
百度垂类离线计算系统发展历程

作者 | 弘远君
导读
本文以百度垂类离线计算系统的演进方向为主线,详细描述搜索垂类离线计算系统发展过程中遇到的问题,以及对应的解决方案。架构演进过程中一直奉行“没有最好的架构,只有最合适的架构”的宗旨,面对不同阶段遇到的问题,给出了适合的解决方案。尤其是近 10 年来的超大规模系统架构的升级, 一方面需要考虑系统本身的通用性和适配性,以满足多个业务方的需求;另一方面需要结合系统当前运行的特点,在易用性、稳定性、智能化等不同方面进行提升。希望读者能在了解系统演进的过程中获得一些启发。
全文 9127 字,预计阅读时间 23 分钟。
01 相关背景介绍
在过去,用户通过“百度一下”得到的搜索结果是从互联网上抓取来的结果,也被称为“自然结果”。随着网络信息日益丰富,自然结果不能有效满足用户需求。为了解决自然结果无法满足搜索需求的问题,提出了针对各个垂类深耕的搜索结果的解决方案,一方面为用户带来的更优质的内容,让用户体验即搜即得的便捷,另一方面也可以帮助优质内容生产者提升访问量。
随着业务发展,除了标准通用的业务处理需求变更之外,越来越多的业务有自定义代码的更新需求。通过自定义数据处理,一方面,产品负责同学可以将原始传入的数据按照业务需求进行定制化处理,将原始数据转化为最终搜索的结果数据。 另一方面,通用默认的一些功能机制限制了少量垂类的发展,业务希望引入更多的策略 模型逻辑 信号等处理以及打分机制,提升排序召回的效果。
在这样的背景下,业务对于数据加工计算的框架引擎的需求越来越强烈,并且功能也逐渐成为整个垂搜离线处理过程中不可或缺的一部分。
02 计算系统演进过程
百度搜索系统离线数据处理从时间线的发展阶段来说一共经历如下几个阶段:
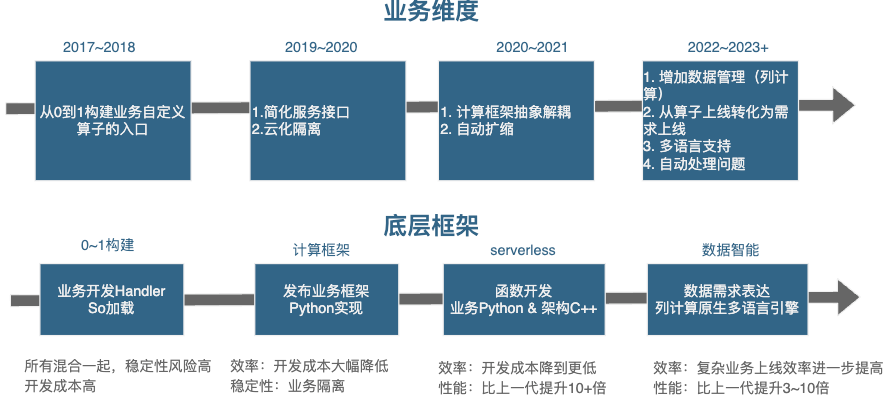
a.原始离线处理系统: 本阶段主要是实现业务加工入口从 0 到 1 的构建。整体上还没有形成完备的框架体系并且开发成本较高,并且所有业务逻辑混在一个公共服务中,不同数据通过不同配置调用不同的策略逻辑。
b.业务离线处理架构: 本阶段初步形成一整套的业务服务处理框架,有统一的服务框架和开发阶段,实现了云原生和服务隔离的模式。
c.Serverless 架构: 本阶段业务的接入效率上进一步提高,业务从管理服务面向转向管理业务加工函数,业务只需注册函数就可以快速测试上线,同时支持容器实例的自动伸缩,使得在业务的使用效率得到的极大提升的同时相应资源成本急剧压缩。
d.数据智能架构: 在原有服务部署的基础上同时实现了数据的管理,从函数管理进一步升级成为需求管理,实现多语言服务框架支持的基础上,成本进一步压缩 &效率提升。
03 计算系统核心设计核心思路 &核心实现
下面详细阐述各个阶段的详细特点以及核心实现。
3.1 原始离线处理系统
