
开源 | Spark Commiter 深度解读:Apache Spark Native Engine

本文来自网易杭研大数据技术专家、Apache Kyuubi PMC Member、Apache Spark Committer 尤夕多,内容主要围绕 Apache Spark 与 Native Engine 展开,分享什么是 Native Engine,为什么要做 Native Engine,以及怎么做 Native Engine。
前言
Apache Spark 是基于 JVM 语言开发的分布式计算引擎,其 SQL 单个算子的执行性能已经很长时间没有得到提升,比如 Aggregation,Join 等。我们从 Spark2 迁移升级到 Spark3 的主要性能收益来源是 AQE ,而 AQE 其实是一个优化执行计划以及 Shuffle 数据读取的框架,和算子性能本身没有关系,因此 AQE 的优化效果也是有上限的。而在降本增效的背景下,计算集群资源越来越紧张,在不加机器下的基线保证成为常态,但是计算任务却会越来越多,因此用更底层的语言比如 C,C++,Rust 来实现 Native Engine 加速 Spark SQL 计算性能的需求就出现了。其实在 OLAP 生态里,已经有很多成功的 Native 计算引擎,比如 ClickHouse,Doris 等。一般来说,Native Engine 也意味着它是基于向量化计算的引擎。

01 Native Engine
为什么要做 Native Engine
现在 SSD 在大数据集群里已经变得非常普遍,比如我们 Spark 使用的 Shuffle 盘,在核心集群都是 SSD 甚至更好的 NVMe,这使得 IO 不再是计算瓶颈。而瓶颈永远不会消失,它只会从一个指标转移到另一个指标,现在的计算大部分瓶颈是由计算资源不足造成的,也就是 CPU,当然内存有时候也占一部分。

图 1 JVM vs. C++
那么如果我们继续围绕 JVM 来优化不行吗?当然是可以的,只是这会非常非常困难,而且业界也没有很成熟的方案和项目。
比如 Spark 当前的优化方案 Codegen,JVM 就存在很多限制,比如单个方法字节码不能超过 64KB,JIT 不对超过 8K 字节码的方法优化等,在一些有时候也占一部分。大宽表计算场景,就很容易出现性能下降现象,这也是为什么 Spark codegen 会有字段数量限制。另一方面,开发者也很难在 JVM 上利用现代 CPU 的一些特性,比如 SIMD 这类单指令多数据流来加速计算的 CPU 特性,常见的 AVX 指令集,AVX2, 甚至更现代的 AVX512 等。而基于 C++ 开发就能很容易的达到这一目的,只需要调用一个 C++ 库,然后在编译的时候开启相应的指令集优化就行。而且在内存管理上,JVM 垃圾回收的效率也是影响任务性能的一个因素,一般来说 GC 占用的 CPU 时间在总 CPU 时间的 10% 以内往往是比较良好的情况,但即便这样,也浪费了 10% 的计算性能,何况在更大的内存上表现会更加糟糕,比如超过 32GB 的堆。
因此用更底层的语言来开发 Native Engine 来加速计算性能成为业界主流。
Native Engine 现状

图 2 Spark Native Engine
在 Spark 的生态里,Native Engine 的声音其实已经存在了一段时间,第一款产品应该就是 Databricks 的 Photon,早在 18 年左右就已经开始研发,但即便是 Spark 母公司,也花了 5 年的时间研发才开始正式商业化可用,可见工程量之大。遗憾的是 Photon 不是一个开源项目,我们只能从其发表的论文来分析它的设计实现。
