
国产 GPT 到底哪家强?看看专家怎么选
摘要:随着国产大模型的连续亮相,行业发展迅速。豆茉君为了解决用户如何选择最适合的大模型,对比过文心一言和 ChatGPT,今天要给大家分享 InfoQ 和 SuperCLUE 的评测结果。结果显示,GPT-4、Claude-2 和 GPT-3.5 在全球范围内表现最佳,而在国内,百川、MiniMax 和文心一言表现突出。
前言
9 月 7 日,2023 年腾讯全球数字生态大会召开,腾讯混元大模型正式亮相。进入 9 月,国产大模型陆续高调亮相,几乎是天天都有大新闻,由此可见这个行业的蓬勃发展,一浪接一浪。
作为一个普通用户,豆茉君已经消化不良了:这么多模型,到底应该怎么选?之前就为了摸清一个 ChatGPT ,豆茉君就花了几个月时间使用,才有了些心得。现在,国产大模型产品开放了这么多,到底用哪家啊?
为了解决这个问题,豆茉君在前面的 2 篇文章里面全面对标评测了文心一言和 ChatGPT:
在自己评测的过程中,豆茉君发现,一个全面的指标体系和覆盖面广的测试问题集至关重要。
今天,和豆茉君一开来看看,两个专家团队的评测结果。
正文
一、InfoQ:大语言模型评测报告 2023
InfoQ 是一个为技术人群提供高质量技术资讯、分享技术实践经验、交流技术观点的平台。5 月 29 日,InfoQ 出了一个评测报告,报告中介绍了大模型发展背景、产品特征和核心能力,并对主流的 10 个大模型进行了评测。

无论是国内还是国外,大语言模型产业的发展可谓是百家争鸣,无论在基础模型、ChatBot 还是其他应用方面,都非常热闹:

评测对象
由于评测是在 5 月份进行的,所以测不到最新的版本。

指标体系
这个体系中,70% 的权重在于对准确性进行评价,包括语义理解、语法结构等 9 小项。而占比 10% 的数据基础和 15% 的模型和算法能力均采用专家访谈的形式进行测试。


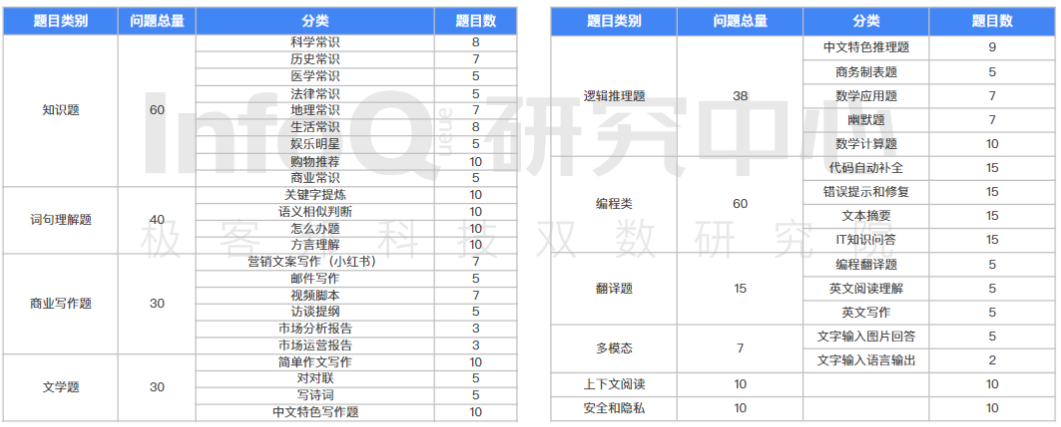
测试问题集
官方准备了 300 个测试问题,分布如下:
测试结论
在 InfoQ 的指标体系下,GPT-3.5 和文心一言属于第一梯队,Claude、讯飞等为第二梯度,通义千问、MOSS 等属于第三梯队。
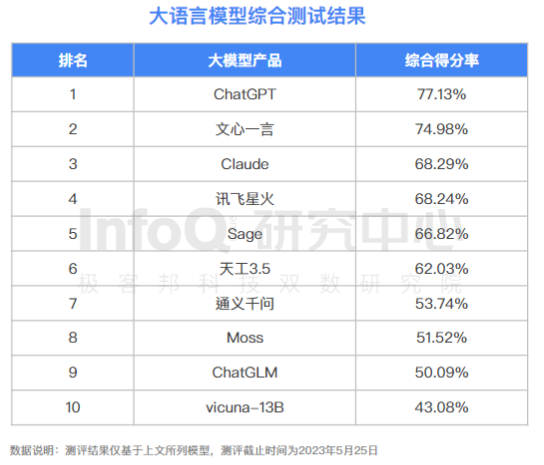
其他结论还包括:
1、写作能⼒和语句理解能力,是目前大语言模型最为擅长的能力

