
【scikit-learn 基础】--『数据加载』之样本生成器
除了内置的数据集,scikit-learn还提供了随机样本的生成器。通过这些生成器函数,可以生成具有特定特性和分布的随机数据集,以帮助进行机器学习算法的研究、测试和比较。
目前,scikit-learn库(v1.3.0版)中有 20 个不同的生成样本的函数。本篇重点介绍其中几个具有代表性的函数。
1. 分类聚类数据样本
分类和聚类是机器学习中使用频率最高的算法,创建各种相关的样本数据,能够帮助我们更好的试验算法。
1.1. make_blobs
这个函数通常用于可视化分类器的学习过程,它生成由聚类组成的非线性数据集。
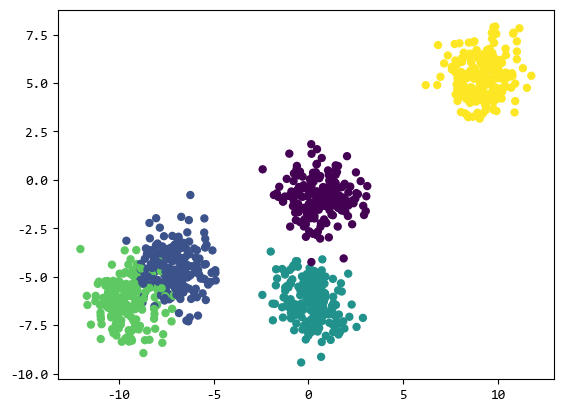
上面的示例生成了 1000 个点的数据,分为 5 个类别。
make_blobs的主要参数包括:
n_samples:生成的样本数。
n_features:每个样本的特征数。通常为 2,表示我们生成的是二维数据。
centers:聚类的数量。即生成的样本会被分为多少类。
cluster_std:每个聚类的标准差。这决定了聚类的形状和大小。
shuffle:是否在生成数据后打乱样本。
random_state:随机数生成器的种子。这确保了每次运行代码时生成的数据集都是一样的。
1.2. make_classification
这是一个用于生成复杂二维数据的函数,通常用于可视化分类器的学习过程或者测试机器学习算法的性能。
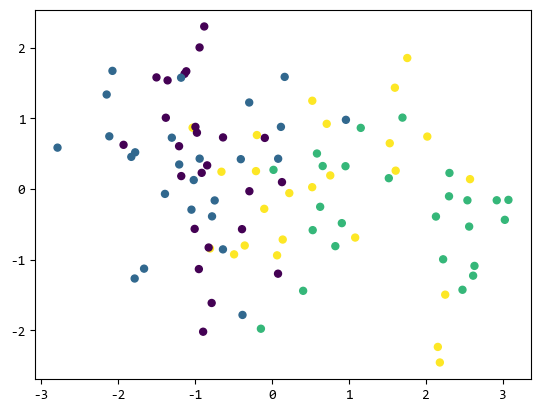
可以看出它生成的各类数据交织在一起,很难做线性的分类。
make_classification的主要参数包括:
n_samples:生成的样本数。
n_features:每个样本的特征数。这个参数决定了生成的数据集的维度。
n_informative:具有信息量的特征的数量。这个参数决定了特征集中的特征有多少是有助于分类的。
n_redundant:冗余特征的数量。这个参数决定了特征集中的特征有多少是重复或者没有信息的。
random_state:随机数生成器的种子。这确保了每次运行代码时生成的数据集都是一样的。
1.3. make_moons
和函数名称所表达的一样,它是一个用于生成形状类似于月牙的数据集的函数,通常用于可视化分类器的学习过程或者测试机器学习算法的性能。
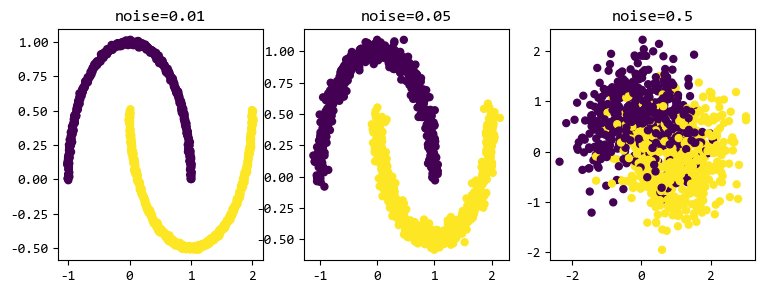
noise越小,数据的分类越明显。
make_moons的主要参数包括:
n_samples:生成的样本数。
noise:在数据集中添加的噪声的标准差。这个参数决定了月牙的噪声程度。
random_state:随机数生成器的种子。这确保了每次运行代码时生成的数据集都是一样的。
2. 回归数据样本
除了分类和聚类,回归是机器学习的另一个重要方向。scikit-learn同样也提供了创建回归数据样本的函数。
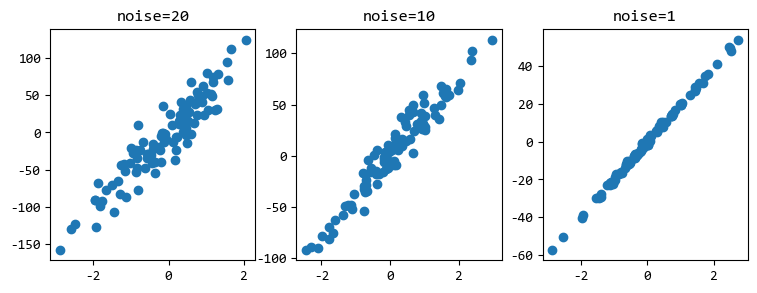
通过调节noise参数,可以创建不同精确度的回归数据。
make_regression的主要参数包括:
n_samples:生成的样本数。
n_features:每个样本的特征数。通常为一个较小的值,表示我们生成的是一维数据。
noise:噪音的大小。它为数据添加一些随机噪声,以使结果更接近现实情况。
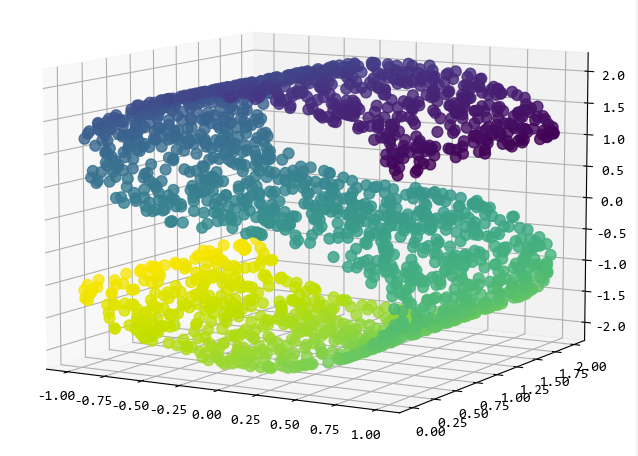
3. 流形数据样本
所谓流形数据,就是 S 形或者瑞士卷那样旋转的数据,可以用来测试更复杂的分类模型的效果。比如下面的make_s_curve函数,就可以创建 S 形的数据:
4. 总结
本文介绍的生成样本数据的函数只是scikit-learn库中各种生成器的一部分,还有很多种其他的生成器函数可以生成更加复杂的样本数据。
所有的生成器函数请参考文档:https://scikit-learn.org/stable/modules/classes.html#samples-generator
文章转载自:wang_yb

还未添加个人签名 2023-06-19 加入
还未添加个人简介









评论