
Elasticsearch 基本概念与使用
简介
Elasticsearch 是一个分布式搜索和数据分析引擎。
随着业务的增长,数据量越来越大,传统的数据库在处理文本搜索、海量数据统计分析的时候总是力不从心,当面对这些搜索需求时,我们更倾向于使用 Elasticsearch。
基本概念
数据层的概念
1. Index
文档的集合,每个 Index 都是一个文档的集合。ES 将数据存储在一个或者多个 Index 中,例如将团队数据存储在 Team Index 中,而将用户数据存储在 User Index 中。
2. Mapping
Mapping 定义了 Index 里的文档有哪些字段以及这些字段的类型、特性等,类似于传统数据库中表结构的定义。Mapping 的作用:
定义 Index 里各个字段的名称以及类型;
定义各个字段的特性。例如这个字段是否被索引、用什么分词器等;
除了可以预先定义好 Mapping,还有一种 Dynamic Mapping 的方式,使用 Dynamic Mapping,我们不需要手动定义 Mapping,ES 会帮我们根据文档的信息自动推算出各个字段的信息,也就是如果写入文档时 Index 不存在会自动创建 Index,或者写入的字段不存在也会自动创建这个字段。但是对于复杂场景或者字段比较多,推断出来的可能与预期有一定差别,所以在生产环境还是建议预先定义 Mapping。
3.字段(Field)
每个文档都有一个或者多个字段。每个字段都有指定的类型,常见的类型有:keyword、text、数字类型(integer、long、float、double 等)等。
其中,keyword 类型适合存储结构化的字符串,例如 ID、邮件地址、编号等。keyword 类型数据通常被用在 term query、排序等。
text 类型的字段适合存储全文本数据,如描述内容、文档内容等。text 的类型数据将会被分词器进行分词,最终成为一个个词项存储在倒排索引中。
4. 文档(Doc)
我们向 ES 中写入的每一条数据都是一个文档,类似传统数据库中的一条记录,文档是 ES 中的主要实体。文档有以下几个特性:
ES 是面向文档的并且以文档为单位进行搜索的。
文档以 JSON 格式进行序列化存储。
每个文档都有唯一的 ID。
5. 词项(Term)
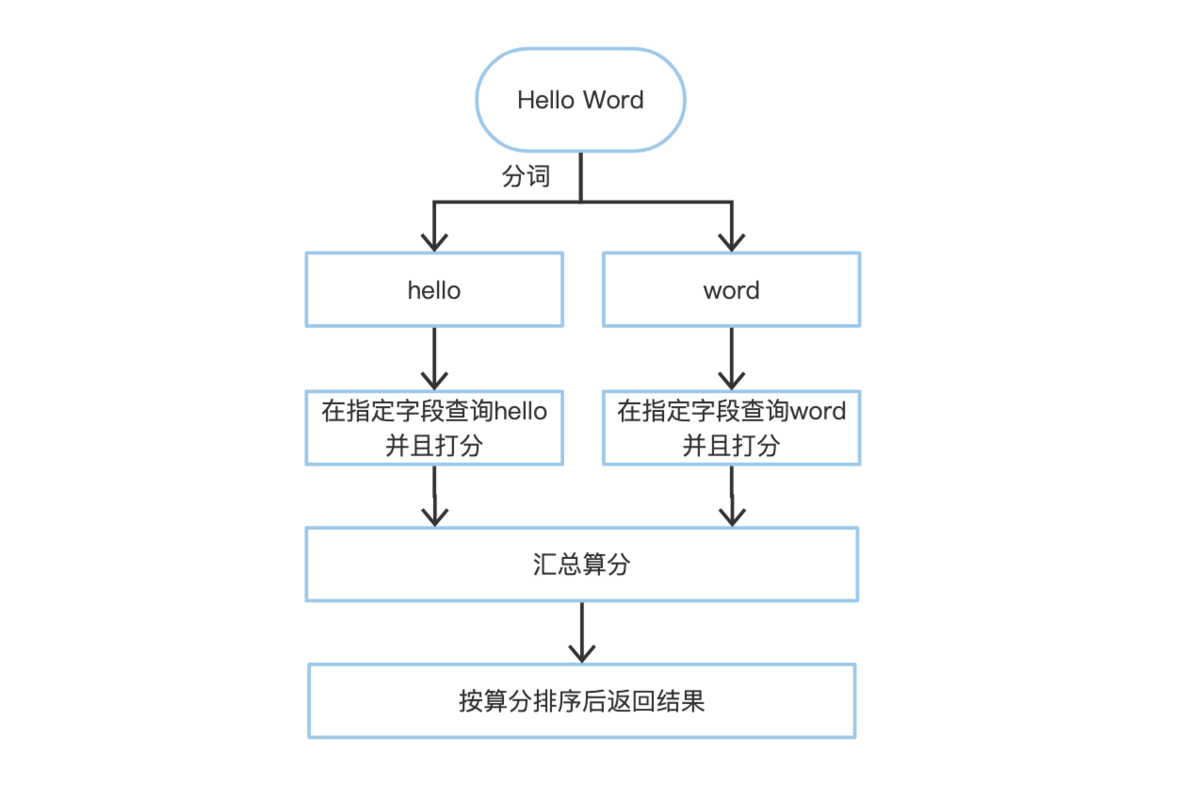
