
深入理解 Python 多进程:从基础到实战
引言
在 Python 编程中,多进程是一种重要的并发编程方式,可以让我们充分利用多核处理器的计算能力,实现并行处理任务,提高程序的运行效率。与多线程相比,多进程具有独立的内存空间,避免了全局解释器锁(GIL)的影响,因此更适合于 CPU 密集型的任务。
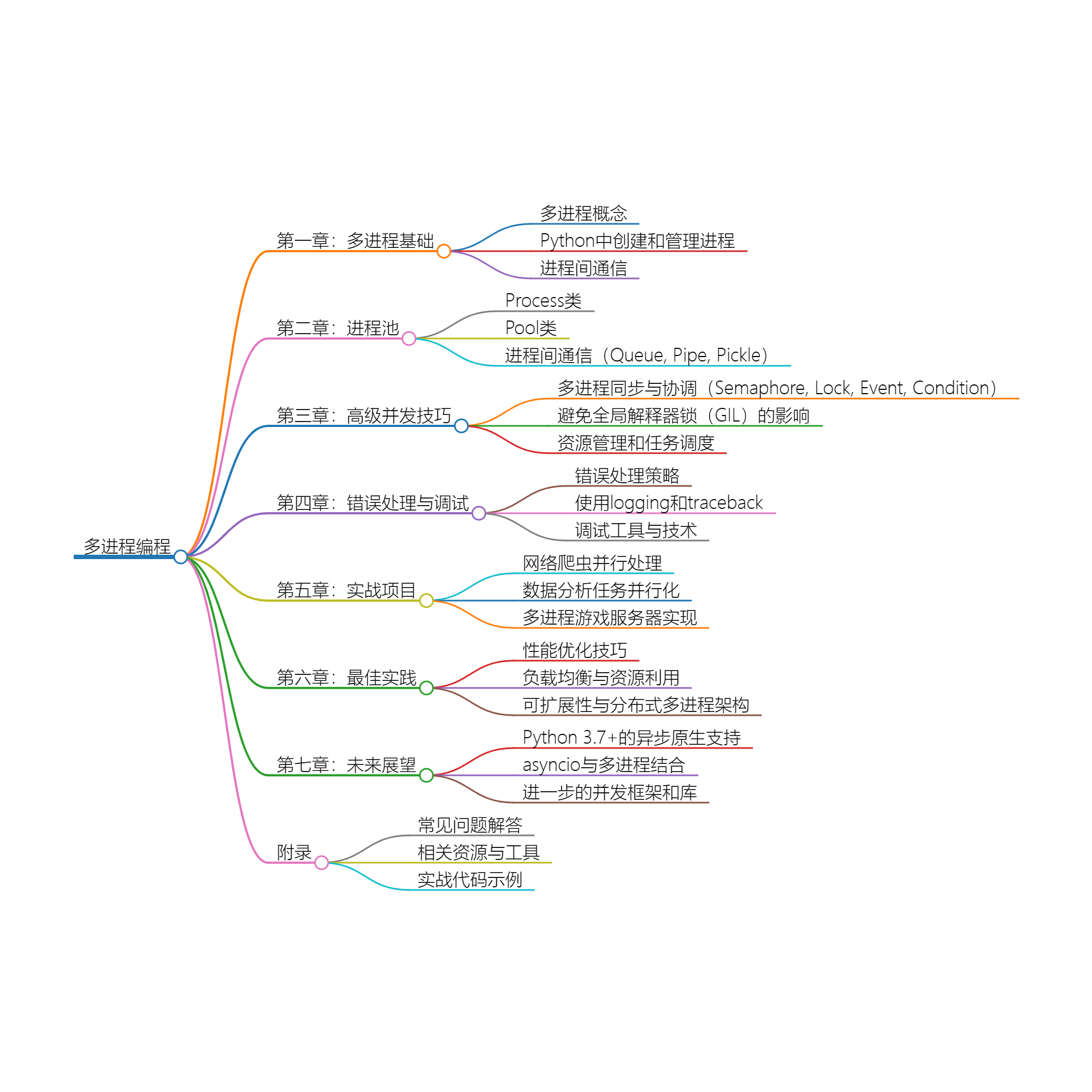
Python 多进程基础
在 Python 中,可以使用multiprocessing模块来创建和管理进程。通过Process类可以创建新的进程,通过Pool类可以创建进程池,实现并行处理任务。多进程之间可以通过队列(Queue)、管道(Pipe)等方式进行通信,从而实现数据共享和协作。
为什么选择多进程
充分利用多核处理器:多进程可以同时利用多个 CPU 核心,实现并行处理,加快任务执行速度。
避免 GIL 的影响:Python 的全局解释器锁(GIL)限制了多线程并发执行时的效率,而多进程避免了这一限制,可以更好地利用多核处理器。
提高程序稳定性:由于多进程拥有独立的内存空间,进程之间互不影响,因此在处理一些需要隔离环境的任务时更加稳定可靠。
适用于 CPU 密集型任务:对于需要大量计算的任务,多进程能够更好地利用计算资源,提高程序的执行效率。
总之,选择多进程可以让我们更好地利用计算资源,提高程序的运行效率,同时避免了一些多线程并发编程中的问题,是一种值得掌握的并发编程方式。
第一章:Python 进程与线程
进程与线程概念介绍
进程:进程是程序的一次执行过程,是系统资源分配的基本单位。每个进程都有自己独立的内存空间,包括代码段、数据段、堆栈等。进程之间相互独立,通信需要特殊手段。
线程:线程是进程中的一个执行流,是 CPU 调度的基本单位。同一进程内的线程共享相同的内存空间,包括代码段、数据段等。线程之间可以直接访问共享的内存,通信更方便。
Python 中的进程模型
在 Python 中,可以使用multiprocessing模块来创建和管理进程。通过Process类可以创建新的进程,实现并行处理任务。每个 Python 进程都有自己独立的解释器和内存空间,进程之间数据不共享,需要通过特定方式进行通信。
线程与进程的区别
资源占用:线程比进程轻量,创建和销毁线程的开销小,占用的资源少。进程拥有独立的内存空间,资源消耗较大。
通信方式:线程之间共享同一进程的内存空间,可以直接访问共享数据,通信更方便。进程之间通信需要特殊手段,如队列、管道等。
并发性:多线程可以实现并发执行,但受全局解释器锁(GIL)限制,无法利用多核处理器。多进程可以充分利用多核处理器,实现真正的并行处理。
稳定性:由于线程共享内存,线程之间的错误可能会影响整个进程。而进程之间相互独立,一个进程崩溃不会影响其他进程。
适用场景:线程适合 I/O 密集型任务,如网络请求、文件操作等;进程适合 CPU 密集型任务,如大量计算、图像处理等。
总之,线程适合处理需要频繁 I/O 操作的任务,进程适合处理需要大量计算的任务。在 Python 中,多线程受到全局解释器锁的限制,多进程能更好地利用多核处理器,选择合适的并发编程方式可以提高程序的运行效率。
第二章:Python 内置的 multiprocessing 模块
multiprocessing 模块介绍
