用自己的真实数据文件,请用真实文件路径替代/data/allzero-demo):
预期输出为:
接着,再另一个容器中,测试读取相同的 10G 大小文件的耗时如果您使用自己的真实数据文件,请用真实文件路径替代 /data/allzero-demo):
预期输出:
从上述输出信息,可发现吞吐量从原来的 648MiB/s 提高到了 1034.3MiB/s,对于相同文件的读取效率提升了 59.5%。
总结和展望
通过将 Fluid 和 EFC 相结合,可以更好地为云原生场景下的 AI 和大数据服务提供支持。这种组合可以通过标准化的数据预热和迁移等操作,提高数据使用效率并增强自动化运维的整合。
此外,我们还将支持 Serverless 场景下的运行,从而为 Serverless 容器提供更好的分布式文件存储访问体验。
最后,欢迎使用钉钉搜索群号加入我们,一起参与讨论(钉钉群号:33214567)。
相关链接:
[1] Fluid
https://github.com/fluid-cloudnative/fluid
[2] insightface(ms1m-ibug) 数据集
[3] Arena
https://help.aliyun.com/document_detail/212117.html?spm=a2c4g.212116.0.0.47f66806YlI7y4
[4] EFC 加速 NAS 或 CPFS 文件访问
https://help.aliyun.com/document_detail/600930.html?spm=a2c4g.207353.0.0.431b113b6APACM
版权声明: 本文为 InfoQ 作者【阿里巴巴云原生】的原创文章。
原文链接:【http://xie.infoq.cn/article/5fcec6963619c42c461edaae5】。文章转载请联系作者。

阿里云云原生 2019-05-21 加入
还未添加个人简介









评论