将全文本的内容通过分词器进行分词,得到的词语就是词项。例如 "Hello Word" 使用标准分词器分词后得到 [hello, word] 这 2 个词项,这个分词器会将文本按单词切分并且转为小写。
6. 倒排索引与正排索引
索引从本质来讲就是一种为了加快检索数据的存储结构。
将建立实体 ID 与实体数据关联关系的数据结构叫做正排索引。
将建立词项与文档实体关联关系的数据结构叫做倒排索引。
系统层概念
1. 近实时系统
ES 是一个近实时系统,默认情况下我们写入的数据在 1 秒后才能被查询到。所以我们刚写入数据后,如果立即查询,有可能会查询不到数据或者获取到旧数据。
2. Lucene
Lucene 是一个用于全文检索的开源项目,而 ES 是基于 Lucene 实现的,ES 是在 Lucene 上增加了分布式特性的系统服务。
3. 相关性评分
全文本数据的检索是用相关性来决定最后的返回结果的,相关性的指标是相关性评分。
文档的基础操作
一、新建文档
ES 提供了两种创建文档的方式,一种是使用 Index API 创建文档,一种是使用 Create API 创建文档。

上面是新建文档时 3 种写法的总结,如果需要系统为你创建文档 ID,应该使用第一种方式;如果有更新文档内容的需求,应该使用第二种方式;如果写入文档时有唯一性校验需求的话,应该使用第三种方式;相对于第二种方式来说,第一种方式写入的效率会更高,因为不需要在库里查询文档是否已经存在,并且进行后续的删除工作。
二、获取文档

三、更新文档

四、删除文档
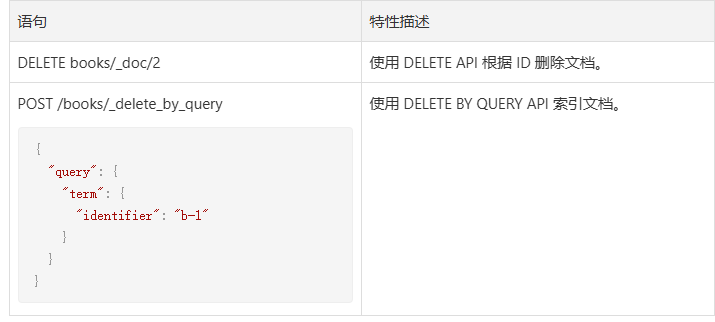
五、批量操作文档
当我们需要写入多个文档的时候,可以使用 Bulk API 来批量处理文档。
Bulk API 支持在一次调用中操作不同的 Index,而且还可以同时支持 4 种类型的操作:
Index
Create
Update
Delete
Bulk API 的格式是使用换行符分隔 JSON 的结构,第一行指定操作类型、索引、文档 id 等,下一行是这个操作的内容(文档数据,如果有的话,像删除就没有)。
满足搜索需求的 API
一、全文搜索
