
Unity JobSystem 使用及技巧
什么是 JobSystem
并行编程
在游戏开发过程中我们经常会遇到要处理大量数据计算的需求,因此为了充分发挥硬件的多核性能,我们会需要用到并行编程,多线程编程也是并行编程的一种。
线程是在进程内的,是共享进程内存的执行流,线程上下文切换的开销是相当高的,大概有 2000 的 CPU Circle,同时会导致缓存失效,导致万级别的 CPU Circle,Job System 的设计使用了线程池,一开始先将大量的计算任务分配下去尽量减少线程的执行流被打断,也降低了一些 thread 的切换开销。获取地址:http://www.jnpfsoft.com/?from=infoq
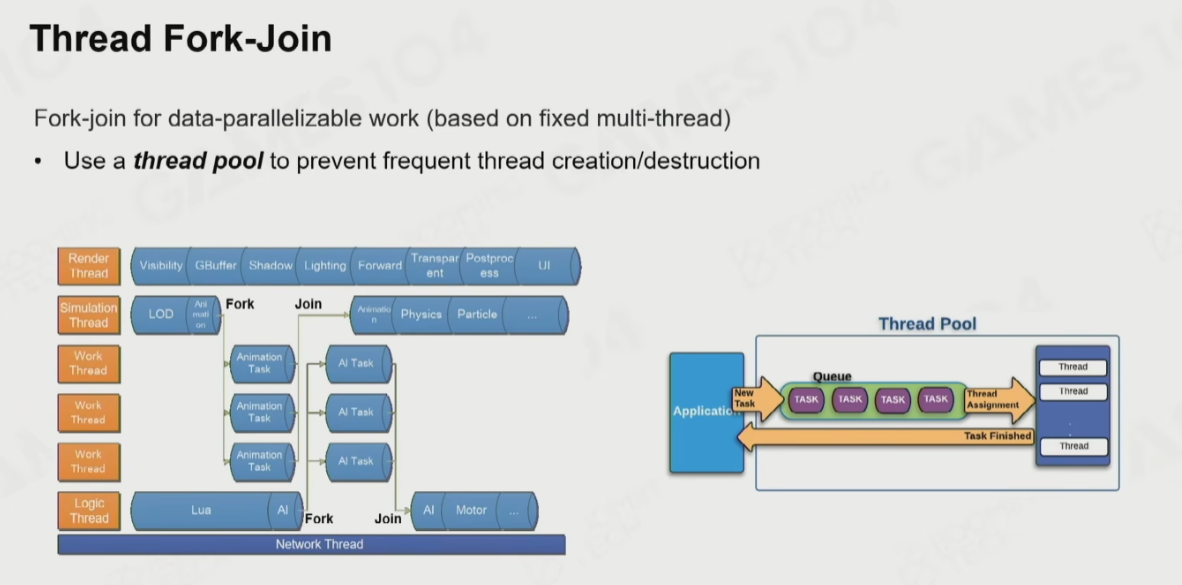
Unreal Unity 大部分都是这种模型,分配了一些 work thread 然后其他的线程往这个线程塞 Task,相比 fixed thread 模式性能好一些,多出了 Task 的概念,Unity 里称这个为 Job。
Unity JobSystem
通常 Unity 在一个线程上执行代码,该线程默认在程序开始时运行,称为主线程。我们在主线程使用 JobSystem 的 API,去给 worker 线程下发任务,就是使用多线程。
通常 Unity JobSystem 会和 Burst 编译器一起使用,Burst 会把 IL 变成使用 LLVM 优化的 CPU 代码,执行效率可以说大幅提升,但是使用 Burst 时候 debug 会变得困难,会缺少一些报错的堆栈,此时关闭 burst 可以看到一些堆栈,更方便 debug。虽然并行编程有着种种的技巧,比如,线程之间沟通交流数据有需要加锁、原子操作等等的数据交换等操作。但是 Unity 为了让我们更容易的编写多线程代码,
通过一些规则的制定,规避了一些复杂行为,同时也限制了一些功能,必要时这些功能也可以通过添加 attribute、或者使用指针的方式来打破一些规则。规定包括但不限于:
不允许访问静态变量
不允许在 Job 里调度子 Job
只能向 Job 里传递值类型,并且是通过拷贝的方式从主线程将数据传输进 Job,当 Job 运行结束数据会拷贝回主线程,我们可以在主线程的 job 对象访问 Job 的执行结果。