Meta 开源了自家的 Velox,可以理解为一个用 C++ 实现的 SQL Engine SDK,它围绕 SQL 提供了很多库,比如逻辑/物理执行计划,函数,向量数据结构,Parquet 读写,内存池管理等。开发者可以基于 Velox 来实现自己的 SQL 引擎。Velox 诞生的初衷就是为 JVM 开发的计算引擎加速,Meta 的 Presto 团队正在基于 Velox 开发 Native Engine。Intel 团队也基于 Spark + Velox 构建并开源了项目 Gluten,对标 Databricks 的 Photon。而无论是 Photon 还是 Gluten 都可以做到:用户不用修改一行代码就可以带来 Spark SQL 任务性能 2 倍提升,这是非常令人期待的。
除了这两个项目,还有 Apache Arrow Datafusion 一个基于 rust 开发的 Native Engine,快手开源的 Blaze 是基于其开发的 Spark Native Engine,该社区也已经不在活跃,在国内参与的公司也比较少,我们持保守观望态度(PS 最近好像又开始活跃了)。
02 Gluten 介绍
Gluten 是由 Intel 和 Kyligence 发起的开源项目。Gluten 架构 Gluten 本质上是基于 Spark 插件接口开发的项目,也可以理解成是一个大型的 Spark 插件库,因此不需要侵入 Spark 代码库,这是非常好的设计,像 Iceberg,Delta 这些 Spark 下游项目也是这么做的,这保证了 Spark 内核的稳定性。
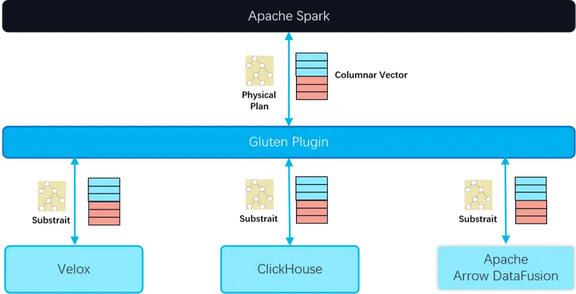
图 3 Gluten 总览
如图 3,Gluten 是一款支持多种 Native Engine Backend 的向量化执行引擎,当前社区主要围绕着 Velox 和 ClickHouse 这两个 backend 开发,未来可能会集成 Apache Data Fusion 或者其他优秀的开源项目。其核心原理包含两部分:
传递执行计划序,通过 Substrait 来实现执行计划在 JVM 和 Native 的传递,Substrait 可以理解为是基于 google protobuf 的面向关系对象的跨语言序列化 SDK,Velox 也支持基于 Substrait 作为执行计划输入
传递数据,通过 Spark SQL 提供的向量化框架实现。Spark SQL 的社区版本默认提供了 Row-based 的实现,算子操作的对象是 Row,而在向量化框架里,算子操作的对象是 ColumnarBatch,一个 ColumnarBatch 可以包含多行数据,ColumnarBatch 里每个字段的数据结构是 Column Vector
Gluten 插件库
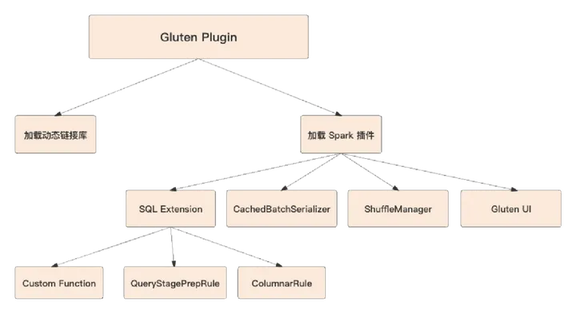
图 4 Gluten Plugin
如图 4,首先 Gluten Plugin 基于 Spark 开放的 Driver Plugin 以及 Executor Plugin 实现。通过这个入口,Gluten 把自己的能力和 Spark 连接起来。1) 通过 Java 接口加载动态链接库,也就是 Linux 操作系统下的 .so,比如 gluten.so, velox.so, arrow.so 等。2) 动态加载 Spark 插件:
