
应用层修复大语言模型(LLMs)输出异常 JSON 通用解决方案

摘要: 在应用集成大语言模型逐步深入的过程中,对于以 JSON 为代表的结构化数据输出逐步成为核心用例。在模型无法保证 100% 生成正确 JSON 输出的当下,应用层是否有一套能够适配多语言,多种结构化格式,同时提供更为健全修复能力的方案?本文结合个人经验,提出了一个基于 ANTLR 的修复方案,希望能为你带来一定的参考价值。
大语言模型结构化输出的意义
在 2024 这一年,基于大语言模型(LLMs)的 AI 应用层出不穷,类 Chatbox 的交互形式早已不能满足应用系统软件对智能化的需求。随着应用系统与软件对于大语言模型(LLMs)集成的不断深入与扩展,对于大语言模型(LLMs)输出内容的结构化呈现的诉求愈发明显。结构化数据对于系统自动化程度、系统间互操作性都有着极其重要的意义,而从非结构化输入产生结构化数据已是当下应用人工智能的核心用例场景。
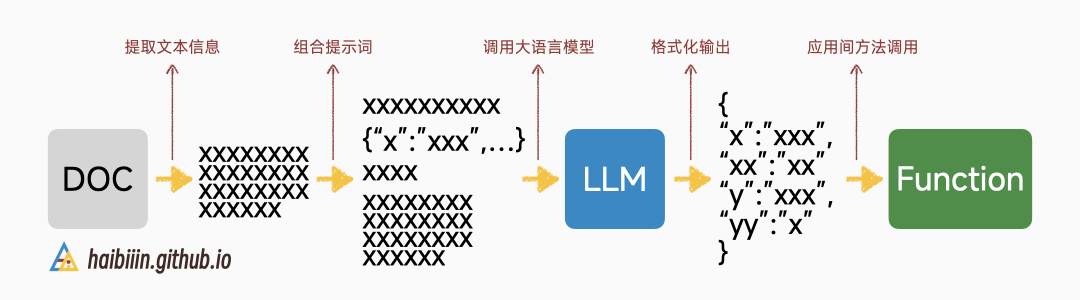
但是大语言模型的概率采样推理过程。决定其难以 100% 按照要求输出准确的格式化数据。而这一步错误会导致整个链路后续操作无法进行,进而影响系统功能。
大语言模型结构化输出的现状
截止目前(2024 年底)市面上能够 100% 支持结构化输出的大语言模型依然凤毛麟角,有部分大语言模型支持 JSON 模式,虽然该模式可以一定程度上提升模型输出有效 JSON 格式的可靠性,但依然不能保证 100% 稳定,除了需要提示词的调教外,仍需应用层对输出结果进行校验。
OpenAI 在 8 月份为 gpt-4o 增加了 结构化输出(Structured Outputs) 的能力,通过 OpenAI 的文章(Introducing Structured Outputs in the API)与数据显示可以 100% 输出 JSON 格式内容,但国内大语言模型厂商尚未发布同类功能。
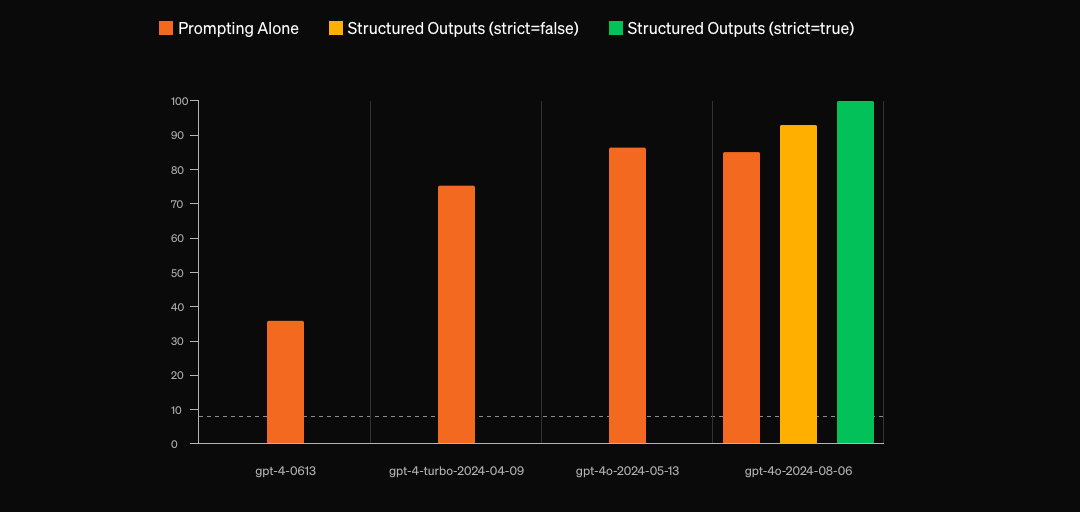
通过 OpenAI 的文章与数据,我们可以发现即便是 gpt-4o 在仅仅使用提示词的情况下,也有近 15% 的几率无法生成有效的 JSON 格式。我们可以借此推测其他大语言模型在同类场景下的表现效果,如果与这 15% 的几率存在上下 5% 的浮动差距,那么,意味着在效提示词的加持下,大语言模型普遍情况下存在 10-20% 几率无法生成有效 JSON 格式。
