
Bitmap 和 布隆过滤器傻傻分不清?你这不应该啊
Bitmap
Redis 中的 Bitmap(位图)是一种较为特殊数据类型,它以最小单位bit来存储数据,我们知道一个字节由 8 个 bit 组成,和传统数据结构用字节存储相比,这使得它在处理大量二值状态(true、false 或 0、1 等只有两种状态)数据时具有极高的空间效率。不过,它不是一种全新的数据类型,其底层实现仍是基于 String 类型。
便于理解,你可以将 Bitmap 的底层结构看成是由一系列 bit 位组成的数组,在此数组中,每个位都对应一个偏移量(类似数组的下标)。通过将特定偏移量上的位值设置为 0 或 1,来表示不同的状态。

比如我们要设计一个答题游戏系统。其规则为:若用户答对全部 7 道题,则可获得大奖。
每个答题用户都有自己的 key,即 answer:user:X。使用 bitmap 记录用户的答题情况,将题号设置为对应偏移量,当用户答对 ✅ 题目时 ,偏移量位值设为 1;当用户答错 ❌ 题目时,位值设为 0。
假如用户user:1 答对了 2、5、7 号题,可将对应偏移量为 2、5、7 的位值设置为 1,其余位值默认设为 0。若要查看该用户对某个题目的回答情况,只需按照偏移量遍历此数据结构,一旦碰到位值为 1 的情况,即表示该题回答正确。
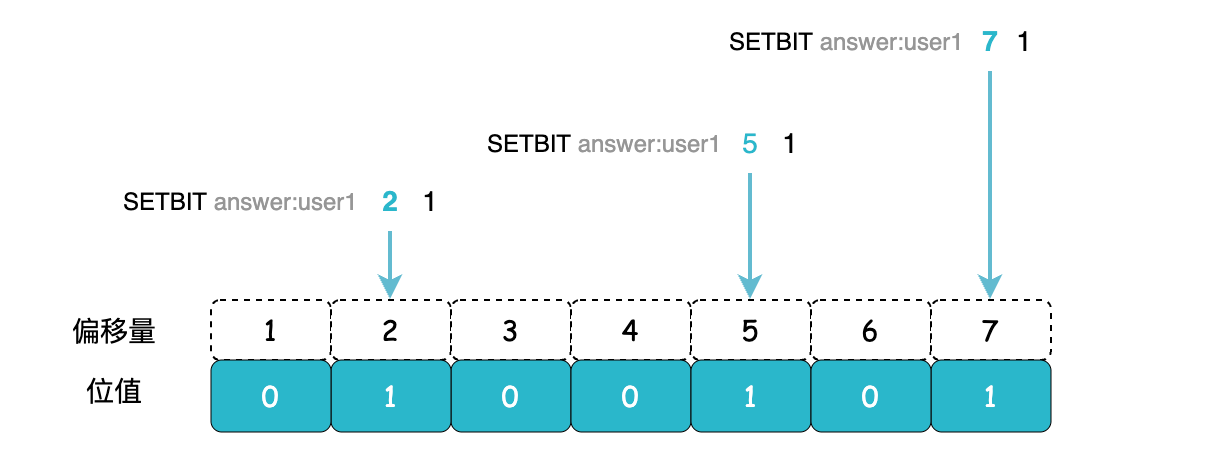
答题活动结束后,接下来需要统计获奖者,即那些全部答对 7 道题的用户。
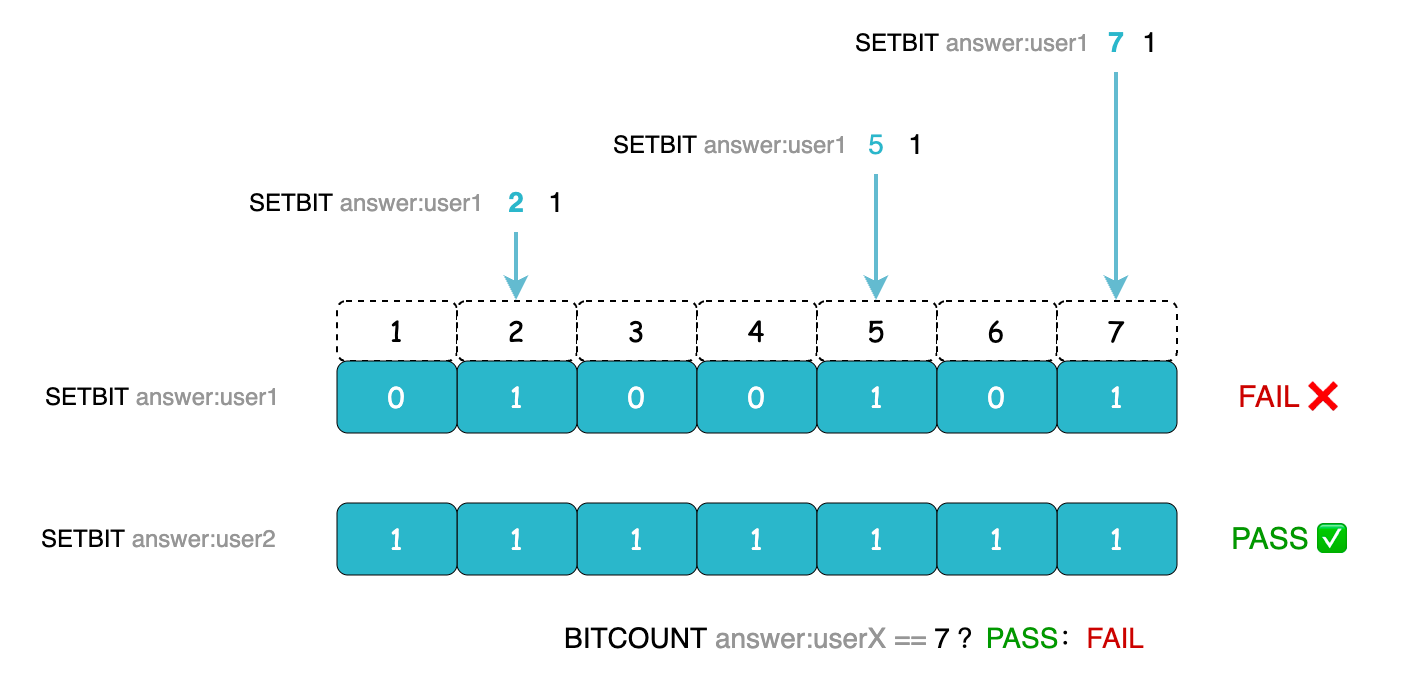
要快速统计用户是否全部答对题目,可以使用 BITCOUNT 命令来统计位值中被设置为 1 的数量。通过执行 BITCOUNT answer:userX == 7 这样的操作进行判断,若结果等于 7,则表明该用户全部答对了题目。
聪明的你或许会产生疑惑,如果想用 bitmap 判断邮箱地址是否在黑名单内,偏移量该如何设置呢?遗憾的是,bitmap 并不支持直接以字符串作为偏移量。不过,我们可以对邮箱进行哈希运算得到哈希值,进而算出偏移量。
