
FFA 2022 主会场 Keynote:Flink Towards Streaming Data Warehouse

摘要:本文整理自 Apache Flink 中文社区发起人、阿里巴巴开源大数据平台负责人王峰(莫问),在 Flink Forward Asia 2022 主会场的分享。本篇内容主要分为四个部分:
实时流计算全球范围事实标准
2022 数据实时化技术创新不止
Streaming Data Warehouse
流式数仓 Demo
一、实时流计算全球范围事实标准
Apache Flink 社区从 2014 年诞生到 2022 年已经经过了连续八年的快速发展。从早期的互联网行业逐步扩展到更多的传统行业,比如金融、电信、交通、物流、以及能源制造等等。
Apache Flink 诞生于欧洲,爆发于中国。最近几年席卷全球,在北美、东南亚等全球各地开始被大量使用。可以说在全球的各个行业,只要大家想到实时流计算,基本上都会选择 Apache Flink。因此我们就可以认定 Apache Flink 社区已经成为了全球范围内实时流计算的事实标准。从 2022 年社区的各项指标中,也进一步得到印证。
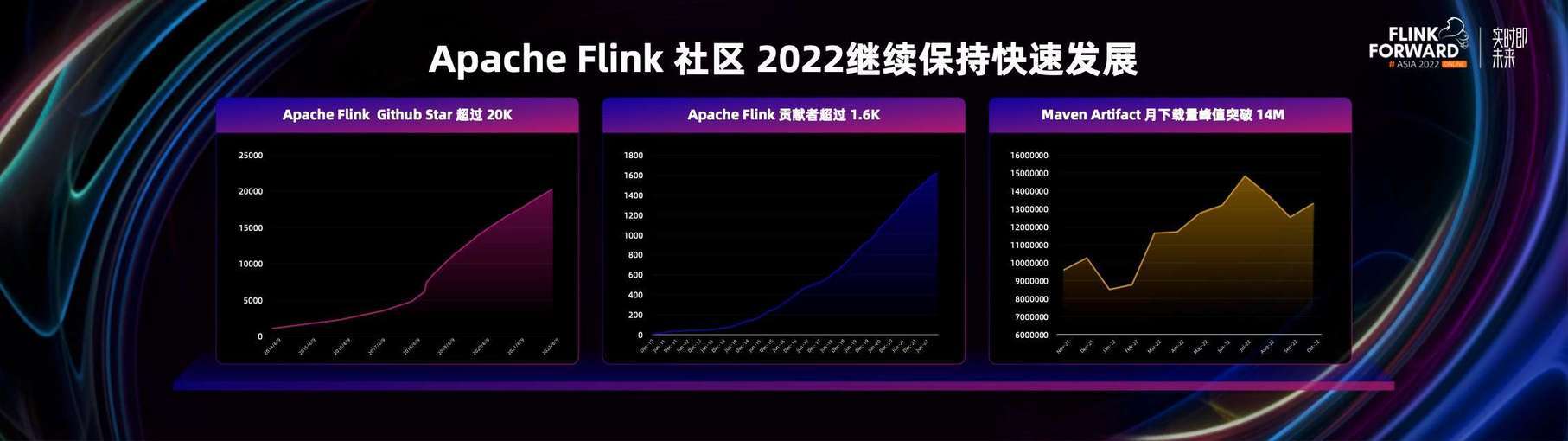
Flink 社区经过八年的快速发展,在 Github Star 上也一直持续稳定的快速增长。目前为止,Flink 的 Github Star 已经超过了 20000,这在 Apache 主流的大数据项目中依然是名列前茅的。
在开发者生态方面,我们也已经积累了超过 1600 名的开发者,为 Flink 社区做贡献,2022 年又新增加了 200 多名开发者。从下载量上也可以看到,Flink 在 2022 年再创新高,月度峰值的下载量最高已经突破 1400 万次。
在整个 Flink 国际化生态不断繁荣发展的过程中,我们可以非常自豪的看到,中国开发者在里面承担了非常大的核心推动力。
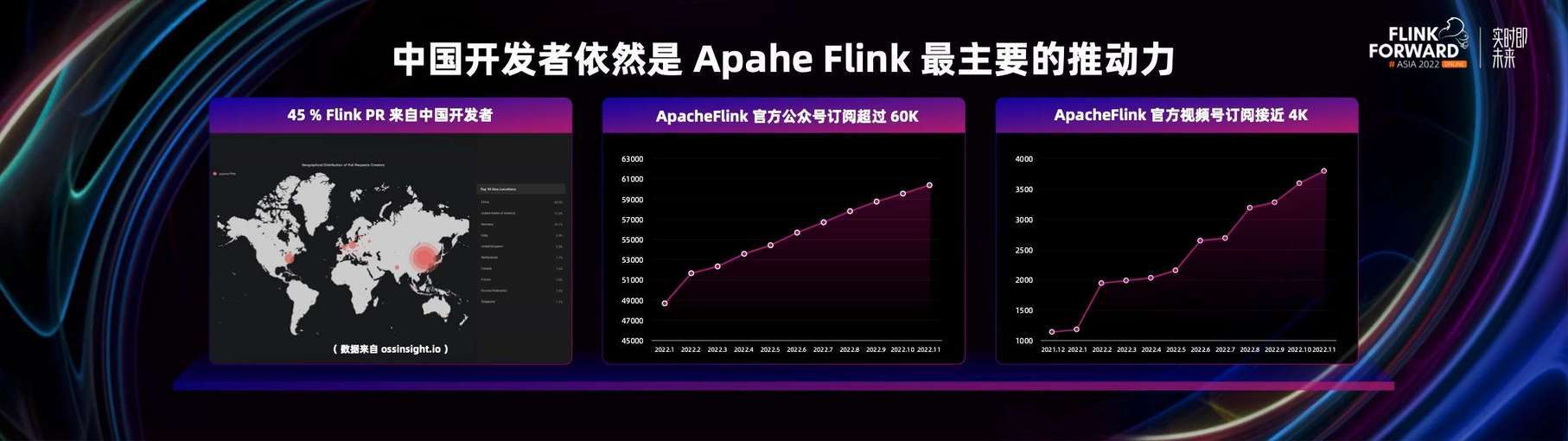
通过 OSS Insight 网站的数据统计可以看到,Flink 社区在 Github 上产生的 Pull Request 有 45% 是来自于中国的开发者。由此可见,整个社区的技术演进和技术开发的推动力主要都是由中国开发者带来的。
Apache Flink 中文社区这几年也在持续稳定的发展中。去年非常多国内的开发者在 Apache Flink 社区公众号上发布了文章,数量达 100 多篇。Apache Flink 社区公众号的订阅人数也已经超过了 60000 名。今年我们还推出了 Apache Flink 官方的视频号,目前订阅人数也已经将近 4000 名。
Flink 经过多年持续的健康发展,形成了一个繁荣的生态, 它的核心竞争力是什么呢?其实非常明确的可以看到,就是 Flink 的技术领先性,实时化的大数据计算能力。
Flink 社区最近几年其实也和其他的主流的开源社区和生态进行了合作,形成了一系列丰富多彩的实时化大数据场景解决方案,例如:
和 HBase 社区联合起来形成实时大屏分析的解决方案。
和一些生态数仓项目,比如 Hudi、Iceberg、ClickHouse、StarRocks、Doris、TiDB 等开源湖仓产品,形成全链路实时湖仓分析解决方案。
和主流的深度学习框架,比如 TensorFlow,PyTorch 项目进行联合使用,提供实时化、个性化推荐的解决方案。
和 Prometheus 形成实时监控报警的解决方案。

