
JVM 调优
什么时候 JVM 调优
要对 Java 应用程序进行调优,优化 JVM 并不是第一选择。我们首先应该考虑软件架构和代码优化等方面,这方面的优化可能会取得更大的进步空间。因此假设我们已经对于软件架构、代码优化、数据库优化等等做过了一些努力,接着我们希望通过 JVM 调优来做一些事情,那么我们可以接着往下读。
性能优化的一些方式:
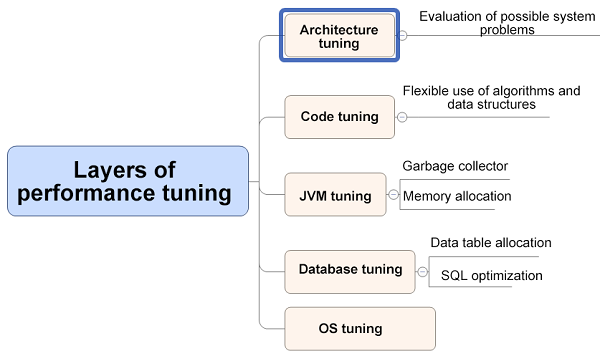
JVM 调优指标
我们对 JVM 调优有哪些指标呢?一般来说有下面三点:
吞吐量(Throughput):is the percentage of time the VM spends executing the application versus time spent performing garbage collection.
延时(Latency):is the amount of time required to run a garbage collection event.
资源占用(Footprint):is the amount of memory required by the garbage collector to run smoothly.
如果能增加资源投入,提高 CPU、内存等,自然可以提高吞吐量和减少延时。
对于吞吐量和延时,我们一般通过调节垃圾收集参数来做权衡。而对于吞吐量和延时的不同的统计方式,可能会得到不同的结果。
对于垃圾收集对应用程序请求的影响的计算方法,可以参考美团文章。通过统计一分钟内请求受影响的占比,来判断 GC 影响时间是否减少。
我们还可以开启 GC 日志,来看每次垃圾收集的时间、频率,来判断 GC 总时间是否减少。