2、大语言模型展现出优秀的中文创意写作能力
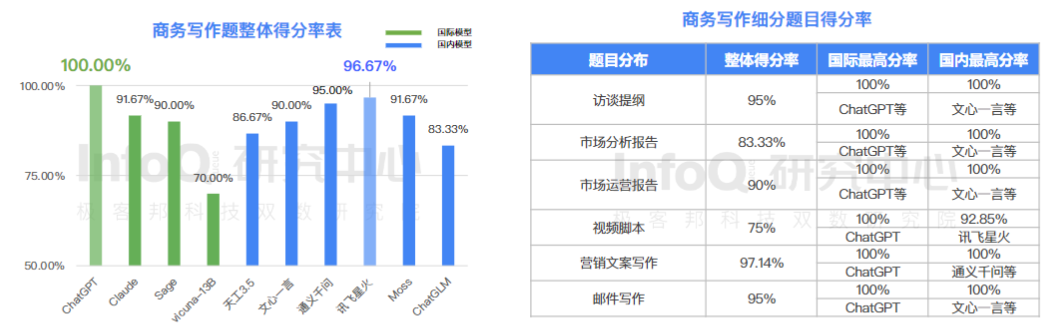
在国内,讯飞星火的表现最佳,而且与 GPT-3.5 水平非常接近。
3、中文方言理解题难倒大语言模型,整体准确率仅为 40%

文心一言的表现最佳,这可能得益于百度的语料库吧。
4、国际产品编程能力显著高于国内产品

5、中文知识题目,国内模型表现明显优于国际模型

对于这种有明确对错、标准答案的问题,文心一言得分最高,所以再次彰显了百度的语料库优势。
6、国内产品在跨语言翻译中仍有较大的提升空间
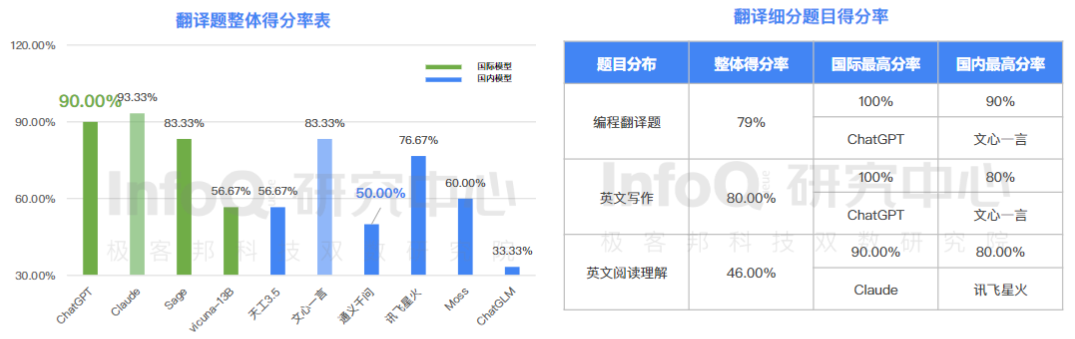
要知道 GPT 是支持多达 26 种语言的,而国内得分最高的文心一言直到今天,也只能支持中英文两种。
7、逻辑推理能力挑战整体较大,国内部分产品表现接近 GPT-3.5
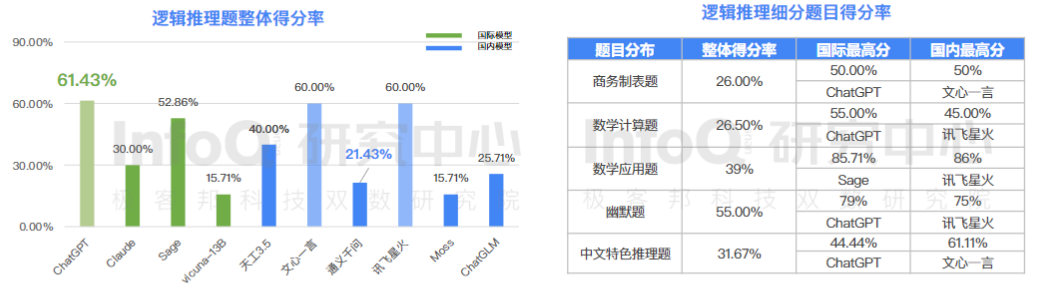
逻辑推理能力考的是开放性问题,没有标准答案,从结果看,文心一言和讯飞星火的成绩不错。
二、中文语言理解测评基准 superCLUE
豆茉君发现了一个叫做 superCLUE 的中文大模型评价体系,论文署名是西湖大学的各位专家们。