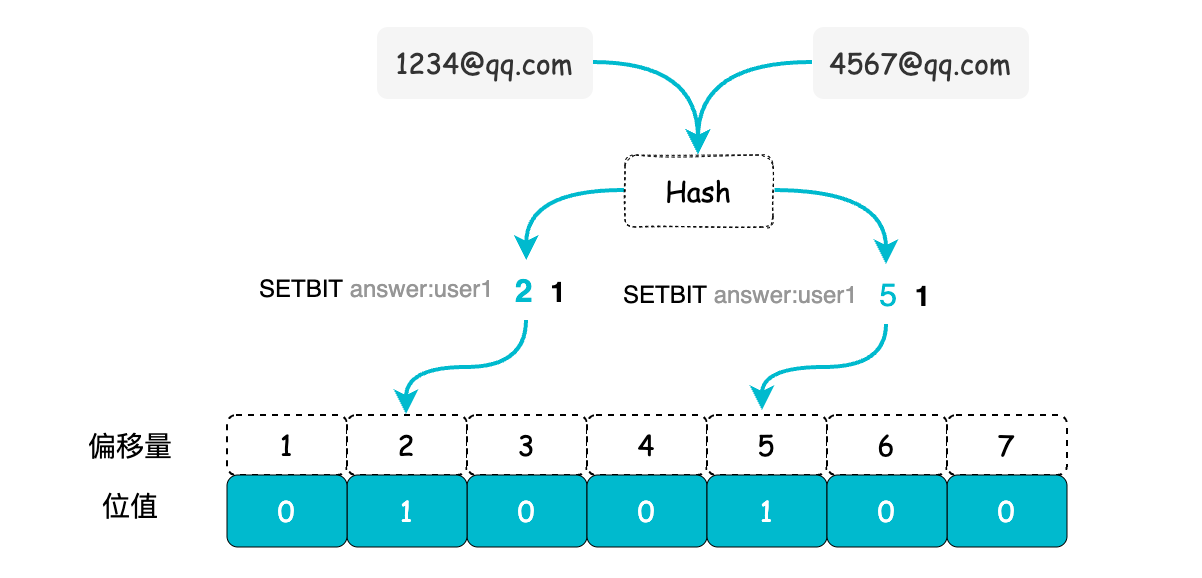
由于用到哈希运算,就不可避免地会出现数据碰撞问题,即不同的字符串可能得出相同的哈希值。这样一来,状态判断就可能不准确。别急,后边介绍布隆过滤器(Bloom Filter)看它如何来优化这个问题。
操作命令
Bitmap 的操作命令不多且使用简单,主要用到的就是SETBIT、GETBIT、BITCOUNT、BITOP几个命令。
SETBIT:用于设置指定偏移量上的位值,其时间复杂度为 O (1)。例如,当用户答对了第 7 题时,可以将题号对应的偏移量为 7 的位值设置为 1,以此表示该题已被答对。
GETBIT:获取指定偏移量上的位值,同样具有高效的时间复杂度。可以快速查询用户对特定题号的回答状态。
BITCOUNT:用于统计位值中被设置为 1 的数量。比如上边我可以很容易统计答对全部题目的用户,但也仅能知道个数,无法查看具体的哪个题目。
BITOP:对一个或多个 bitmap 进行位运算,并将结果保存到新的键中,支持 AND、OR、NOT、XOR 四种操作。这个命令的用法是将多个 bitmap 中相同偏移量的位值进行运算。若我想知道用户 1 和用户 2 都答对的题目,经过 AND 运算后,假如只有题号 1 是两个用户都答对的题目,那么生成新的结果集中就只有题号 1 对应的位值为 1。
扬长避短
优点
极高空间效率:bitmap 是真的节省数据存储空间。粗略的算一下,一亿位的 Bitmap 大概才占 12MB 的内存,相比其他数据结构,能极大地节省存储空间;
快速查询:位操作通常比其他数据结构查询速度更快。无论是设置位值还是获取位值,时间复杂度都为 O (1),能够快速响应查询请求;
易于操作:支持单个位操作、位统计、位逻辑运算等,运算效率高,不需要进行比较和移位;
缺点