从以上内容我们可以看到,Flink 社区的心态是非常开放的,可以和很多主流的开源社区形成联合解决方案。让丰富多彩的实时化场景解决方案,推动各个行业大数据实时化技术的升级。
二、2022 数据实时化技术创新不止
接下来我将为大家介绍一下,2022 年中 Flink 社区在实时化技术路线上的一些重要技术成果和创新成果。
Apache Flink 社区在 2022 年发布了两个大的版本,Flink 1.15 和 Flink 1.16。在 1.15 中,Flink 解决了很多以前历史存在的一些难题,比如初步支持了跨版本流 SQL 作业升级,在 1.15 中可以检测到新老版本不兼容的情况并对用户进行提示,也可以去兼容老版本的 plan 进行升级。
此外 1.15 也解决了 Flink 在多 Source 对齐情况下的挑战。因为 Flink 的一个流任务可以有时候会有多个数据源或者日志流。不同的日志流的数据进展是不一样的,所以就有可能导致他们的数据进度差异较大。在 1.15 中提出了新的方案,更加方便的实现了多 Source 的 Watermark 对齐。
在 Flink 核心理念中,比如 Checkpoint 和 Savepoint 这两个概念用户就一直不是很清楚,经常会使用不当。因此在 1.15 中也对这两个概念重新进行了梳理和定义。同时也将 Checkpoint 和 Savepoint 进行存储格式的统一,让 Savepoint 也可以像 Checkpoint 一样高效的被使用。
此外对批处理技术也进行了更多的完善,包括批算子的自动并发设置,让批处理更加易用,流批一体更加实用。
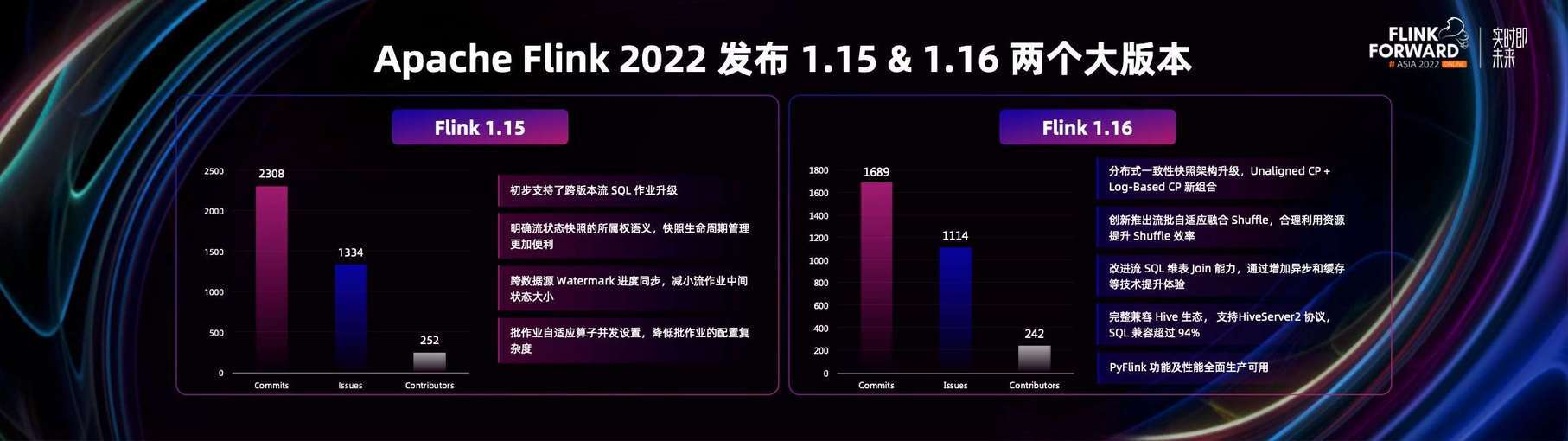
在 1.16 中,我们做了更多的技术创新和新的技术的尝试。比如我们对整个 Flink 分布式一致性快照技术架构,进行了很大程度的升级,落地了 Unaligned CP + Log-Based CP 新组合。在 Flink Streaming 方面引进了异步化的技术和缓存能力,使得 Streaming 维表 Join 有更强的能力。
在流批一体领域提出了流批自适应 Hybrid Shuffle,通过更加合理的利用集群资源,来提升网络 Shuffle 的性能。
在生态方面,对 Hive 生态进行了更好的兼容和拥抱。不仅能够无缝对接 Hive 的 HMS,也完全兼容了 HiveServer2 协议。在 Hive SQL 的兼容性上,Flink SQL 也达到了 94%以上的兼容度,也就是原来用户在 Hive 生态上写的 Hive SQL 绝大部分都可以不经过修改直接运行在 Flink 引擎之上,利用 Flink 实时化计算高性能的能力,去加速 Hive 离线数仓的性能。
在 Python API 方面,PyFlink 也得到了彻底的完善。在 1.16 中已经基本覆盖了所有 Flink 的关键算子。这样对 Python 程序员来说,也可以通过 Python 语言使用 Flink 所有特性了。
刚才介绍的 Flink 1.15 和 Flink 1.16 的诸多特性,也只是冰山一角。其实整个 1.15 和 1.16,还推出了非常多的特性和改进。接下来我会选择一些比较有代表性和创新性的技术点进行深度解读。
首先来看一下新一代分布式一致性快照的架构。我们知道分布式一致性快照技术在整个 Flink 社区里是非常核心的理念。Flink 作为一款有状态的流计算引擎,分布式快照是它的非常核心的特点。
比如 Flink 在不停做流计算的过程中,会定期 Take Snapshot 或者 Checkpoint 将流计算的状态进行持久化。就算流任务出现异常,它也可以从上一个临近的状态进行恢复,保证业务的连续性。因此 Flink 的用户都有一个天然的诉求,就是希望 Flink 的分布式一致性快照可以更加低成本、高频的做出来,从而让业务更加流畅。
但是在真实的生产环境中,尤其是大规模、复杂的生产环境中, 分布式一致性快照是面临非常多挑战的。尤其是在反压的情况下,挑战尤为突出。因为在反压的过程中,整个流计算的网络 buffer 会被打满,也就是网络拥塞。
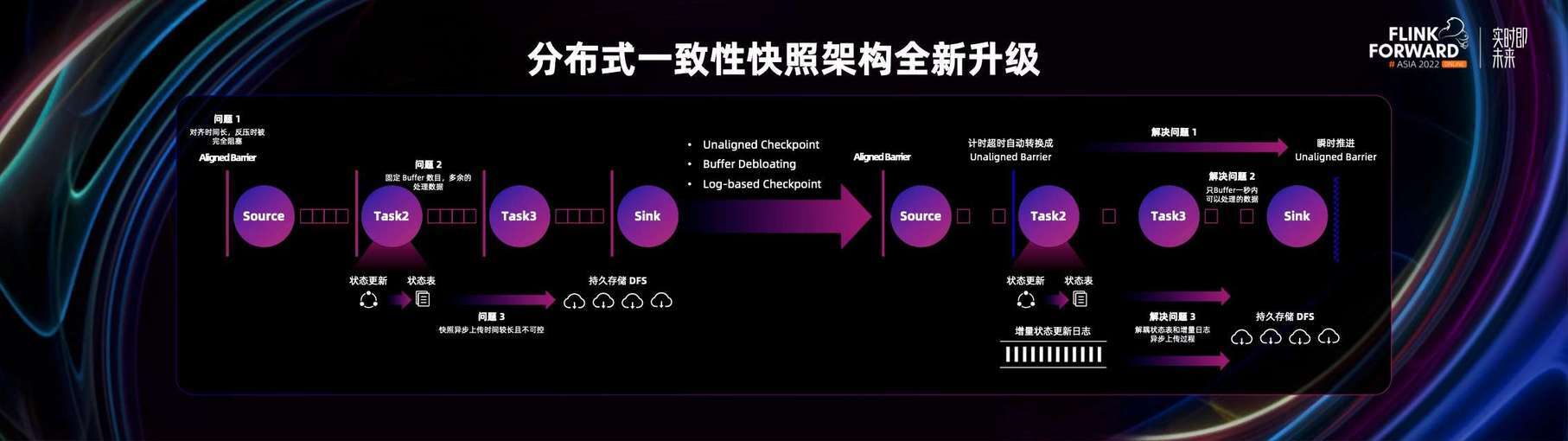
用来做 Checkpoint 的 Barrier 没有办法成功的在流里面传输,所以各个流计算的算子也没有办法收集到这些 Barrier,并且让 Barrier 对齐,也就没有办法触发 Checkpoint。即使能够触发 Checkpoint,在执行 Checkpoint 动作的时候,也需要把本地的状态数据上传到远程的云存储之上,数据量的大小也是不可控的。如果在状态数据的变化比较大的情况下,Checkpoint 依然会持续很久,并变得不可控。
所以 Flink 在最近几个版本中对整个分布式一致性快照架构做的很多的技术点的升级 。比如我们连续做了多个版本的 Unaligned Checkpoint,推出了 Buffer Debloating 技术。在 Flink 1.16 中落地了 Log-based Checkpoint 来做架构升级和改造。
通过 Buffer Debloating 可以让整个网络 buffer 使用更加高效;通过 Unaligned Checkpoint 去除对 Barrier 对齐的依赖;通过 Log-based Checkpoint 大幅降低执行 Checkpoint 的成本。
接下来分享一下 State 状态存储体系。在云原生时代,我们需要对 Flink 的状态存储体系进行了更大范围的升级。相信各个开源软件或者基础软件都需要去考虑如何去适应 Cloud Native 时代,如何去进行相应的升级和转型。
云原生时代给我们带来了的最明显的特点就是资源的弹性更强了,越来越 Serverless 了,这对 Flink 架构提出了更高的弹性扩缩容需求。Flink 作业的并发会随着资源弹性和业务负载不断改变,因此 Flink 的状态存储也需要进行相应的适配,即状态数据的分裂和合并。
如果状态存储根据并发的变化而进行分裂合并的性能变差,整个 Flink 的弹性扩缩容就会受到严重的影响。因此在 Flink 1.16 中,对 RocksDB State Backend 的状态重建算法进行了大量优化,使之有 2-10 倍的提升。
但这还不是我们的终极方案,后续 Flink 将会对整个状态存储管理体系进行更大的升级,变成一个彻底的存算分离架构来适应云原生环境。我们希望所有的状态数据全部都原生在 HDFS 或者云存储之上,本地磁盘和内存只是状态数据的缓存加速层,构建一套体系化的 Tiered State Backend 系统。