SQL Extension,转换执行计划,通过 Spark 暴露的 Columnar Rule 把 Spark Plan 转换成 Gluten Plan
CachedBatchSerializer,支持 RDD Columnar Cache,对应的使用接口是 dataset.cache
ShuffleManager,支持 Columnar Shuffle Exchange
Gluten UI,展示 C++/Java 编译信息,Gluten 执行计划回退信息等
Gluten 执行层
基于 Spark 做 Native Engine 的一个最大优势就是不用重复造轮子,可以直接享受 Spark 久经沙场的代码库,以及未来的社区迭代。比如健壮的调度框架,推测执行,task/stage 不同粒度的失败重试;丰富的生态连接,比如 YARN/K8s。而我们只需要专注在我们关注的 SQL 性能上。
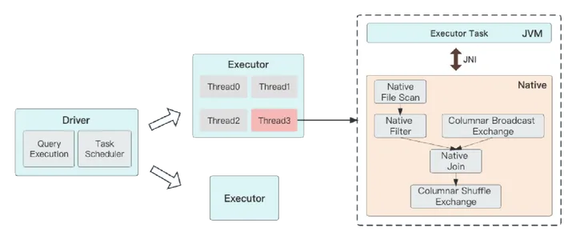
图 5 Gluten 执行模型
如图 5,Gluten 完全遵循 Spark 的设计理念,Task 作为最小执行单元跑在一个线程里。Gluten 通过 JNI 调用的方式传递执行计划片段,Native 拿到后就可以在当前线程构建自己的 Native Task 并执行。也就是说每有一个 Spark Task,在执行时候就有一个对应的 Native Task。
Gluten 解决了哪些问题
前面分享了 Gluten 的一些基本原理和实现,那么大家可能会想,看起来 Gluten 也没做很多事情,Spark Native Engine 实现起来不是很难的样子。下面我们就再深入了解一下,Gluten 解决了哪些问题。
执行计划转换
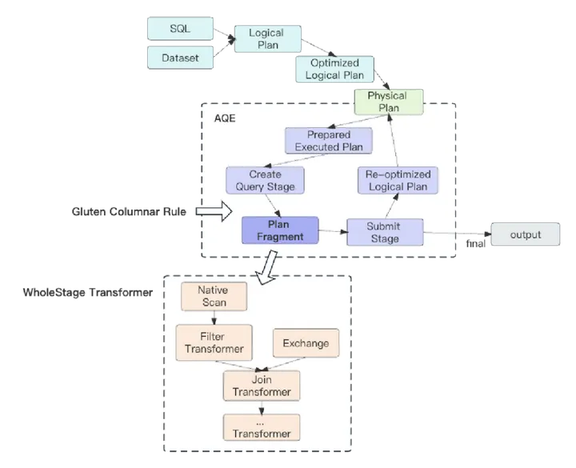
图 6 执行计划转换
上文提到 Gluten 通过向 Spark SQL Extension 注入 Columnar Rule 的方式来转换执行计划,只匹配 Spark 的物理执行计划的方式降低了转化的复杂度。这个转换的过程完全兼容 Spark AQE 框架,我们知道 AQE 会在运行过程中以 Stage 为切分粒度,不断的基于子执行计划来重新优化新的父执行计划,因此每进入一个新的 Stage,AQE 都会喂给 Columnar Rule 一个新的 Spark 执行计划片段。Gluten 有一个 WholeStageTransformer 概念,类似 Spark WholeStageCodegen 的优化思路,WholeStageTransformer 会把整个 Stage 产生的执行计划片段用 Substrait 转换成 Native 执行计划,从而让这整个 Stage 跑在 Native Engine,这样在执行的过程中不再需要和 JVM 产生额外的数据交互。
JVM + Native 共存执行计划
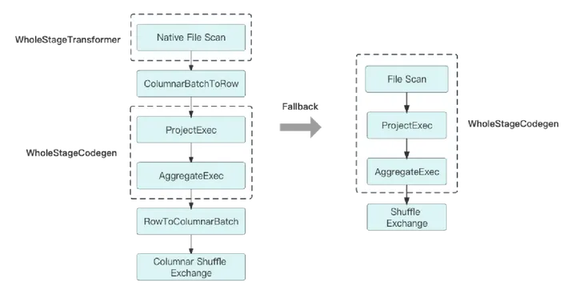
图 7 共存执行计划和回退
当然,整个 Stage 都在 Native Engine 跑是我们期望的场景,在现实里肯定不会这么理想。毕竟就连同为基于 JVM 实现的 Hive 和 Spark,有时候同一条 SQL 跑起来的结果还会不一样。而到了 Native Engine,这种差异性只会更加放大,典型的比如 Hive UDF,Native 肯定是跑不了的,怎么用 C++ 去跑 Java 实现的代码?那么面对这种在 Native 不支持的算子,Gluten 就会选择回退给 Spark 去跑。如图 7,左边是一个 JVM 和 Native 共存的执行计划。如果一个 Stage 既包含在 JVM 上跑的算子,也包含在 Native 跑的算子,那么 Gluten 就会在两个算子之间增加 ColumnarToRow 或者 RowToColumnar 算子,用于桥接数据结构。需要注意的是,这个算子的代价会比 Spark 自带的更高,因为在 Gluten 的这两个算子还包含了数据在 OffHeap 和 OnHeap 之间的拷贝。