这套架构应用于 2018 以前,当时垂类的发展整体属于起步阶段。该阶段业务主要的需求就是可以将原始的业务数据直接上线。架构的主要精力聚焦于通用业务能力的建设。随着业务的逐步深耕,发现有少量的业务慢慢演化出来自定义加工的需求。
根据当时的业务需求,最终从原有的数据加工模块中衍生出业务数据加工系统。当前阶段的数据加工处理方式是使用统一 Handler 处理方式,当然这个处理并非是必选项,多数业务仍然不需要自定义加工处理。各业务之间也完全没有 数据 隔离,这种架构最核心的意义就是从无到有提供业务的自定义加工能力。如下图所示,此时计算系统只包含计算引擎部分,其他系统完全没有建设。下面会对该系统的部分细节进行详细说明。

3.1.1 业务特点
这个时期的业务特点主要有两个:
多数业务,核心诉求最主要的是通用能力的建设。
个别业务,有少量简单的自定义加工处理的需求。
所以这个时间点的核心主要是为了解决业务加工入口的问题。
3.1.2 核心设计
初版本的离线架构模块非常简单,如下图所示蓝色部分。随着业务发展,为了满足业务自定义加工的需求,引入红色数据通路,其中统一数据加工模块就是主要处理业务自定义加工逻辑。
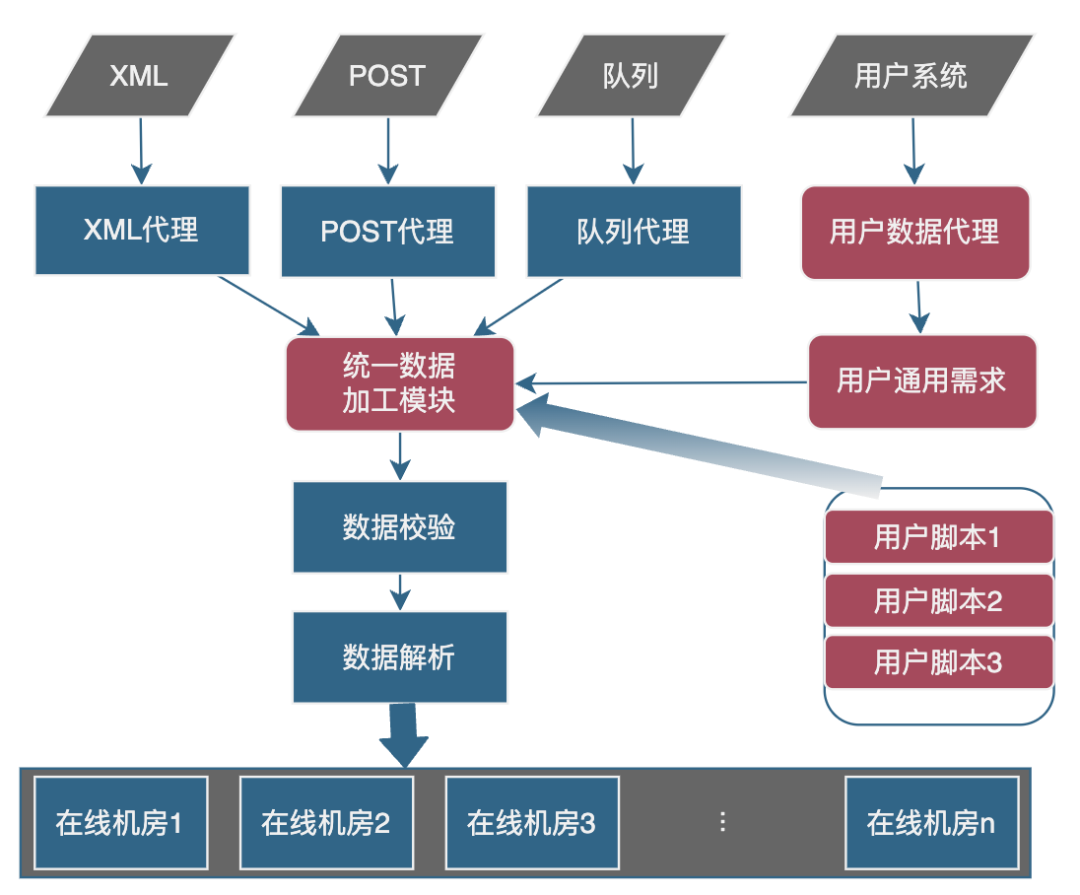
如上图所示,灰色部分是业务外层接入的数据系统,最开始的时候只有 XML、POST 和 数据队列的这种模式。蓝色部分就是业务没有自定义时候原始的数据框架代码。红色部分就是为了针对业务自定义需求引入的框架模块:
用户数据代理:主要是为了适配业务数据接入方式,数据的协议打平,主要是不同用户协议的 RPC 做建库层的数据转化。
用户通用需求:主要是为用户共性需求做统一处理,会根据不同业务的不同配置做功能处理:比如业务图片视频的转化处理,业务用户版本管理处理以及用户的核心机制等。
统一数据加工模块:主要是为了统一用户数据的加工处理,主要是给所有接入的业务的数据提供了一个可以数据加工的入口。
3.2 业务处理架构
如上文所述 3.1 架构核心价值是自定义加工能力的从 0 到 1 的建设,然而随着业务的快速发展,越来越多的业务需要自定义加工能力。业务自定义加工的需求从原来个位数迅速膨胀了 10 倍。因此,为了满足业务在自定义开发上易用性和稳定性的诉求,将原来 3.1 的中心化的处理模式升级成为服务框架的模式。总体上来说,当前阶段的计算系统建设已经基本具备了服务层和业务层两层:

业务层:业务通过平台已经基本上可以实现,基础的服务管理。
服务层:对计算引擎进行重构,让新的服务框架支持业务的高效开发。
下面会对该系统的部分细节进行详细说明。
3.2.1 业务特点
由于 3.1 中上一代系统数十个业务自定义需求统一在同一个模块里面开发 &统一线上运行,遇到了主要如下几方面问题:
效率:业务在相同的模块里面开发,导致业务开发上线的过程中经常遇到冲突,以及上线排队的问题,导致整体生效周期比较长。
稳定性:由于这种业务流量混合的模式隔离性比较差,导致单个业务出问题,经常会影响所有的业务。