multiprocessing是 Python 中用于支持多进程编程的内置模块,可以实现并行处理任务,充分利用多核处理器。
Process 类和 Pool 类详解
Process 类:
multiprocessing.Process类用于创建新的进程。通过实例化Process类并传入要执行的函数,可以创建一个新的进程。调用start()方法启动进程,调用join()方法等待进程结束。每个Process实例都有自己独立的内存空间。
Pool 类:
multiprocessing.Pool类用于创建进程池,可以方便地管理多个进程。通过Pool类的map()、apply()等方法,可以将任务分配给进程池中的多个进程并行执行。进程池会自动管理进程的创建和销毁,提高了并行处理的效率。
进程间通信(Queue, Pipe, Pickle 等)
Queue:
multiprocessing.Queue类提供了进程间通信的队列。多个进程可以通过共享的队列进行数据交换,实现进程间的通信。队列是线程/进程安全的,可以在多个进程之间安全地传递数据。
Pipe:
multiprocessing.Pipe类提供了进程间通信的管道。管道包含两个连接,每个连接对应一个进程,可以双向传递数据。通过Pipe可以实现两个进程之间的通信。
Pickle:
pickle模块用于序列化和反序列化 Python 对象,可以将对象转换为字节流进行传输。在进程间通信中,可以使用pickle将对象序列化后传输,再在另一端反序列化得到原始对象。
通过使用multiprocessing模块提供的Process类、Pool类以及进程间通信的机制,可以方便地实现并行处理任务,并实现不同进程之间的数据交换和通信,从而提高程序的运行效率和灵活性。
第三章:进程池与异步编程
Pool 类的使用与优化
使用:
multiprocessing.Pool的主要用法是通过apply()、map()、starmap()等方法将任务提交给进程池,然后通过Pool的close()和join()方法关闭和等待所有进程完成。例如:
优化:为了提高效率,可以考虑以下几点:
适当设置进程数:根据机器的核数和任务的特性,设置合适的进程数,避免过多的进程导致上下文切换开销。
避免频繁的进程间通信:尽量减少进程间的通信,例如,如果任务可以并行处理,尽量一次性提交大量任务。
多进程中的异步 I/O 处理
在多进程环境中,
multiprocessing模块本身并不直接支持异步 I/O,因为 I/O 操作通常是阻塞的。然而,可以结合其他库(如asyncio或concurrent.futures)来实现异步 I/O。例如,concurrent.futures提供了ThreadPoolExecutor和ProcessPoolExecutor,它们可以配合asyncio的run_in_executor()方法实现异步 I/O。
使用
concurrent.futures:
这里,ThreadPoolExecutor用于管理线程,as_completed()用于异步等待所有任务完成。这样,尽管 I/O 操作是异步的,但整个进程池的其他任务仍可以并行执行。
concurrent.futures 模块的使用