他们还成立了一个叫做 Chinese GLUE 的组织,组织的成员都是国内的学者和专家:

如果说 InfoQ 的评测是媒体级的专业,那么 superCLUE 就是学术级别的专业。
superCLUE 体系,相较于国外学术界其他的体系,其最大特点在于:
采用了多种评价方法,包括实际用户查询和评分、开放式问题以及闭合式问题,综合考察 LLM 在不同应用场景中的性能,使评价更全面。
强调开放式问题,更好地反映了 LLM 与用户在实际应用中的互动能力。
使用 GPT-4 作为可靠的评价工具,自动评估开放式问题,提高了评估的效率和一致性。

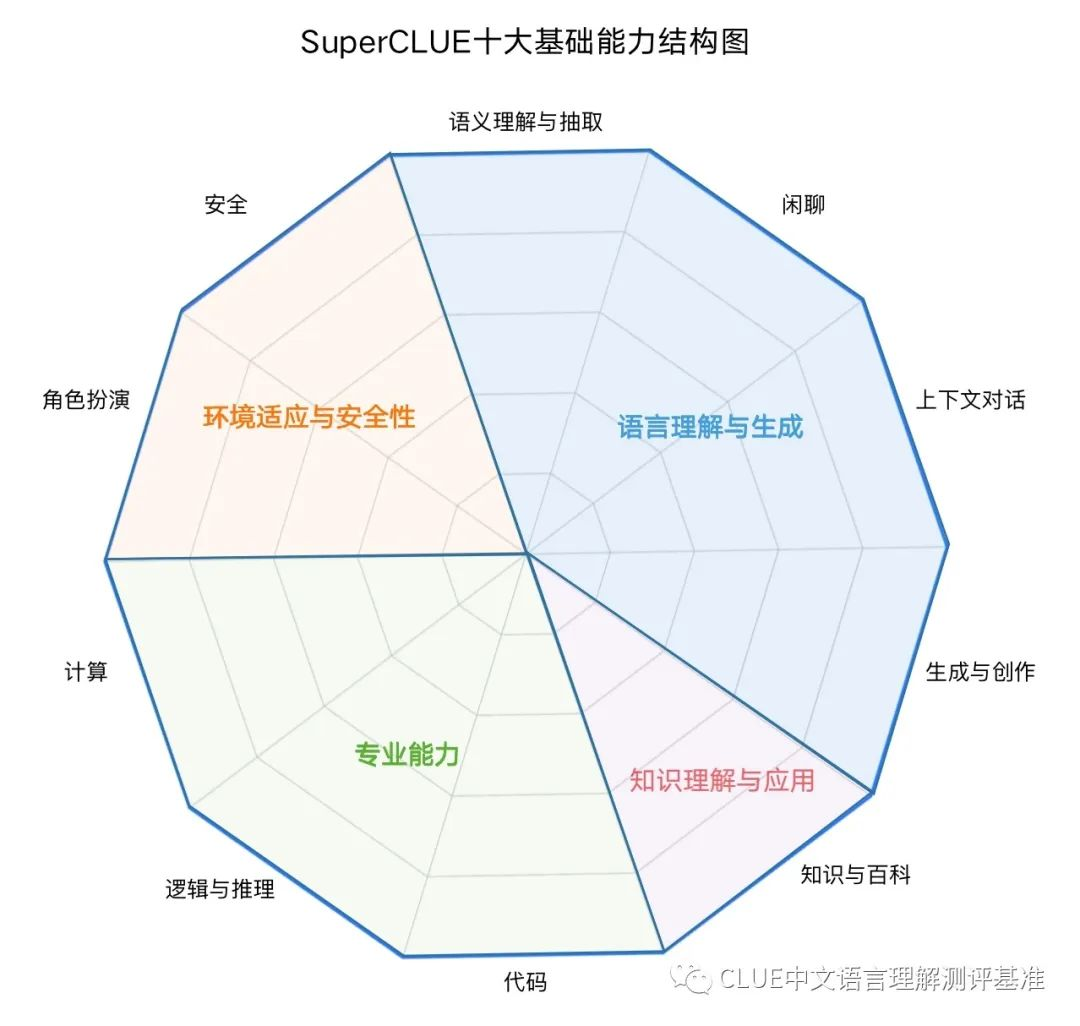
指标体系
superCLUE 的指标体系包括四大项 10 小项:
测试问题集
由于采用了 GPT-4 作为裁判,可以大大增加评判效率,所以 sperCLUE 的测试问题集非常大。分为 CArena、OPEN Set 和 CLOSE Set 三大数据集:
CArena
CArena 专门设计用于中文语境中的聊天机器人(chatbots)交互评估。它允许用户同时与两个匿名聊天机器人进行对话,然后根据个人偏好对其进行评分。CArena 旨在评估聊天机器人在实际对话情境中的表现,以了解用户的喜好和评价。