对于多数没有模型开发能力或者模型能力相对较弱的应用开发来讲,几乎无法在模型输出前和输出过程中进行干预,则需要应用层做更多的努力来消减产生异常结构数据的情况,避免引发系统异常。
一种最简单的实现方式,当模型输出数据不满足要求,无法进行后续方法调用等操作时,重新调用大语言模型(LLMs)尝试生成新的输出内容。显然,这种方式执行过程中即耗时,也会消耗更多的 token,是一个成本比较高的方案。
好在基于合适的提示词加持,大语言模型(LLMs)生成的异常 JSON 通常并不离谱,而且 JSON 格式的规则相对并不复杂。使得我们可以基于字符串的遍历,进行简单的检查与修复。且市面上已经有一些针对 Python、Go、JavaScript 的开源库用于对异常 JSON 进行简单修复。
但是该方案所能提供的修复能力有限,如果系统需要的格式化数据不是 JSON ,而是更复杂的格式化数据,则显得捉襟见肘。同时应用系统中大量基于 Java 以及 JVM 系语言尚没有相对成熟的开源库。
基于 ANTLR 解析 JSON 抽象语法树进行修复
结构化数据的好处是,对于结构的描述必然有一套适配的语法规则,与之相对的文本理应可以生成一套语法树。那么对于异常结构是否可以基于已知的语法树进行修复?而且因为系统在与模型交互时,通常会在提示词中给出明确的格式化样例,那么也就意味着拥有一个准确的语法树作为修复参考,同时也就意味着可以修复任何异常结构。
如此一来,问题便变成了如何通过文本构建并遍历一颗抽象语法树。如果我们可以提供一个通用的解决方案,也就意味着对异常结构化数据修复存在一个统一的解决方案。
接下来我将结合个人实际经验,阐述基于 ANTLR 实现异常 JSON 的修复方案。通过该方案,理论上可以迁移到对其他结构化数据的修复中。
整个解决方案最关键的一步是寻找一种能够通过文本构建并遍历一颗抽象语法树的工具,好在我们有 ANTLR 。
ANTLR 是什么
我么将 ANTLR 官网的介绍摘录与翻译如下:
ANTLR (ANother Tool for Language Recognition) is a powerful parser generator for reading, processing, executing, or translating structured text or binary files. It's widely used to build languages, tools, and frameworks. From a grammar, ANTLR generates a parser that can build and walk parse trees.
