
三步实现 BERT 模型迁移部署到昇腾
本文分享自华为云社区 《bert模型昇腾迁移部署案例》,作者:AI 印象。
镜像构建
1. 基础镜像(由工具链小组统一给出 D310P 的基础镜像)
From xxx
2. 安装 mindspore 2.1.0,假定 whl 包和 tar 包已经下载到本地,下载地址:https://www.mindspore.cn/lite/docs/zh-CN/r2.0/use/downloads.html
3. 安装 cann 包 6.3.RC2 版本,假定也下载到本地,下载地址:https://support.huawei.com/enterprise/zh/ascend-computing/cann-pid-251168373/software
4. 安装 pip 依赖
5. 安装昇腾迁移工具 tailor,假定也下载到本地
6. 生成镜像
docker build -t bert_poc_test:v1.0.0 .
容器部署
宿主机用户目录/home/xxx/下存放着若干文件:
1. 运行容器
参数说明:
-itd 设置交互守护运行容器,可以退出容器
-- privileged 设置特权容器,可以查看所有 npu 卡信息
-p 主机端口和容器端口映射
2. 进入容器
docker exec -it bert_d310p bash
进入容器内部,执行 npu-smi info 命令查看 npu 卡使用情况
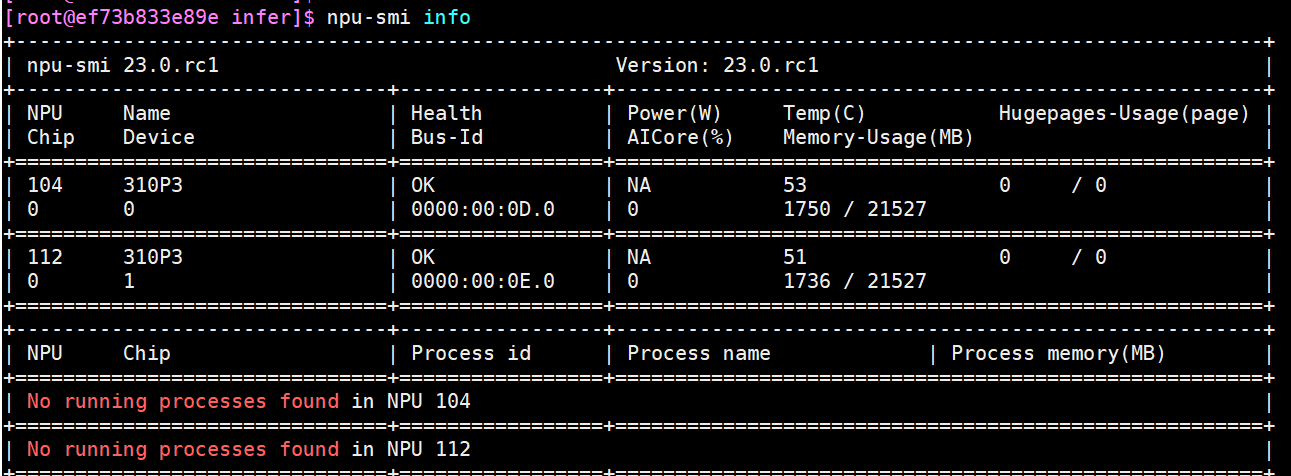
3. 使用 tailor 工具转换并优化模型文件