在 CArena 中,用户可以与不同的聊天机器人互动,并评估它们的回答质量。这个平台旨在收集大量用户与聊天机器人的交互数据,以帮助开发者更好地了解他们的模型在真实用户交互中的效果如何。
CArena 的设计使其能够支持单轮和多轮对话,以更全面地评估聊天机器人的性能。这个平台的目标是为开发者提供一个可靠的方式来测试他们的聊天机器人,并获得用户反馈,以进一步改进他们的模型。
OPEN Set
OPEN Set 数据集包括了 SuperCLUE 基准测试的一个重要子任务,旨在评估大型语言模型(LLMs)在中文语境下处理开放式问题的能力。这个数据集涵盖了单轮和多轮对话的开放式问题,为了了解更多关于 LLMs 在实际应用中的表现,提供了有意义的答案。问题数量一共有 600 个。

在 OPEN Set 数据集中,问题是开放式的,这意味着它们不能简单地用"是"或"否"回答,也不能通过多项选择或特定信息来回答。这些问题需要思考,需要提供一个充分而有意义的答案,通常需要使用回答者的知识和/或感觉来回答。
此数据集中的问题涵盖了不同主题和领域,旨在评估 LLMs 在各种任务和情境中的性能。对于每个问题,还可以包括一个或多个后续问题,以促使更深入的对话。
CLOSE Set
CLOSE Set 是 SuperCLUE 综合基准测试的一个子任务,旨在评估中文大型语言模型(LLMs)在处理封闭式问题时的性能。封闭式问题是一种类型的问题,可以用简单的"是"或"否"回答,或从一组多项选择中选择一个答案,或提供特定的信息来回答。这些问题通常不需要深思熟虑,因为它们的答案通常是明确的。
在 CLOSE Set 中,研究人员使用 GPT-3.5,将 SuperCLUE 的开放数据集中的问题转换为带有 4 个选项的封闭式问题,并进行了人工校对,以供评测使用。
评测结论
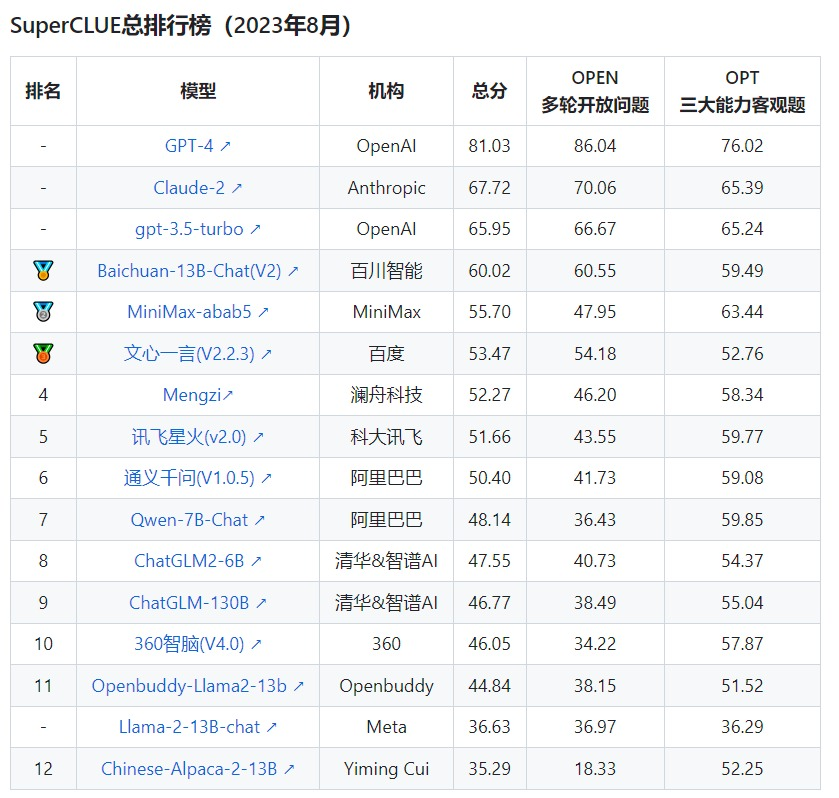
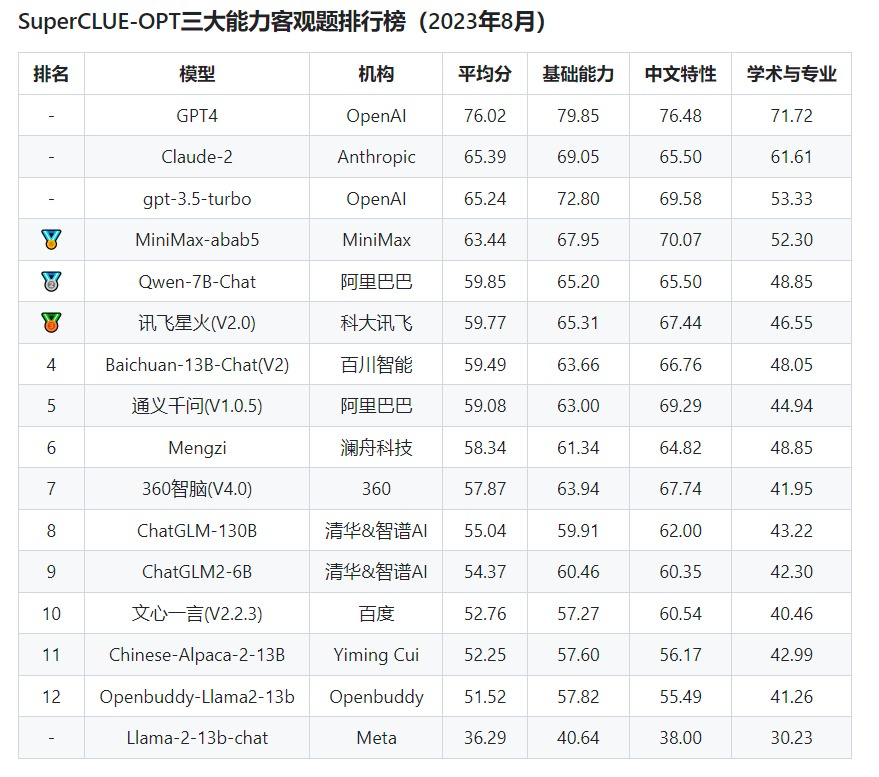
最棒的是,SuperCLUE 的评测会每个月都做,每个月都会给出最新的评测结论,所评测的对象是最新的大模型版本,最新的排行榜是 8 月份的。