不允许在 Native 容器里添加托管类型
不允许使用指针
不允许多个 Job 同时写入同一个地方
不允许在 Job 里分配额外内存
可以查看 官方文档。
应用场景
基本上所有需要处理数据计算的场景都可以使用,我们可以用它做大量的游戏逻辑的计算,我们也可以用它来做一些编辑器下的工具,可以达到加速的效果。
细节
接口
unity 官方提供了一系列的接口,写一个 Struct 实现接口便可以执行多线程代码,提供的接口包括:
IJob:一个线程
IJobParallelFor:多线程,使用时传入一个数组,根据数组长度会划分出任务数量,每个任务的索引就是数组元素的索引
IJobParallelForTransform:并行访问 Transform 组件的,这是 unity 自己实现的比较特殊的读写 Transform 信息的 Job,实测下来用起来貌似 worker 还是一个在动,但是经过 Burst 编译后快不少。
IJobFor:几乎没用
IJobParallelFor 是最常用的,对数据源中的每一项都调用一次 Execute 方法。Execute 方法中有一个整数参数。该索引用于访问和操作作业实现中的数据源的单个元素。
容器
Job 使用的数据都需要使用 Unity 提供的 Native 容器,我们在主线程将要计算的数据装进 NativeContainer 里然后再传进 Job。主要会使用的容器就是 NativeArray,其实就是一个原生的数组类型,其他的容器这里暂时不提这些容器还要指定分配器,分配器包括
Allocator.Temp: 最快的配置。将其用于生命周期为一帧或更少的分配。从主线程传数据给 Job 时,不能使用 Temp 分配器。Allocator.TempJob: 分配比 慢Temp但比 快Persistent。在四帧的生命周期内使用它进行线程安全分配。Allocator.Persistent: 最慢的分配,但只要你需要它就可以持续,如果有必要,可以贯穿应用程序的整个生命周期。它是直接调用 malloc. 较长的作业可以使用此 NativeContainer 分配类型。