问题又来了,如果一个 Stage 里有多个算子在 JVM 和 Native 之间反复横跳,那就会出现很多个 ColumnarToRow 和 RowToColumnar 算子,这个 Stage 性能很大概率是会下降的。所以,Gluten 还支持 Stage 粒度回退,如果一个 Stage 里存在多个 ColumnarToRow 算子,那么会把这一整个 Stage 回退给 JVM 跑。这样做可以保证这个 Stage 的计算性和 Spark 保持一致,不会出现性能下降的问题。由此我们也可以看出来,算子回退的比例是影响 Gluten 性能的关键因素之一。
数据交互
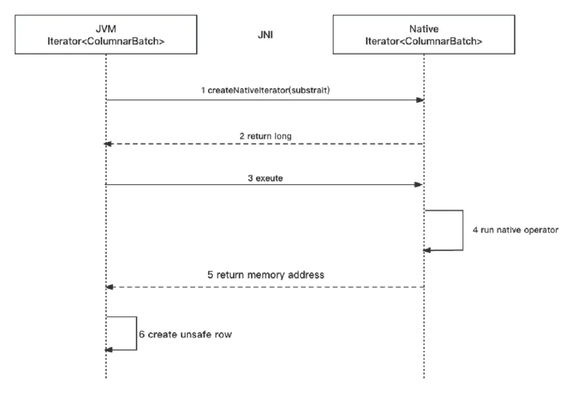
图 8 数据交互
上面讲了 Gluten 是如何传递执行计划,那么这里我们再来看看整个数据是如何流转起来。如图 8,Gluten 使用了两个 ColumnarBatch 迭代器,JVM 和 Native 各维护一个,相互之间通过 JNI 来交互。而实际的数据是维护在 Native 这边,也就是使用 OffHeap Memory 管理,暴露给 JVM 的只有一个指向这个 ColumnarBatch 的索引,以及一些基础的元数据,比如这个 ColumnarBatch 的数据条数,字段数。这就使得整个数据流转非常轻量,只有在遇到一些特定的比如 ColumnarToRow 这类需要改变数据内存分布的算子,Gluten 才会把实际数据拷贝到 OnHeap 暴露给 JVM,再转换成 UnsafeRow。也就是说,在 JVM 里流转的 ColumnarBatch 有两种,一种是轻量的,只有索引和元数据的,另一种是重量的,包含实际数据的。
统一内存管理
在知道数据是如何流转之后,那么更大的问题来了,Gluten 是如何做内存管理的,数据可能在 JVM 也可能在 Native,如何统一 OnHeap 以及 OffHeap Memory?这是 Spark 稳定性保障的根本,比如 SQL 算子是否需要 Spill,是否可以缓存 RDD Block 等。
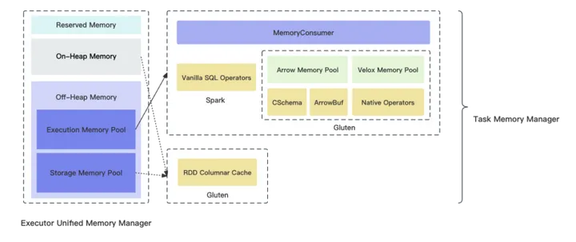
图 9 Spark 内存框架下的 Gluten
如图 9,Gluten 完全遵循 Spark 的统一内存管理框架,Spark 内存池分为两部分 Execution Memory Pool 以及 Storage Memory,前者负责管理运行时内存,比如 SQL 排序/聚合时使用的内存,后者负责维护存储时内存,比如 RDD cache 等。对于 Execution Mmeory Pool 这部分内存池,在 Gluten 接入后有三个使用场景:
Spark 自己使用,因为可能存在 JVM 与 Native 共存的场景,那么 Spark 算子就需要申请内存,这跟 Spark 社区的行为是一样的
Arrow Memory Pool,Gluten 在自己实现的 JVM 算子中内存管理是通过 Arrow 来完成的,比如在 RowToColumnar 算子里,通过缓存一批 Row 来生成一个 ColumnarBatch,那么就需要提前申请一块内存