因此,架构构建出完善的服务框架,业务可以基于服务框架构建自己的业务代码,从效率和稳定性两个方面解决上述问题:
效率:服务开发上线的过程是完全隔离的,业务在开发上线的过程中完全没有业务阻塞,整体服务上线周期从天级缩短到小时级别。
稳定性:由于每个业务服务执行逻辑都有完全独立的 app,导致业务的稳定性大大提升,不会存在业务之间的互相影响。
3.2.3 核心设计

业务处理框架:建设一个数据处理框架,业务可以基于这个框架来实现自己的业务处理功能。
任务平台:每个任务注册、升级、管理都可以通过任务平台来进行管理。
统一网关:所有数据的统一入口,统一接收上游数据,并且做数据的转发和分发。
业务 APP:每个业务都有自己独立服务的 app,每个业务开发是基于框架的独立分支开发,上线是每个业务单独上线,业务处理的服务流量也都是完全隔离的。
3.3 Serverless 架构
如上文中 3.2 表述已经解决系统隔离性的问题,业务快速发展从最开始的几十个,发展到上百个业务应用。当业务发展到井喷状态后,服务框架的形式已经完全不能满足业务的开发需求。
Serverless 架构如下图所示,此时计算系统整体版图已经相对完善,相比上一代计算架构,不仅仅业务层包含的全流程的优化,提供了完整的工具功能;服务层充分考虑的架构的设计和复用,同时增加控制层增加智能调度的功能针对系统流量进行资源的动态调度。
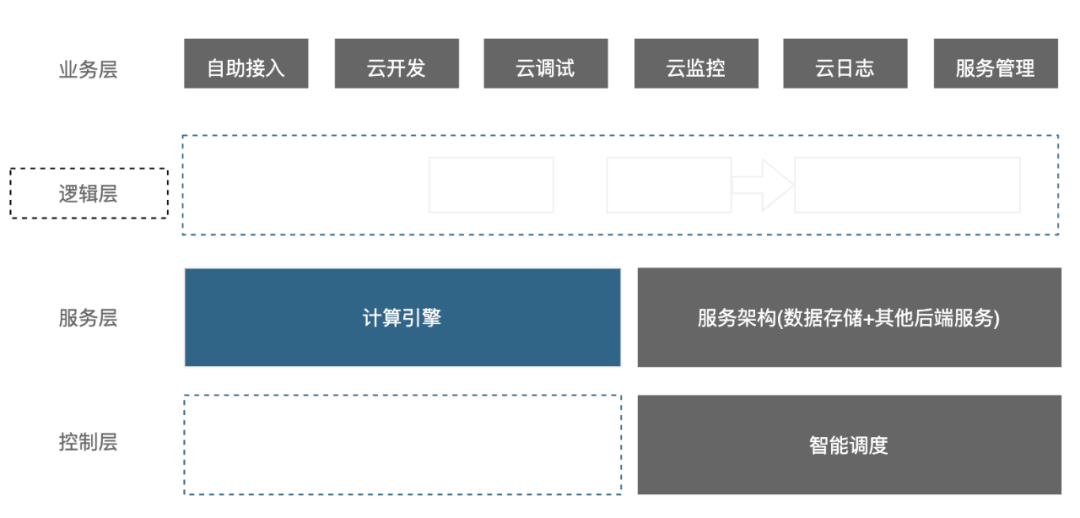
下面会对该系统的部分细节进行详细说明。
3.3.1 业务特点 &解决问题
业务学习成本:大量的新业务接入需要进行开发,导致框架本身学习成本需要几天的时间,新业务的接入和开发的时间基本上都在周级别。
资源如何节省:大量的业务也带来 app 的高速膨胀,原来接入的数百台机器已经用满,到了资源瓶颈,当前的资源量无法支持业务的快速膨胀。
3.3.3 核心设计
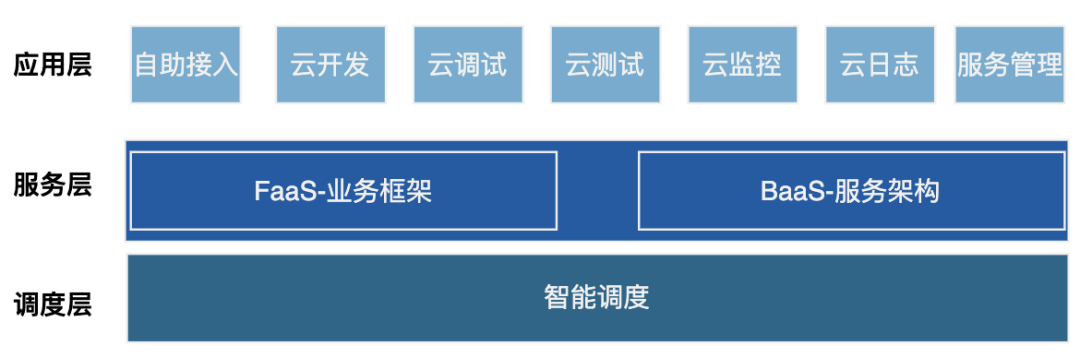
应用层:针对于基础服务架构,上面给业务开放的各种云服务,从业务的 接入、开发到后面的调试、测试,到服务上线后的监控。
服务层:这部分是整体架构的基础,应用层都是基于这里进行开发的,这部分是整个系统的基石,属于整体系统的核心框架。
调度层:通过根据流量形式的扩缩容,保证后续服务可以自动化的进行服务操作。
下面重点介绍一下 服务层的主要内容,对业务来说主要包含两部分:
极致抽象的业务框架:是核心框架基础中的基础,提供新的开发范式同时,为后续智能调度奠定良好基础。
高度复用的基础服务:强大丰富的后端服务能力封装,支持业务低成本复用,降低开发成本同时提升稳定性。同时系统还提供强大的编排能力,低成本支持业务从简单到复杂的发展。
极致抽象的业务框架
业务框架作为 FaaS 层和业务代码的载体,是整个业务逻辑的代码框架。框架本身维护数据流语义,面向有向无环图(DAG)的数据流,调用业务函数代码。业务框架是面向有向无环图的数据流实时计算,基于公司基础的数据流框架支持完备的流式计算语义,结合业务场景需要功能构建出业务框架:
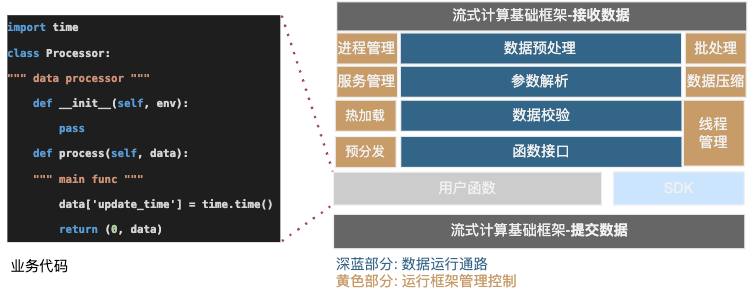
如上图左边就是用户实际的执行代码,对于函数的接口定义:入参和返回值都是 Dict 类型。业务的代码逻辑直接在函数中实现,需要变更的数据,如上图所示业务在根目录下增加了一个时间戳字段,然后把更新后的结果传递给下游。
业务端使用开发成本低的脚本语言进行开发(例如 Python),基础服务框架使用 C++实现,结合数据压缩、批处理、数据预分发等机制,使得业务可以在简化服务框架开发同时优化服务运行性能。通过架构层面的优化策略来达到服务性能和开发成本的平衡。
高度复用的基础服务
业务依赖的后端服务,包括多媒体长留服务,数据存储服务,策略计算等十项服务能力,所有的服务架构的支持目标都是通过简单配置、少量代码的方式进行服务接入。
架构通用能力:包括索引处理(倒排、正排、向量索引),数据审核(政治敏感数据/色情数据识别 &过滤),多路分发、数据建库等能力。
与业务联合研发的能力:数据的低质过滤能力(实现数据清洗/归一化/数据去重/类目拼接),数据多元融合,数据质量打分计算(质量打分/作弊识别/物料打分)。
基于公司强大基础能力: 多媒体处理服务(外链转内链/OCR/水印计算/重复图计算/主体识别/视频转储等),自然语言处理服务,数据沉淀服务。
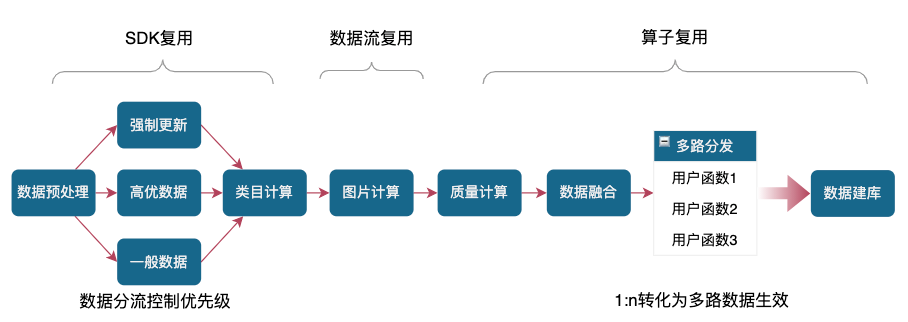
支持的基础服务(BaaS 服务)主要是两个特点: 简单稳定 & 充分集成公司内其他优质能力。用户通过 SDK 调用、算子复用和数据流复用等方式直接进行能力复用,完全不需要进行服务的部署和管理,服务易用性、稳定性由搜索中台来处理。使用任何服务后端都可以收口在一个地方,避免业务频繁跟多个服务团队进行交流处理,极大降低业务使用成本。业务最开始接入通常只需要简单的少数功能(例如,修改部分字段的信息),多数业务直接用我们提供的平台化的开发模板即可完成开发。但是随着业务的逐步深耕,业务逐步使用,业务会向复杂逐步过渡,例如搜索中台某业务通过复用数十种能力的组合使用,建设出具有深度定制的数据系统。
3.4 数据智能架构
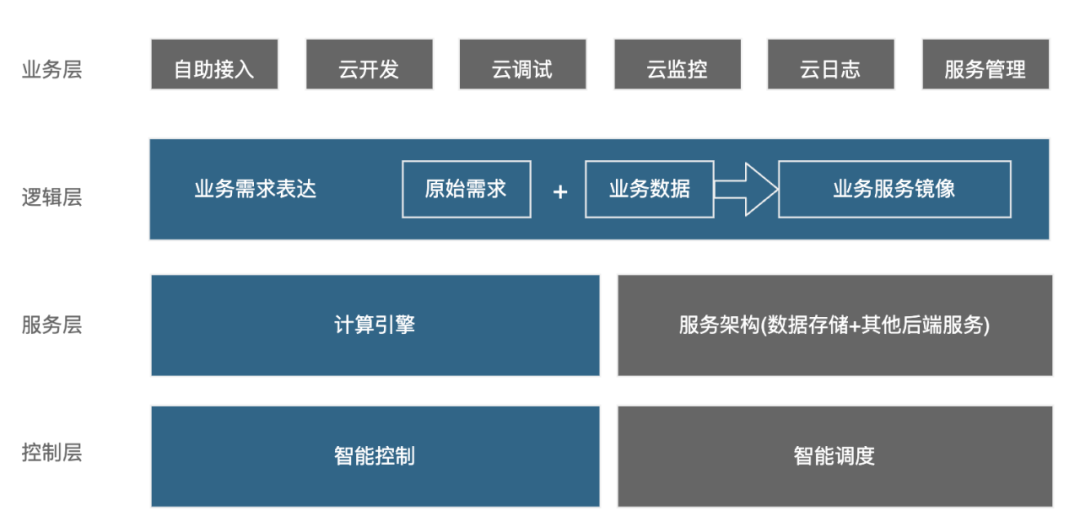
如上文中 3.3 表述已经很大程度上解决业务接入效率的问题并且在资源的使用效率上实现根据流量的扩缩容实现的资源极大程度的节省,业务的 app 的数量已经发展到上千个,业务对于效率、成本、服务质量提出来更高的要求。至此已经构建出,从业务层、逻辑层、服务层、控制层的四层架构,实现离线计算系统从指令式计算系统到声明式计算系统的彻底转变。
3.4.1 业务特点
效率业务的迭代开发很多都是针对少数几个字段,但是当前业务同学仍然需要了解服务全拓扑才能开发。