当我们进行各种压力测试,基准测试后,拿到这个测试数据,才能判断是否达到了我们预设的指标。
获取 JVM 监控数据
开启 GC log
-Xloggc specifies where the file is located
-XX:+PrintGCDetails – includes additional details in the garbage collector log
-XX:+PrintGCTimeStamps – prints the timestamps to the log
开启 GClog 可得到如上日志,不同的垃圾收集器可能形式略有差异,但都大致相同。上面写了由于内存分配失败而导致 full GC。显示了新生代,老年代,堆内存,元空间垃圾收集前和后的空间大小的变化。垃圾收集时间,用户态时间、内核态时间、真正用时等。
关于 gclog 文件的分析,可以参考https://sematext.com/blog/java-garbage-collection-logs/#parallel-and-concurrent-mark-sweep-garbage-collectors。至于好用的免费可视化工具没有发现,如果有人知道可评论区指出。
jmap
此命令可以获得当前堆快照,我使用 JProfiler 来查看堆信息。官方操作文档
先使用 jps -v查看 Java 程序进程 id,然后使用jmap -dump:live,format=b,file=<filename> <PID>,filename 可以起名为 xxx.hprof
-XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=./heapDump.hprof 此两个参数当 OOM 发生后,会生成堆快照来帮助排查问题。
文件如下:
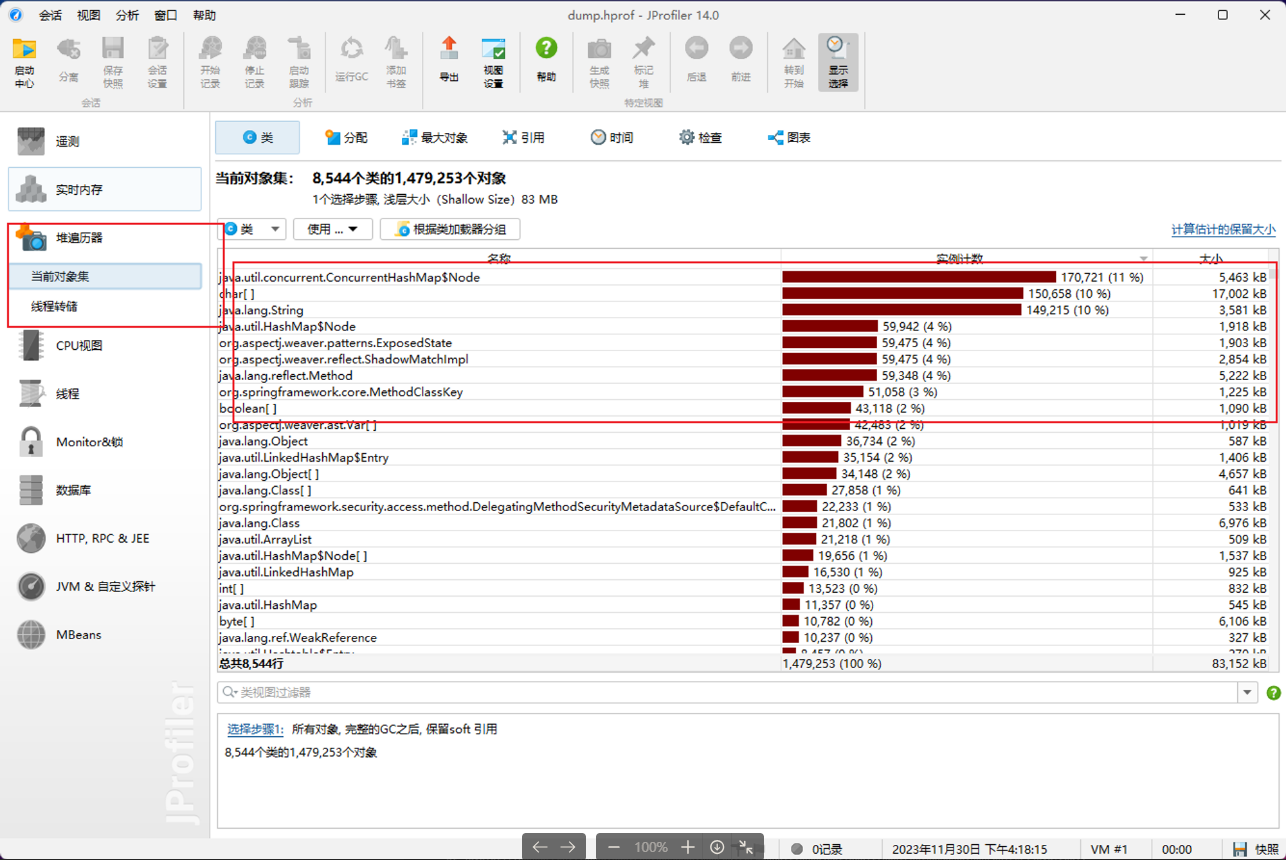
JProfiler
至于 JProfiler 的安装部署不赘述,只列几张图片看看大致监控的内容。

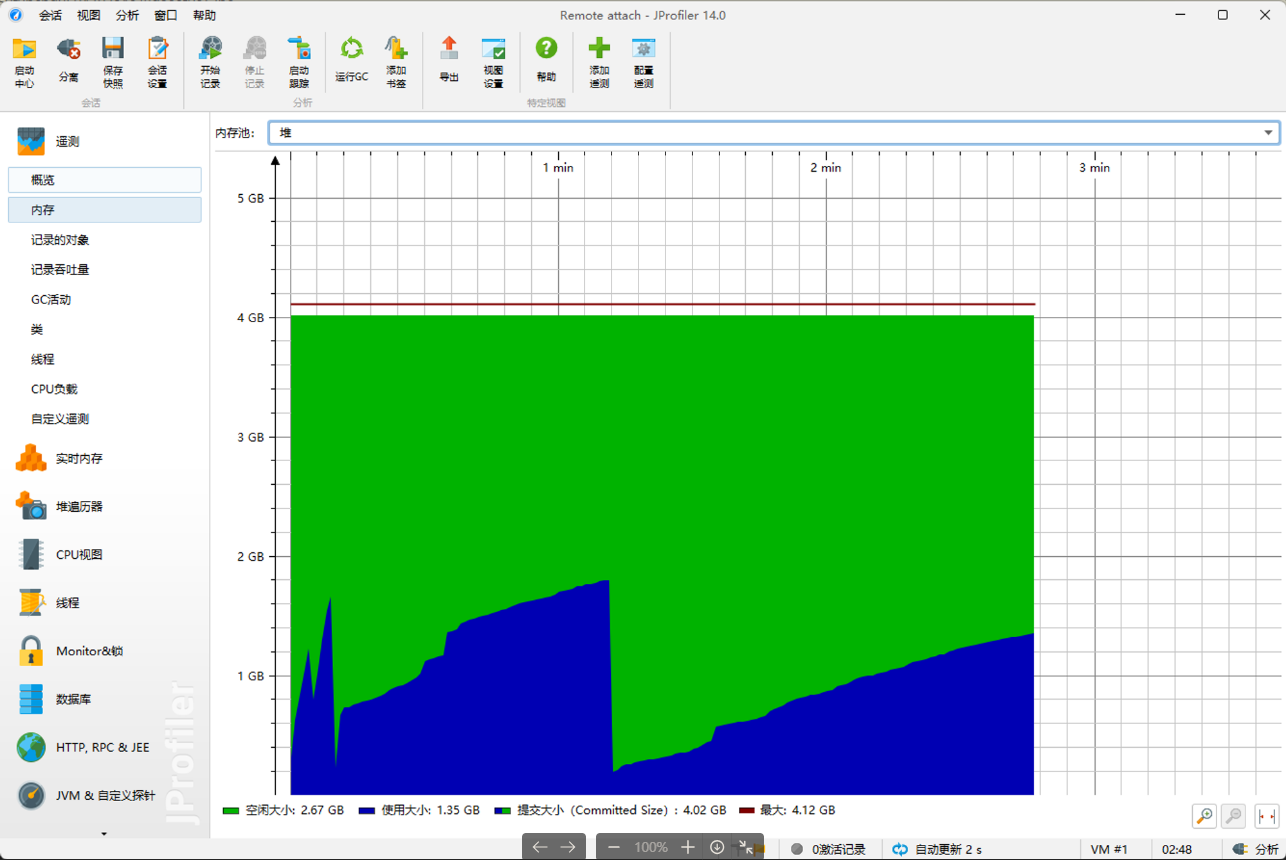

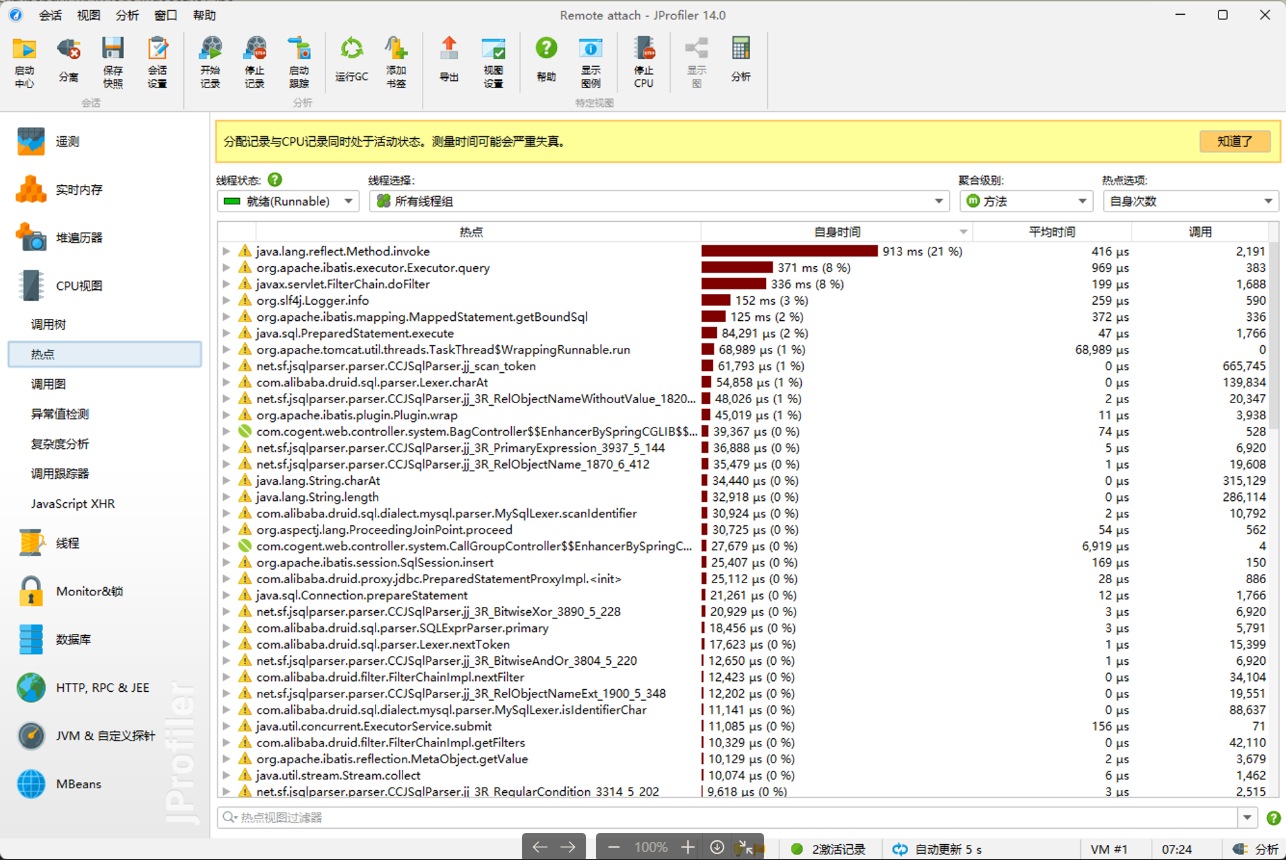
jstat
jstat 可实时查看堆状态。
先jps -v得到 Java 程序进程号,再jstat -gcutil <pid> <time interval>(Example: jstat -gcutil 29218 3000 每隔三秒打印一次 Java 进程号为 29218 的 gc 信息)。
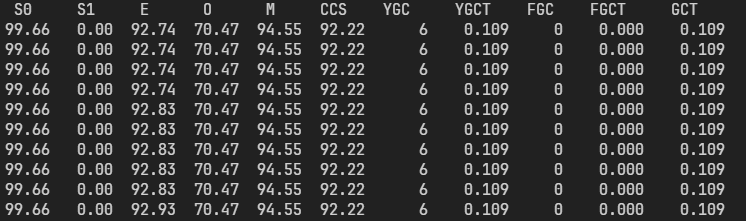
S0,S1:幸存者区
E:Eden 区
O:Old 区
M:Metaspace
CCS:被编译的类所占元空间大小
YGC:Young GC 次数
YGCT:Young GC 总时间
FGC,FGCT:Full GC 次数,总时间
GCT:GC 总时间
关于 jstat -gc 和 jstat -gcutil 区别,主要是第一个显示实际大小,比如多少 k。第二个显示百分比
Arthas
使用Arthas也可以监控 cpu,内存,gc 等情况,具体可参考官方文档。也可参考我的这篇文章关于使用Arthas排查问题
无论使用什么方式获得 JVM 运行信息,最终我们要得到几组数据,用数据证明我们的调优确实有作用。
关于垃圾收集器
如果是 JDK8,那么会有人说 CMS 是延时低的,Parallel GC 等是吞吐量高的。但实际上还要经过测试才能确定。
对于 JDK 大于 8 的,比如 JDK17 等,可以看看 G1、ZGC 等收集器,测试其是否合适。
