
聊聊多模态大模型处理的思考
多模态:文本、音频、视频、图像等多形态的展现形式。目前部门内业务要求领域大模型需要是多模态——支持音频/文本。从个人思考的角度来审视下,审视下多模态大模型的实现方式。首先就要区分输入与输出,即输入的模态与输出的模态。从目前来看,模型的输出大多都是文本,模型的输入一般是图片/文本;但少数的大模型比如 QWen、讯飞星火等支持语音的输入。
输入
对于输入来说,最需要考虑的就是 Embedding。不管是哪种大模型,其最终的输入都是张量数字的形式;其模型的结构都是神经网络模型,而神经网络模型计算的单位是张量。这中间就需要一个转换过程,也就是最常用听到看到的 Embedding。
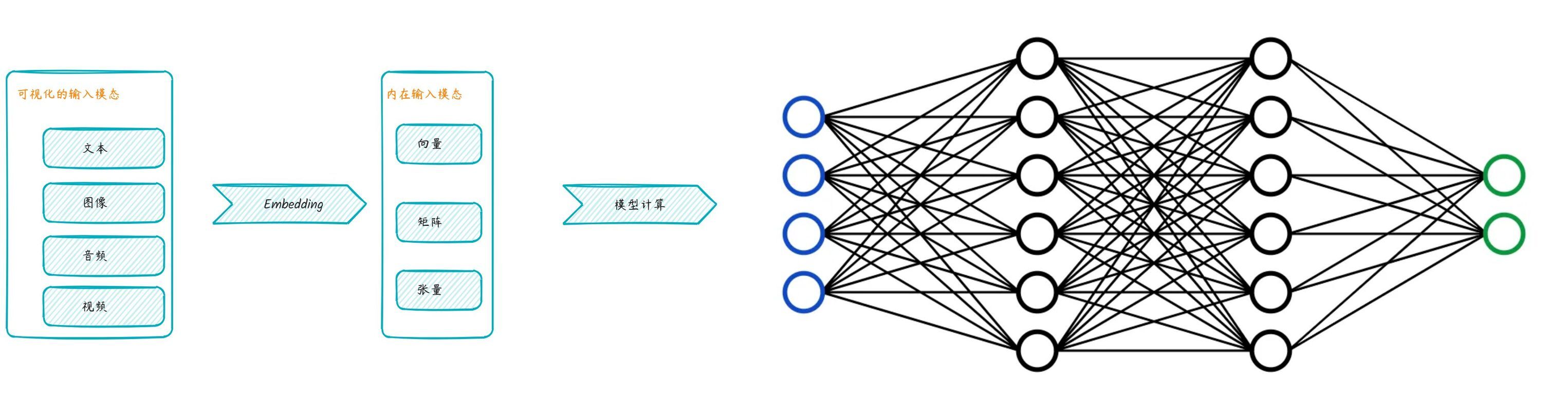
Embedding 的作用是巨大的,不论是在深度学习领域还是推荐系统领域、搜索引擎领域等等;而且也衍生出向量数据库的概念;存的就是这些 Embedding 后的张量。
多模态基座模型
即原生基座模型,比如 GLM、LlaMa2、QWen、文心一言等基座模型支持多模态的输入输出,从个人调研来看,GLM、文心一言对这方面的支持比较弱,仅支持文本/图像;LlaMa2 有开源的实现支持文本/图像/音视频;QWen 是最全的,阿里对其支持很到位,而且在魔塔社区,阿里开源了很多的音视频模型,还是蛮强大覆盖很全的。