concurrent.futures提供了更简洁的接口,它抽象了底层的线程池或进程池,使得异步编程更加方便。ProcessPoolExecutor和ThreadPoolExecutor是两个主要的类,它们都支持submit()方法提交任务,然后你可以通过as_completed()或result()等方法获取结果。与multiprocessing.Pool相比,concurrent.futures更加面向异步编程,更适合现代 Python 应用。
第四章:高级并发技巧
这一章将深入探讨 Python 中进行多进程同步与协调的高级技巧,以及如何避免全局解释器锁(GIL)的影响,还有资源管理和任务调度。
多进程同步与协调(Semaphore, Lock, Event, Condition)
Semaphore(信号量) :用于限制可以同时访问某个资源的进程数。在进程间同步对共享资源的访问非常有用。
Lock(互斥锁) :用于确保一次只有一个进程可以访问共享资源。
Event(事件) :用于在进程间同步操作,一个进程可以设置或等待事件。
Condition(条件变量) :与 Lock 类似,但允许进程在某些条件下等待或通知其他进程。
避免全局解释器锁(GIL)的影响
GIL 是 CPython 中的一个机制,它确保同一时间只有一个线程在执行 Python 字节码。为了绕过 GIL,可以使用以下方法:
使用多进程而不是多线程,因为每个 Python 进程都有自己的 GIL。
使用 Jython 或 IronPython,这些 Python 实现没有 GIL。
使用 C 扩展来执行计算密集型任务,这些扩展可以在没有 GIL 的情况下运行。
资源管理和任务调度
资源管理:使用上下文管理器(如
with语句)确保资源如文件和网络连接被正确关闭。对于进程和线程,确保使用Pool和Executor的上下文管理器来关闭和等待所有任务完成。任务调度:可以使用队列(如
multiprocessing.Queue)来调度任务,其中生产者进程将任务放入队列,消费者进程从队列中取出任务并执行。
通过这些高级技巧,你可以更有效地管理并发任务,提高应用程序的性能和稳定性。
第五章:进程间的错误处理与调试
在这一章中,我们将讨论进程间的错误处理与调试,包括错误处理策略、使用 logging 和 traceback 进行错误处理,以及调试工具与技术。
错误处理策略
在多进程编程中,错误处理非常重要,因为一个进程的错误可能会影响其他进程甚至整个应用程序。以下是一些错误处理策略:
进程间通信异常处理:在进程间通信时,要捕获并处理异常,以避免进程崩溃。可以在进程间通信的代码块中使用 try-except 语句来捕获异常。
进程池异常处理:如果使用进程池(如
multiprocessing.Pool),要注意捕获并处理子进程中抛出的异常,以避免整个进程池被终止。日志记录:及时记录错误和异常信息到日志文件中,以便后续排查问题。
使用 logging 和 traceback
logging 模块:Python 的 logging 模块提供了灵活且强大的日志记录功能,可以用于记录程序运行时的信息、警告和错误。在多进程环境中,可以使用 logging 模块将日志信息写入文件或控制台,以便进行错误排查。
traceback 模块:Python 的 traceback 模块可以用于获取异常的堆栈信息,帮助定位错误发生的位置。