GC progress from JDK 8 to JDK 17
JVM OPTs 样例
-Duser.timezone=Asia/Shanghai-Xms6G -Xmx6G-XX:NewSize=3G -XX:MaxNewSize=3G-XX:SurvivorRatio=10-XX:MetaspaceSize=2G -XX:MaxMetaspaceSize=2G-XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=./heapDump.hprof-XX:+PrintGCDetails -XX:+PrintGCTimeStamps -Xloggc:gc.log
Xms Xmx 设置堆大小,两者一样可以避免扩容而导致一定延时 SurvivorRatio 影响幸存者进入老年代的年龄阈值 MetaspaceSize 设置一样可以防止扩容而导致延时 HeapDumpOnOutOfMemoryError OOM 后输出堆快照 PrintGCDetails .... 打印 GClog
JVM 调优案例
例子大部分来自于《深入理解 Java 虚拟机》,不说具体例子,只说造成结果
大对象直接进入老年代
导致老年代很快内存不够,导致频繁 full GC,从而更多的延时
内存溢出
大量数据缓存到 Java 的堆中得不到释放,导致 OOM。只要我们开启 HeapDumpOnOutOfMemoryError 查看堆信息,基本上就能知道缓存了大量的什么 Java 对象。
Direct Memory
我们一看到直接内存就能想到 NIO,可以尝试扩大 Direct Memory
外部命令导致资源占用
Java 程序大量调用外部 shell 脚本
socket 连接耗尽