容器在实现 Job 的 Struct 里可以打标记,包括 ReadOnly、WriteOnly,一方面可以提升性能,另一方面有时候会有读写冲突的情况,此时应该尽量多标记 ReadOnly,避免一些数据冲突。
创建 使用
官方文档已经说的很好。https://docs.unity3d.com/Manual/JobSystemCreatingJobs.html对于 ParallelFor 的 Schedule 多了一些参数,innerloopBatchCount 这个参数可以留意一下,可以理解为一个线程次性拿走多少任务。
Job 之间互相依赖
https://docs.unity3d.com/Manual/JobSystemJobDependencies.html
其实执行了一个 Job 之后,在主线再执行另一个 Job 也不会性能差很多,并且易于 debug,可以断点查看多个阶段执行过程中 Job 的数据情况,但是追求完美还是可以把依赖填上。
性能测试比较
笔者曾经做过简单的使用 Job 和不用 Job 的对比,通过打上 Unity Profiler 的标记,可以方便的在图表里查看运行开销。
IJob
使用 IJob 执行一项复杂的工作,没有使用 job 跑了 2-4ms,使用 job 也是跑了 2-4 ms,但是使用了 job+burst,这个 for 循环的速度就变得只有 0.2-0.8 ms 了,burst 对此优化挺大的。
IJobParallelFor
普通 for 寻找两个 list,遍历 list 元素然后相加,数据量 10 万,每一个批次这里是处理 1 个 execute, 不开 job 2.48ms,开 job 1.34ms,job 开了 burst 就 0.28ms。
IJobParalForTransform
100+vec3,不用 job 0.02ms,用 job +burst 0.02ms
1600+vec3,不用 job 0.31ms,用 job 0.07ms +burst 0.04ms
1 万+vec3,不用 job 2.23ms,用 job 0.35ms + burst 0.12ms
1 万+float3,不用 job 2.55ms,用 job 0.4ms