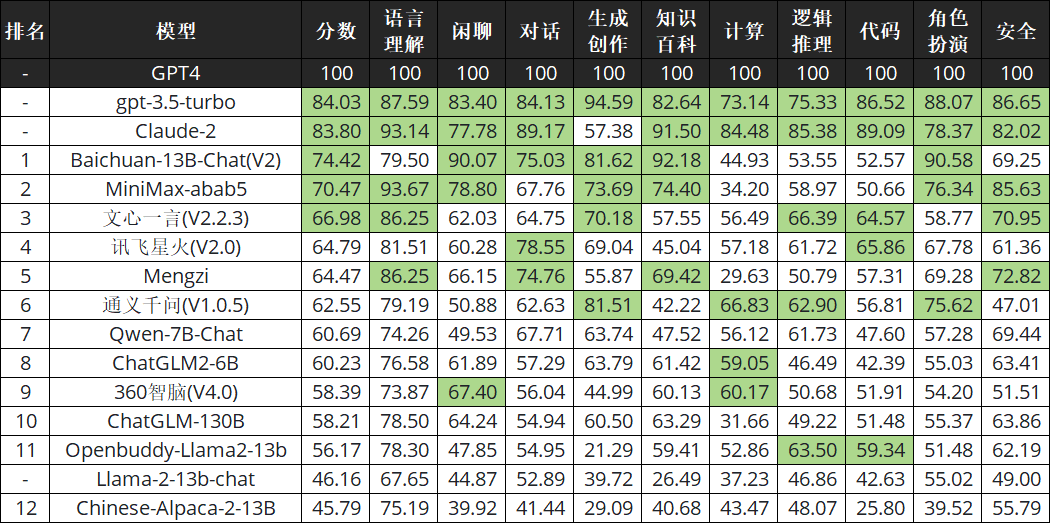
从总榜来看,Top 3 是 GPT-4、Claude-2 和 GPT-3.5,这也是豆茉君的使用体验和内心答案。而国内方面,百川排第一,MiniMax 排第二,文心一言排第三:
从十大能力分项来看,结果如下:
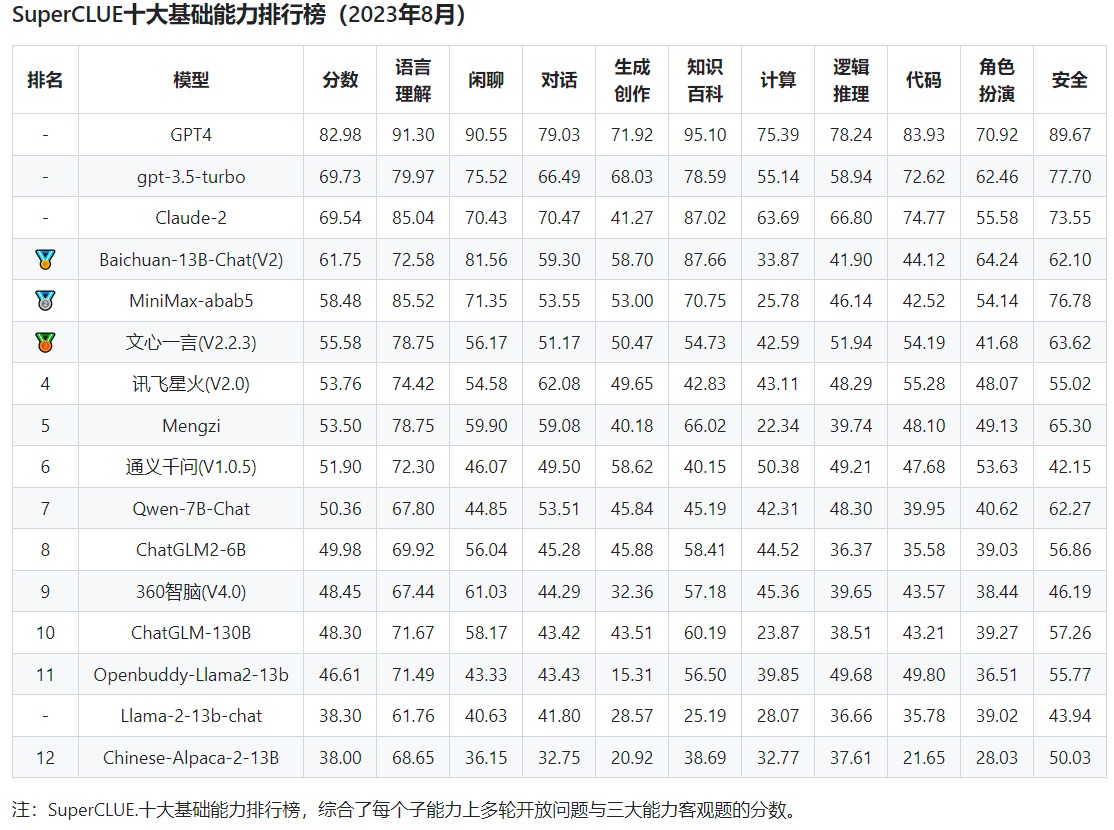
为了方便比较,豆茉君把 GPT-4 的各项能力值调为 100,其他模型的都是相对于 GPT-4 各项的相对分数,绿色标出了每一列的前 5 项得分:
1694077705400.jpg
相比较其他模型,这个 MiniMax 特别神秘,豆茉君也查了下,才发现 MiniMax 联合创始人为前商汤科技副总裁、通用智能技术负责人闫俊杰,也曾担任商汤研究院副院长。