接下来分享一下流批一体上的技术创新。流批一体是 Flink 中一个非常有特色的技术理念,Shuffle 是整个分布式计算里非常核心的一个性能相关的技术。在 Flink 的 Shuffle 中,有两种经典的 Shuffle,分别是流式的 Pipeline Shuffle 和批式的 Blocking Shuffle。
流式的 Pipeline Shuffle 是任务的上下游,通过网络的方式直接连接进行数据传输。批式的 Blocking Shuffle 是上游将中间数据写到磁盘或者存储服务上,下游通过磁盘或者存储服务下载中间数据。因此在常规的理念中,流执行模式都会用流式 Shuffle,批任务都会用批式 Shuffle。
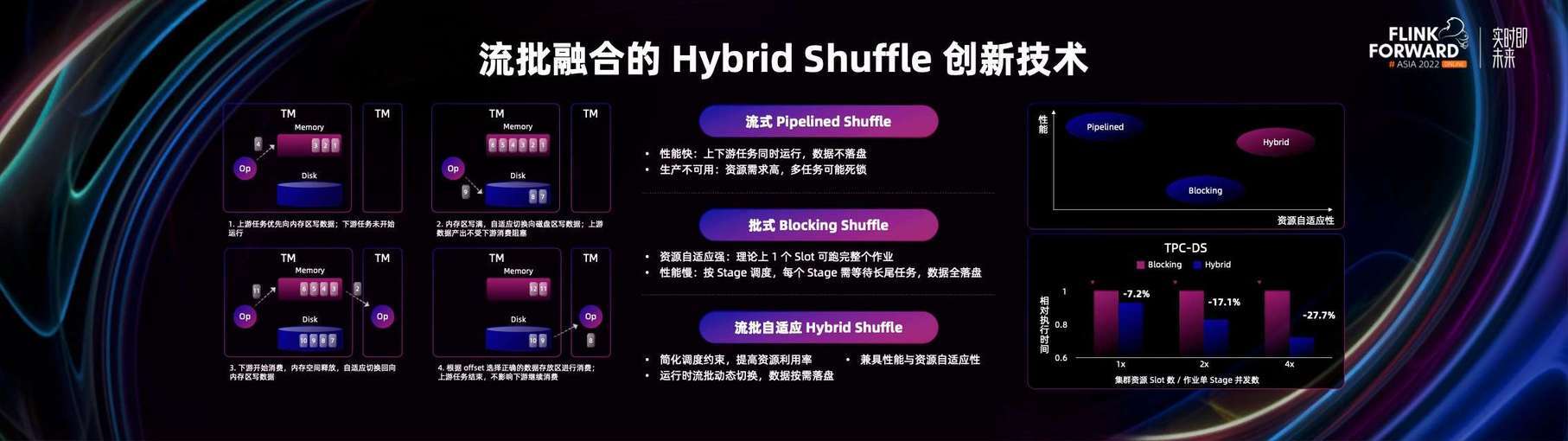
但我们也可以明显的看出,流式 Shuffle 的性能比较高,因为它不经过磁盘 Io,而批式 Shuffle 经过一次磁盘 Io 性能会更差一点。所以我们能不能将流式 Shuffle 也应用在批执行模式或者批任务场景下,加速批式 Shuffle 呢?
从技术本身来说是可以的,但在真正生产环境下执行的时候,会发现有一个很大的约束或者不确定性。因为流式 Shuffle 有个前提条件是,上下游或者说一个联通的连通图需要同时拉起。但这就需要更多的资源,而真正在生产环境下是否能有这么多资源是不可保证的,所以就可能有死锁的情况发生。
因此是否可以在资源相对充足的情况下,把连通图一起拉起进行流式 Shuffle 加速。而资源不够的情况下,退回到经典的批式 Blocking Shuffle,这样就可以合理的利用资源来进行 Shuffle 加速了。答案肯定是可以的。这也是在 1.16 中推出 Hybrid Shuffle 的背景和思路起因。
接下来分享一下最近一两年新提出的概念 Flink CDC,即基于 Flink 的全增量一体数据同步技术。首先介绍一下做 Flink CDC 的原因。
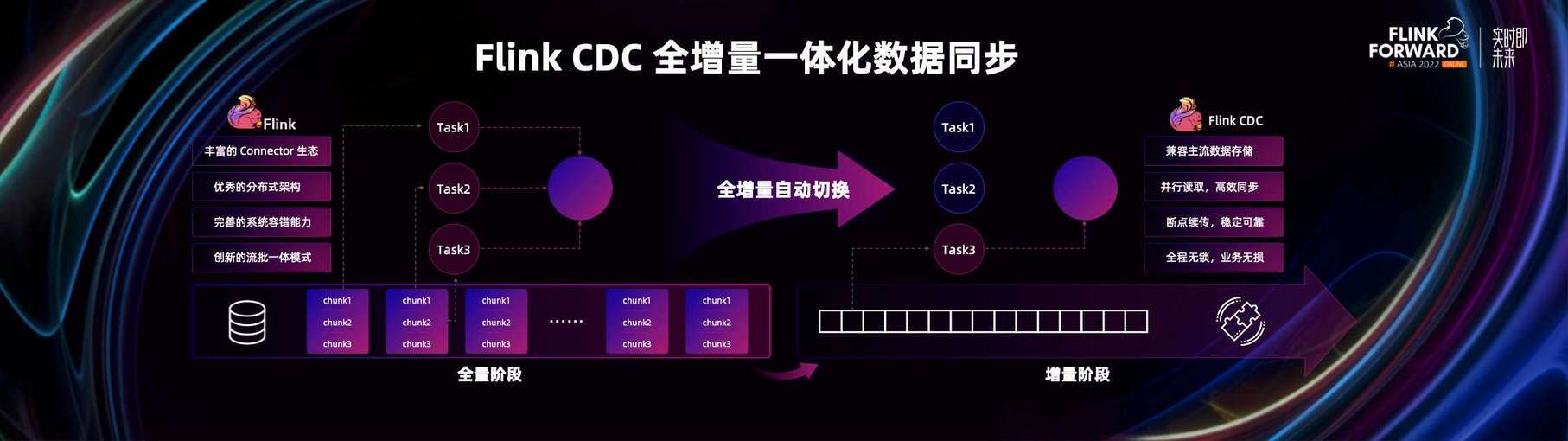
Flink 本质上是一款流式的分布式执行引擎或者计算引擎,它在大家心目中已经是连接各种不同存储的数据管道或者数据通道了。Flink 本身具有非常多的技术特色,比如有丰富的 Connector 生态,能够连接各种各样的主流存储系统;有优秀的分布式架构,包括支持 Checkpoint 机制,流批融合机制。这些都是一款全增量一体数据集成引擎所需要的特性。所以我们认为,在 Flink 的肩膀上去构建一款全增量数据同步引擎是特别容易成功的,因此就启动了 Flink CDC 项目。
其实在去年 Flink-CDC 1.0 的试水中,整个开发者生态对它都是一个非常正向的反馈。所以今年加大了对 Flink CDC 的投入,推出了更加完善和成熟的 Flink CDC 2.0 大版本和框架。在 2.0 中,我们抽象出了通用的增量快照一致性读取算法。有了它之后,就可以降低接入数据源的成本,加速接入更多的数据源。
同时结合整个分布式框架的诸多优势,Flink CDC 已经具备了非常强的能力。比如支持高性能的并行读取,借助 Flink Checkpoint 优势,实现数据断点续传。并通过增量一致性快照读取算法,可以全程对数据库无锁,这样我们在整个全增量一体数据同步的过程中不会对在线业务有任何的影响。
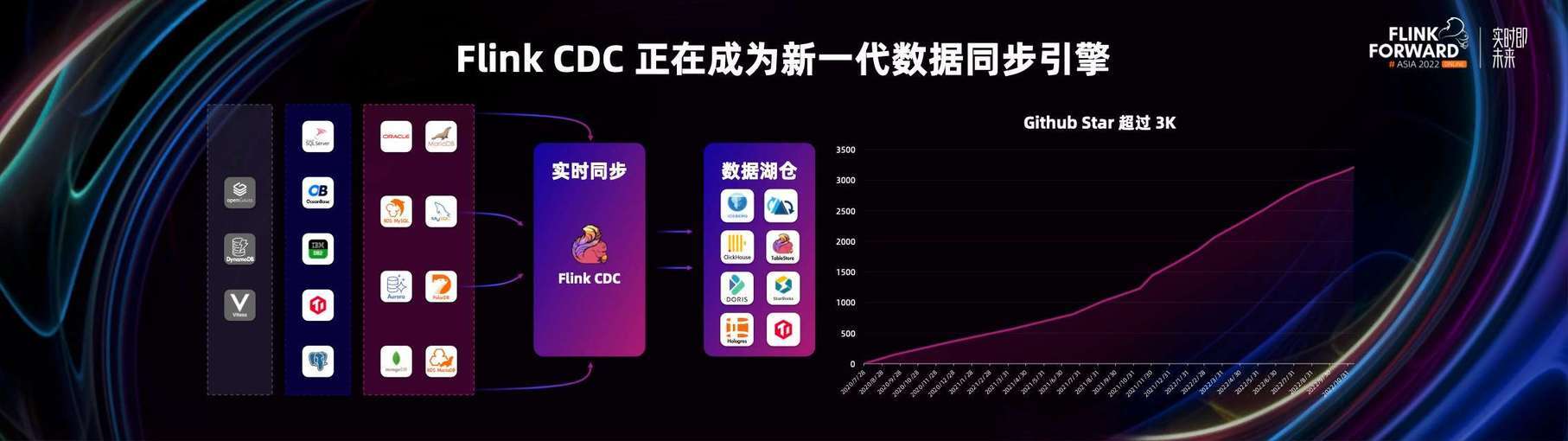
从下图中可以看到,Flink-CDC 2.0 已经接入了很多主流的数据源,比如 MySQL 家族,PolarDB,Oracle,MariaDB 等,接入中有 PG,TiDB 和 Ocean Base 等,相信日后会有更多的数据源接入到 Flink CDC 数据同步框架中。
在最后一项技术创新中,我分享一下 Flink 在机器学习场景中的子项目 - Flink ML 2.0。大家都知道在老版的 Flink 中有一个模块叫 Flink ML,即 Flink 机器学习算法库。老的 Flink ML 模块是基于 Flink DataSet API 来构建的,但 DataSet API 已经被废弃了。在最近几个版本中,Flink 已经将基础的 API 层全部统一到流批一体的 DataStream API 之上,不再使用 DataSet,所以老版 Flink ML 也相当于被废弃了。
去年其实已经预告了要重新建设 Flink ML 成为一个新的 Flink 子项目。今年我们通过努力已经将这件事进行了从 0-1 的孵化和落地,并发布了两个版本,第三个版本也在进行之中。
我们都知道机器学习的算法库,它的运算核心是迭代计算框架,因此我们在 Flink ML 2.0 项目中,基于 Flink Data Stream 流批一体的 API,重建了一套流批一体的迭代计算框架。它不仅支持传统的同步迭代训练,也支持异步的迭代训练模型。
Flink 不只支持有限数据集的训练,也支持无限流数据集上的在线迭代训练。同时借助 Flink Checkpoint 分布式框架的优势,也支持整个分布式训练断点的异常恢复。这对一些需要长时间运行的训练任务还是有很好的生产意义的。