100 万+float3,不用 job 199ms ,用 job 40ms + burst 31ms
100 万+vec3,不用 job 189ms ,用 job 35ms + burst 31ms
高级技巧
使用特定的数学库中的实现
unity 特定的数学库中的数据类型可以获取 simd 优化,比如 vector3 就可以换成 float3,但是缺少的数学库,就要自己解决了,所以我一般就 vector3。
在合适的时机 Schedule 和 Complete
拥有作业所需的数据后就立即在作业上调用 Schedule,并仅在需要结果时才开始在作业上调用 Complete。最好是调度当前不与正在运行的任何其他作业竞争的、不需要等待的作业。例如,如果在一帧结束和下一帧开始之间的一段时间没有作业正在运行,并且可以接受一帧延迟,则可以在一帧结束时调度作业,并在下一帧中使用其结果。另一方面,如果游戏占满了与其他作业的转换期,但在帧中的其他位置存在大量未充分利用的时段,那么在这个时段调度作业会更加有效。
在单线程里运行 JobSystem
IJobParallelForExtensions 可以调用 Run 方法,会将所有的 Job 放到一个 Thread 里执行,之前我们提到了 Schedule 的 innerloopBatchCount 参数,将它调到和数据源一样大,也是在一个 Thread 里执行,当我们的数据量小于 1000,分配线程可能都觉得费劲,用单线程的 JobSystem 配合 Burst 效果可能更好。需要注意的是,如果我们出现了并行写入问题(多个 Thread 同时写一个位置),在单线程模式下是不会报错的。
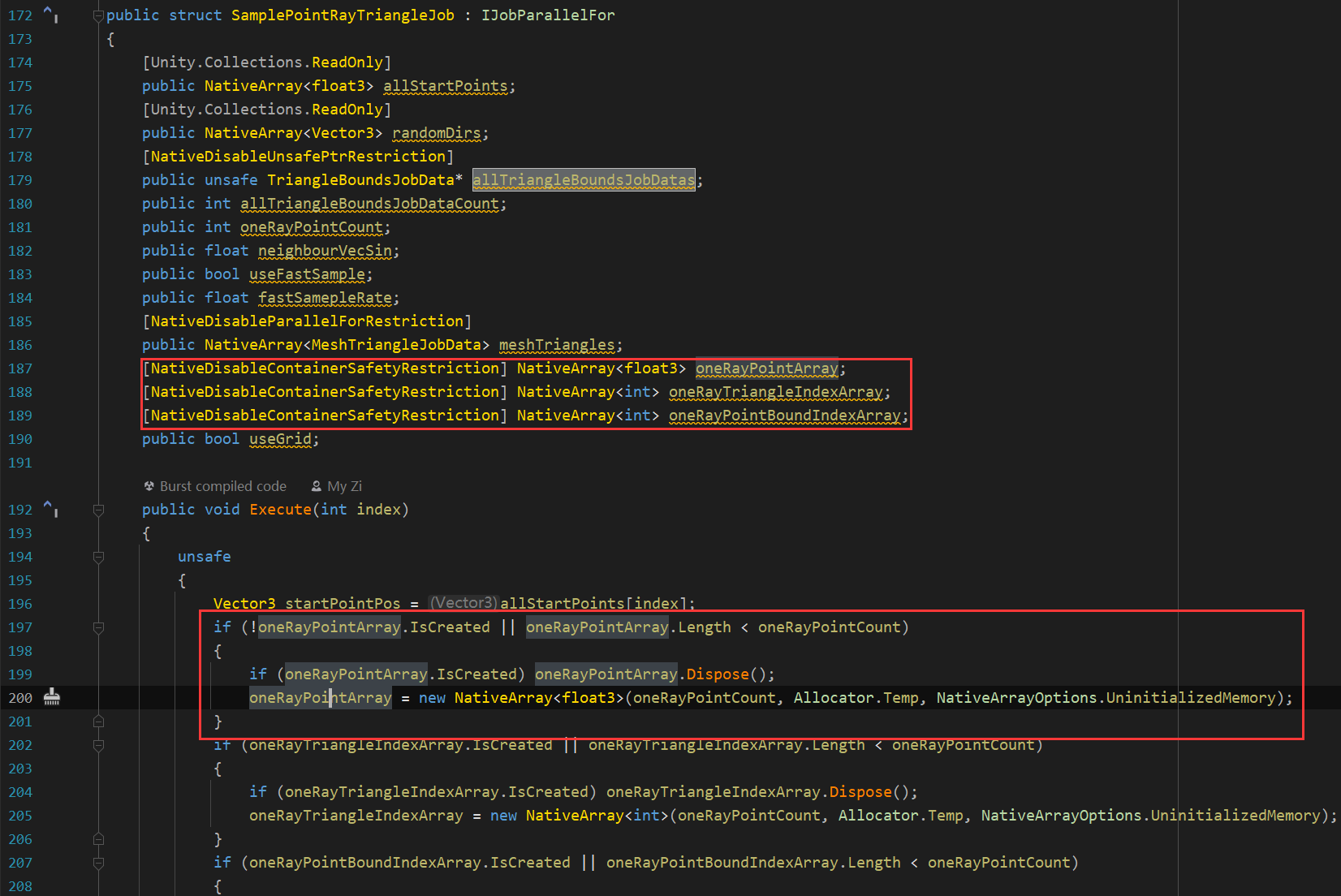
使用 NativeDisableUnsafePtrRestriction
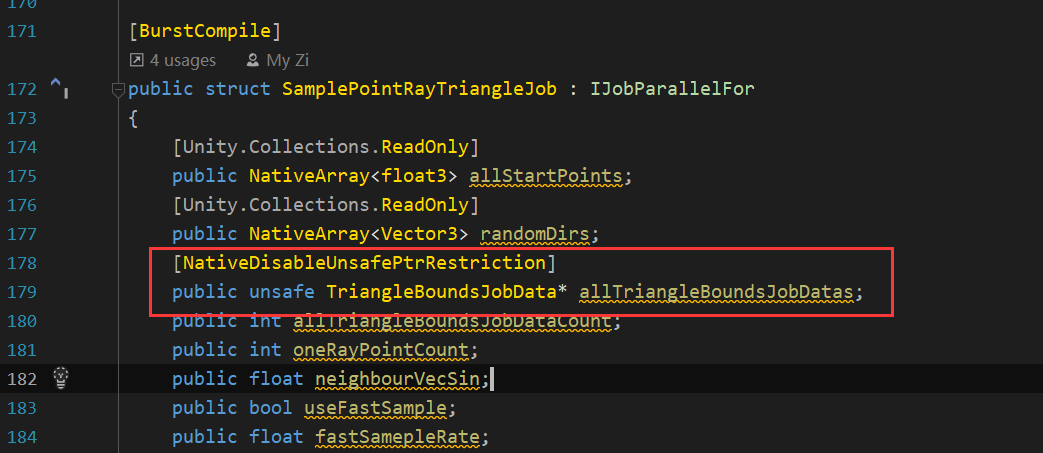
打上这个标记后可以在 Job 里使用 Unsafe 代码块,使用指针有多个好处
可以不需要拷贝数组就把主线程的数据塞进子线程,对数据量大,需要频繁调用的可以考虑