随着业务复杂深耕业务的开发迭代业务开发者出现多语言开发情况来提高服务的开发和执行效率。
业务如何实现新类目的快速接入、在不了解全面的情况下快速迭代。
计算引擎执行效率更高,用更少的资源计算跑更多的服务资源。
业务问题能不能快速定位 &发现以及问题的自动处理。
3.4.2 核心思路
从设计思路来看当前系统架构是上一代架构的拓展:
数据管理:出了原始服务管理外,引入数据全面管理,为列计算奠定基础。
编排能力:将原来业务手动编排的函数能力扩展成为需求声明式自动编排的能力。
服务处理:极致高效的服务处理能力,支持多种不同业务开发者的高效开发效率,将整体的计算从行计算转向列计算,提高整体的计算复用。
控制能力:将原来自动伸缩的能力扩展成为智能控制能力,做到问题的自动识别、自动分发、自动分析 和 自动处理。
整体架构的设计核心理念大致是多层抽象、分层复用。
3.4.3 核心设计
当前阶段的核心设计已经呈现出完整的四层架构的抽象能力:
应用层:业务直接可见的相关服务,包括业务从开始数据接入到服务运行的全周期各阶段各种应用。
逻辑层:也可以称之为编排层,负责将原始的业务需求表达转化成为线上真实运行的服务, 业务通过 Codeless 平台化选择勾选自己的功能集合,以及对应数据映射关系进行提交,将用户提供的功能 & 数据的绑定关系转化为业务的自定义的功能 以及映射关系。
服务层:计算系统的核心,业务实际计算运行在这层,主要包含计算引擎 和服务架构两部分。向上承接逻辑层的编排结果运行服务,向下提供基础信号作为控制层的输入。
控制层:包含智能调度和智能控制两部分:智能控制主要是通过自动接受业务指标数据进行智能控制保证服务稳定,而智能调度是除了根据数据流量进行进行自动伸缩以外还可以根据业务服务关系进行流量复用,减少业务的重复计算。
下面我们针对部分核心系统(如上图蓝色部分)的设计作展开说明。
需求表达逻辑
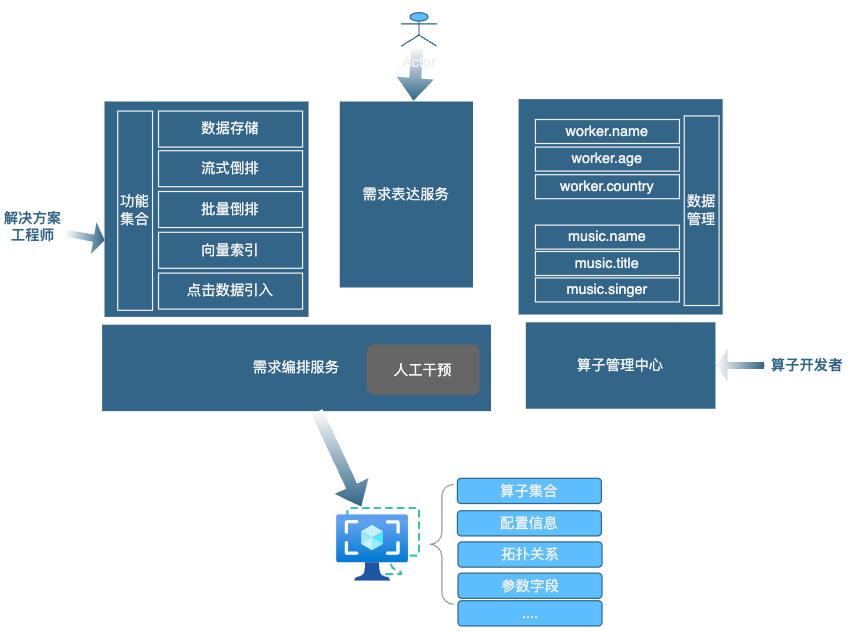
需求逻辑的表达的核心就是如何把用户原始的功能需求转化成真是线上服务的算子、配置、关系的表达。用户最原始的输入包含两部分:
业务数据:业务数据需要功能的最小单位进行切割,后续算子进行配置转化以及服务绑定的列式计算。这里说的有点绕口,其实本质上就是把业务数据的原始 Proto 或者数据 Schema 注册一下就可以。
功能集合:功能集合既可以用户直接使用的系统提供的默认模版的功能集合 也可以是用户通过平台自定义的集合,值的注意的是每个功能都都有其指定的传入参数,比如图片计算,需要传入图片 URL,向量计算需要传入原始数据 & 向量参数等等。功能完成后也会有对应的输出结果业务可以指定。
获取完成用户的原始输入后,架构通过两层逻辑映射的方式,将原始用户需求转化成为线上服务部署信息:
需求表达服务:用户的原始需求转化为功能模版的组合。这个阶段会根据用户配置,将原始算子和数据进行绑定,原始用户抽象的需求实例化成带数据的算子集合。