以 Llama2 实现为例,官方地址:Video-LLaMA;其架构图如下:
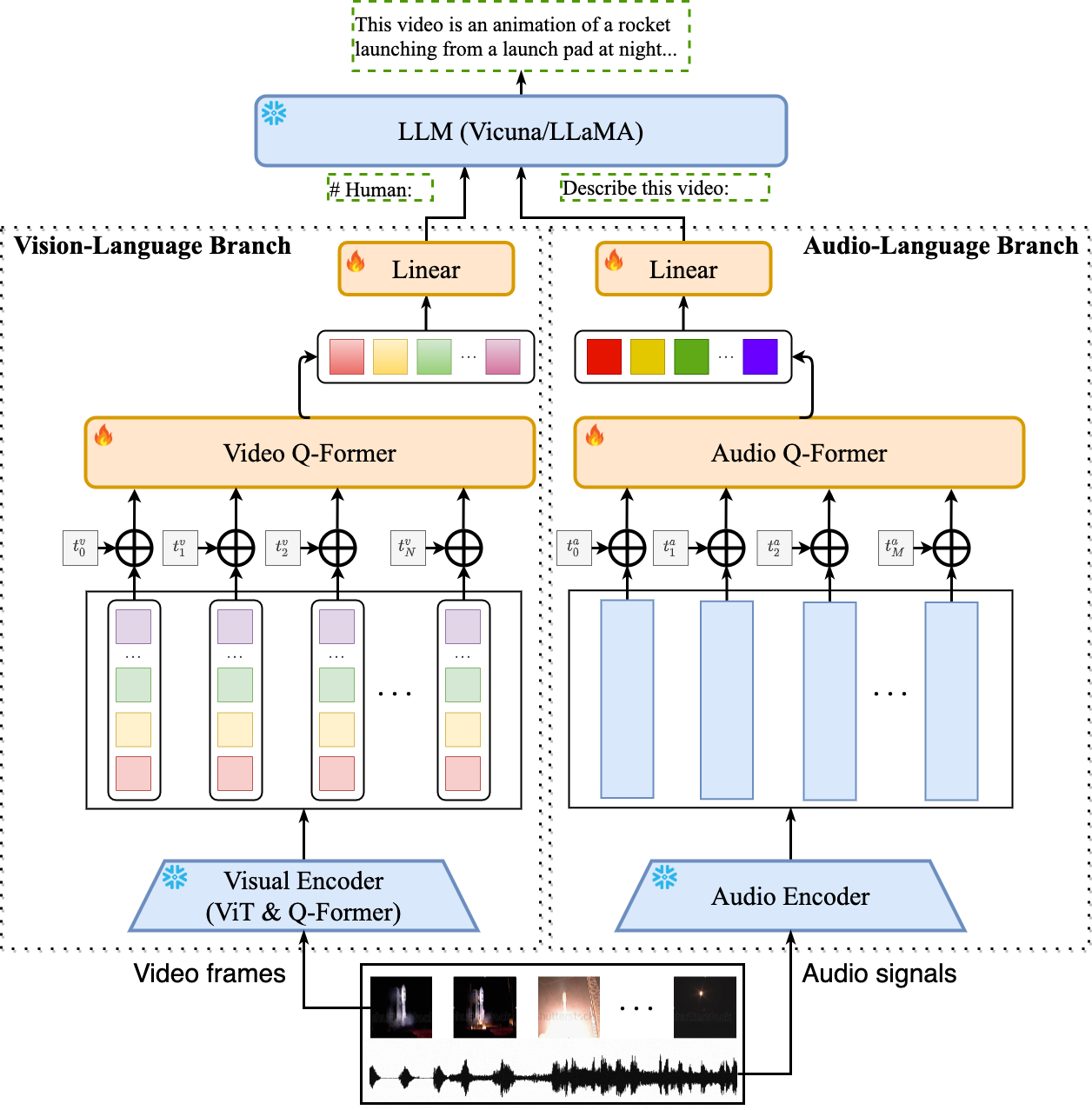
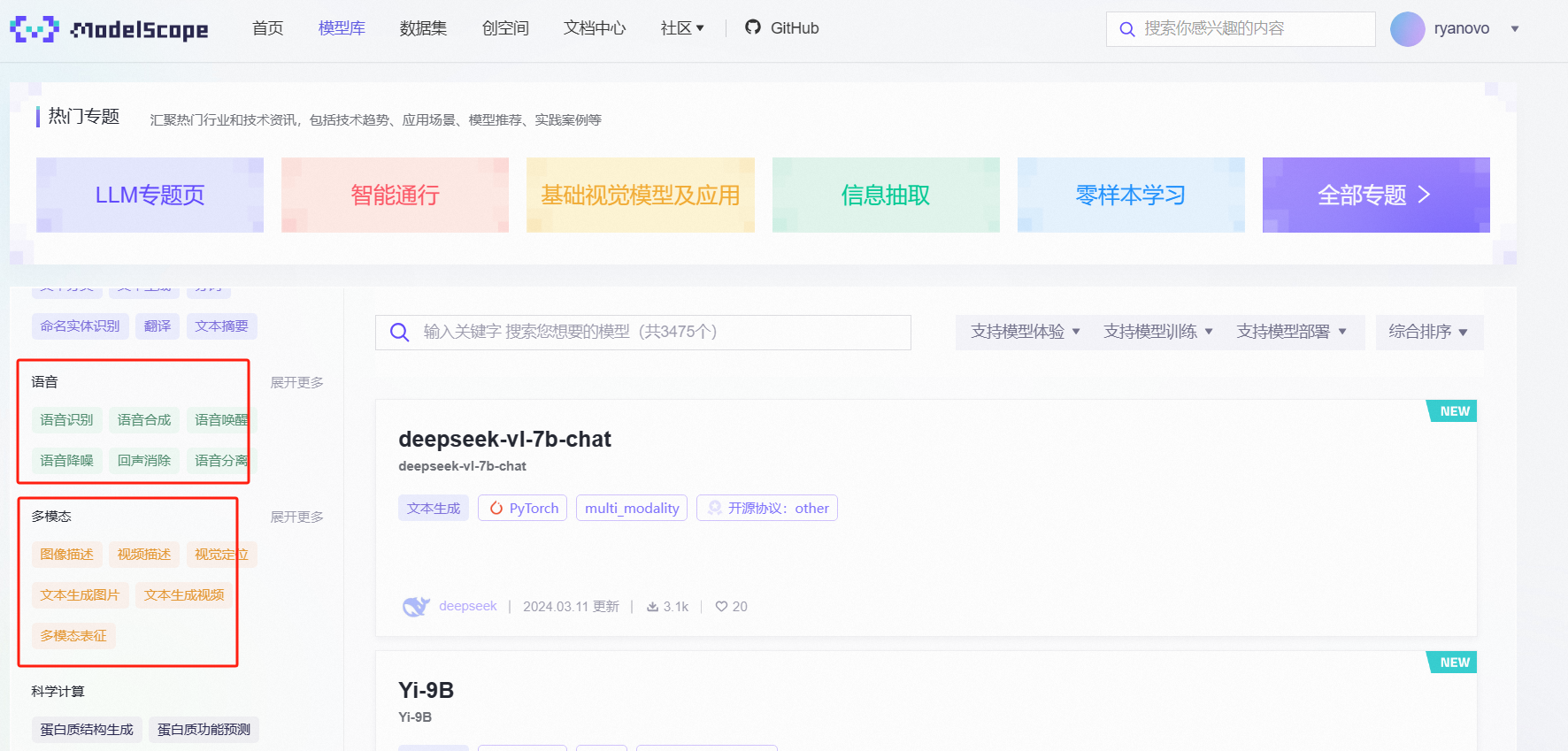
输入的 Embedding 化都在模型内部已处理完毕,我们无需考虑。魔塔社区/HuggingFace 上,已经开源了很多高质量的多模态模型,截个图展示下:
文本化处理
使用开源/商务组件处理输入的内容,将其文本化,再输入到模型中;然后再经历输入部分的流程。

但对于这类的处理来说,需要考虑的问题还是比较多:
组件转换文本的准确性
组件转换的损失
大模型中 Embedding 组件将输入文本 Embedding 化时的损失
第一点不用叙述;第二点,如果组件的处理不到位,遗漏了一些语气词或是某些情感词之类的,对输出文本的内容表达、语义表达将产生一定的损失。第三点,如果转换后的文本语义与文本内容不对应,比如同音词或是生僻字的情况下,导致 Embedding 化时产生一定的损失。
Embedding 化处理
利用某种 Embedding 模型,将输入的内容直接 Embedding 化,生成张量后,直接丢进大模型中。在这里需要考虑两点:
大模型支持 Embedding 的输入
Embedding 组件与大模型内置的 Embedding 组件要一致
大模型训练时,有自己的内置的 Embedding 组件,如果输入时的 Embedding 组件产生的张量与训练时的 Embedding 张量不一致,这就是两种不同的 Embedding 组件导致的问题,其最终的效果将会大打折扣。
输出
模型的输出虽然最终也是经过处理后,生成文本;但这就已经很满足绝大多数的需求。而对于很多场景下,比如我们的场景需要再制定角色语音包,也是很好处理的。这个过程其实就是语音合成的过程。比如,开车导航时的语音包,有不同的人物声音,这都是语音合成处理的。
总结
最终来看,第一个方案肯定是最合适的;但如果对于选型的大模型不支持多模态的情况下,考虑开源实现或是第二张方案,但要综合调研其带来的影响,并不是简单的转文本就行。第三种,目前我没有找到合适的 Embedding 模型支持多模态,后续继续探讨挖掘下。
文章转载自:又见阿郎

还未添加个人签名 2023-06-19 加入
还未添加个人简介






评论