经过一年的努力,在社区版已经对 Flink ML 的算法进行了第一步的完善。阿里云实时计算和机器学习团队共同贡献了 30 多个经典的机器学习算法,覆盖了常见的特征工程场景,明年将会完成所有主流经典 ML 算法库的完善。
三、Streaming Data Warehouse
Flink 下一步核心演进的方向是 Streaming Data Warehouse。在这之前,为了更好理解,先来回顾一下历史上核心理念的演进的过程。
Flink 在诞生的时候,它为什么能击败了上一代流式计算引擎 Storm,受到开发者的青睐,成为新的一代流计算的计算引擎的呢?我觉得关键的核心点是 Flink 是一款有状态的流计算,而 Storm 是一个无状态的流计算引擎。

Flink 将 Streaming 计算和状态存储进行有机融合,这样就可以在框架层支持整个流计算状态的精准数据一致性。不仅保持低延迟、高吞吐的流计算能力,还保证了数据一致性,而且是在框架层面保持的,这是 Storm 做不到的。所以 Flink 凭借技术架构上的创新成为了新一代流计算的霸主。
但在 Flink 诞生之后的几年,就遇到了一个瓶颈,推广门槛过高。因为大家在早期开发 Flink 的时候,都要写 Java 程序,通过 DataStream 的 API 写 Java 代码,这对很多数据分析师来说门槛还是很高的。因为在整个数据分析师的世界里,标准的语言是 SQL,这也是 Flink 很难推广的一个原因。
2019 年,阿里巴巴将自己内部积累的 Blink SQL 贡献给了 Flink 社区,从此 Flink 社区也有了一套非常易用的 Stream SQL。有了 SQL 后大幅降低了开发门槛,所以之后 Flink 的应用得到了爆炸式的增长,这也是为什么大家看到最近这两三年 Flink 出现了一个加速普及的过程。
但是 SQL 只能够解决计算层的一些体验问题。即使 Flink 具备流批一体 SQL 的能力,能够实现全量增量开发一体化的体验,但它依然没有办法解决存储层割裂的问题。
下一阶段 Flink 社区新的机会点就是继续提升一体化的体验,来实现一套实时数据链路。因此我们可以通过 Flink 的流批一体的 SQL 和流批一体的存储,构建一套真正一体化体验的流式数仓- Streaming Data Warehouse。
在 Streaming Data Warehouse 新的理念和形态中,可以保证所有的数据端到端都可以实时流动;整个全链路的开发过程中,用户都可以有全增量一体化的开发体验,并且有统一的数据存储和管理体系。
因此如果要去做下一代的 Streaming Data Warehouse 架构。第一步要完善的就是流批一体存储。目前在开源生态中还没有一款真正能够实现,高性能流读流写、批读批写的流批一体存储。
因此 Flink 社区去年推出了全新子项目 Table Store,它的定位就是实现流批一体的存储能力。它的特点是能实现高性能的流读流写、批读批写,所以我们把 Table Store 的数据表称为动态表。
Table Store 的设计完全遵循现在新一代存算分离的理念,可以把数据存储在 HDFS 或者主流云存储上。它的核心存储格式是由 Lake Store 和 Log Store 两部分组成。
在 Lake Store 中,应用了很多经典的数据结构,比如 LSM 和 ORC,以及一系列索引技术。LSM 技术比较适合大规模数据更新,ORC 的列存技术配合一些索引,适合高性能的数据读取。在 Log Store 中,提供了完整 CDC 语义的 Changelog,这样配合 Flink 的 SQL 就可以增量订阅 Table Store,进行流式的数据分析了。
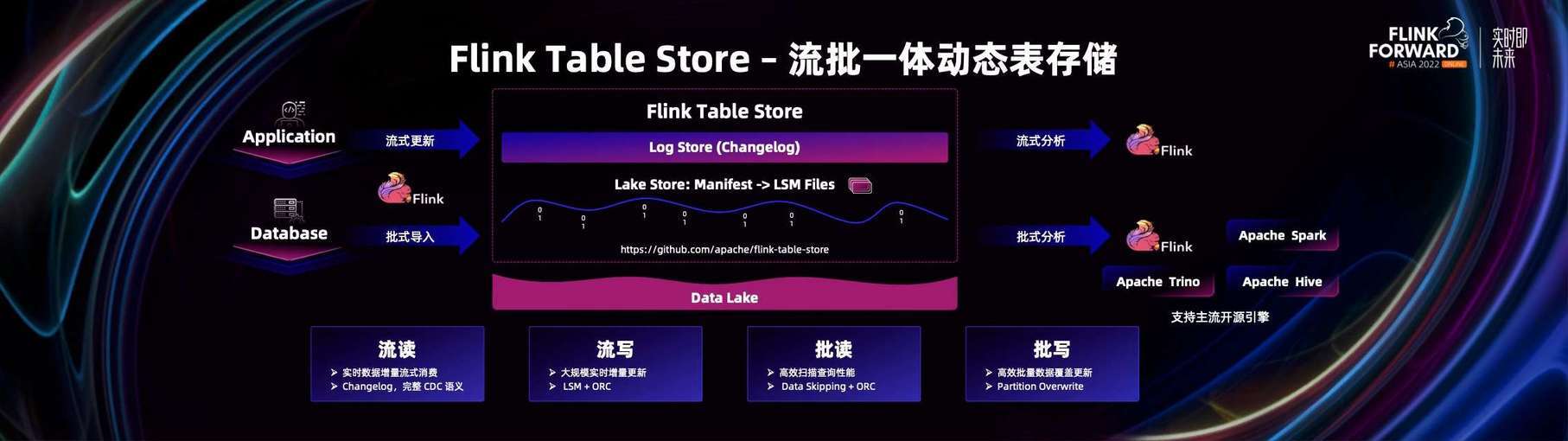
整个 Table Store 的数据体系是完全开放的,它除了可以默认对接 Flink 之外,它也能对接 Spark、Hive、Trino 等这些主流的开源计算引擎。
Table Store 在 Flink 社区已经发布了两个版本,0.1 和 0.2。目前除了阿里巴巴以外,字节跳动等一些公司也参与了项目的共建。接下来看一下经过两个版本发布,Table Store 在真正场景下的流读、流写、批读、批写的性能怎么样。我们做了一个性能测试,将 Table Store 和目前最主流的数据湖存储 Hudi 进行了对比。