调试工具与技术
pdb 调试器:Python 自带的调试器 pdb 可以用于在程序中设置断点、查看变量值、逐行执行代码等操作,帮助排查问题。
PyCharm 等集成开发环境:使用集成开发环境如 PyCharm 可以更方便地进行调试,提供图形化界面和更多调试功能。
打印调试信息:在代码中插入打印语句可以帮助跟踪程序执行过程,查看变量值���。
通过合理的错误处理策略、使用 logging 和 traceback 记录错误信息,以及灵活运用调试工具与技术,可以更好地处理进程间的错误和调试工作,提高程序的稳定性和可靠性。
第六章:实战项目
在这一章中,我们将介绍三个常见的多进程应用场景,包括网络爬虫并行处理、数据分析任务并行化以及多进程游戏服务器实现。
网络爬虫并行处理
在网络爬虫中,并行处理可以提高爬取速度和效率。可以使用多进程技术将爬取任务分配到多个进程中,并行爬取多个网页。
下面是一个简单的多进程网络爬虫示例:
数据分析任务并行化
在数据分析中,并行处理可以提高计算速度和效率,减少计算时间。可以使用多进程技术将数据分析任务分配到多个进程中,并行处理。
下面是一个简单的多进程数据分析示例:
多进程游戏服务器实现
在游戏服务器中,多进程技术可以提高并发连接数和系统吞吐量,支持更多玩家在线并行游戏。
下面是一个简单的多进程游戏服务器示例:
通过这些实战项目,我们可以看到多进程技术在实际应用中的重要性和威力,可以提高程序性能和效率,提供更好的用户体验和服务质量。
第七章:并发编程最佳实践
性能优化技巧
避免不必要的同步:尽量减少全局变量和同步操作,因为它们会引入锁,降低并发性能。使用局部变量和异步通信(如消息队列)可以提高效率。
使用适当的并发模型:Python 中有多种并发模型,如多线程(GIL 限制),多进程,协程(如 asyncio),以及并行计算库(如 multiprocessing)。选择适合任务特性的模型,如 IO 密集型任务适合多线程,CPU 密集型任务适合多进程或并行计算。
利用缓存和数据共享:合理使用缓存可以减少不必要的计算,而数据共享可以通过内存映射文件或进程间通信(IPC)实现。
使用线程池和进程池:预创建一定数量的线程或进程,然后重复使用,可以避免频繁创建和销毁的开销。
限制线程/进程的数量:过多的并发线程或进程会导致资源竞争,适当限制数量可以提高性能。
负载均衡与资源利用
负载均衡:可以通过负载均衡器(如 Nginx、HAProxy)将请求分发到不同的服务器上,确保每个服务器不会过载。
资源分配:根据服务器的硬件资源(如 CPU、内存)动态调整任务分配,避免资源浪费。
水平扩展:通过添加更多的服务器来增加处理能力,而不是依赖单个服务器的性能提升。
使用微服务架构:将大型系统拆分为小型、独立的服务,每个服务可以独立扩展,提高整体系统的可扩展性。
可扩展性与分布式多进程架构
分布式计算:使用分布式系统(如 Hadoop、Spark)将任务分解到多台机器上并行处理,通过网络通信协调工作。
服务拆分:将服务划分为更小、独立的服务,每个服务可以独立部署和扩展。
分布式缓存:使用分布式缓存(如 Redis、Memcached)存储热点数据,提高数据访问速度。
事件驱动架构:通过事件驱动的方式处理请求,可以减少阻塞,提高并发处理能力。