发送的 http 请求,而响应却很慢才返回,导致 socket 耗尽
内存占用过大
数据结构问题,比如我们想查看某个人的一年的出勤率,我们可以看他未出勤的数据。比如我们就是要看一个人 365 天每一天的是否出勤,那么可以用 map 存 365 个 key、value,但使用一个 365 长度的 01 字符串更节省空间。
safepoint
文中说 JVM 对 for 循环有 safepoint,对于 for int 的是整个执行完才过 safepoint,对于 for long 的是每一个循环就有 safepoint。由于一个 for int 执行时间过长导致 STW 过长。
总结
对于 JVM 调优,我们首先需要知道有什么样的问题,我们调优的目标是什么。一般有三个指标,吞吐量,延时,资源(footprint)。明确我们需要提高哪项指标后,才可进行相应的手段进行优化。
并且还有一个前提条件,那就是对于系统架构和代码层面的优化也做过了,对于数据库相关的优化也做过了,那么我们可以尝试调优 JVM 来优化相关指标。以为我们不能指望通过调优 JVM 来大幅提升性能。
仅仅从 JVM 角度说,如果我们要提高吞吐量,我们可以提高物理机性能,比如多开内存。或者换一个更注重吞吐量的垃圾收集器。当然也可以调节 JVM 参数来减少垃圾回收次数。
比如我们要减少延时,还是多开内存。或者换一个更注重降低延时的收集器。当然也是可以调节 JVM 参数减少垃圾回收次数等等。
如果我们要减少资源,如果可以忍受降低程序性能的话。那么我们能做的可能就是调节新生代,老年代比例等,比如我们的应用是朝生夕灭多(调大新生代),还是永久的对象更多(调大老年代)。
文章转载自:KeBoom

还未添加个人签名 2023-06-19 加入
还未添加个人简介









评论