需求编排服务:通过业务算子的本身的依赖关系和数据依赖的血缘关系进行表达组合,将带数据的算子构建出 N 个有向无环图。
整体需求表达都可以通过 Codeless 方式表达,通过描述功能集合✖️数据集合描述方式,加之两层逻辑映射的转化,这样就可以将原始用户声明式需求直接转化线上服务关系和系统配置,并且服务的算子的拓扑关系完全可以通过业务的数据关系表达自动化推导出来, 实现了 95%以上的功能可以完全自动化配置实现,当然有个别服务无法低成本转化表达的,也提供了人工接口。
计算引擎实现
计算引擎层的核心组件大致分成两部分,图计算引擎 & 多语言算子的执行引擎 。

图计算引擎:主要控制的业务拓扑的表达关系,通过有向无环图来表达。
算子执行引擎:主要控制业务真实业务函数的执行,不同语言有不同的函数实现,例如 Python、GoLang、C/C++都有自己的执行引擎。
下面针对两部分进行仔细说明
图计算引擎实现:实现的核心功能就是实现支持表达有向无环图的框架,使用 C++实现的,图下图部分中,蓝色部分就是有向无环图的框架实现,当然我们这个框架的底层实现支持了多种数据的表达:
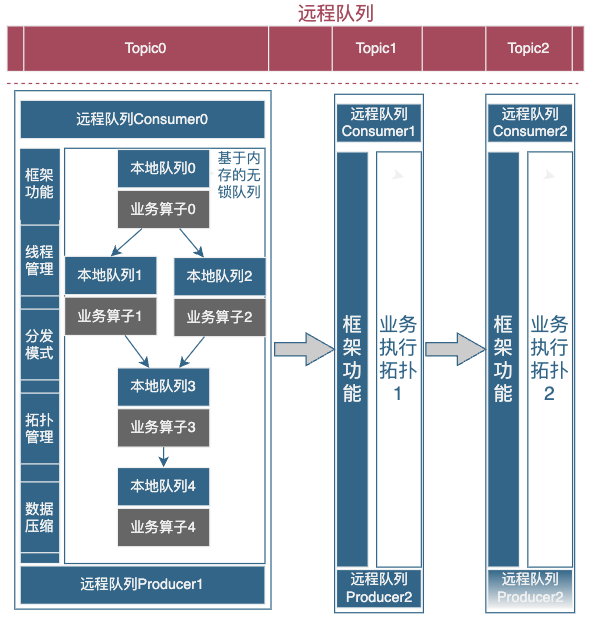
本地队列表达:如图左下角部分表达的就是一个简单的拓扑表达,拓扑关系是通过本地的无锁队列进行串联的,每个队列下面挂载一个业务算子,业务算子处理完成数据后,算子拓扑配置管理分发到下游的本地队列中,如果是最后一个算子,数据结果全部处理完成后输出到远程队列 Producer 中。左侧这边是框架内部的通用功能:
线程管理:每个业务算子默认都是多线程的分发模式(如果业务算子只支持单线程,可以把线程数设置成 1)。
分发模式:数据消费分发模式默认是轮询分发,固定 KEY 分发(实现保序)以及按消费能力分发。
数据压缩:这个默认支持常见数据压缩方法,是可选的吞吐优化手段,支持 LZ4、Gzip、Snappy 等常见压缩算法。
远程队列表达:每个蓝色大框表示一个具体实例,实例之间使用远程队列交互,如果每个实例里面只有一个业务算子,这种的交互方式类似于远程队列的表达方式。
混合方式表达:更多使用方式是混合使用,一个巨型拓扑会拆分成多个子拓扑,每个子拓扑使用本地队列的方式进行表达,而子拓扑之间使用远程队列的方式进行表达。
多语言引擎执行层:语言执行层整体框架整体根据不同的语言有不同实现模式,大体上分成三部分:编译型、解释型、原生 C++。
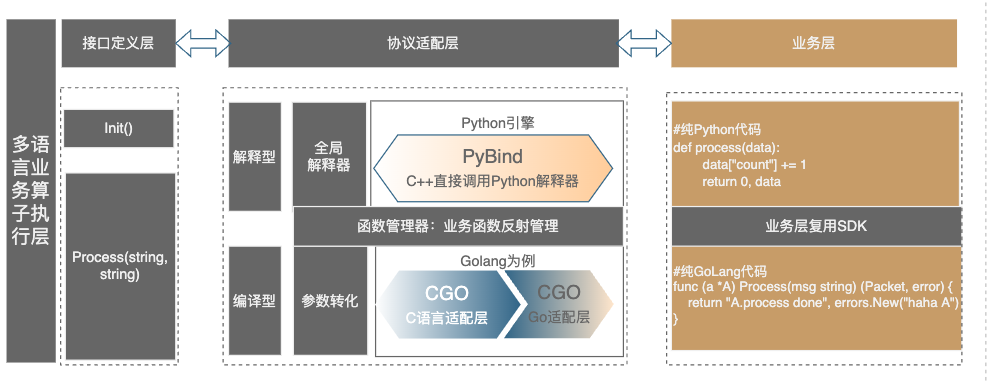
解释型:最典型的就是 Python 实现方式,这种方式也是过去同学最喜欢用的开发语言之一。图上图最上面,左边灰色部分是 C++开发的部分,最右边黄色部分是业务代码,中间这部分就是 C++转 Python 的交互引擎调用。这种方式的本质就 C++的开发引擎使用 PyBind 实现指定接口服务解释器,根据指定的数据序列化和反序列化方式进行操作,在函数调用时再实时转化为 python 的 Dict。
