
国产数据库市场横空杀出个巨头?亚信 AntDB 数据库凭什么

信创政策加持下国产数据库市场异常热闹,大大小小的厂商二三百家,与行业人交流发现,竟然还有不少数据库方面的专业人才,也有在某个行业深耕十几二十年的不错的数据库产品。有了政策的东风,这些产品也不甘于深藏原行业,纷纷杀到国产数据库市场攻城略地。从通讯行业走出的亚信科技 AntDB 数据库也一样势头很猛,被越来越多的行业客户关注、青睐。
一
2022 年 7 月,亚信科技发布了分布式数据库 AntDB 的 7.0 版本。这是 AntDB 自 2008 年在通信运营商核心系统上线以来第七个大的版本。这次发布会也是亚信科技 AntDB 的首次发布会,并成功引起了外界对亚信数据库的好奇:亚信还有数据库?竟然在十几年前就开始做了?已经到第 7 个版本了?这到底是一个什么产品?
严格来说,亚信数据库是亚信的被动选择,因为亚信数据库是被客户场景逼出来的产品,是为了解决当时的国际主流数据库没有遇到过、无法满足的场景需求,被迫进行技术创新才有的产品。
21 世纪初,中国移动电话用户进入了迅猛发展的时期,仅中国移动某省的客户就高达四五千万,每天通信记录高达 10 亿级别,如此数量级的用户量和业务量在全球来看都是史无前例的,用户量和业务量同时剧增给核心计费账务系统的吞吐量和相应效率带来了严重挑战,即使用到当时最先进的国际主流数据库产品也无法满足业务需求。
面对全球超级规模的数据和信息处理需求,亚信作为为三大运营商提供业务支撑的合作伙伴“临危受命”,投入到了第一代 AntDB 的开发中,并于 2008 年在通信运营商核心系统正式上线运行,在电信级高可用的基础上,使整个交易处理的吞吐率和响应时间提升了一个数量级。
从需求方面说,亚信 AntDB“出道即巅峰”——从一开始就在应对超高强度和密度的业务需求,由此而来的产品,安全性和稳定性可以说是与生俱来、并且一直在实打实的场景中验证打磨着的,这种高频高密度交易的天然“练兵场”对于大多数产品来说都是可遇不可求的稀缺资源。
应用场景这种天然的“练兵场”对 AntDB 的发展演进非常重要,毕竟对着教科书都能把代码编出来,但是代码出来,产品能不能稳定运行、可靠性怎么样就需要实实在在的应用场景来打磨,脱离应用场景谈产品能力谈产品发展都是不现实的,尤其对于这种连国际主流数据库都束手无策的独具中国特色的场景更能考验和打磨出产品的实战能力。
二
第一代 AntDB 是内存数据库,它把单节点交易处理的吞吐量和响应时间都提高了一个数量级,有效支撑了通信运营商业务发展的需要,亚信也因此开始了自己的数据库研发之路。经过 10 多年的发展,AntDB 已经从满足自用需求发展为企业级的通用产品,并在通信、金融、交通、能源、物联网等行业成功商用落地。
下图总结了 AntDB 的各个版本的研发演进情况,包括各个版本开发时间和重要特性。
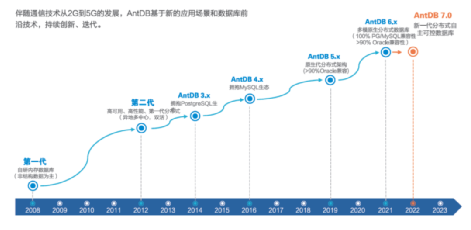