整个性能测试的业务场景来自经典的 TPC-H,利用 TPC-H 的工具产生 6000 万条订单数据,写入到 MySQL 的订单表中,模拟一个真实的业务行为。然后利用 Flink CDC 做数据同步,将 MySQL 的数据同步到数据湖仓表中。一条链路将它写入到 Apache Hudi 里,一条链路写入到 Table Store。然后去测试、对比一下,两个不同技术数据更新的性能差异,同时我们再用 Flink SQL 对这两张数据表进行查询。
在测试结果中,我们可以看到 Table Store 的更新性能非常优秀,明显领先了 Hudi 的更新能力。在数据查询的性能上明显领先了 Hudi 的 MOR 模式,比较接近 COW 模式,综合性能上可以看出 Table Store 流批一体的读写性能还是非常优秀的。
四、流式数仓 Demo
为了让大家更好的理解 Streaming Data Warehouse 这个新理念,制作了一个 demo 供大家观看。
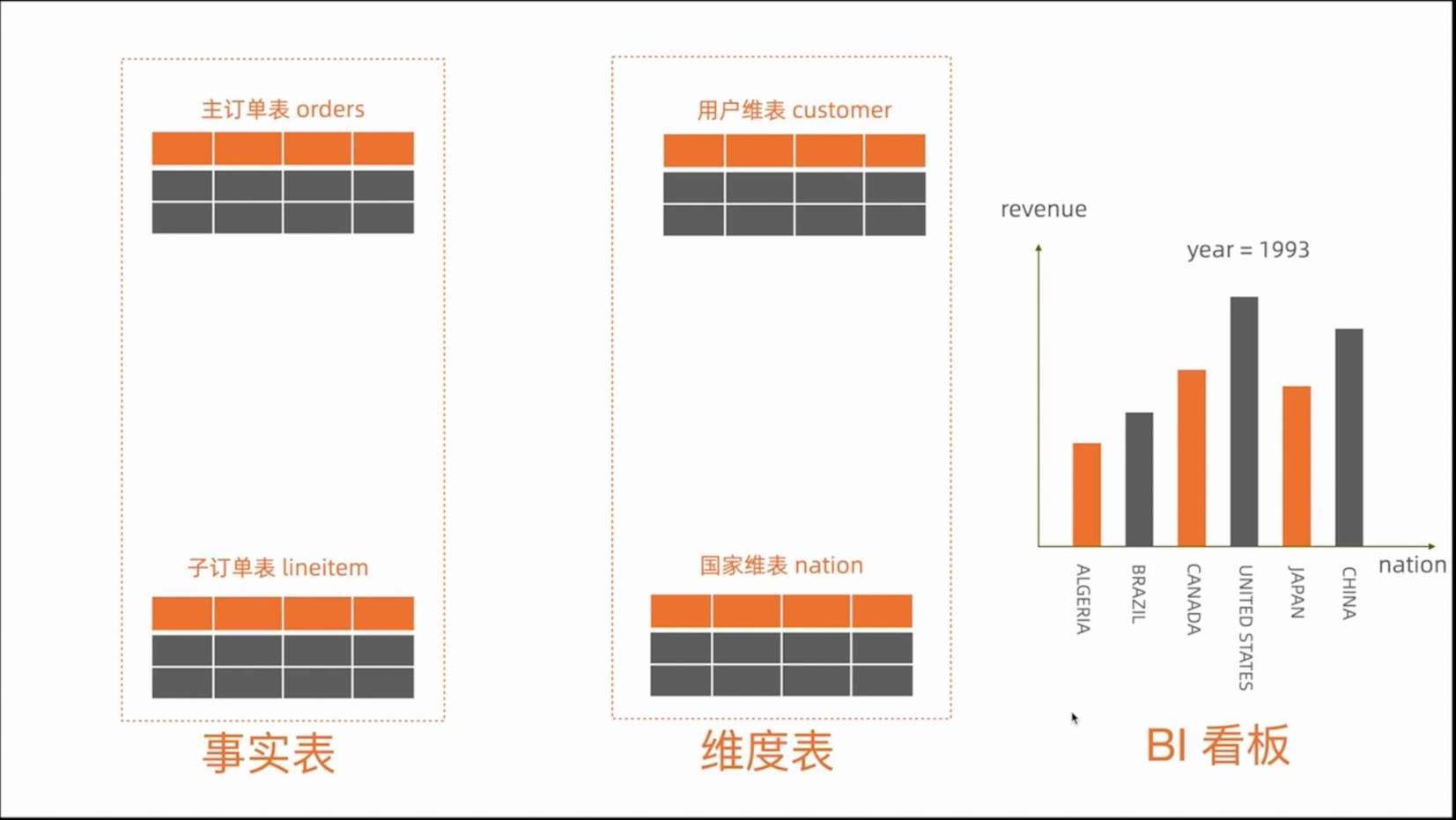
首先通过 Flink SQL 实时同步到 Table Store,然后构建 ODS, DWD,ADS 层。数据及元数据存储在云上 OSS。demo 使用 TPC-H 数据集,包含两张事实表,主订单 orders,子订单 lineitem,和两张维度表,分别是用户维表 customer、国家维表 nation。
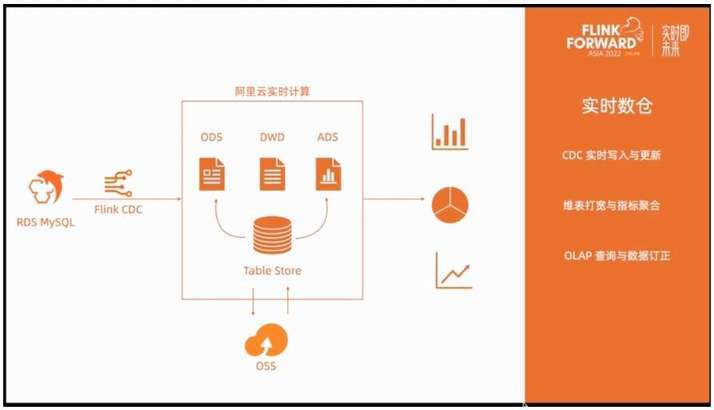
主订单表关联用户维表可以得到用户所在国家标识,关联子订单表可以得到订单价格,关联国家维表可得到国家字段。被打宽后的明细表,按年和国家进行聚合即可得到年度国家 GMV 分布。
首先创建 MySQL 数据库到 Table Store 的同步任务。第一张是订单明细表 line item。在 Table Store 中,为了更好的区分不同数据层,我们给它加上 ods 前缀。在 with 参数中,我们指定了表的 OSS 存储地址,并设置 auto-create 属性为 true,即自动创建当前表的所在目录。

类似的方式声明其余三张表的 DDL,将主订单表、用户维表、国家维表进行同步。在提交任务时,我们使用 statement set 语法,将四张表放在一个任务里进行同步。下面我们开始操作;
从模板中心创建同步任务,点击提交准备上线作业。
切换到运维界面,准备启动。
在同步任务启动后,我们可以开始生成订单明细数据,接下来的动画会演示生成明细数据的过程。
首先使用主订单中的 o_orderkey 关联子订单中的 l_orderkey,可以看到主订单中只有 o_orderkey 等于 1 的记录,满足等值条件。
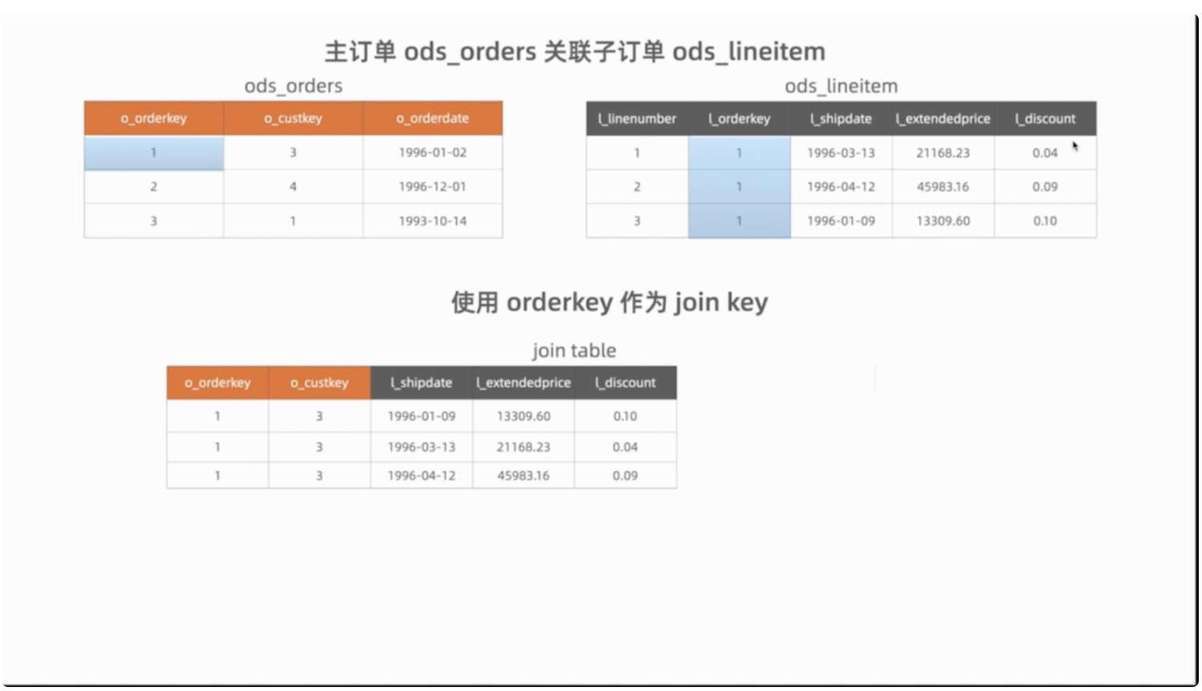
这里使用 interval join 让主订单表的下单日期 o_order_date 与子订单表的发货日期 l_shipdate 在 14 天内,可以看到子订单表中只有一条记录满足 interval 条件。