编译型:典型是 Golang 的使用方式。与 Python 的实现类似,左边灰色部分是 C++开发的部分,最右边黄色部分是 Golang 业务代码,中间是 C++转 Golang 的交互引擎。Golang 的实现相比 Python 的方式有点复杂,本质是通过原生 CGO 作为用户接口,为了统一用户接口层,其实分成两部分:左半部分是直接跟 C++交互,直接用 C++实现负责把原生 C++转化为基础的 C 类型的函数指针进行调用。右半部分使用 Golang 实现负责把原生序列化好的函数反序列化成业务结构体,然后再进行真正调用。
原生 C++:这里很多人可能觉得奇怪,C++不是也是编译型的么,已经有编译型的实现模式何必画蛇添足,增加这么一种实现模式,其实本质不然,golang 虽然是编译型语言,底层框架的实现由于尽量考虑通用性,数据传递的过程中势必需要进行序列化和反序列操作,而在原生的 C++的实现过程中我们在实现的过程完全摒弃所有的序列化和反序列操作,数据在本地队列中的传递完全是业务的数据指针(而非序列化数据),而每个业务算子在处理数据过程中,直接根据原始的数据指针通过反射机制(实现方式有很多最简单的 map)可以直接获取对应列的数据项,整个过程无锁的超高效率。这里的核心优化思路数据链式处理过程。拉链上的每个算子,都共享同一个输入和输出。 每个算子,其实就是一个接口相同的函数,这样就可以随意地调整函数指针的组合,形成不同的处理链。比如:一个请求走 A 模型排序,一个请求要走 B 模型排序,他们可以共享前序的算子,只在最后一个算子有所不同。在链式处理基础上,算子也可以是继承同一基类接口的派生类,或者 lambda 表达式。结合工厂模式等一些编程技巧,处理链的调整可以配置化、动态化、脚本化。实测执行业务单算子普通的纯数据项带分支的多节点的拓扑计算单机(单线程/算子)可以达到数十万的处理能力。
通过新计算引擎的实现从使用上完全兼容上一代计算系统的使用方式,将不常使用的功能做精简,同时优化复杂拓扑执行方式,通过架构层也业务层解耦,支持多语言高效执行方式,对于老业务平迁的数据框架平均计算效率提高 5~10 倍,同时业务由于针对性建设业务框架业务开发效率进一步提升。
智能控制实现
自动化问题分析引擎是整个智能控制系统的大脑。它上游接收观测提供的原始数据,进行自动的分析决策后,通过系统提供的自愈能力处理。自动化问题分析引擎的核心思路: 只要历史上出现过的问题,RD 同学能找到问题和解决方案,就可以转化为系统规则和后置函数梳理。那当下一次遇到问题则无需人工干预。规则引擎的核心分析过程是 2 段式的:
阶段 1: 传统配置化的规则引擎的配置(上图中右上角黄色部分),配置多个采集指标项的逻辑关系(与或交非), 这里主要是针对问题的基础分析功能,判定规则是否触发。