Velox Moemry Pool,这是统一内存的关键,Velox 提供了一个 Memory Pool 来管理 Native 算子在运行时对内存的申请和释放,Gluten 通过注册监听器的方式调用 JNI 回调给 JVM 的 Task Memory Consumer,从而接入 Spark 内存管理框架
Gluten 的 RDD Columnar Cache 使用 Storage Memory Pool 这部分内存池,Spark Cache 有 StorageLevel 这个属性,因此用户可以自行选择把数据缓存在 OnHeap 或者 OffHeap,比如我们最常用的 dataset.cache 默认会选择 OnHeap, 当然我们可以自定义一个新的 StorageLevel,来显式的声明通过 OffHeap 缓存,在 Native Engine 我们也推荐用 OffHeap 来做缓存。所以,一个理想的基于 Native Engine 跑的 Spark 任务,它的 OnHeap 使用应该是非常少的,所有和数据有关的算子都是用的 OffHeap。这也降低了在大堆场景下 GC 导致的性能损失。
03 Gluten 性能
我们基于 TPCDS 1TB 规模的数据量来给 Gluten 和 Spark 做性能测试,如图 10,一共有 99 个测试用例,其中 95% 的测试用例 Gluten 好于 Spark。从整体数据上来看,Gluten 的表现也都优于 Spark,跑得更快,用的资源更少。
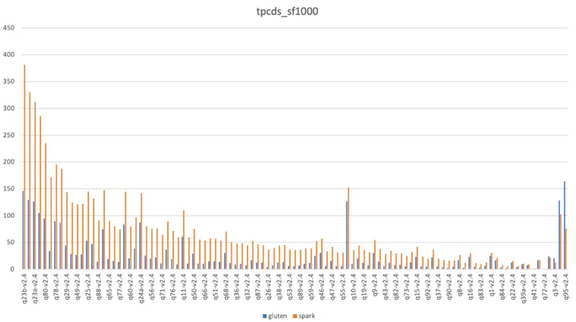
图 10 TPCDS-1TB
这个测试数据比 Intel 官方提供的测试数据差一些,官方大概有 2.8 倍性能提升。这里有很多因素会影响性能,比如硬件层面的 CPU、Shuffle 盘、网卡等,软件层面的操作系统版本、GCC 版本等。当然,这个测试数据能够说明 Gluten 有非常好的前景,而在实际落地到生产环境,我们还需要做非常多的事情。毕竟 TPCDS 测试用例覆盖不了所有的 Spark 使用方式,比如 Spark write table, Datasource v1/v2 interface, Dataset cache,Hive UDF 等。
04 未来计划
Gluten 社区除了网易,还有阿里云,百度,美团等公司在深度参与,社区目前也正在快速迭代,我们希望在深入参与 Gluten 社区的同时可以把内部的使用场景,遇到的问题暴露给社区,使其成为标准的一部分,加快落地速度。
由于 Native Engine 对操作系统有一定的依赖需求,而有些跑在老硬件上的 Hadoop 集群还采用较老的 CentOS7 版本,这会是一个影响落地的阻碍。因此,我们计划先在 K8s 集群使用起来,基于 Ubuntu 的 Docker 镜像来装载 Native Engine,从而实现在用户无感知的前提下加速 Spark SQL 任务计算性能。
最后,非常欢迎有想法的团队来找我们交流。
版权声明: 本文为 InfoQ 作者【网易数帆】的原创文章。
原文链接:【http://xie.infoq.cn/article/ef3476bdb5c017fb0f2f66286】。文章转载请联系作者。

专注数字化转型基础软件研发 2020-07-22 加入
源自网易杭州研究院,是网易数字经济的创新载体和技术孵化器。聚合云计算、大数据、人工智能等新型技术,聚焦研发数据智能、软件研发、基础设施与中间件等基础软件,推动数字化业务发展。









评论