可以包装一些托管内存,比如我这里就包装了一个二维数组,每个 containsTriangleIndex 其实是一个 int 的 NativeArray
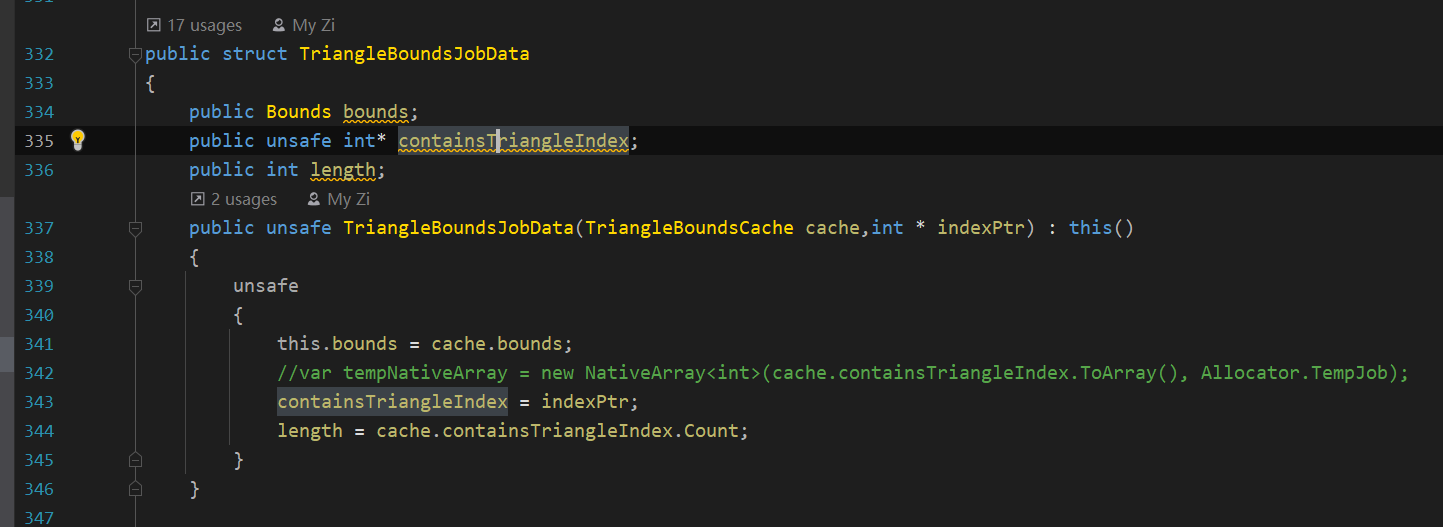
如果 struct 里有 NativeArray,这个 struct 放进 NativeArray 的时候会过不了安全检查。我这里是在主线程维护好了这些动态的数组,然后再传进了这个结构的。在 unsafe 代码块里,Native 容器相关的 API 中有 GetUnsafePtr 可以获得指针。
NativeDisableParallelForRestriction 并行写入
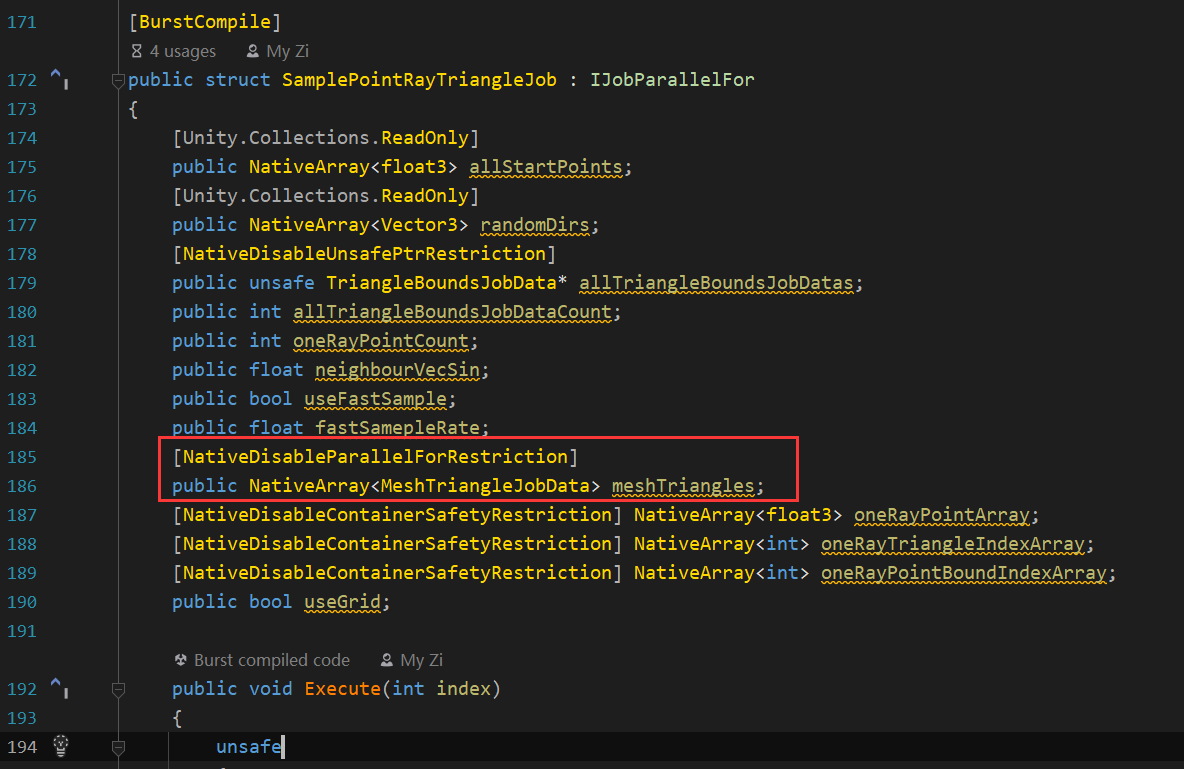
打上这个标记后,多个 Thread 同时数组的同一个地方进行写入,unity 不会阻拦,但是自己也要处理好逻辑问题。
举个例子:下面这篇文章里https://blog.csdn.net/n5/article/details/123742777在 Parallel Job 里面进行光栅化三角形时,多个三角形有可能并行访问 depth buffer/frame buffer 的相同地方。这在多线程编程中属于 race conditions,Job system 内部会检测出来,会直接报错。
IndexOutOfRangeException: Index 219108 is out of restricted IJobParallelFor range [4392…4392] in ReadWriteBuffer.ReadWriteBuffers are restricted to only read & write the element at the job index. You can use double buffering strategies to avoid race conditions due to reading & writing in parallel to the same elements from a job.
NativeDisableContainerSafetyRestriction