执行成功后在/home/xxx/model/ output/model_fp16_aoe_xxx/convert 目录下会生成转换成功的 mindir 文件,然后将这个文件拷贝到/home/xxx/model 下
4. 修改 infer_server.py 指定模型文件路径, 这里给出例子
5. 修改 run.sh 文件指定进程个数,这里给出例子
6. 启动服务
sh run.sh
7. 外部调用请求
使用 curl:
curl -kv -X POST http://{宿主机 ip}:8443/
性能评估
1. 安装 java
下载 jdk 包
拷贝到/opt/jdk
解压
然后设置环境变量:
export JAVA_HOME=/opt/jdk/jdk1.8.0_252
export PATH=${JAVA_HOME}/bin:${PATH}
2. 安装 jemter
下载 jmeter 包
拷贝到/opt/jmeter
解压
然后设置环境变量
export PATH=/opt/jmeter/apache-jmeter-5.4.1/bin:${PATH}
也可以持久化到 /etc/profile
source /etc/profile
3. 测试 qps
服务器端 gunicorn 使用 60 个 worker,显存占用接近 80%
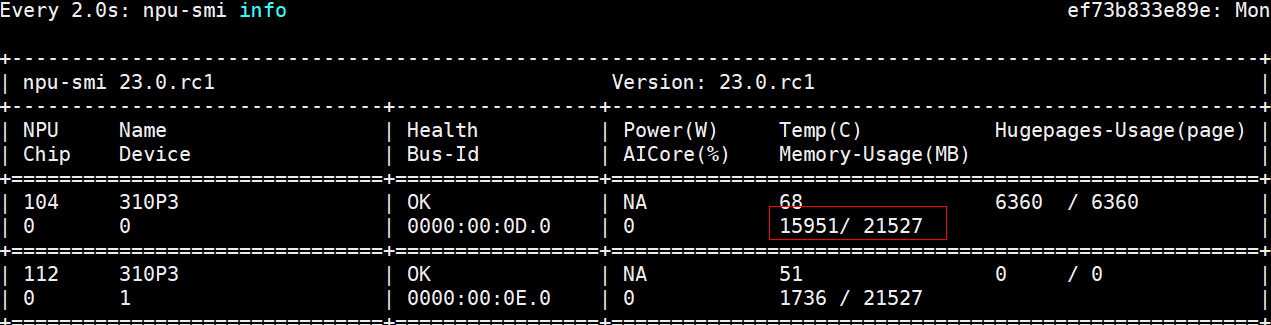
客户端 jmeter 使用一个进程压测 iops 为 248 平均时延为 4ms
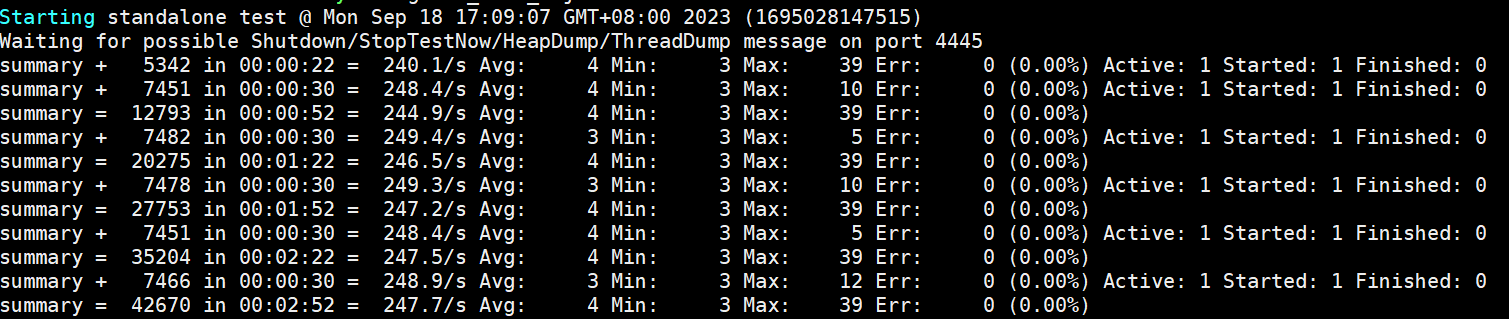
客户端使用 2 个进程, npu 使用率到 71%,qps 到 356 平均时延 5ms
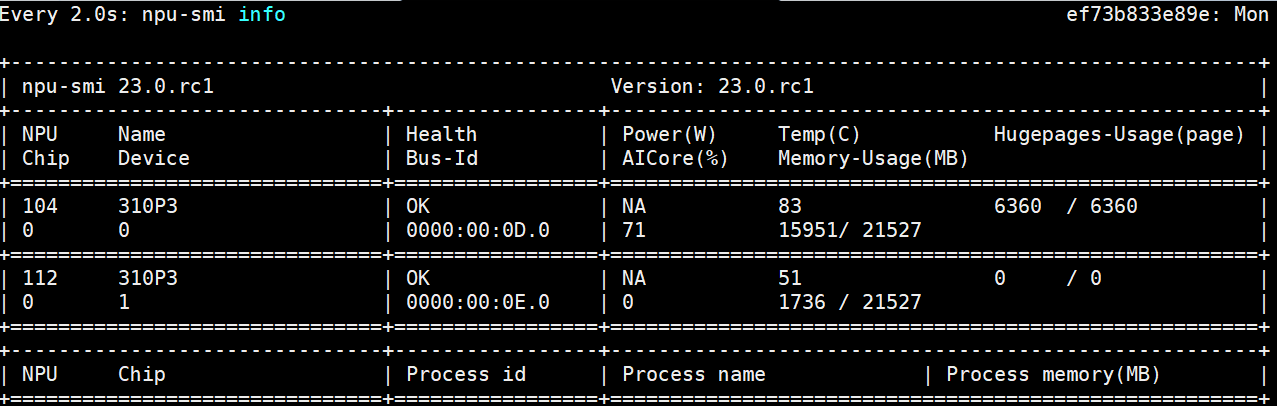