ANTLR(另一个语言识别工具)是一个强大的解析器生成器,用于读取、处理、执行或翻译结构化文本或二进制文件。它被广泛用于构建语言、工具和框架。ANTLR 根据语法生成一个解析器,该解析器可以构建和遍历解析树。
透过介绍,我们似乎可以确认 ANTLR 便是我们所需要的那个工具,同时其对运行时的支持也相对广泛,涵盖:Java、C#、Python、JavaScript、Go、C++、Swift ,这也意味着对应用系统全平台的覆盖性。
再看案例层面,Apache ShardingSphere 基于 ANTLR 做 SQL 语法解析以实现相应关键属性替换进而实现 SQL 分片相关能力。除此之外还有诸如 Drools、Hive、Cassandra 等知名项目中均有对 ANTLR 的使用。当然,通常情况下这些软件依赖 ANTLR 都是在处理正确的文本内容,基于 ANTLR 解析器来构建自身特殊需求。
而我们需要 ANTLR 处理异常文章进行修复,使用的方向略有不同,但对于 ANTLR 的应用则大同小异。
第一部分:语法文件
ANTLR 需要基于语法文件来进行解析,好在 ANTLR 官方提供了 JSON 的语法文件,省去了我们自主编写语法文件的过程,该文件部分内容截取如下:
有了上面的语法文件,我们可以利用 ANTLR IDEA plugin 实现抽象语法树的可视化分析,具体示例见下图:
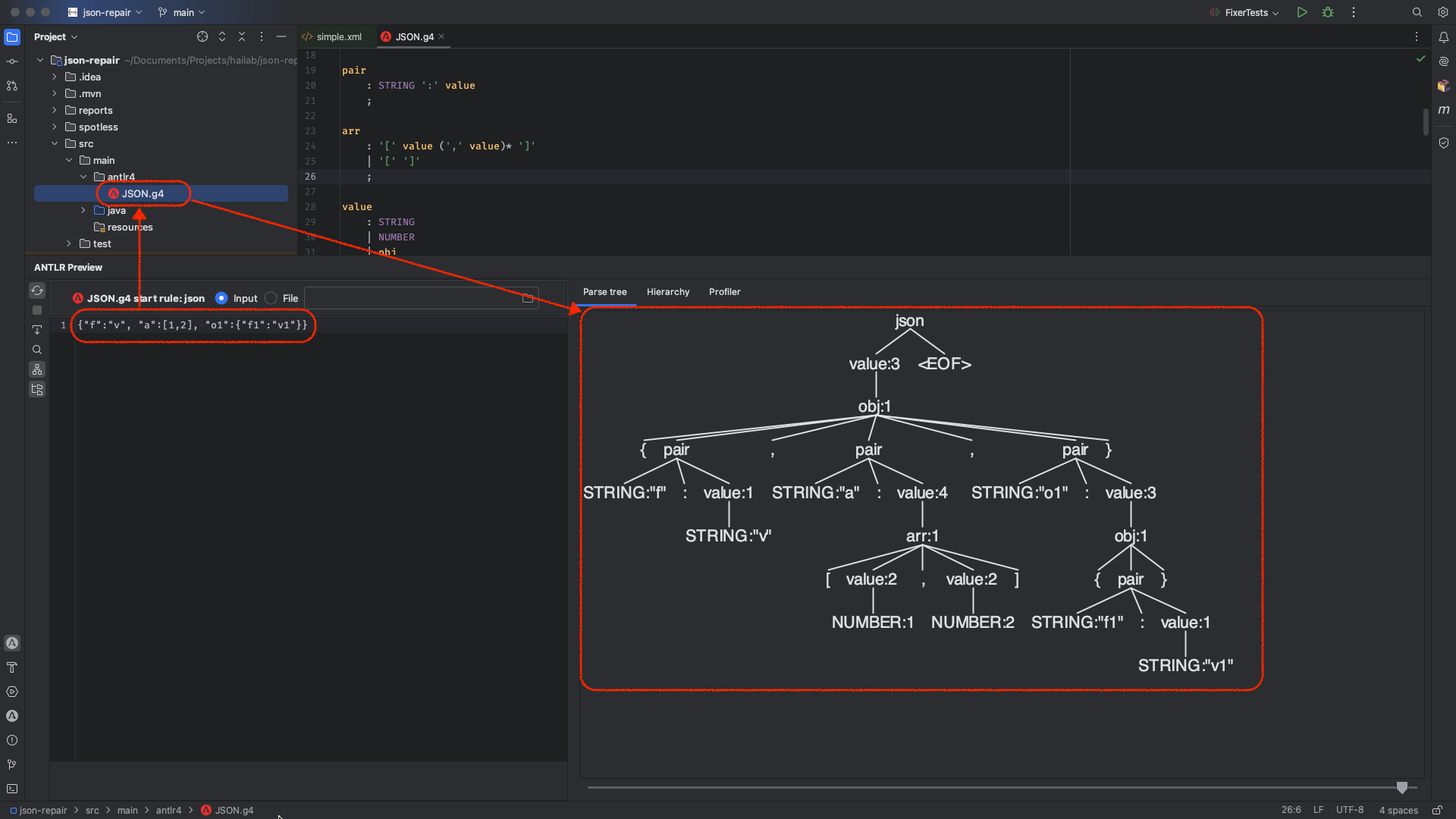
上图展示了一个完整匹配 JSON 格式的字符串所构建出的语法树。
同时,对于异常 JSON 字符串,因为有 JSON 语法的定义,ANTLR 在解析的过程中,可以同时记录异常节点,并对该节点预期内容判断。具体示例见下图。
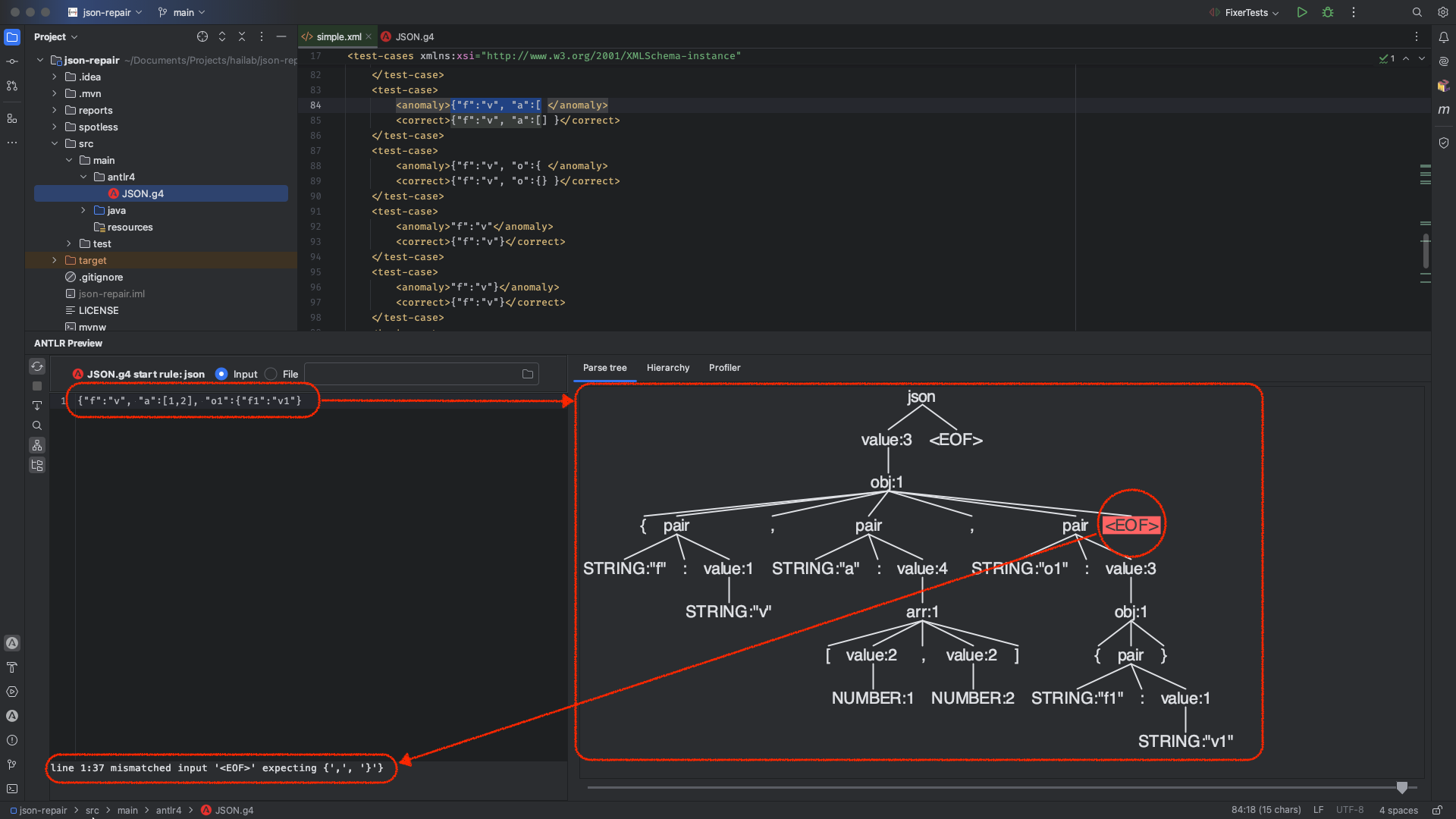
上图左下角显示了对于结尾异常节点(同时 line 1:37 也提示了问题节点处于字符串中的哪个位置)所期望出现的内容为 , 或 } 。
第二部分:遍历修复
基于上述语法文件 ANTLR 可以生成目标语言的解析器代码,同时配合目标语言的运行时,使用者可以方便的开发自定义业务逻辑代码。ANTLR 语法分析基本过程如下图所示。其生成的解析器代码主要包含 Lexer(词法分析) 和 Parser(语法解析) 两部分。
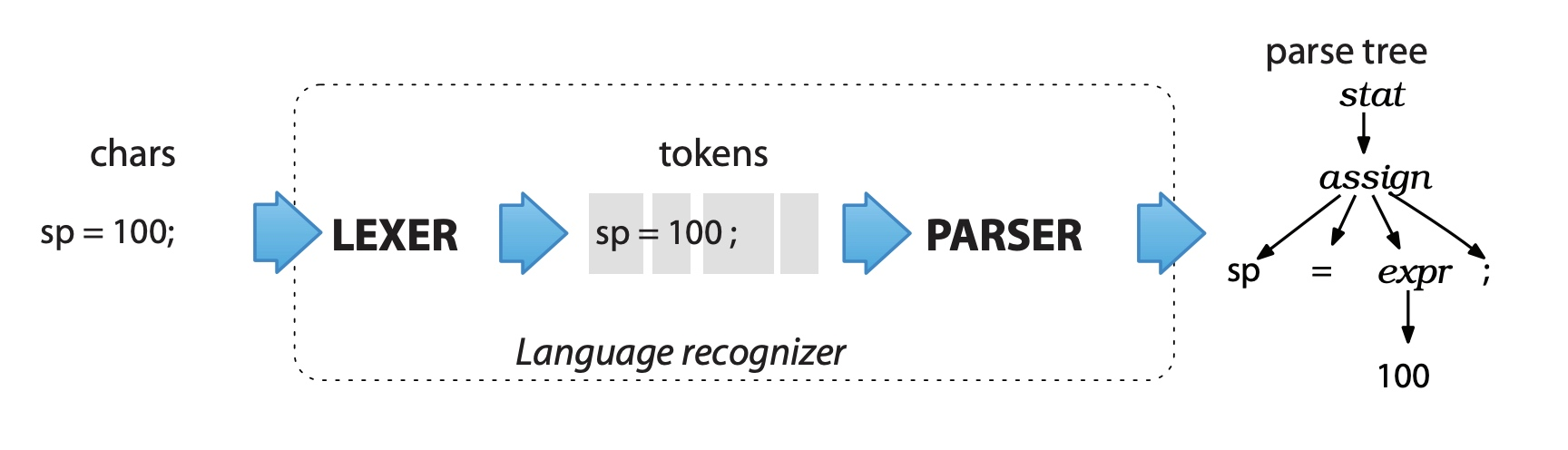