由于数据结构特点,导致它仅适用于表示两种状态,即 0 和 1。对于需要表示更多状态的情况,Bitmap 就不适用了;
只有当数据比较密集时才有优势,如果我们只设置(20,30,888888888)三个偏移量的位值,则需要创建一个 99999999 长度的 BitMap ,但是实际上只存了 3 个数据,这时候就有很大的空间浪费,碰到这种问题的话,可以通过引入另一个
Roaring BitMap来解决;
应用场景
看到 Bitmap 还是比较简单的一种数据结构,占用空间小查询效率高,非常适用于记录状态的场景,它的应用场景很常见,比如:
用户签到状态(连续签到天数)
用户的在线状态(统计活跃用户)
问卷答题等等吧!
布隆过滤器
上边咱们提到 bitmap 记录字符元素的状态时,需要先借助哈希运算得出偏移量。但引入哈希运算后可能会出现哈希碰撞的情况,导致状态误判。
布隆过滤器对这个问题做了进一步的优化,做到了可控误判率,当我们将一个邮箱地址添加到集合中,多个不同的哈希函数会将这个邮箱地址映射到 bitmap 中的不同偏移量位置上,且将这些位值置为 1。
要判断邮箱地址是否在集合中,通过相同的哈希函数映射到 bitmap 上的多个位置,如果这些位上的值都为 1,则邮箱可能存在集合中;如果有任何一个位置的值为 0,则元素一定不在集合中。这是布隆过滤器的特点。
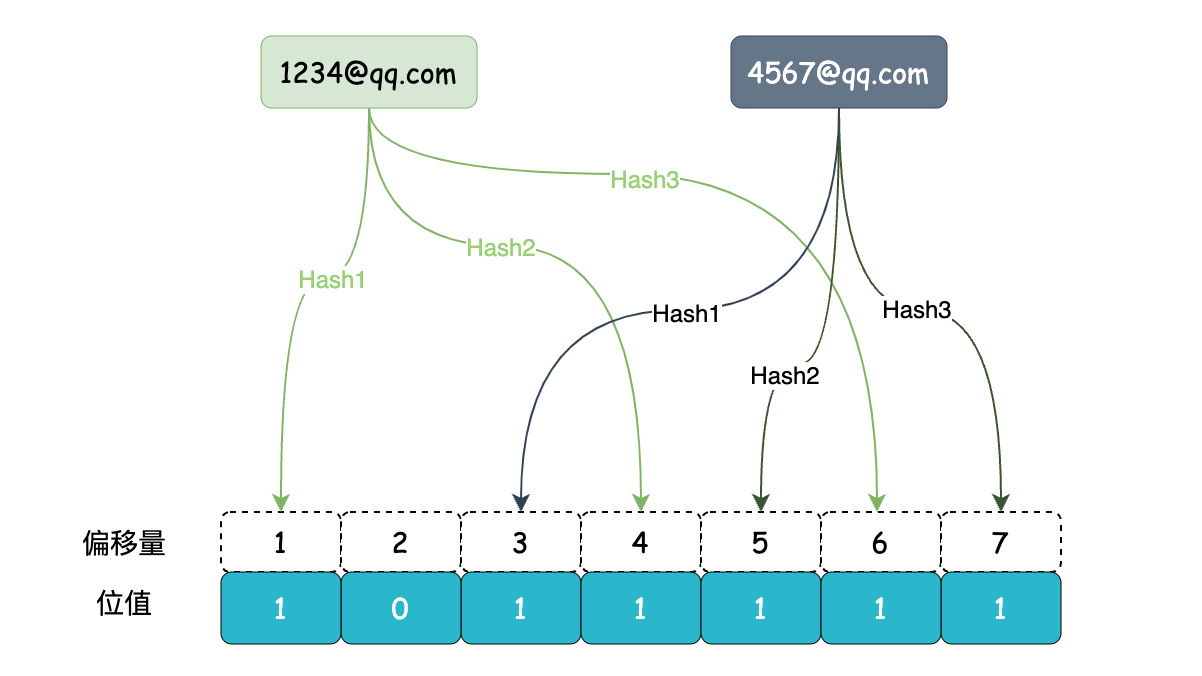
虽然但是布隆过滤器还是会发生误判的情况,额~,但好在我们可以通过调整布隆过滤器的大小和哈希函数的数量来控制误判率。
操作命令
布隆过滤器的命令也不多,主要用到的如下几个:
BF.RESERVE:创建一个新的布隆过滤器,并指定容量 capacity 和误判率 error_rate。
BF.INFO:获取布隆过滤器的信息,包括容量、误判率等。
BF.ADD 和 BF.MADD:分别是向布隆过滤器中添加元素和批量添加
BF.EXISTS 和 BF.MEXISTS:分别是检查布隆过滤器中某个元素和批量检查元素是否存在
扬长避短
优点