服务网格:使用服务网格(如 Istio、Linkerd)管理服务之间的通信,实现服务发现、负载均衡和故障恢复等。
实践这些最佳实践可以确保并发应用程序在高负载下仍能保持高效和稳定。同时,持续监控和优化是保持性能的关键。
第八章:并发编程的未来展望
Python 3.7+的异步原生支持
async/await 语法:Python 3.5 引入了 async/await 语法,使得异步编程更加直观和易于理解。
asyncio 库:Python 3.7+对 asyncio 库进行了改进和优化,提供了更强大的异步编程能力,包括协程、事件循环、异步 IO 等。
async/await 与多线程/多进程:异步编程可以与多线程和多进程结合,实现更高效的并发处理。
asyncio 与多进程结合
并发处理:通过将 asyncio 与多进程结合,可以实现更高级别的并发处理,充分利用多核处理器的性能。
分布式计算:将异步任务分发到多个进程中执行,可以提高系统的整体处理能力。
资源隔离:每个进程都有独立的内存空间,可以避免进程之间的资源竞争问题。
进一步的并发框架和库
更强大的异步库:随着异步编程的普及,将会有更多强大的异步库涌现,提供更多功能和性能优化。
更灵活的并发框架:未来可能会有更灵活、可扩展的并发框架出现,以满足不同场景下的需求。
更智能的调度器:进一步优化调度器算法,提高任务调度的效率和性能。
未来的并发编程将更加注重性能、可扩展性和灵活性,同时更多的工具和框架将会被开发出来,帮助开发者更好地应对复杂的并发编程需求。持续关注并发编程领域的发展,将有助于把握未来的趋势并提升自身技能。
附录:常见问题解答
异步编程与多线程/多进程的区别:异步编程和多线程/多进程都可以实现并发处理,但它们的实现方式和应用场景有所不同。异步编程更适用于 IO 密集型任务,而多线程/多进程更适用于 CPU 密集型任务。
asyncio 的使用限制:asyncio 有一些使用限制,例如不能在嵌套的事件循环中使用,不能直接在主线程中使用。
asyncio 与多进程结合的注意事项:在将 asyncio 与多进程结合时,需要注意进程之间的通信和同步问题。
相关资源与工具
Python 官方文档:Python 官方文档中提供了详细的 asyncio 库使用指南和教程。
异步编程教程:可以参考一些关于异步编程的在线教程和书籍,了解更多关于异步编程的知识。
异步编程框架和库:可以尝试一些流行的异步编程框架和库,例如 Sanic、Quart、FastAPI 等。
实战代码示例
异步 IO 示例:一个使用 asyncio 实现异步 IO 的简单示例。
多进程异步示例:一个将 asyncio 与多进程结合实现并发处理的示例。
请注意,这些代码示例只是简单的实现,并未考虑完整的错误处理和资源管理。在实际应用中,需要根据具体场景和需求进行优化和扩展。
Python 多进程常见问题解答
什么是多进程?
多进程是指在操作系统中同时运行多个独立的进程,每个进程有自己独立的内存空间和资源。多进程可以实现并发处理,提高程序的性能和效率。
Python 中如何创建多进程?
在 Python 中可以使用 multiprocessing 模块创建多进程。通过 multiprocessing 模块提供的 Process 类可以创建子进程,从而实现多进程编程。
多进程与多线程有什么区别?