ANTLR 的运行时提供了两种遍历树的机制——语法分析树监听器(Listener) 和 语法分析树访问器(Visitor),使用者主要实现自定义的监听器或访问器来实现自定义逻辑。我们这里主要利用访问器实现对语法树的遍历,可以先了解一下访问器的遍历与执行过程,具体可参考下图示例:
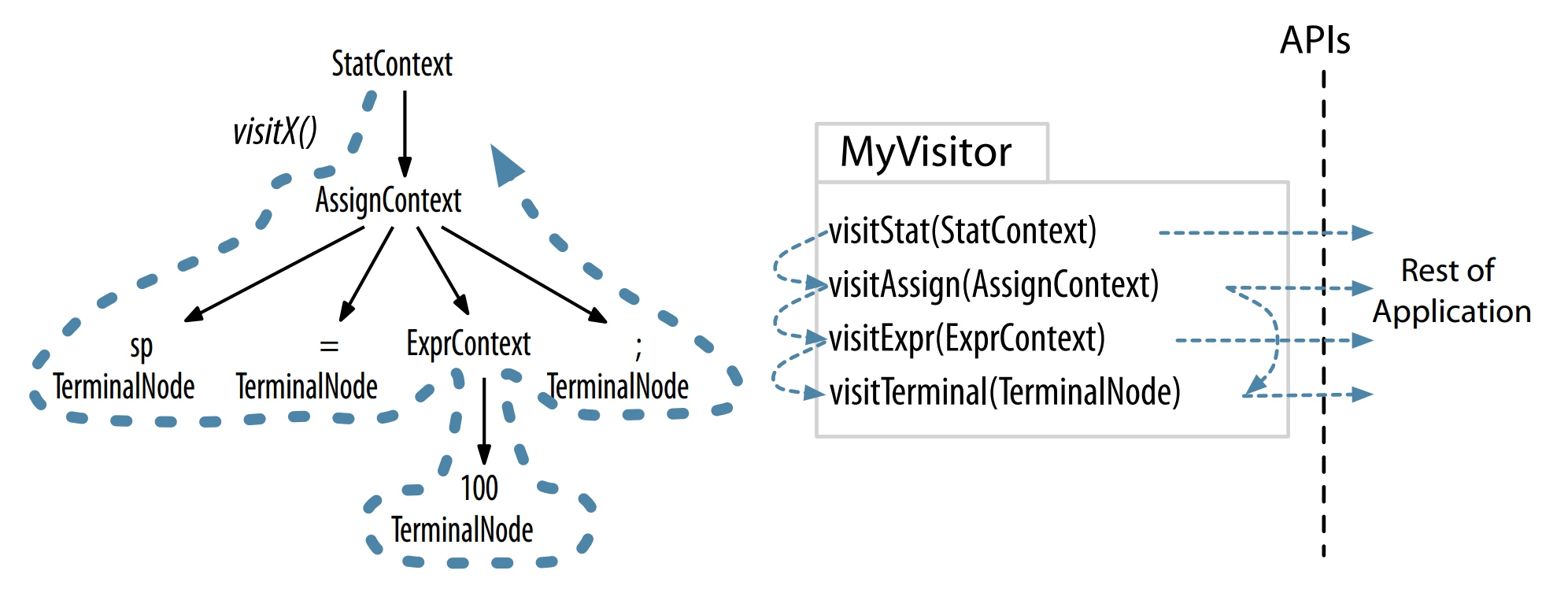
除此之外,ANTLR 在其运行时有一定默认监听器,用于记录异常节点(token)信息以及记录该节点期望出现内容。
下面案例内容以 Java 作为编译器目标语言与运行时语言。基于前面的 JSON 语法文件会生成 JSONLexer JSON 词法分析类和 JSONParser 语法解析类,我们需要将 JSON 字符串转换为流用于构建这两个类的实例。
之后实现 ANTLRErrorListener 接口构建我们自己的异常信息,并加入到 Lexer 与 Parser 实例监听器中。
理论上单异常信息为空时,可以认为该字符串符合 JSON 格式,无需进行修复。而且我们可以基于异常信息尝试对字符串进行修复,便可以实现基本的修复能力,而无需进行语法树的遍历。
除了对 JSON 格式修复外,我们可以对大语言模型产生的 JSON 输出进行修正,例如部分 JSON 属性不匹配,或者面临值确实的时候,简单处理我们可以会为其设置 NULL,但是基于提示词中的 JSON 示例,可以实现对其更准确的修正。