同时我们用子订单中的金额字段和折扣字段计算出 GMV 字段 l_revenue。

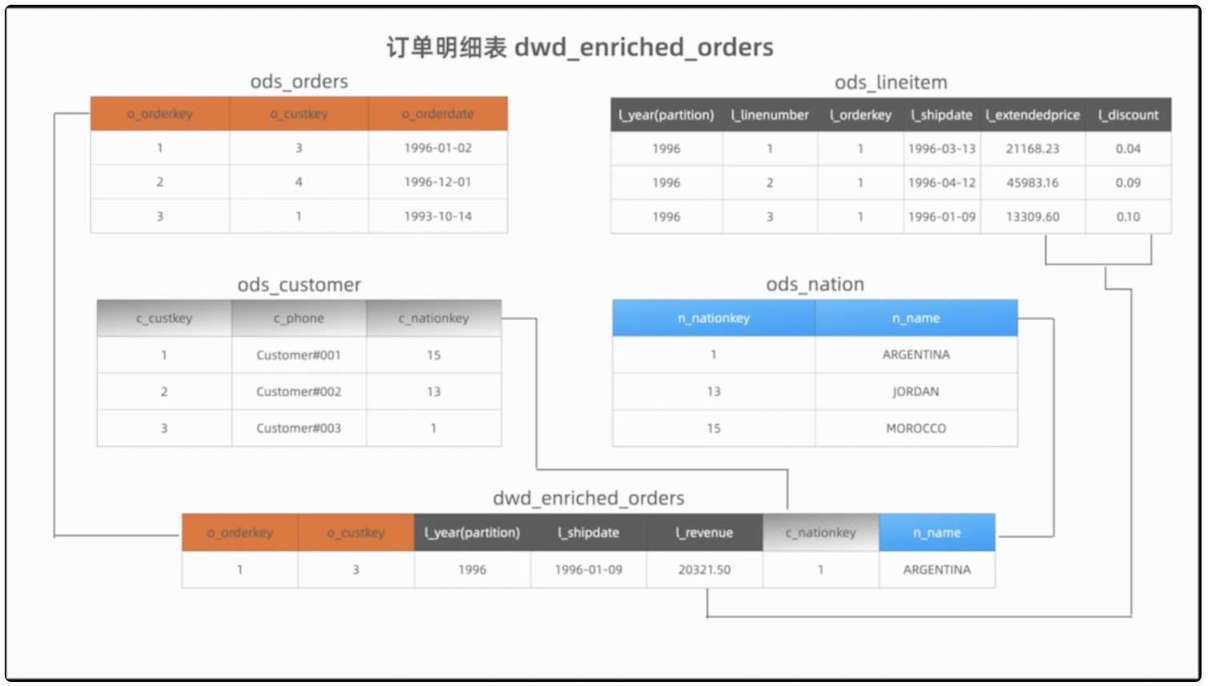
紧接着,我们使用 customer key 与用户维表进行 look up join,得到了用户所在国家的标识 c_nation_key。

最后我们与国家维表进行关联,得到了用户所在国家字段。

通过一次 interval join 和两次 look up join 订单明细表就构建完成了。
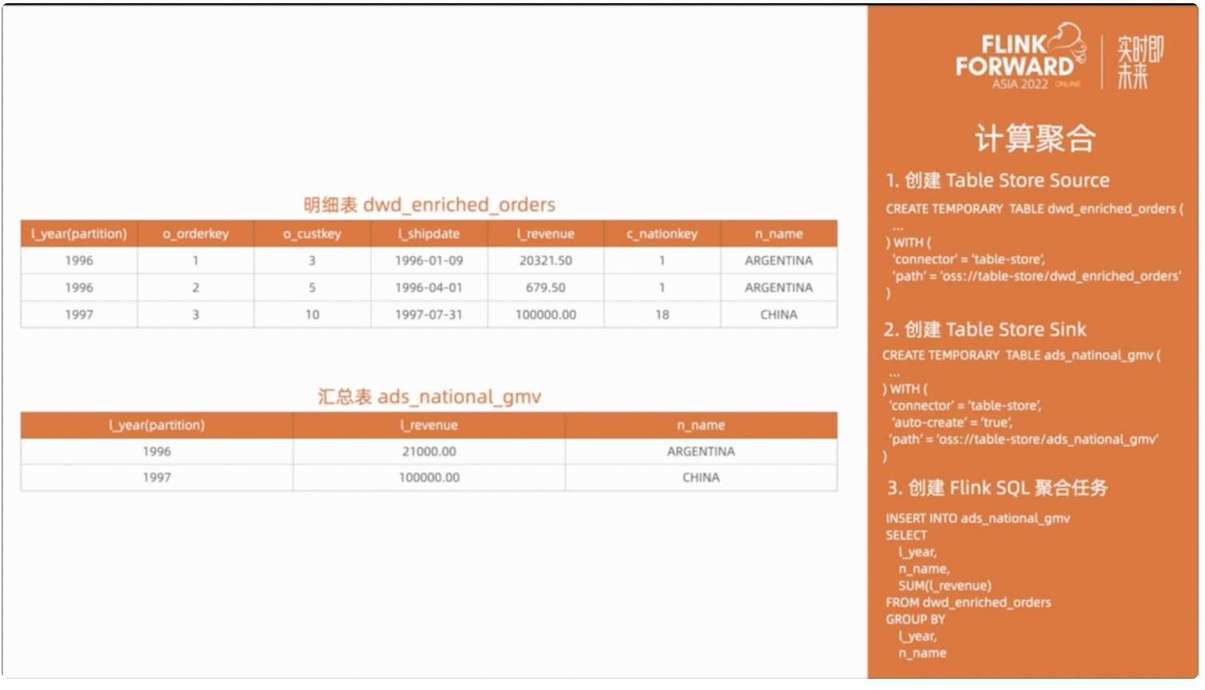
接下来我们就可以对明细表按年和国家进行汇总,计算出 GMV 金额。我们同样使用 statement set 语法将明细层和汇总层的计算放在同一个任务里。