客户端使用 4 个进程,npu 使用率已经到了 97%,qps 到 429 平均时延 9ms
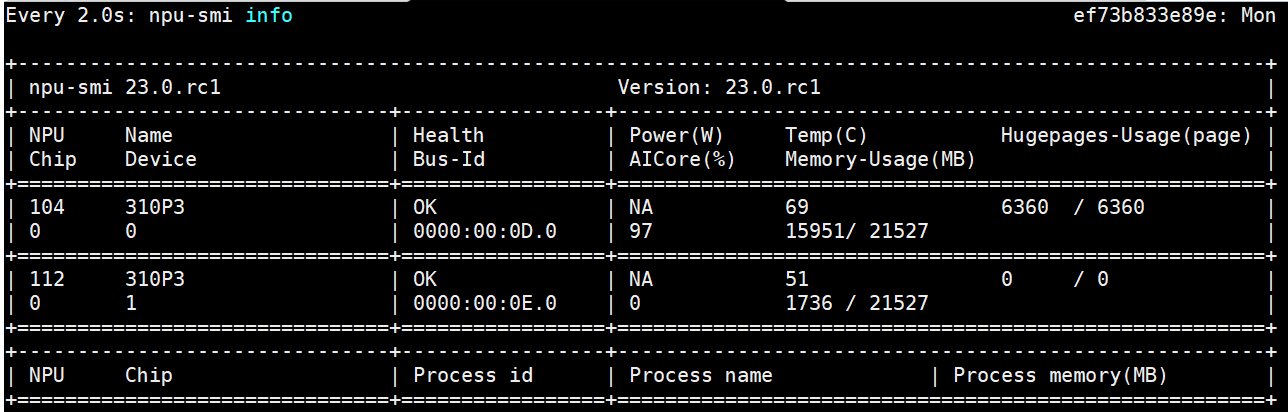

进一步加大进程个数到 8 个,性能开始下降:

综上,bert poc 模型在 D310p 单卡 qps 可以达到 429。
版权声明: 本文为 InfoQ 作者【华为云开发者联盟】的原创文章。
原文链接:【http://xie.infoq.cn/article/06c29793d0596dd6667ee9e88】。文章转载请联系作者。

提供全面深入的云计算技术干货 2020-07-14 加入
生于云,长于云,让开发者成为决定性力量









评论