多进程是在不同的进程中执行任务,每个进程有独立的内存空间;而多线程是在同一个进程中创建多个线程,共享进程的内存空间。多进程更安全稳定,但开销较大;多线程更高效,但需要注意线程安全。
多进程中如何实现进程间通信?
在多进程中可以使用 multiprocessing 模块提供的 Queue、Pipe、Manager 等机制实现进程间通信。这些机制可以在多个进程之间传递数据和共享资源。
如何处理多进程中的异常?
在多进程中,每个进程都有自己的异常处理,可以使用 try-except 语句捕获异常并处理。此外,可以使用进程间通信机制将异常信息传递给父进程进行处理。
多进程中如何避免资源竞争和死锁?
为了避免资源竞争和死锁,可以使用进程间通信机制进行资源共享,并且在设计多进程程序时合理规划资源的使用顺序和互斥访问。
如何控制多进程的数量?
可以使用进程池(Pool)来控制多进程的数量,通过设置最大进程数量来限制同时运行的进程数量,从而避免资源过度消耗和系统负载过高。
多进程中如何处理子进程的返回值?
在多进程中,可以使用 join()方法来等待子进程结束,并获取子进程的返回值。也可以通过进程间通信机制将子进程的返回值传递给父进程。
如何在多进程中共享数据?
在多进程中可以使用共享内存、Manager、Pipe 等机制来实现数据共享。需要注意多进程之间的数据同步和互斥访问,避免数据不一致和竞争条件。
如何在多进程中实现任务调度和协同工作?
可以使用队列、事件、信号等机制在多进程之间实现任务调度和协同工作。通过合理设计进程之间的通信和同步机制,可以实现多进程之间的协同工作。
为什么在 Python 中使用多进程而不是多线程(特别是在 Windows 上)?
在 Python 中,由于全局解释器锁(GIL)的存在,多线程在执行 CPU 密集型任务时可能不会提供真正的并行执行。特别是在 Windows 上,由于 GIL 和线程调度的问题,多线程的性能可能不如多进程。多进程可以绕过 GIL 的限制,因为每个进程有自己的 Python 解释器和 GIL。
如何优雅地终止多进程?
可以使用multiprocessing.Event来通知所有进程应该终止。当主进程决定终止所有子进程时,它可以设置这个事件,而子进程可以检查这个事件并在适当的时候退出。
如何避免在多进程中启动子进程时出现的“fork”错误?
在某些操作系统(如 Windows)上,直接使用fork()来创建子进程是不可能的。Python 的multiprocessing模块会自动处理这种情况,但是如果你直接使用了底层的系统调用,可能会遇到问题。为了避免这种错误,应该始终使用multiprocessing模块提供的 API 来创建和管理进程。
在多进程中如何处理日志记录?
在多进程中,每个进程都会产生自己的日志输出,这可能会导致日志记录混乱。为了避免这个问题,可以使用以下方法:
使用不同的日志文件名或者日志输出流来区分不同进程的日志。
使用中央日志服务器或者日志收集器来聚合所有进程的日志。
使用
multiprocessing模块中的日志记录工具,如logging.Handler的子类,它们可以安全地在多进程环境中使用。
如何确保多进程的启动顺序?
如果需要确保进程按照特定的顺序启动,可以使用multiprocessing.Barrier或者条件变量(multiprocessing.Condition)。这些同步原语可以帮助你控制进程的启动和执行顺序。
多进程程序在部署时需要注意什么?
在部署多进程程序时,需要注意以下几点:
确保系统资源足够支持运行多个进程。
考虑系统的最大进程数限制,避免超出限制。
管理好进程的生命周期,确保进程可以正常启动、运行和终止。
监控进程的运行状态,确保系统稳定性和性能。
使用日志记录和错误处理机制来帮助调试和监控。
文章转载自:Amd794

还未添加个人签名 2023-06-19 加入
还未添加个人简介






评论