在讲全文搜索 API 前,我们先了解一下全文搜索的过程。在我们写入数据的时候,首先系统会使用分词器把文本类型的数据进行分词,当我们对文本类型的数据进行检索时,会使用同样的分词器对检索内容进行分词,然后与保存的文本内容匹配并打分,最后根据公式算出相关性评分,即内容的相似性,最后返回相关性最高的 N 个文档给用户。下面描述一下使用标准分词器进行分词的过程:
本次主要介绍以下几个全文搜索的 API :
match,匹配查询。
match phrase,短语匹配查询,这些词语需要全部出现在被检索的内容中,并且顺序一致且连续。
1. match
匹配查询,其示例如下:
match API 提供了 operator 和 minimum_should_match 参数:
operator,参数值可以为 "or" 或者 "and" 来控制检索词项间的关系,默认值为 "or"。
minimum_should_match,可以指定检索时词项的最少匹配个数,一般将其设置为一个百分比。
如上示例,至少有 75% 的词项匹配上的文档才会返回。
2. match phrase
短语匹配会将检索内容进行分词,这些词语需要全部出现在被检索内容中,并且顺序一致,这些词都必须连续。
match phrase API 提供了 slop 参数:
slop,来指定检索的词项间的距离差值,也就是两个词项中可以有多少个不相关的词语,slop 默认是 0。
二、Term Query API
与全文搜索不同,Term Query API 是基于词项查询的 API, 是不需要对输入内容进行分词的。Term Query API 会将输入的内容会作为一个整体来进行检索,并且使用相关性算分公式对包含整个检索内容的文档进行相关性算分。
ES 中提供很多基于 Term 的查询功能:
Term Query,返回在指定字段中准确包含了检索内容的文档。
Terms Query,跟 Term Query 类似,不过可以同时检索多个词项的功能。
Range Query,范围查询。
Exist Query,返回在指定字段上有值的文档,一般用于过滤没有值的文档。
Prefix Query,返回在指定字段中包含指定前缀的文档。
Wildcard Query,通配符查询。
1. Term Query
Term Query API 返回在指定字段中准确包含了检索内容的文档,你可以使用此 API 去查询精确值的字段,如书本 ID、编号等。其示例如下:
我们一般不在 text 类型的字段上使用 Term Query,比如搜索书名中含有 "Hello" 的文档,如果我们数据中确实有本书名叫“Hello Word”,但是却无法匹配上。因为基于 Term 的查询不会对检索内容进行分词,但是在我们写入数据的时候,如果使用的是标准分词器,除了分词还会将词项转化为小写,所以上述的例子就匹配不到任何文档了。如果要对 text 类型的字段进行检索,建议使用 Match API 。
另外,我们一般使用 Term Query API 进行结构化搜索,例如 ID、日期、颜色、编号等等。当我们对结构化数据进行精确匹配时,可以考虑跳过相关性算分的步骤,来提高搜索的性能。推荐使用 Constant Score,它可以忽略相关性算分的环节,从而提高查询的性能。
2. Range Query
Range Query API 可以查询字段值符合某个范围的文档数据。其示例如下:
3. Exist Query
使用 Exist Query API 可以查询那些在指定字段上有值的文档。
4. Wildcard Query
Wildcard Query 使用通配符表达式进行匹配。Wildcard Query 支持两个通配符:
?,使用 ? 来匹配任意字符。
*,使用 * 来匹配 0 或多个字符。
需要注意的是,Wildcard Query 在进行查询的时候需要扫描倒排索引中的词项列表才能找到全部匹配的词项,然后再获取匹配词项对应的文档 ID。所以使用 Wildcard Query API 的时候需要注意性能问题,要尽量避免使用左通配匹配模式,如 "*hello"。
通过上面对全文搜索和 Term Query API 的介绍,我们总结 match 和 term 在查询时的主要区别是:
term 在搜索 text 类型数据前不会对搜索内容进行分词,直接对词项搜索,而 match 搜索前会对搜索内容进行分词;
match 适合做全文本搜索,而 term 适合进行结构化搜索,做一些精确查询,比如对 keyword、数字等类型的数据进行精确搜索;
下面通过以下几个示例来感受一下在 text 类型使用 match query 和 term query 的区别。
1、term 查询 text 类型
结果
结果
2、match 查询 text 类型
结果
结果
全文搜索背后的支撑:倒排索引
索引从本质来讲就是一种为了加快检索数据的存储结构,而 ES 能快速的进行全文检索的核心技术之一就是倒排索引。
为了更好地帮助理解,这里有两种场景:
给定古诗词的名称,背诵古诗词的内容
给定多个词语,说出带有这些词语的古诗词的名称
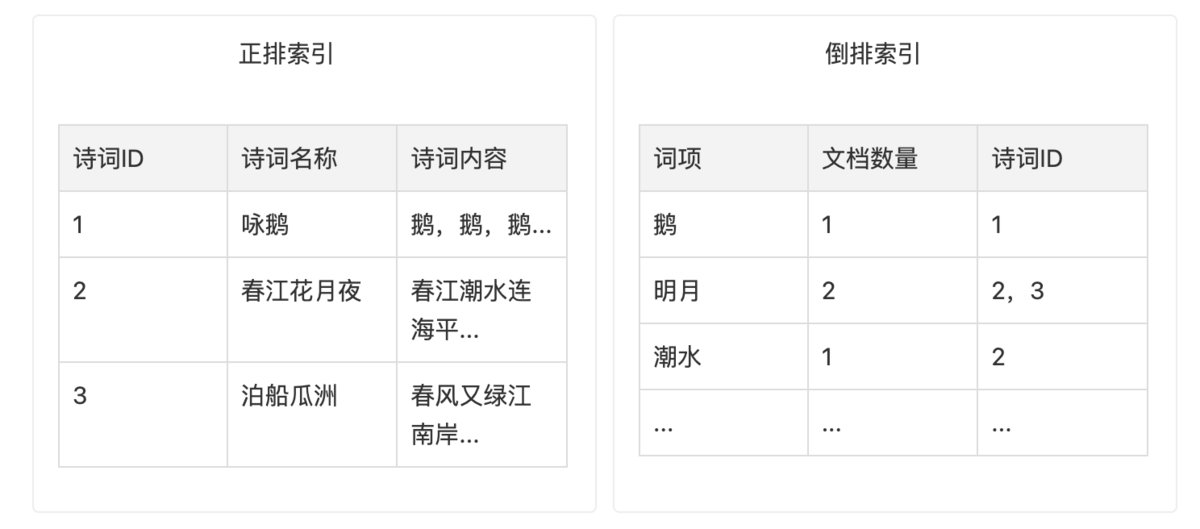
第一种就是正排索引,把诗词的名字作为唯一 ID,像这种建立实体 ID 到数据实体数据的关联关系的索引我们称为正排索引。
而倒排索引则是相反的,我们把所有诗词的内容进行分词,然后建立各个词语到诗词名称的索引,这种把分词后建立词项到实体 ID 关系的索引称为倒排索引。
倒排索引的组成主要有 3 个部分:Term Index、Term Dictionary 和 Posting List。其中,Term Dictionary 保存的是词项,我们知道,词项可能是海量的,在这种情况洗我们如果从 Term Dictionary 中查找一个词项势必比较慢,所以必须对这些词项做索引,这样就有了 Term Index,它是 Term Dictionary 的索引。而 Posting List 则保存着每个词项对应的文档 ID 列表。
我们都知道一个文档有多个字段,在 ES 中对于文本类型的字段,它们的内容会被分词器分成多个词项,这些词项是以块的形式保存在 Term Dictionary 中的,并且系统会对 Term Dictionary 的内容做索引形成 Term Index。在搜索的时候,通过 Term Index 找到 Block 后进一步找到 Term 对应的 Posting List 中的文档 ID。
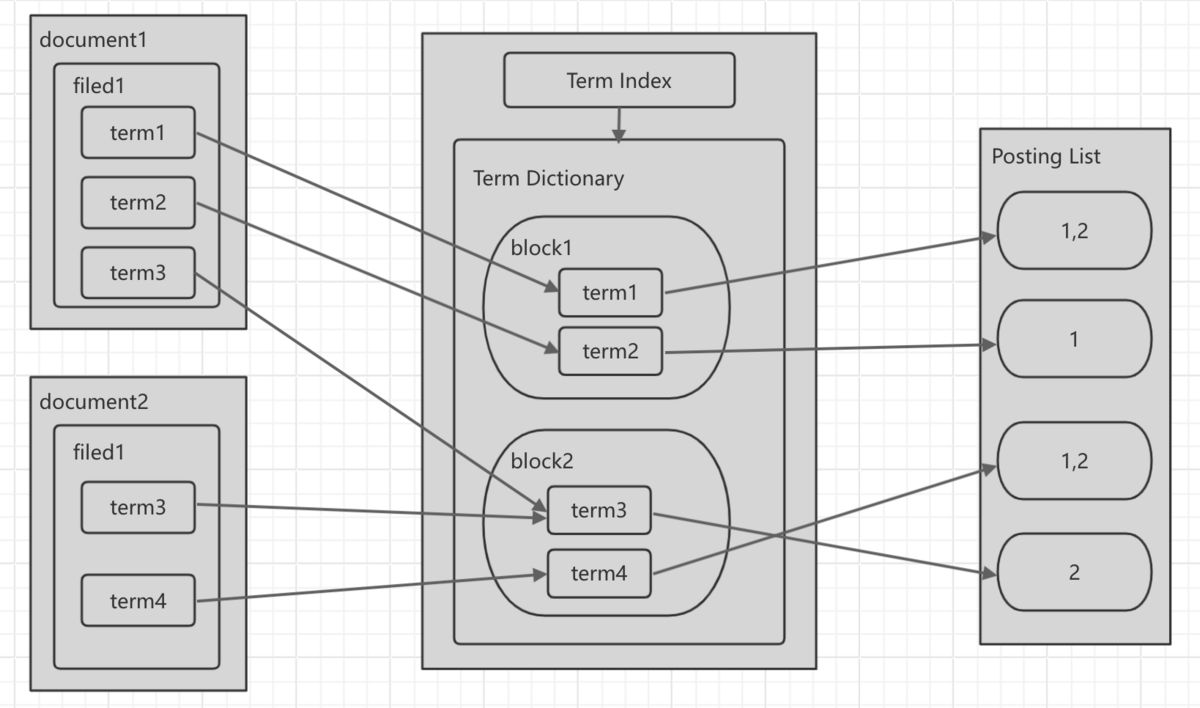
Term Index 采用的是前缀索引,我们都知道索引也是占用内存的,所以索引消耗的资源越小越好。我们把 Term Dictionary 中的 Term 排序后按公共前缀抽取出来按块存储,这样的话,拥有同一公共前缀的 Term 会共用一个索引,通过索引找到对应的块,块里的数据都是有序的,然后找到对应的 Term 以及对应的 Posting List 信息。前缀索引使用了 FST 算法,这里不展开介绍了。
总结
本次从 0 到 1 带大家认识了 Elasticsearch,更多内容和细节需要大家在开发中去阅读官方文档并实践,以便根据业务的特点快速构建出相应的搜索业务。
参考: 官方文档

还未添加个人签名 2020-09-24 加入
分享技术知识、管理工具






评论