闫俊杰于 2015 年博士毕业于中科院自动化所,此前在商汤科技负责搭建深度学习的工具链和底层算法,以及通用智能的技术发展。此外,他还搭建了商汤的人脸识别和智慧城市相关的技术体系。
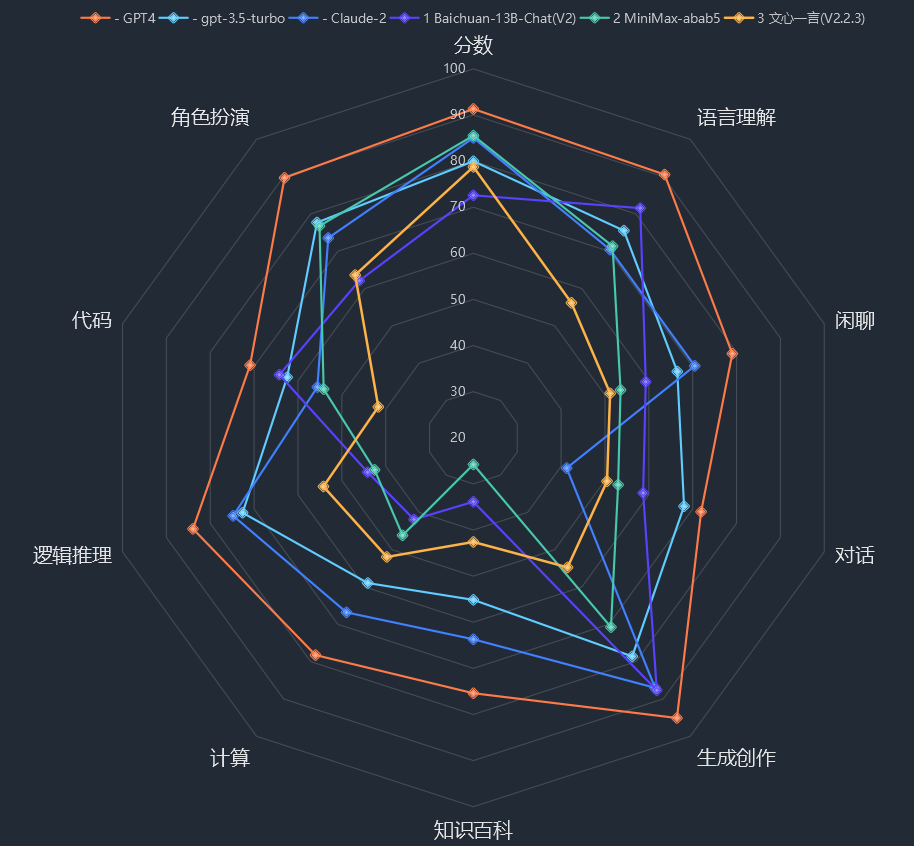
其他评测结果还包括:

结语
看完这些评测结果,豆茉君觉得自己 20 美元每个月的 GPT-4 买的还是值得的😅。而国产大模型的话,优先用百川、MiniMax 和文心一言,是不错的选择。
版权声明: 本文为 InfoQ 作者【豆茉君】的原创文章。
原文链接:【http://xie.infoq.cn/article/f97785caf997a63b21c21f7bc】。未经作者许可,禁止转载。

公众号「别学AI」 2023-09-04 加入
华科本硕,AI 俱乐部合伙人,GPT 达人









评论