下面开始生成作业:点击提交,准备上线作业。
切换到运维界面准备启动。
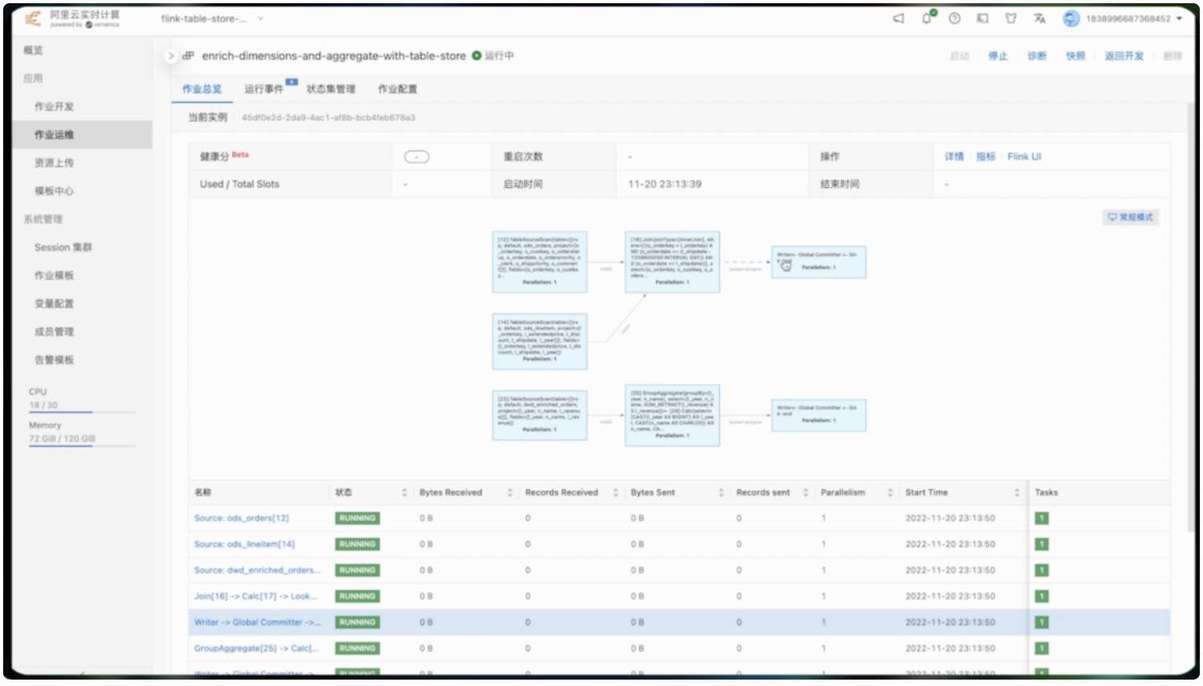
现在所有任务都在运行中,我们创建临时查询来预览汇总表的数据。随机选取 1993 年,各个国家的 GMV 数据已经展示出来了。
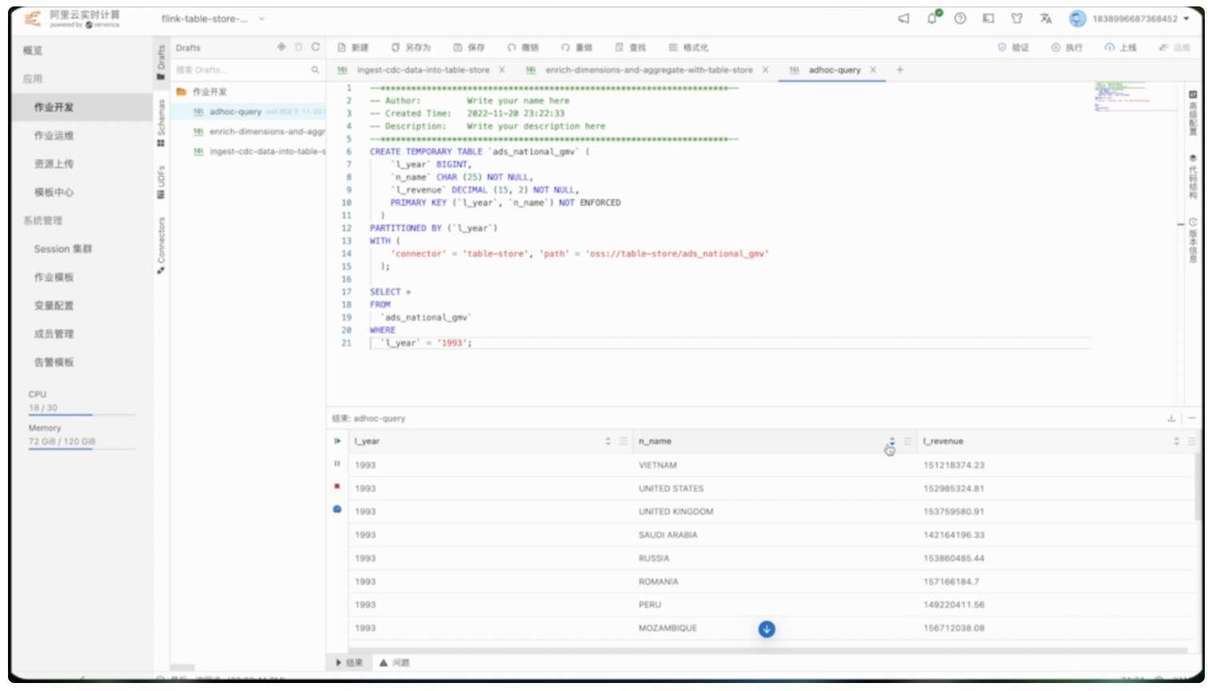
在上一步中,我们已经计算并查询了汇总之后的国家 GMV 数据。假设我们接到一个新的需求,要将国家维表中的国家字段从英文转换为中文,进行数据订正。此时我们可以创建 batch 作业,对维表和它所产生的下游表进行 overwrite。