AntDB1.0 是一个内存数据库,到 2.0 的时候已经发展成为第一代的分布式数据库,支持异地多中心双活。AntDB3.x,4.x 和 5.x 的时代分别增加了对 PostgreSQL 生态社区,MySQL 生态,Oracle 的 SQL 的支持。
AntDB 的发展,展示了一条从内存数据库,到高可用全功能的关系型数据库,再到兼容 MySQL,PostgreSQL 以及 Oracle 的全栈式数据库,更进一步到分布式,多模原生数据库的发展路径。
三
从架构上来看,AntDB 的架构是典型的主流数据库架构。具体来说,AntDB 是一个典型的 share-nothing 架构。这种架构没有什么特殊功能节点,所有的查询都可以通过任意节点进行。目前大部分的开源分布式数据库和商业分布式数据库也都采用这种架构。
在 share-nothing 架构下,AntDB 的计算和存储是分离的。计算有计算的节点,存储也有存储的节点。无论是计算节点还是存储节点,都可以按照实际需要水平扩展。AntDB 系统通过自动化分片技术,来实现分散式存储和负载均衡。
下图是它的架构图。
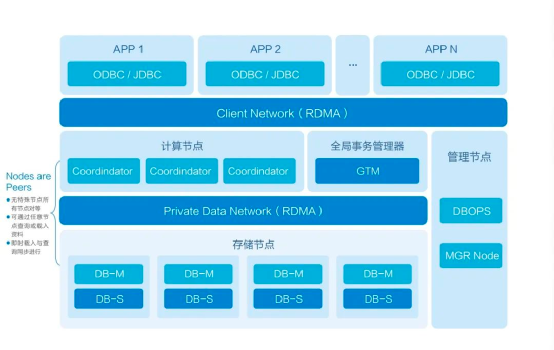
和其他 share-nothing 的数据库比起来,AntDB 的独到之处在于存储引擎和计算引擎都是自研的,拥有自主知识产权的源代码。AntDB 的内存引擎提供了比大部分商业数据库超过一个量级的交易能力,还提供了从内存引擎到磁盘引擎之间的数据自动同步功能。
同时在内核全自研的基础上,AntDB 还做了产品的标准化和第三方生态兼容,通过 SQL 解析来保护数据库语法的多样性,既支持 SQL2016 标准,全面兼容 MySQL、PostgreSQL 语法,也同时兼容 Oracle 等国外主流数据库的 SQL 语法。用户可以根据自己的业务需求,选择合适的 SQL 语法解析引擎,做到用同样的 AntDB 引擎,去替换多种已有的数据库的目的,而且 AntDB 对 SQL 解析引擎的切换动态生效,不需要重启数据库。这给了用户极大的方便。
在信创政策下,拥有全自研引擎的 AntDB 全面融入信创,与国产芯片、操作系统等底层软件硬件生态兼容,适配国产第三方工具。目前 AntDB 对国产的飞腾,龙芯,鲲鹏,海光等 CPU 架构,和统信,中标麒麟,银河麒麟,欧拉等国产操作系统全面对接。
四
经历了 10 多年各种应用场景的锤炼,为 10 亿多用户提供在线服务,AntDB 已经成为性能稳定、执行速度快的系统——手机用户的每次点击、每次通话都需要 AntDB 的支持,AntDB 峰值每秒处理百万笔通信核心交易,超过了国外商用数据库产品一个数量级,当之无愧的强大。
也正因为一直在通信运营商核心系统应用,离中国信息技术发展最近,因此 AntDB 数据库可以说一直站在未来的场景中迭代升级。对于数据库未来的发展,AntDB 将关键字锁定在是“融合”+“实时”两个词上。
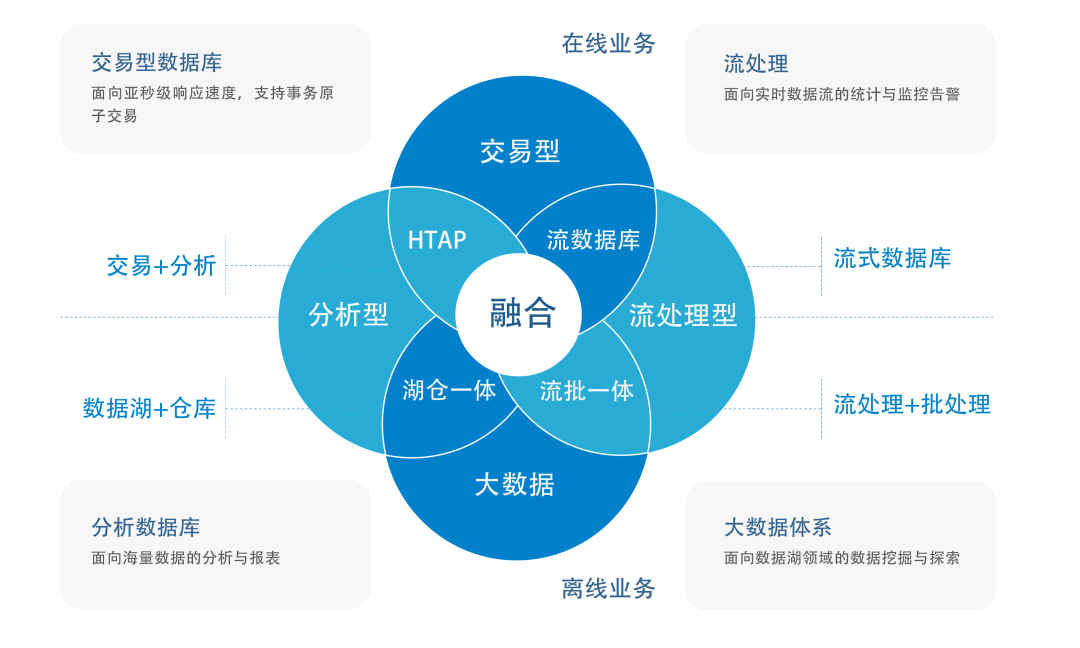