我们将 JSON 示例与模型输出的文本分别通过 JSONParser 构建出两颗语法树,并对其同步遍历,当遇到问题时可以参照示例 JSON 语法树进行修复与订正。那么意味着我们不仅可以修复 JSON 格式,理论上为应用层提供了一套实现针对大语言模型生成的任意结构化语言的统一修复方案。并且可以确保较高的准确性。
开箱即用的 Java 开源实现
上文中主要阐述了思路,要想实现还是需要一点工作量。接下来我会介绍我们基于上述思路,采用 Java 语言的并提供出来的开源实现 json-repair ,如果你感兴趣可以 clone 到本地了解,也可以尝试接入项目验证是否满足使用场景。
该组件已发布到 Maven 中央仓库,可直接通过 Maven 或 Gradle 引用。
一旦引入项目后,只需要实例化 JSONRepair 并调用 handle() 方法便可以完成异常 JSON 的修复。
目前最新版本为 0.2.1 版本,支持对异常 JSON 的简单修复:
修补缺少的右括号;
修补缺少的右中括号;
值为数组情况下多余逗号清理;
值缺失以 null 填补;
修补缺少的左括号;
修补缺少的最外层括号;
修补个别场景下字符串缺少引号。
基于示例 JSON 进行修正的功能正在跌倒开发中,你可以通过项目主页 或 项目介绍页 了解更多关于性能、测试覆盖、修复场景、功能跌倒等内容。
总结
当然,随着大语言模型能力的逐步完善,相信总有一天,应用层修复结构化输出内容的方案会成为历史。但是,在前往那一天的路上,这一过程似乎是必然的经历。希望上述思路与案例能够为更广泛的开发者提供有价值和有意义的参考。
如果您发现文章内容中任何不准确或遗漏的部分。非常希望您能评论指正,我将尽快修正疏漏,为大家提供优质技术内容。
参考链接:
你好,我是 HAibiiin,一名探索技术之外更多可能性的 Product Engineer。如果本篇文章对你有所启发或提供了一定价值,还请不要吝啬点赞、收藏和关注。
版权声明: 本文为 InfoQ 作者【HAibiiin】的原创文章。
原文链接:【http://xie.infoq.cn/article/f5127bde6115158c21ed8ec4f】。文章转载请联系作者。

为自己工作 2018-02-19 加入
你好,我是 HAibiiin。擅长古法纯手工软件制作工艺,也算半个手艺人。偶尔写作擅长熵增加,记录对自我与技术的好奇。












评论