阶段 2: 基于这个基础分析的结果,进行后置 Function 的执行分析,这个主要是针对复杂问题的分析补充, 最终执行引擎根据这个返回结果进行函数执行。
下面针对问题分析引擎的执行结果如下:
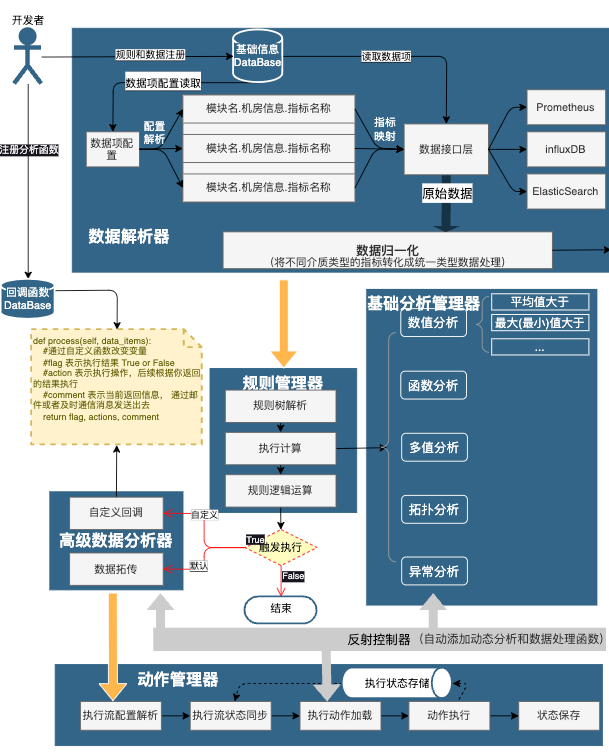
前提: 开发者需要配置好处理逻辑规则(以及规则依赖的数据项,必填) & 回调函数(选填)。
数据解析器: 数据解析器主要承担的数据的原始抽取的工作,一共分成如下 3 步:
a.配置解析: 逻辑执行根据开发者配置的数据信息解析;
b.数据抽取: 根据解析出来的配置通过数据接口进行获取,可以从统一接口根据配置的信息从不同的介质充抽取所需求的信息;
c.数据归一化: 将不同介质的原始数据归一化成为统一的数据格式供规则管理器使用。
规则管理器: 规则管理器主要承担核心的逻辑分析工作,一共分成如下几步:
a.规则解析: 根据开发者配置的规则逻辑,将原始配置信息,解释成原始的规则树。
b.执行计算: 根据数据解析器提供的数据结果和配置的函数规则分别执行计算。执行计算过程中最重要的就是基础分析器,整体提供了 5 大基础能力,数十种常见的逻辑计算来辅助规则配置。
c.规则逻辑运算: 根据上层解析出来的规则树 和 每个数据项执行完成的计算结果进行逻辑运算,并根据执行的结果确定是否进行高级数据分析器,如果判断结果为真则根据所配置的后置函数进行处理。
高级数据分析器: 如图所示有两种模式,对于简单基础分析可以判断结果的,直接给默认的处理函数进行数据拓传;对于简单逻辑规则无法准确表达的,开发者可以自定义后置分析函数, 函数会将原始数据和基础计算的计算结果作为参数传出来,开发者只需要通过处理后的数据描述清楚分析逻辑即可。
动作执行器: 就是这个分析器的真正的执行引擎,根据规则运算的结果中包含的参数进行动态调整。
通过智能控制系统的建设,月级别分析处理上万的异常问题,自动恢复的比例占总数的 95%以上,绝大多数的问题几分钟内完成自动恢复, 核心故障同比减少 60% (由于预处理防止普通问题恶化成严重问题)。
04 结论以及展望
本文全篇以离线计算系统的发展为主线,贯穿全文讲解遇到的问题以及解决方案。尤其是当前新一代架构核心就是以数据+功能为核心的声明式的设计,配合高效计算引擎、配合智能化的设计,把整体的离线计算系统的高度做了进一步提升。设计中其实还是虽然解决了过去的很多问题,但是仍然有不完善的地方,当然当前的效果还远没有达到最终的理想状态,部分系统功能有待持续性的打磨升级。
——END——
推荐阅读
版权声明: 本文为 InfoQ 作者【百度Geek说】的原创文章。
原文链接:【http://xie.infoq.cn/article/201531bb2ad0d3faf2ea1a424】。文章转载请联系作者。

百度官方技术账号 2021-01-22 加入
关注我们,带你了解更多百度技术干货。









评论