为了适应现在的诸多数据应用场景,数据库产品有交易型数据库,有分析型数据库。现存的还有以 Hadoop 生态圈为代表的大数据体系。还有近年来越来越流行的流处理数据库等等。
如果一个用户为了支撑不同的应用场景,就需要按照不同的数据处理工具,并且要在不同的数据处理工具之间对底层数据进行同步,那么这将是一个非常复杂的系统。用户的管理和维护都非常的困难。很不幸的是,现实中,目前很多单位的数据处理工具确实是这样的。
AntDB 的“超融合”理念认为,一个数据处理引擎应该能够融合和处理各种不同的场景。客户应该只需要一个数据库产品就能够同时获得内存计算、交易、分析、流处理、时序等诸多能力,完成对数据库引擎的“超融合“。
随着技术的发展,用户对数据处理实时性要求越来越高。比如说,用户以前只需要看每天的统计报表,现在用户更希望能够实时看到统计报表,获得实时的风险推送告警。
目前实时计算是通过流计算引擎进行的,它们游离在数据库之外,通常通过 Kafka 传送数据,通过 Spark streaming 或者 Flink 等流处理引擎处理。这些引擎不能简单地用 SQL 来处理数据,流处理系统和批处理系统之间也无法进行融合。
所以面向未来的数据库引擎应当具备流式处理引擎,通过 SQL 对流和批统一的进行处理,可以对流流,流表等进行多种模式的关联,可以进行弹性部署,流处理和批处理节点可以分别根据业务需要进行缩容扩容。
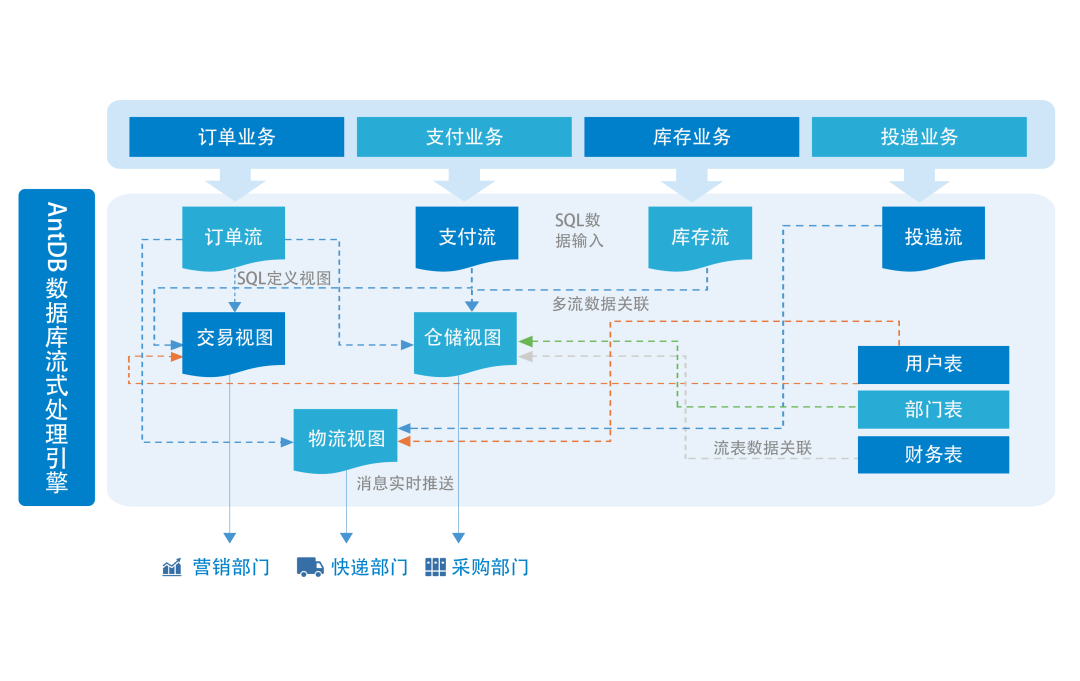
“超融合”和“流式处理引擎”也是 AntDB 数据库新版本中即将实现的能力。
根据可靠消息,12 月 26-28 日亚信产品发布会上,AntDB 将就这两种能力进行公开发布,发布会的相关消息也会同步到 AntDB 公众号,感兴趣的朋友可以关注公众号随时跟进。
AntDB 数据库
AntDB 数据库始于 2008 年,在运营商的核心系统上,服务于全国 20 多个省份的 10 亿多用户;具备高性能、弹性扩展、高可靠等产品特性,峰值每秒可处理百万笔电信核心交易,并保障系统持续 0 故障运行近十年。
五
过去由于国际品牌数据库的挤压,国产数据库没有生存空间和发展机会,如果说当下的信创政策和环境,是国产数据库发展的天时,那么实实在在的应用场景是地利,研发实力和技术生态是人和,未来的国产数据库市场必将属于占据天时、地利、人和的厂商和产品。
AntDB 会不会是国产数据库横空而来的巨头呢?我们拭目以待吧。
原地址:https://mp.weixin.qq.com/s/Slon8zIBw80T7M2Nq9ecyg
作者:飞总聊 IT

企业数据库创新实践者 2021-07-26 加入
AntDB数据库始于2008年,服务于全国20多个省份的10亿多用户提供在线服务;具备高性能、弹性扩展、高可靠等产品特性,峰值每秒可处理百万笔电信核心交易,并保障系统持续0故障运行近十年。 官网:asiainfoah.com







评论