布隆过滤器的空间占用也是极小,它本身不存储完整的数据,和 bitmap 一样底层也是通过 bit 位来表示数据是否存在。
性能比较稳定,无论集合中元素的数量有多少,插入和查询操作的时间复杂度都非常低,通常为 O (k),其中 k 是哈希函数的个数。也就是说在处理大规模数据时,布隆过滤器的性能不会随着数据量的增加而急剧下降。
缺点
存在一定的误识别率:布隆过滤器存在误判的情况,即当一个元素实际上不在集合中时,有可能被判断为在集合中。这是因为多个元素可能通过哈希函数映射到相同的位置,导致误判。但是,当布隆过滤器判断一个元素不在集合中时,则是 100% 正确的。
删除元素比较困难:一般情况下,不能直接从布隆过滤器中删除元素。这是因为一个位置可能被多个元素映射到,如果直接将该位置的值置为 0,可能会影响其他元素的判断。
应用场景
布隆过滤器存在一定的误判,所以使用它的场景就一定要允许不准确的情况发生:
解决 Redis 缓存穿透问题:秒杀商品详情通常会被缓存到 Redis 中。如果有大量恶意请求查询不存在的商品,通过布隆过滤器可以快速判断这些商品不存在,从而避免了对数据库的查询,减轻了数据库的压力。
邮箱黑名单过滤:在邮件系统中,可以使用布隆过滤器来过滤垃圾邮件和恶意邮件。将已知的垃圾邮件发送者的地址或特征存储在布隆过滤器中,新邮件来时判断发送者是否在黑名单中。
对爬虫网址进行过滤:在爬虫程序中,为了避免重复抓取相同的网址,可以使用布隆过滤器来记录已经抓取过的网址。新网址出现时,先判断是否已抓取过。
太多太多了.....
总结
一起梳理了 bitmap 和 布隆过滤器的原理、用法以及它们各自的优缺点和应用场景,大环境不好更要多多提升自身技术能力,而且现在面试三句不离大数据量和高并发,此类问题想要应对自如,不仅要有深度还要有广度,掌握这两个知识点多提供一种答案也是好的。写的不好大家对付看吧!
文章转载自:程序员小富

还未添加个人签名 2023-06-19 加入
还未添加个人简介












评论