从模板中心创建为表订正任务。点击提交准备上线作业,切换到运维界面准备启动。
等待作业启动并执行完毕后,按照同样方式对 DWD 和 ADS 表进行 overwrite。在上游数据订正任务都执行完成后,我们重新查询汇总表的数据,可以看出在订正后汇总表的国家已经转化为中文。
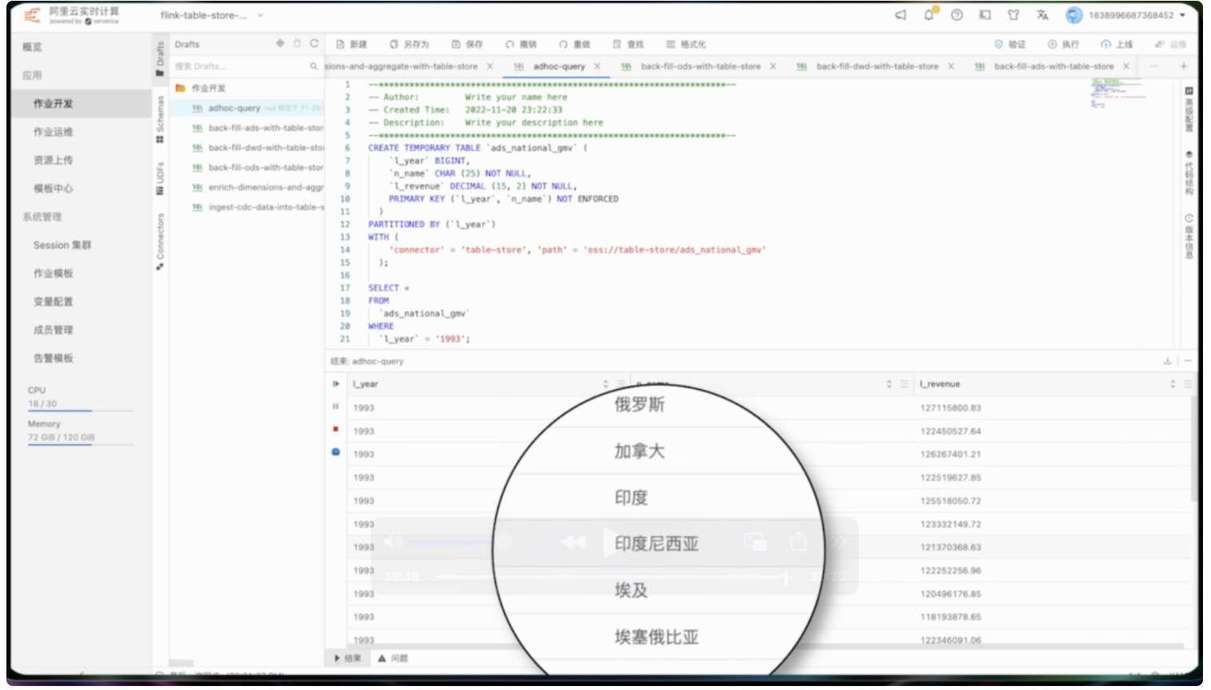
以上就是本次 demo 的全部内容。
更多内容
本届 Flink Forward Asia 更多精彩内容,可点击阅读原文或扫描图片二维码观看全部议题的视频回放及获取 FFA 2022 峰会资料!

PC 端观看:https://flink-forward.org.cn/ 「建议前往 FFA 2022 大会官网观看全部议题的视频回放」

活动推荐
阿里云基于 Apache Flink 构建的企业级产品-实时计算 Flink 版现开启活动:99 元试用 实时计算Flink版(包年包月、10CU)即有机会获得 Flink 独家定制卫衣;另包 3 个月及以上还有 85 折优惠!了解活动详情:https://www.aliyun.com/product/bigdata/sc


Apache Flink 中文社区 2020-04-29 加入
官方微信号:Ververica2019 微信公众号:Apache Flink 微信视频号:ApacheFlink Apache Flink 学习网站:https://flink-learning.org.cn/ Apache Flink 官方帐号,Flink PMC 维护









评论