使用这个 Attribute 可以在子线程分配一块内存,比如我这里每个子线程是创建了一个数组来接受光线三角形求交,一根光线击中了多少个点,一个子任务会执行许多次光线遍历 Mesh
这个主要是博主在 Github 上学习 Unity 官方的 MeshApiExample 项目看到的案例,有点像 StaticBatch 可以查看这个链接:把整个场景的Mesh合并
DeallocateOnJobCompletion
容器在 job 结束之后自动释放这个博主用的很少 基本都是主动释放可能在用非并行 Job 的时候 接受外面的 NativeArray 后自己不想管释放之类的。可以查看一个 github 上别人的案例看看
自定义 Native 容器
https://docs.unity3d.com/Manual/job-system-custom-nativecontainer-example.html
思考
JobSystem 与 ComputeShader 相比 优势
JobSystem 主要是利用 CPU 来降低计算负载,在数量级上远远比不上 GPU,在前面的性能测试中数据到万以上就相当吃力了。ComputeShader 是利用 GPU 来降低计算负载,,现在 GPU Driven 的技术也逐渐越来越多。
思考这两个的取舍主要应该看业务逻辑的数据流向,如果我们的数据是从 CPU 发起的,那么在把数据从 CPU 拷贝到 GPU 也是肯定是不如在 CPU 内做拷贝要快的,如果我们的计算的数据最后是给 CPU 做下步计算的,如果用 GPU 做计算就会出现 CPU 等 GPU 的回读问题,数据若停留在 GPU,那么 ComputeShader 自然好。
另外就是考虑两个后端的硬件特性,CPU 高主频,处理复杂的逻辑,大量的循环、分支判断上比 GPU 要有优势,数量级上则 GPU 更有优势。
最后也可以考虑一下易用性问题,如果用到了很多原本在 CPU 里的数学库,在 JobSystem 里都是可以直接用的,ComputeShader 的话则需要自己实现一版,不过脚手架这种东西属于见仁见智,只要自己方便就好。
文章转载自:FlyingZiming

还未添加个人签名 2023-06-19 加入
还未添加个人简介









评论